当前位置:网站首页>Construction of yolox based on paste framework
Construction of yolox based on paste framework
2022-07-06 05:43:00 【Python's path to immortality】
YOLOX Structure analysis and based on Paddle Network construction of
Ben Notebook Yes YOLOX The network structure of , And USES the PaddlePaddle Framework for YOLOX The network structure of .
notes : Ben Notebook Just discuss the building part of the network , Network training 、 The prediction process will follow NoteBook Have a discussion .
1. YOLOX brief introduction
YOLOX It's Kuangshi Technology (Megvii) stay YOLOv3 Improved on the basis of . The main improvements are Decoupled Head、Anchor Free、SimOTA、Data Aug. And for the sake of yolov5 contrast , Backbone network introduces yolov5 Of FOCUS、CSPNet、PAN Head、SiLU Activate .
1.1 Decoupled Head
Decoupled Head It is the standard configuration of a stage network in the academic field . However , The previous version of YOLO The prediction heads used are the same , Classification and regression are in one 1x1 Convolution .
The author found that End2End Of YOLOX Always better than the standard YOLOX low 4-5 A little bit , Accidentally put the original YOLO Head Switch to Decoupled Head, It is found that the gap has narrowed significantly , Think YOLO Head Your expressive ability may be lacking .
YOLOX in ,YOLO Head Realize classification and regression respectively , Only when the final prediction is made . After weighing the gains and losses of speed and performance , End use 1 individual 1x1 Convolution first reduces the dimension , And in the classification and regression branches 2 individual 3x3 Convolution .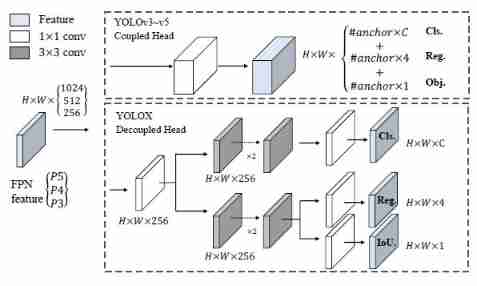
1.2 Anchor Free
Anchor Free There are several advantages :
- Reduce the cost of time
Anchor Based In order to pursue the best performance, the detector needs to anchor box Clustering analysis , Increased time cost .
- Reduce the complexity of detection head and the number of generated results
Anchor Based The detector increases the complexity of the detection head and the number of generated results , A large number of test results from GPU Carry to CPU It is intolerable for edge devices .
- The code logic is simple , Readability enhancements
Anchor Free The decoding code logic is simpler , More readable .
Anchor Free Technology can now be used YOLO, And the performance increases instead of decreasing , There is an inseparable connection with sample matching .
1.3 Sample matching SimOTA
Sample matching algorithm can naturally alleviate the problem of crowded scene detection 、 Alleviate the problem of poor detection effect of objects with extreme aspect ratio 、 Extreme size target positive sample imbalance problem 、 Alleviate the problem of poor detection effect of rotating objects .
The author believes that there are four important factors in sample matching :
- Loss/Quality/Prediction Aware
Calculate based on the prediction of the network itself anchor box perhaps anchor point And Groud Truth Match relationship , Fully consider different structures / Complexity models may behave differently , It is a kind of dynamic sample matching .
In contrast , be based on IoU threshold /In Grid(YOLOv1)/In Box or Center(FCOS) Both rely on artificially defining geometric priors to do sample matching , It belongs to the sub optimal scheme .
- Center prior
In most scenes , The center of mass of the target is related to the geometric center of the target , Limiting the positive samples to a certain area in the center of the target for sample matching can well solve the problem of unstable convergence .
- Dynamic k
For targets of different sizes, different numbers of positive samples should be set . Set the same number of positive samples for targets of different sizes , It will lead to a large number of low-quality positive samples for small targets or only a few positive samples for large targets .
Dynamic k The key is to determine k,k Can be estimated by prediction aware Of , The specific author first calculates the closest of each goal 10 Forecast , Then put this 10 A prediction and Groud Truth Of IOU Add up to get the final k.
Besides 10 This number is not very sensitive , stay 5-15 Adjustment between has little effect .
- Global information
part anchor box/point At the junction between positive samples 、 Or the boundary between positive and negative samples , This kind of anchor box/point Positive and negative division of , Which positive sample does it belong to , Should consider the overall information .
Final , Under the condition of weighing speed , The author only retains the first three points , Remove the optimal solution process , take OTA To SimOTA.
1.4 Data Augmentation
Data enhancement continues Mosaic and Mixup Data enhancement technology , Four pictures are spliced to realize the enhancement in the data , It enriches the background of the detected object .
Mosaic Method in YOLOv4 It is proposed that , The main idea is to cut the four pictures randomly , Then splice it into a picture as training data . The advantage is to enrich the picture background , And the four pictures are spliced together to improve in disguise batch_size, It's going on batch normalization Four pictures will also be calculated when , On itself batch_size Not very dependent on .
For details, please refer to the paper :YOLOv4: Optimal Speed and Accuracy of Object Detection
Mixup Methods a simple linear interpolation method was used to obtain the new extended data .
For details, please refer to the paper :mixup: Beyond Empirical Risk Minimization
2. Analysis of network structure
Reference resources B standing Up Lord Bubbliiiing Drawn network structure diagram , The whole network can be divided into three parts : Backbone network CSPDarknet、 Features enhanced PAN Head、 Detection head YOLO Head.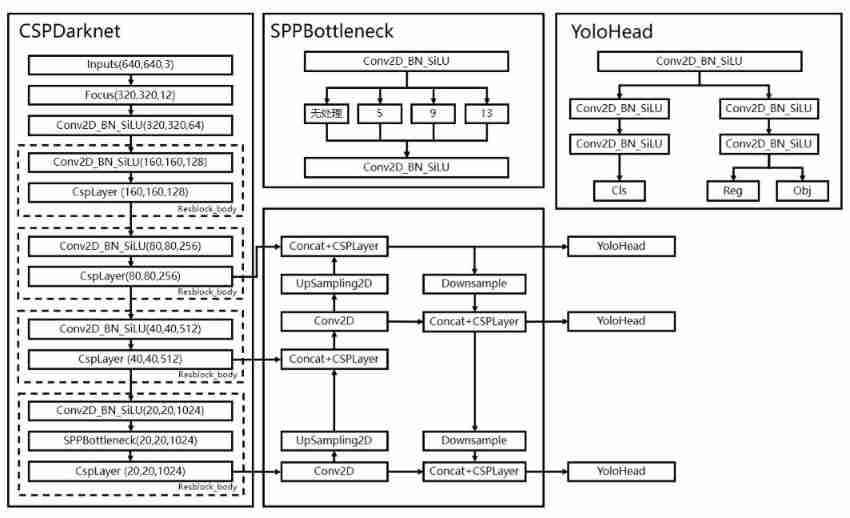
- The main structures involved in the backbone network include ConvBlock( contain Conv、Batch norm、SiLU)、FOCUS、CSPLayer、SPPBottleneck Isostructure .
- The main structures involved in the feature enhancement section include CSPLayer、UpSampling、DownSampling etc. .
- YOLO Head This part mainly includes ConvBlock structure .
Next, we will build the following parts one by one .
# Import and stock in
import paddle
from paddle import nn
2.1 Backbone network CSPDarknet
2.1.1 ConvBlock
The basic convolution block contains convolution 、 Batch normalization and activation functions . The basic convolution block is filled with equal size Same Padding, Contains general convolution (BaseConv) And depth separable convolution (DWConv) Two types of .
BaseConv Structure schematic
| Input |
|---|
| Conv2D |
| Batch Norm |
| Act |
Bottleneck Residual convolution block , Trunk adoption 2 Basic convolution block , The convolution kernel sizes are 1 and 3, The residual part keeps the original input , The sum of the result output trunk and the residual edge .
Bottleneck Structure schematic
| Input | |
|---|---|
| BaseConv 1x1 | Identity |
| BaseConv 3x3 | |
| Add | |
## Building convolution blocks
class BaseConv(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride, groups=1, act='silu'):
super().__init__()
padding = (kernel_size-1)//2
self.conv = nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding, groups=groups)
self.bn = nn.BatchNorm2D(out_channels,momentum=0.03, epsilon=0.001)
if act == 'silu':
self.act = nn.Silu()
elif act == 'relu':
self.act = nn.ReLU()
elif act == 'lrelu':
self.act = nn.LeakyReLU(0.1)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
## Construct deep separable convolution
class DWConv(nn.Layer):
# Some Problem
def __init__(self, in_channels, out_channels, kernel_size, stride=1, act='silu'):
super().__init__()
self.dconv = BaseConv(in_channels, in_channels, kernel_size, stride, groups=in_channels, act=act)
self.pconv = BaseConv(in_channels, out_channels, 1, 1, groups=1, act=act)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
## Build residual structure
class Bottleneck(nn.Layer):
def __init__(self, in_channels, out_channels, shortcut=True, expansion=0.5, depthwise=False, act="silu"):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
# 1x1 Convolution reduces the number of channels ( The reduction rate defaults to 50%)
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# 3x3 Convolution expands the number of channels ( feature extraction )
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
## Test convolution module
x = paddle.ones([1, 3, 640, 640])
conv1 = BaseConv(3, 64, 3, 1)
conv2 = DWConv(3, 64, 3, 1)
block1 = Bottleneck(3, 64)
print(conv1(x).shape)
print(conv2(x).shape)
print(block1(x).shape)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:653: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
[1, 64, 640, 640]
[1, 64, 640, 640]
[1, 64, 640, 640]
2.1.2 Focus
Focus As early as YOLOv5( No papers ) It is proposed that , The specific operation is to get a value every other pixel in a picture , Similar to adjacent down sampling , So you get four pictures , The four pictures complement each other , take W、H The information is concentrated in the channel space C, The input channel is expanded to 4 times , The stitched picture is relative to the original RGB The three channel mode becomes 12 Channels , Finally, the new image will be convoluted , Finally, the double down sampling characteristic map without information loss is obtained .
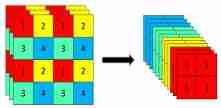
Focus The function is to speed up , The author mentioned the use of Focus Layer can reduce parameter calculation , Reduce Cuda Using memory .
## Focus layer
class Focus(nn.Layer):
def __init__(self, in_channels, out_channels, ksize=1, stride=1, act="silu"):
super().__init__()
self.conv = BaseConv(in_channels * 4, out_channels, ksize, stride, act=act)
def forward(self, x):
# respectively 4 individual 2 Times the sampling result
patch_1 = x[..., ::2, ::2]
patch_2 = x[..., 1::2, ::2]
patch_3 = x[..., ::2, 1::2]
patch_4 = x[..., 1::2, 1::2]
# Splice along the channel 4 Next sampling result
x = paddle.concat((patch_1, patch_2, patch_3, patch_4), axis=1)
# Convolution of splicing results
out = self.conv(x)
return out
## test FOCUS modular
x = paddle.ones([1, 3, 640, 640])
layer = Focus(3, 64)
print(layer(x).shape)
[1, 64, 320, 320]
2.1.3 CSPLayer
CSPLayer The main structure is shown in the figure below , On the basis of conventional structure , Introduce a branch similar to the residual structure .
The trunk part adopts 1 Basic convolution block + The stack N individual Bottleneck Residual block structure extraction feature , The residual part adopts 1 Basic convolution block , Finally, merge the two branches and act on the basic convolution block again .
CSPLayer Structure schematic
| Input | |
|---|---|
| BaseConv 1x1 | BaseConv 1x1 |
| Bottleneck(x N) | |
| Concat | |
| BaseConv 1x1 | |
## CSPLayer
class CSPLayer(nn.Layer):
def __init__(self, in_channels, out_channels, n=1, shortcut=True, expansion=0.5, depthwise=False, act="silu",):
super().__init__()
hidden_channels = int(out_channels * expansion)
# The basic convolution block of the trunk
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# Basic convolution block of residual edge part
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
# The basic convolution block after splicing the trunk and residual
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
# Build multiple residual block bottleneck structures according to the number of cycles
res_block = [Bottleneck(hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act) for _ in range(n)]
self.res_block = nn.Sequential(*res_block)
def forward(self, x):
# The main part
x_main = self.conv1(x)
x_main = self.res_block(x_main)
# Residual edge part
x_res = self.conv2(x)
# Stack the trunk part and the residual side part
x = paddle.concat((x_main, x_res), axis=1)
# Convolute the stacked results
out = self.conv3(x)
return out
## test CSPLayer modular
x = paddle.ones([1, 3, 640, 640])
layer = CSPLayer(3, 64, 5)
print(layer(x).shape)
[1, 64, 640, 640]
2.1.4 SPPBottleneck
SPPBottleneck The main structure is shown in the figure below , Use convolution block 1+4 Access road + Splicing + Convolution block 2 Overall structure .
Convolution block 1 Reduce the number of channels by half ;4 The down sampling of channels is the original input and the window size is 5,9,13 Maximum pooling of ; Splice along the channel ; Convolution block 2 Adjust the number of output channels .
SPPBottleneck Structure schematic
| Input | |||
|---|---|---|---|
| BaseConv 1x1 | |||
| Identity | MaxPool 5x5 | MaxPool 9x9 | MaxPool 13x13 |
| Concat | |||
| BaseConv 1x1 | |||
## SPPBottleneck
class SPPBottleneck(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.pool_block = nn.Sequential(*[nn.MaxPool2D(kernel_size=ks, stride=1, padding=ks // 2) for ks in kernel_sizes])
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = paddle.concat([x] + [pool(x) for pool in self.pool_block], axis=1)
x = self.conv2(x)
return x
## test SPPBottleneck modular
x = paddle.ones([1, 3, 640, 640])
layer = SPPBottleneck(3, 64)
print(layer(x).shape)
[1, 64, 640, 640]
2.1.5 CSPDarknet
CSPDarknet by YOLOX The backbone network of is used for network feature extraction , The result will output three feature layers ( Input is [3, 640, 640], The dimensions of the three feature layers are [256, 80, 80], [512, 40, 40], [1024, 20, 20]). Its main structure is shown in the figure below , The main blocks involved are Focus、BaseConv、CSPLayer、SPPBottleneck Are implemented above , Now assemble these parts :
CSPDarknet Structure schematic
| Input(-1, 3, 640, 640) | |||
|---|---|---|---|
| Focus | (-1, 12, 320, 320) | Stem | None |
| Conv | (-1, 64, 320, 320) | ||
| Conv | (-1, 128, 160, 160) | ResBlock1 | |
| CSPLayer | (-1, 128, 160, 160) | ||
| Conv | (-1, 256, 80, 80) | Resblock2 | |
| CSPLayer | (-1, 256, 80, 80) | feature[dark3] | |
| Conv | (-1, 512, 40, 40) | ResBlock3 | None |
| CSPLayer | (-1, 512, 40, 40) | feature[dark4] | |
| Conv | (-1, 1024, 20, 20) | ResBlock4 | None |
| SPPBottleneck | (-1, 1024, 20, 20) | ||
| CSPLayer | (-1, 1024, 20, 20) | feature[dark5] | |
## CSPDarknet
class CSPDarknet(nn.Layer):
def __init__(self, dep_mul, wid_mul, out_features=("dark3", "dark4", "dark5"), depthwise=False, act="silu",):
super().__init__()
assert out_features, "please provide output features of Darknet"
self.out_features = out_features
Conv = DWConv if depthwise else BaseConv
# Image Size : [3, 640, 640]
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
# utilize focus Network feature extraction
# [-1, 3, 640, 640] -> [-1, 64, 320, 320]
self.stem = Focus(3, base_channels, ksize=3, act=act)
# Resblock1[dark2]
# [-1, 64, 320, 320] -> [-1, 128, 160, 160]
self.dark2 = nn.Sequential(
Conv(base_channels, base_channels * 2, 3, 2, act=act),
CSPLayer(base_channels * 2, base_channels * 2, n=base_depth, depthwise=depthwise, act=act),
)
# Resblock2[dark3]
# [-1, 128, 160, 160] -> [-1, 256, 80, 80]
self.dark3 = nn.Sequential(
Conv(base_channels * 2, base_channels * 4, 3, 2, act=act),
CSPLayer(base_channels * 4, base_channels * 4, n=base_depth * 3, depthwise=depthwise, act=act),
)
# Resblock3[dark4]
# [-1, 256, 80, 80] -> [-1, 512, 40, 40]
self.dark4 = nn.Sequential(
Conv(base_channels * 4, base_channels * 8, 3, 2, act=act),
CSPLayer(base_channels * 8, base_channels * 8, n=base_depth * 3, depthwise=depthwise, act=act),
)
# Resblock4[dark5]
# [-1, 512, 40, 40] -> [-1, 1024, 20, 20]
self.dark5 = nn.Sequential(
Conv(base_channels * 8, base_channels * 16, 3, 2, act=act),
SPPBottleneck(base_channels * 16, base_channels * 16, activation=act),
CSPLayer(base_channels * 16, base_channels * 16, n=base_depth, shortcut=False, depthwise=depthwise, act=act),
)
def forward(self, x):
outputs = {
}
x = self.stem(x)
outputs["stem"] = x
x = self.dark2(x)
outputs["dark2"] = x
# dark3 Output feature layer :[256, 80, 80]
x = self.dark3(x)
outputs["dark3"] = x
# dark4 Output feature layer :[512, 40, 40]
x = self.dark4(x)
outputs["dark4"] = x
# dark5 Output feature layer :[1024, 20, 20]
x = self.dark5(x)
outputs["dark5"] = x
return {
k: v for k, v in outputs.items() if k in self.out_features}
## test CSPDarknet modular
x = paddle.ones([1, 3, 640, 640])
net1 = CSPDarknet(1, 1)
print(net1(x)['dark3'].shape, net1(x)['dark4'].shape, net1(x)['dark5'].shape)
[1, 256, 80, 80] [1, 512, 40, 40] [1, 1024, 20, 20]
2.2 Feature enhancement pyramid YOLOPAFPN
YOLOPAFPN by YOLOX The characteristics of the network strengthen the part , Integrated FPN and PANET. The three feature layers obtained from the backbone network are fused through multiple up sampling and down sampling , Combine the characteristic information of different scales .YOLOPAFPN The overall structure is as follows :
- The underlying characteristics [1024, 20, 20] Conduct 1 Time 1X1 Convolution is obtained after adjusting the channel P5 features [512, 20, 20],P5 Upsampling and middle-level features [512, 40, 40] Combine , And then use CSPLayer Feature extraction is carried out to obtain P5_upsample features [512, 40, 40].
- P5_upsample features [512, 40, 40] Conduct 1 Time 1X1 Convolution is obtained after adjusting the channel P4 features [256, 40, 40],P4 Perform up sampling and upper layer features [256, 80, 80] Combine , And then use CSPLayer Feature extraction P3_out features [256, 80, 80].
- P3_out features [256, 80, 80] Do it once. 3x3 Convolution down sampling , After down sampling, compare with P4 The stack , And then use CSPLayer Feature extraction P4_out features [512, 40, 40].
- P4_out features [512, 40, 40] Do it once. 3x3 Convolution down sampling , After down sampling, compare with P5 The stack , And then use CSPLayer Feature extraction P5_out features [1024, 20, 20].
YOLOPAFPN Structure schematic
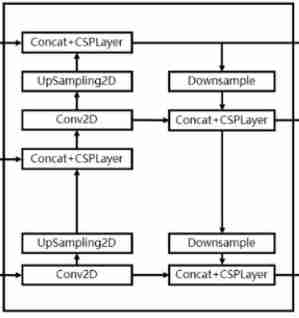
## YOLOPAFPN
class YOLOPAFPN(nn.Layer):
def __init__(self, depth = 1.0, width = 1.0, in_features = ("dark3", "dark4", "dark5"), in_channels = [256, 512, 1024], depthwise = False, act = "silu"):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.backbone = CSPDarknet(depth, width, depthwise = depthwise, act = act)
self.in_features = in_features
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
# [-1, 1024, 20, 20] -> [-1, 512, 20, 20]
self.lateral_conv0 = BaseConv(int(in_channels[2] * width), int(in_channels[1] * width), 1, 1, act=act)
# [-1, 1024, 40, 40] -> [-1, 512, 40, 40]
self.C3_p4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act
)
# [-1, 512, 40, 40] -> [-1, 256, 40, 40]
self.reduce_conv1 = BaseConv(int(in_channels[1] * width), int(in_channels[0] * width), 1, 1, act=act)
# [-1, 512, 80, 80] -> [-1, 256, 80, 80]
self.C3_p3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[0] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act
)
# Bottom-Up Conv
# [-1, 256, 80, 80] -> [-1, 256, 40, 40]
self.bu_conv2 = Conv(int(in_channels[0] * width), int(in_channels[0] * width), 3, 2, act=act)
# [-1, 512, 40, 40] -> [-1, 512, 40, 40]
self.C3_n3 = CSPLayer(
int(2 * in_channels[0] * width),
int(in_channels[1] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act
)
# [-1, 512, 40, 40] -> [-1, 512, 20, 20]
self.bu_conv1 = Conv(int(in_channels[1] * width), int(in_channels[1] * width), 3, 2, act=act)
# [-1, 1024, 20, 20] -> [-1, 1024, 20, 20]
self.C3_n4 = CSPLayer(
int(2 * in_channels[1] * width),
int(in_channels[2] * width),
round(3 * depth),
False,
depthwise = depthwise,
act = act
)
def forward(self, input):
out_features = self.backbone(input)
[feat1, feat2, feat3] = [out_features[f] for f in self.in_features]
# [-1, 1024, 20, 20] -> [-1, 512, 20, 20]
P5 = self.lateral_conv0(feat3)
# [-1, 512, 20, 20] -> [-1, 512, 40, 40]
P5_upsample = self.upsample(P5)
# [-1, 512, 40, 40] + [-1, 512, 40, 40] -> [-1, 1024, 40, 40]
P5_upsample = paddle.concat([P5_upsample, feat2], axis=1)
# [-1, 1024, 40, 40] -> [-1, 512, 40, 40]
P5_upsample = self.C3_p4(P5_upsample)
# [-1, 512, 40, 40] -> [-1, 256, 40, 40]
P4 = self.reduce_conv1(P5_upsample)
# [-1, 256, 40, 40] -> [-1, 256, 80, 80]
P4_upsample = self.upsample(P4)
# [-1, 256, 80, 80] + [-1, 256, 80, 80] -> [-1, 512, 80, 80]
P4_upsample = paddle.concat([P4_upsample, feat1], axis=1)
# [-1, 512, 80, 80] -> [-1, 256, 80, 80]
P3_out = self.C3_p3(P4_upsample)
# [-1, 256, 80, 80] -> [-1, 256, 40, 40]
P3_downsample = self.bu_conv2(P3_out)
# [-1, 256, 40, 40] + [-1, 256, 40, 40] -> [-1, 512, 40, 40]
P3_downsample = paddle.concat([P3_downsample, P4], axis=1)
# [-1, 512, 40, 40] -> [-1, 512, 40, 40]
P4_out = self.C3_n3(P3_downsample)
# [-1, 512, 40, 40] -> [-1, 512, 20, 20]
P4_downsample = self.bu_conv1(P4_out)
# [-1, 512, 20, 20] + [-1, 512, 20, 20] -> [-1, 1024, 20, 20]
P4_downsample = paddle.concat([P4_downsample, P5], axis=1)
# [-1, 1024, 20, 20] -> [-1, 1024, 20, 20]
P5_out = self.C3_n4(P4_downsample)
return (P3_out, P4_out, P5_out)
## test YOLOPAFPN modular
features = paddle.ones([1, 256, 80, 80]), paddle.ones([1, 512, 40, 40]), paddle.ones([1, 1024, 20, 20])
net2 = YOLOPAFPN()
print(net2(x)[0].shape, net2(x)[1].shape, net2(x)[2].shape)
[1, 256, 80, 80] [1, 512, 40, 40] [1, 1024, 20, 20]
2.3 Detection head YOLOX Head
YOLOX Head when YOLOX Network detection head , At the same time, it plays the role of classifier and regressor , Compared to traditional yolo Detection head ,yolox head The detection head is decoupled , Classification and regression are divided into two branches for processing , Finally, the integration will be carried out at the time of prediction , Strengthen the recognition ability of the network .
YOLOX Head Structure schematic
## YOLOX Head
class YOLOXHead(nn.Layer):
def __init__(self, num_classes, width = 1.0, in_channels = [256, 512, 1024], act = "silu", depthwise = False,):
super().__init__()
Conv = DWConv if depthwise else BaseConv
self.cls_convs = []
self.reg_convs = []
self.cls_preds = []
self.reg_preds = []
self.obj_preds = []
self.stems = []
for i in range(len(in_channels)):
# Preprocessing convolution : 1 individual 1x1 Convolution
self.stems.append(BaseConv(in_channels = int(in_channels[i] * width), out_channels = int(256 * width), kernel_size = 1, stride = 1, act = act))
# Classification feature extraction : 2 individual 3x3 Convolution
self.cls_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), kernel_size= 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), kernel_size= 3, stride = 1, act = act),
]))
# Classified forecast : 1 individual 1x1 Convolution
self.cls_preds.append(
nn.Conv2D(in_channels = int(256 * width), out_channels = num_classes, kernel_size = 1, stride = 1, padding = 0)
)
# Regression feature extraction : 2 individual 3x3 Convolution
self.reg_convs.append(nn.Sequential(*[
Conv(in_channels = int(256 * width), out_channels = int(256 * width), kernel_size = 3, stride = 1, act = act),
Conv(in_channels = int(256 * width), out_channels = int(256 * width), kernel_size = 3, stride = 1, act = act)
]))
# Regression prediction ( Location ): 1 individual 1x1 Convolution
self.reg_preds.append(
nn.Conv2D(in_channels = int(256 * width), out_channels = 4, kernel_size = 1, stride = 1, padding = 0)
)
# Regression prediction ( Whether it contains objects ): 1 individual 1x1 Convolution
self.obj_preds.append(
nn.Conv2D(in_channels = int(256 * width), out_channels = 1, kernel_size = 1, stride = 1, padding = 0)
)
def forward(self, inputs):
# Input [P3_out, P4_out, P5_out]
# P3_out: [-1, 256, 80, 80]
# P4_out: [-1, 512, 40, 40]
# P5_out: [-1, 1024, 20, 20]
outputs = []
for k, x in enumerate(inputs):
# 1x1 Convolution channel integration
x = self.stems[k](x)
# 2 individual 3x3 Convolution feature extraction
cls_feat = self.cls_convs[k](x)
# 1 individual 1x1 Convolution prediction category
# Output, respectively, : [-1, num_classes, 80, 80], [-1, num_classes, 40, 40], [-1, num_classes, 20, 20]
cls_output = self.cls_preds[k](cls_feat)
# 2 individual 3x3 Convolution feature extraction
reg_feat = self.reg_convs[k](x)
# 1 individual 1x1 Convolution prediction position
# Output, respectively, : [-1, 4, 80, 80], [-1, 4, 40, 40], [-1, 4, 20, 20]
reg_output = self.reg_preds[k](reg_feat)
# 1 individual 1x1 Convolution predicts whether there is an object
# Output, respectively, : [-1, 1, 80, 80], [-1, 1, 40, 40], [-1, 1, 20, 20]
obj_output = self.obj_preds[k](reg_feat)
# Integration results
# Output : [-1, num_classes+5, 80, 80], [-1, num_classes+5, 40, 40], [-1, num_classes+5, 20, 20]
output = paddle.concat([reg_output, obj_output, cls_output], 1)
outputs.append(output)
return outputs
## test YOLOX Head modular
features = paddle.ones([1, 256, 80, 80]), paddle.ones([1, 512, 40, 40]), paddle.ones([1, 1024, 20, 20])
net3 = YOLOXHead(10)
print(net3(features)[0].shape, net3(features)[1].shape, net3(features)[2].shape)
[1, 15, 80, 80] [1, 15, 40, 40] [1, 15, 20, 20]
2.4 Structural integration YOLO Body
class YoloBody(nn.Layer):
def __init__(self, num_classes, kind):
super().__init__()
depth_dict = {
'nano': 0.33, 'tiny': 0.33, 's' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,}
width_dict = {
'nano': 0.25, 'tiny': 0.375, 's' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,}
depth, width = depth_dict[kind], width_dict[kind]
depthwise = True if kind == 'nano' else False
self.backbone = YOLOPAFPN(depth, width, depthwise=depthwise)
self.head = YOLOXHead(num_classes, width, depthwise=depthwise)
def forward(self, x):
fpn_outs = self.backbone.forward(x)
outputs = self.head.forward(fpn_outs)
return outputs
## test YOLO Body modular
x = paddle.ones([1, 3, 640, 640])
net4 = YoloBody(10, 'x')
print(net4(x)[0].shape, net4(x)[1].shape, net4(x)[2].shape)
[1, 15, 80, 80] [1, 15, 40, 40] [1, 15, 20, 20]
Please click on here Check the basic usage of this environment .
Please click here for more detailed instructions.
边栏推荐
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- 备忘一下jvxetable的各种数据集获取方法
- Self built DNS server, the client opens the web page slowly, the solution
- 03. 开发博客项目之登录
- Go language -- language constants
- Li Chuang EDA learning notes 12: common PCB board layout constraint principles
- 【SQL server速成之路】——身份驗證及建立和管理用戶賬戶
- Application Security Series 37: log injection
- Jvxetable implant j-popup with slot
猜你喜欢
Rustdesk builds its own remote desktop relay server
Summary of deep learning tuning tricks
Migrate Infones to stm32

29io stream, byte output stream continue write line feed
【云原生】3.1 Kubernetes平台安装KubeSpher

First knowledge database
[SQL Server fast track] - authentication and establishment and management of user accounts
B站刘二大人-反向传播
03. 开发博客项目之登录
05. 博客项目之安全
![[SQL Server fast track] - authentication and establishment and management of user accounts](/img/42/c1def031ec126a793195ebc881081e)
随机推荐
Note the various data set acquisition methods of jvxetable
Promise summary
Auto. JS learning notes 17: basic listening events and UI simple click event operations
Classes and objects (I) detailed explanation of this pointer
04. Project blog log
Garbage collector with serial, throughput priority and response time priority
Embedded interview questions (IV. common algorithms)
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
初识CDN
Sequoiadb Lake warehouse integrated distributed database, June 2022 issue
数字经济破浪而来 ,LTD是权益独立的Web3.0网站?
Application Security Series 37: log injection
[JVM] [Chapter 17] [garbage collector]
[Tang Laoshi] C -- encapsulation: classes and objects
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Closure, decorator
ArcGIS application foundation 4 thematic map making
【torch】|torch. nn. utils. clip_ grad_ norm_
Station B, Master Liu Er - back propagation
大型网站如何选择比较好的云主机服务商?