当前位置:网站首页>Flink task exit process and failover mechanism
Flink task exit process and failover mechanism
2022-07-07 03:17:00 【Direction_ Wind】
Here's the catalog title
1 TaskExecutor End Task Exit logic
Task.doRun() guide Task The core method of initializing and executing its related code ,
Construct and instantiate Task The executable object of : AbstractInvokable invokable.
call AbstractInvokable.invoke() To start Task Calculation logic included .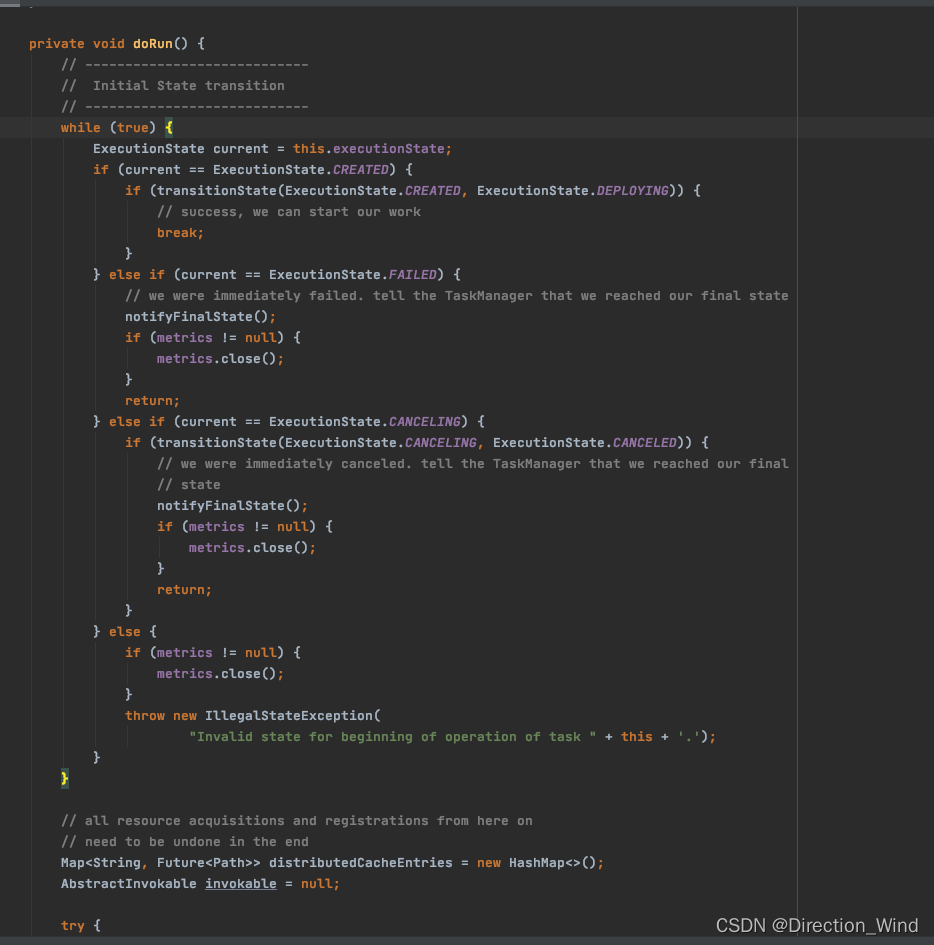
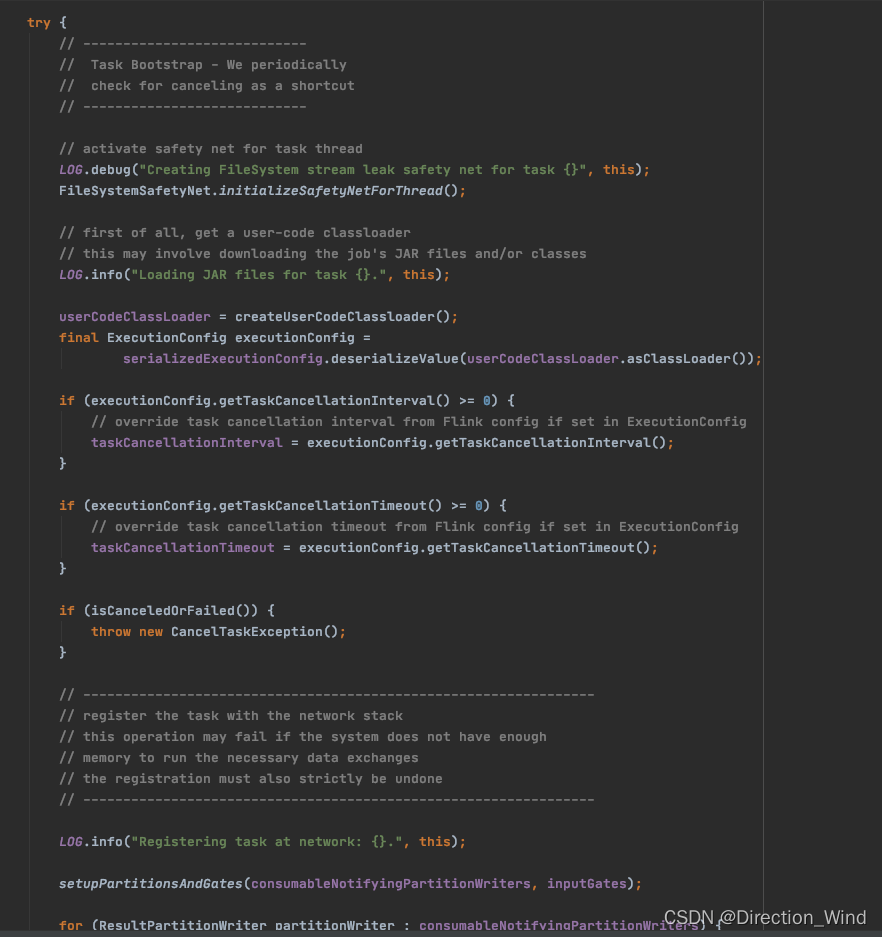
When AbstractInvokable.invoke() After executing exit , Perform the corresponding operation according to the exit type :
- Exit after normal execution : Output ResultPartition Buffer data , And close the buffer , Mark Task by Finished;
- Canceling the operation results in exiting : Mark Task by CANCELED, Close user code ;
- AbstractInvokable.invoke() An exception is thrown during execution to exit : Mark Task by FAILED, Close user code , Record exceptions ;
- AbstractInvokable.invoke() In the process of execution JVM Throw an error : Forcibly terminate the virtual machine , Exit the current process .
Then release Task Related networks 、 Memory 、 File system resources . Finally through Task->TaskManager->JobMaster The delivery link of will Task Notify Leader JobMaster Threads .
Task.notifyFinalState() -> TaskManagerActions.updateTaskExecutionState(TaskExecutionState) -> JobMasterGateway.updateTaskExecutionState(TaskExecutionState)
- TaskExecutionState Key information carried :
TaskExecutionState {
JobID // Mission ID
ExecutionAttemptID // Task The only execution ID, Mark each execution
ExecutionState // Enumerated values ,Task Execution status
SerializedThrowable // if Task Throw an exception , This field records exception stack information
...
}
- Task Perform state transitions :
CREATED -> SCHEDULED -> DEPLOYING -> RUNNING -> FINISHED
| | | |
| | | +------+
| | V V
| | CANCELLING -----+----> CANCELED
| | |
| +-------------------------+
|
| ... -> FAILED
V
RECONCILING -> RUNNING | FINISHED | CANCELED | FAILED
2 JobMaster End failover technological process
2.1 Task Execute State Handle
JobMaster received TaskManager adopt rpc Sent task Execution status change information , Will notify the current Flink Job scheduler (SchedulerNG) Handle , Because they are all called through the same thread , Follow up on ExecutionGraph( Run time execution plan )、failover Count stateful instances such as read/write There will be no thread safety problems in operation .
JobMaster The core processing logic is SchedulerBase.updateTaskExecutionState(TaskExecutionStateTransition) in (TaskExecutionStateTransition Mainly TaskExecutionState Readability encapsulation ).
Processing logic : Try to receive Task The execution status information is updated to ExecutionGraph in . If the update is successful and target Status as FINISHED, According to the concrete SchedulingStrategy Implementation strategy , Select the consumable result partition and schedule the corresponding consumers Task; If the update is successful and target Status as FAILED, Enter specific failover technological process .
- SchedulerBase.updateTaskExecutionState(TaskExecutionStateTransition) :
public final boolean updateTaskExecutionState(
final TaskExecutionStateTransition taskExecutionState) {
final Optional<ExecutionVertexID> executionVertexId =
getExecutionVertexId(taskExecutionState.getID());
boolean updateSuccess = executionGraph.updateState(taskExecutionState);
if (updateSuccess) {
checkState(executionVertexId.isPresent());
if (isNotifiable(executionVertexId.get(), taskExecutionState)) {
updateTaskExecutionStateInternal(executionVertexId.get(), taskExecutionState);
}
return true;
} else {
return false;
}
}
- ExecutionGraph.updateState(TaskExecutionStateTransition): The target cannot be found in the current physical execution topology ExecutionAttemptID when , The update will fail . What needs to be noticed is this ID Used to uniquely identify a Execution, and Execution Then represent ExecutionVertex( Represents a topological vertex subTask plan ) An execution instance of ,ExecutionVertex Can be repeated many times . This means when there is subTask Rerun ,currentExecutions Will no longer hold the last executed ID Information .
/** * Updates the state of one of the ExecutionVertex's Execution attempts. If the new status if * "FINISHED", this also updates the accumulators. * * @param state The state update. * @return True, if the task update was properly applied, false, if the execution attempt was * not found. */
public boolean updateState(TaskExecutionStateTransition state) {
assertRunningInJobMasterMainThread();
final Execution attempt = currentExecutions.get(state.getID());
if (attempt != null) {
try {
final boolean stateUpdated = updateStateInternal(state, attempt);
maybeReleasePartitions(attempt);
return stateUpdated;
} catch (Throwable t) {
......
return false;
}
} else {
return false;
}
}
JobMaster: The central operation class responsible for a task topology , Involving job scheduling , Resource management , External communication, etc …
SchedulerNG: Be responsible for scheduling job topology . All calls to methods of this kind of object will pass ComponentMainThreadExecutor Trigger , There will be no concurrent calls .
ExecutionGraph: The central data structure of the current execution topology , Coordinate the Execution. Describe the various aspects of the whole task SubTask And its partition data , And keep in communication with them .
2.2 Job Failover
2.2.1 Task Failure Handle
- Task The main process of exception is DefaultScheduler.handleTaskFailure(ExecutionVertexID, Throwable), according to RestartBackoffTimeStrategy Determine whether to restart or failed-job; according to FailoverStrategy Select the one that needs to be restarted SubTask; Finally, according to the current task SchedulingStrategy Execute the corresponding scheduling strategy and restart the corresponding Subtask.
private void handleTaskFailure(
final ExecutionVertexID executionVertexId, @Nullable final Throwable error) {
// Update the current task exception information
setGlobalFailureCause(error);
// If the relevant operator (source、sink) There is coordinator, Know its further operation
notifyCoordinatorsAboutTaskFailure(executionVertexId, error);
// Apply the current restart-stratege And get the FailureHandlingResult
final FailureHandlingResult failureHandlingResult =
executionFailureHandler.getFailureHandlingResult(executionVertexId, error);
// Restart according to the result Task Or fail the task
maybeRestartTasks(failureHandlingResult);
}
public class FailureHandlingResult {
// Recover all that needs to be restarted SubTask
Set<ExecutionVertexID> verticesToRestart;
// Restart delay
long restartDelayMS;
// The root of all evil
Throwable error;
// Whether the global failure
boolean globalFailure;
}
- ExecutionFailureHandler: Handling exception information , Return the exception handling result according to the current application policy .
public FailureHandlingResult getFailureHandlingResult(
ExecutionVertexID failedTask, Throwable cause) {
return handleFailure(
cause,
failoverStrategy.getTasksNeedingRestart(failedTask, cause), // Select the one that needs to be restarted SubTask
false);
}
private FailureHandlingResult handleFailure(
final Throwable cause,
final Set<ExecutionVertexID> verticesToRestart,
final boolean globalFailure) {
if (isUnrecoverableError(cause)) {
return FailureHandlingResult.unrecoverable(
new JobException("The failure is not recoverable", cause), globalFailure);
}
restartBackoffTimeStrategy.notifyFailure(cause);
if (restartBackoffTimeStrategy.canRestart()) {
numberOfRestarts++;
return FailureHandlingResult.restartable(
verticesToRestart, restartBackoffTimeStrategy.getBackoffTime(), globalFailure);
} else {
return FailureHandlingResult.unrecoverable(
new JobException(
"Recovery is suppressed by " + restartBackoffTimeStrategy, cause),
globalFailure);
}
}
FailoverStrategy: Failover strategy .
- RestartAllFailoverStrategy: Use this strategy , When a fault occurs , The entire job will be restarted , That is, restart all Subtask.
- RestartPipelinedRegionFailoverStrategy: When a fault occurs , Restart failure occurs Subtask Where Region.
- RestartBackoffTimeStrategy: When Task In case of failure , Decide whether to restart and the delay time of restart .
FixedDelayRestartBackoffTimeStrategy: Allow tasks to restart a fixed number of times with a specified delay .
- FailureRateRestartBackoffTimeStrategy: Allow within a fixed failure frequency , Restart with a fixed delay .
- NoRestartBackoffTimeStrategy: No restart .
SchedulingStrategy: Task Execution instance scheduling policy
- EagerSchedulingStrategy: Hunger scheduling , Dispatch all at the same time Task.
- LazyFromSourcesSchedulingStrategy: When the consumed partition data is ready, it starts to schedule its follow-up Task, For batch tasks .
- PipelinedRegionSchedulingStrategy: With pipline Of the link Task For one Region, As its scheduling granularity .
2.2.2 Restart Task
private void maybeRestartTasks(final FailureHandlingResult failureHandlingResult) {
if (failureHandlingResult.canRestart()) {
restartTasksWithDelay(failureHandlingResult);
} else {
failJob(failureHandlingResult.getError());
}
}
private void restartTasksWithDelay(final FailureHandlingResult failureHandlingResult) {
final Set<ExecutionVertexID> verticesToRestart =
failureHandlingResult.getVerticesToRestart();
final Set<ExecutionVertexVersion> executionVertexVersions =
new HashSet<>(
executionVertexVersioner
.recordVertexModifications(verticesToRestart)
.values());
final boolean globalRecovery = failureHandlingResult.isGlobalFailure();
addVerticesToRestartPending(verticesToRestart);
// Cancel all that need to be restarted SubTask
final CompletableFuture<?> cancelFuture = cancelTasksAsync(verticesToRestart);
delayExecutor.schedule(
() ->
FutureUtils.assertNoException(
cancelFuture.thenRunAsync( // Restart after stopping
restartTasks(executionVertexVersions, globalRecovery),
getMainThreadExecutor())),
failureHandlingResult.getRestartDelayMS(),
TimeUnit.MILLISECONDS);
}
2.2.3 Cancel Task:
- Cancellation is waiting Slot The distribution of SubTask, If it is already in deployment / Running state , Notice is required TaskExecutor Perform the stop operation and wait for the operation to complete .
private CompletableFuture<?> cancelTasksAsync(final Set<ExecutionVertexID> verticesToRestart) {
// clean up all the related pending requests to avoid that immediately returned slot
// is used to fulfill the pending requests of these tasks
verticesToRestart.stream().forEach(executionSlotAllocator::cancel); // Cancellation may be waiting for allocation Slot Of SubTask
final List<CompletableFuture<?>> cancelFutures =
verticesToRestart.stream()
.map(this::cancelExecutionVertex) // Start to stop SubTask
.collect(Collectors.toList());
return FutureUtils.combineAll(cancelFutures);
}
public void cancel() {
while (true) {
// If the status change fails, try again
ExecutionState current = this.state;
if (current == CANCELING || current == CANCELED) {
// already taken care of, no need to cancel again
return;
}
else if (current == RUNNING || current == DEPLOYING) {
// The current status is set to CANCELING, And to TaskExecutor send out RPC Ask to stop SubTask
if (startCancelling(NUM_CANCEL_CALL_TRIES)) {
return;
}
} else if (current == FINISHED) {
// Even after running , You can't consume later , Release partition results
sendReleaseIntermediateResultPartitionsRpcCall();
return;
} else if (current == FAILED) {
return;
} else if (current == CREATED || current == SCHEDULED) {
// from here, we can directly switch to cancelled, because no task has been deployed
if (cancelAtomically()) {
return;
}
} else {
throw new IllegalStateException(current.name());
}
}
}
- After the operation, it will execute Task Exit process notification ExecutionGraph Perform the corresponding data update : ExecutionGraph.updateState(TaskExecutionStateTransition)->ExecutionGraph.updateStateInternal(TaskExecutionStateTransition, Execution) -> Execution.completeCancelling(…) -> Execution.finishCancellation(boolean) -> ExecutionGraph.deregisterExecution(Execution) . stay deregisterExecution The operation will be in currentExecutions Remove the stopped execution ExecutionTask.
2.2.4 Start Task
private Runnable restartTasks(
final Set<ExecutionVertexVersion> executionVertexVersions,
final boolean isGlobalRecovery) {
return () -> {
final Set<ExecutionVertexID> verticesToRestart =
executionVertexVersioner.getUnmodifiedExecutionVertices(
executionVertexVersions);
removeVerticesFromRestartPending(verticesToRestart);
// Instantiate a new SubTask Execution examples (Execution)
resetForNewExecutions(verticesToRestart);
try {
// Restore the state
restoreState(verticesToRestart, isGlobalRecovery);
} catch (Throwable t) {
handleGlobalFailure(t);
return;
}
// Start scheduling , apply Slot And deploy
schedulingStrategy.restartTasks(verticesToRestart);
};
}
边栏推荐
- DOMContentLoaded和window.onload
- Leetcode-02 (linked list question)
- “零售为王”下的家电产业:什么是行业共识?
- opencv环境的搭建,并打开一个本地PC摄像头。
- Introduction to ins/gps integrated navigation type
- 装饰设计企业网站管理系统源码(含手机版源码)
- 上个厕所的功夫,就把定时任务的三种调度策略说得明明白白
- Development of wireless communication technology, cv5200 long-distance WiFi module, UAV WiFi image transmission application
- 掘金量化:通过history方法获取数据,和新浪财经,雪球同用等比复权因子。不同于同花顺
- A complete tutorial for getting started with redis: AOF persistence
猜你喜欢

“零售为王”下的家电产业:什么是行业共识?
mos管實現主副電源自動切換電路,並且“零”壓降,靜態電流20uA

数学归纳与递归
Utilisation de la promesse dans es6
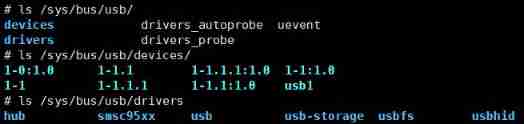
Analysis of USB network card sending and receiving data
![[secretly kill little partner pytorch20 days] - [Day1] - [example of structured data modeling process]](/img/f0/79e7915ba3ef32aa21c4a1d5f486bd.jpg)
[secretly kill little partner pytorch20 days] - [Day1] - [example of structured data modeling process]
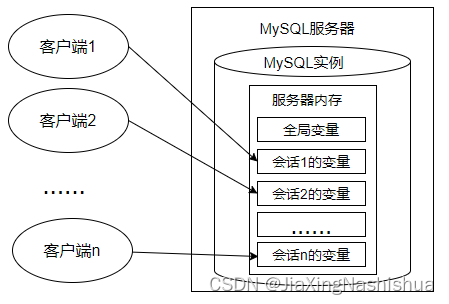
变量、流程控制与游标(MySQL)
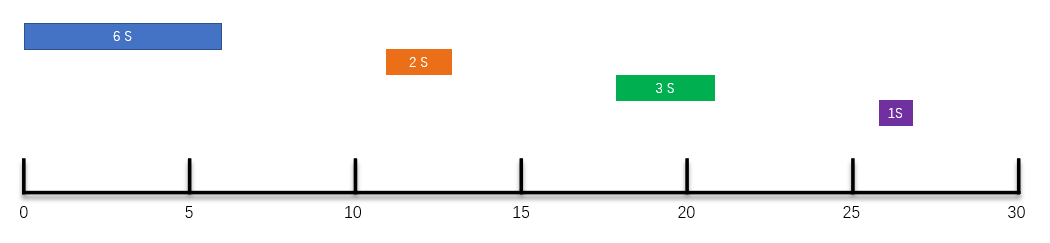
When you go to the toilet, you can clearly explain the three Scheduling Strategies of scheduled tasks
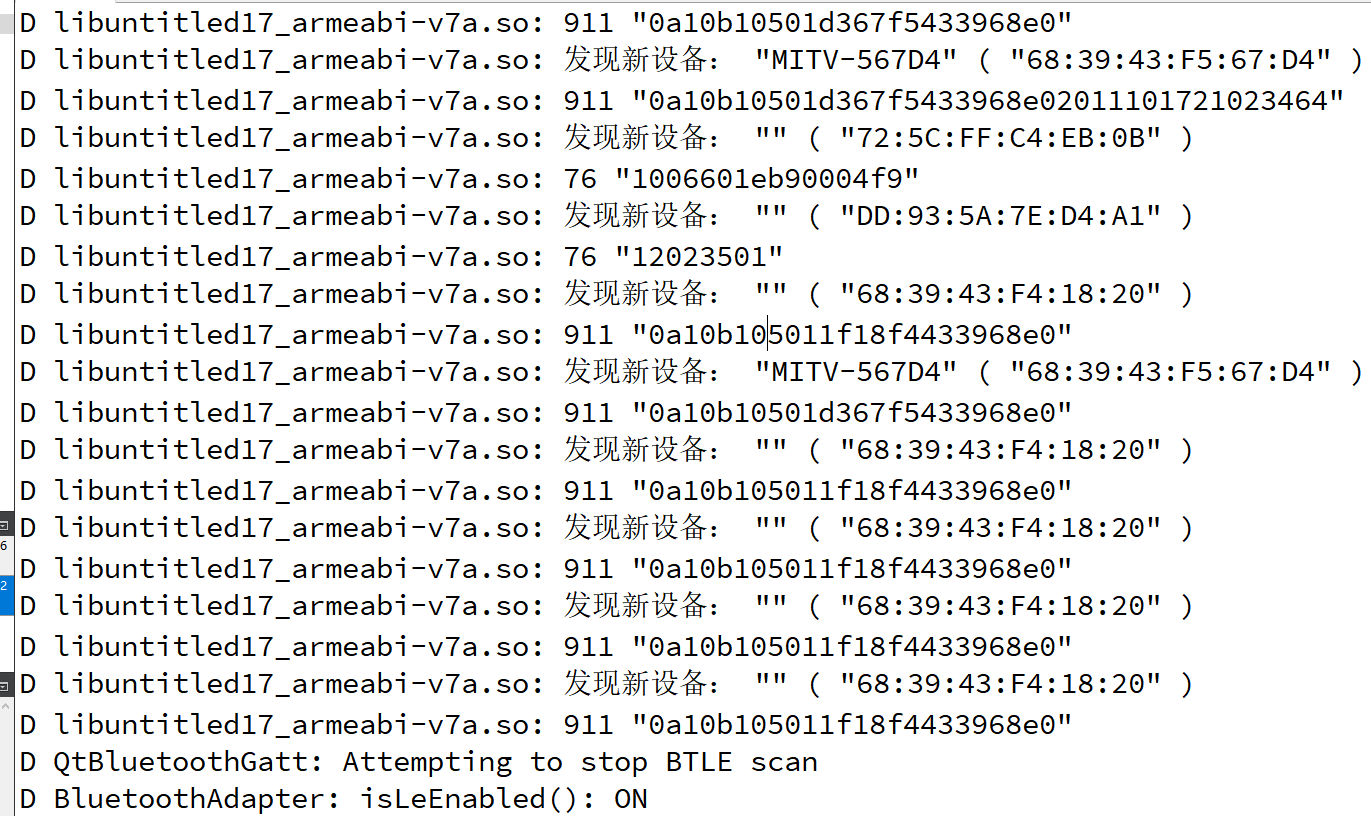
QT Bluetooth: qbluetooth DeviceInfo
Starting from 1.5, build a micro Service Framework -- log tracking traceid
随机推荐
input_ delay
Codeforces round 264 (Div. 2) C gargari and Bishop [violence]
Error: could not find a version that satisfies the requirement xxxxx (from versions: none) solutions
[socket] ① overview of socket technology
Es6中Promise的使用
【达梦数据库】备份恢复后要执行两个sql语句
Summary of research status of inertial navigation calibration at home and abroad (abridged version)
杰理之开启经典蓝牙 HID 手机的显示图标为键盘设置【篇】
Don't you know the relationship between JSP and servlet?
Jerry's question about DAC output power [chapter]
Matlab Error (Matrix dimensions must agree)
Redis getting started complete tutorial: replication configuration
c语言(字符串)如何把字符串中某个指定的字符删除?
sshd[12282]: fatal: matching cipher is not supported: aes256- [email protected] [preauth]
A complete tutorial for getting started with redis: AOF persistence
HMS Core 机器学习服务打造同传翻译新“声”态,AI让国际交流更顺畅
Cocos2d-x box2d physical engine compilation settings
The whole process of knowledge map construction
Do you know the five most prominent advantages of E-bidding?
[cpk-ra6m4 development board environment construction based on RT thread studio]