当前位置:网站首页>Crawler series of learning while tapping (3): URL de duplication strategy and Implementation
Crawler series of learning while tapping (3): URL de duplication strategy and Implementation
2022-07-06 15:19:00 【Jane said Python】
One 、 Preface
What I want to share with you today is ,Python In reptiles url De duplication strategy and implementation .

Two 、url Weight removal and strategy introduction
1.url duplicate removal
Literally ,url De duplication means removing duplicate url, In reptiles, it is to remove what has been crawled url, Avoid repeated crawling , It affects the efficiency of reptiles , And generate redundant data .
2.url De duplication strategy
On the face of it ,url The de duplication strategy is to eliminate url Repeat the method , common url There are five weight removal strategies , as follows :
# 1. Will visit ur Save to the database
# 2. Will visit ur Save to set( aggregate ) in , It only needs o(1) The price can be inquired url
# 10000000*2byte*50 Characters /1024/1024/1024=9G
# 3.url after md5 Wait for the method to hash and save to set in
# 4. use bitmap Method , Will visit ur adopt hash Function maps to a bit
# 5. bloomfilter Method pair bitmap Improvement , multiple hash Function to reduce conflicts 3、 ... and 、 Look at the code , Learn while knocking and remember
1. Will visit ur Save to the database ( Learning how to use )
It's the easiest thing to do , But it's the least efficient .
The central idea is this , Crawl the page to every url Store in database , To avoid repetition , Before each storage, you need to traverse and query whether the current... Already exists in the database url( That is, whether it has been crawled ), If exist , Then do not save , otherwise , Save the current url, Continue to save the next , Until the end .
2. Will visit ur Save to set In the memory
Will visit ur Save to set in , It only needs o(1) The price can be inquired url, take url Convenient and quick , Basically, there is no need to query , But with the storage url More and more , It's going to take up more and more memory .
# Simple calculation : Suppose there is 1 Billion bars url, Every url The average length is 50 Characters ,python in unicode code , Each character 16 position , Occupy 2
# Bytes (byte)
# Calculation formula :10^8 x 50 Characters x 2 individual byte / 1024 / 1024 / 1024 = 9G
# B M G
If it is 2 One hundred million url, Then the occupied memory will reach 18G, It's not particularly convenient , Suitable for small reptiles .3.url after md5 Reduce to a fixed length
''' Simple calculation : One url the MD5 transformation , To become a 128bit( position ) String , Occupy 16byte( byte ), One of method two url Conservative estimation Accounted for 50 Characters x 2 = 100byte( byte ), Calculation formula : Such a comparison ,MD5 The space saving rate is :(100-16)/100 = 84%( Compared with method 2 ) (Scrapy frame url Weight removal is a similar method ) '''
# Look at Wikipedia MD5 Algorithm
''' MD5 summary Designer : Ronald · Levister First release : 1992 year 4 month series : MD, MD2, MD3, MD4, MD5 Code length : 128 position structure : Merkle–Damgård construction MD5 Message digest algorithm ( English :MD5 Message-Digest Algorithm), A widely used cryptographic hash function , can To produce a 128 position (16 byte ) Hash value (hash value), Used to ensure complete and consistent transmission of information .MD5 By American cryptographer Ronald · Levister (Ronald Linn Rivest) Design , On 1992 Open in , To replace MD4 Algorithm . The program of this algorithm is in RFC 1321 To be regulated . Put the data ( Like a paragraph of text ) The operation changes to another fixed length value , Is the basic principle of hash algorithm . '''MD5 Using examples :
# stay python3 Use in hashlib The module carries out md5 operation
import hashlib
# Information to be encrypted
str01 = 'This is your md5 password!'
# establish md5 object
md5_obj = hashlib.md5()
# Conduct MD5 Before encryption, you must encode( code ),python The default is unicode code , Must be converted to utf-8
# Otherwise, the report will be wrong :TypeError: Unicode-objects must be encoded before hashing
md5_obj.update(str01.encode(encoding='utf-8'))
print('XksA The original words are :' + str01)
print('MD5 Encrypted as :' + md5_obj.hexdigest())
# result :
# XksA The original words are :This is your md5 password!
# MD5 Encrypted as :0a5f76e7b0f352e47fed559f904c91594. use bitmap Method , Will visit ur adopt hash Function maps to a bit
''' Realization principle : adopt hash function , Each one url Map to a hash In position , One hash Bits can occupy only one bit( position ) size , that Relative to method three : One url Occupy 128bit( position ),hash The space saving of function method is increased hundreds of times . Calculation formula : Such a comparison ,bitmap The space saving rate of the method is : (128-1)/128= 99.2%( Compared with method 3 ) (100 * 8 - 1)/(100*8)= 99.88%( Compared to method one ) ## ( shortcoming : It's prone to conflict ) ## '''
# Look at Wikipedia Hash function
''' hash function : Hash function ( English :Hash function) Also known as hash algorithm 、 hash function , It's about creating small numbers from any kind of data “ The fingerprint ” Methods . Hash functions compress messages or data into digests , Make the amount of data smaller , Fix the format of the data . This function scrambles the data close , Recreate a value called hash (hash values,hash codes,hash sums, or hashes) The fingerprints of . Hash values are usually Use a short string of random letters and numbers to represent . Good hash functions rarely have hash conflicts in the input field . In hash table and number According to the processing , Don't suppress conflicts to differentiate data , It makes database records more difficult to find . '''5.bloomfilter Method pair bitmap Improvement , multiple hash Function to reduce conflicts
# Look at Wikipedia Bloomfilter
''' # Basic overview If you want to determine whether an element is in a set , The general idea is to save all the elements in the collection , And then through comparison to determine . Linked list 、 Trees 、 Hash table ( Also called hash table ,Hash table) And so on, the data structure is this way of thinking . But as the number of elements in the collection increases , We need more and more storage space . At the same time, the retrieval speed is getting slower and slower , The retrieval time complexity of the above three structures are respectively : O(n),O(log n),O(n/k) # Principle overview The principle of Bloom filter is , When an element is added to a collection , adopt K Hash functions map this element to... In a group of bits K individual spot , Set them as 1. Search time , We just need to see if these points are all 1 Just ( about ) Know if it's in the collection : If these points Any one of them 0, The inspected element must not be in ; If it's all 1, Then the inspected element is likely to be . This is the basic idea of bloon filter . # Advantages and disadvantages The bloom filter can be used to retrieve whether an element is in a collection . The advantage is that the space efficiency and query time are much higher than those of general algorithms . The disadvantage is that it has certain error recognition rate and deletion difficulty . '''
# Bloomfilter You can also see the introduction here :https://blog.csdn.net/preyta/article/details/72804148Bloomfilter Underlying implementation :
# Source code address :https://github.com/preytaren/fastbloom/blob/master/fastbloom/bloomfilter.py
import math
import logging
import functools
import pyhash
from bitset import MmapBitSet
from hash_tools import hashes
class BloomFilter(object):
""" A bloom filter implementation, which use Murmur hash and Spooky hash """
def __init__(self, capacity, error_rate=0.0001, fname=None, h1=pyhash.murmur3_x64_128(), h2=pyhash.spooky_128()):
""" :param capacity: size of possible input elements :param error_rate: posi :param fname: :param h1: :param h2: """
# calculate m & k
self.capacity = capacity
self.error_rate = error_rate
self.num_of_bits, self.num_of_hashes = self._adjust_param(4096 * 8,
error_rate)
self._fname = fname
self._data_store = MmapBitSet(self.num_of_bits)
self._size = len(self._data_store)
self._hashes = functools.partial(hashes, h1=h1, h2=h2, number=self.num_of_hashes)
def _adjust_param(self, bits_size, expected_error_rate):
""" adjust k & m through 4 steps: 1. Choose a ballpark value for n 2. Choose a value for m 3. Calculate the optimal value of k 4. Calculate the error rate for our chosen values of n, m, and k. If it's unacceptable, return to step 2 and change m; otherwise we're done. in every loop, m = m * 2 :param bits_size: :param expected_error_rate: :return: """
n, estimated_m, estimated_k, error_rate = self.capacity, int(bits_size / 2), None, 1
weight, e = math.log(2), math.exp(1)
while error_rate > expected_error_rate:
estimated_m *= 2
estimated_k = int((float(estimated_m) / n) * weight) + 1
error_rate = (1 - math.exp(- (estimated_k * n) / estimated_m)) ** estimated_k
logging.info(estimated_m, estimated_k, error_rate)
return estimated_m, estimated_k
def add(self, msg):
""" add a string to bloomfilter :param msg: :return: """
if not isinstance(msg, str):
msg = str(msg)
positions = []
for _hash_value in self._hashes(msg):
positions.append(_hash_value % self.num_of_bits)
for pos in sorted(positions):
self._data_store.set(int(pos))
@staticmethod
def open(self, fname):
with open(fname) as fp:
raise NotImplementedError
def __str__(self):
""" output bitset directly :return: """
pass
def __contains__(self, msg):
if not isinstance(msg, str):
msg = str(msg)
positions = []
for _hash_value in self._hashes(msg):
positions.append(_hash_value % self.num_of_bits)
for position in sorted(positions):
if not self._data_store.test(position):
return False
return True
def __len__(self):
return self._sizeFour 、 an account of happenings after the event being told
Finish this period , I think , It's time to pick up the advanced mathematics book , Line generation book , probability theory , Discrete Mathematics … Study math well , Ha ha ha !
Complimentary gift : Happy Chinese Valentine's day, everyone .
Welcome to WeChat official account. : The minimalist XksA, obtain Python/Java/ Front end and other learning resources !

边栏推荐
- ucore lab5用户进程管理 实验报告
- 基于485总线的评分系统双机实验报告
- Video scrolling subtitle addition, easy to make with this technique
- Leetcode simple question: check whether two strings are almost equal
- Stc-b learning board buzzer plays music 2.0
- Cadence physical library lef file syntax learning [continuous update]
- [issue 18] share a Netease go experience
- Brief description of compiler optimization level
- Threads et pools de threads
- 几款开源自动化测试框架优缺点对比你知道吗?
猜你喜欢
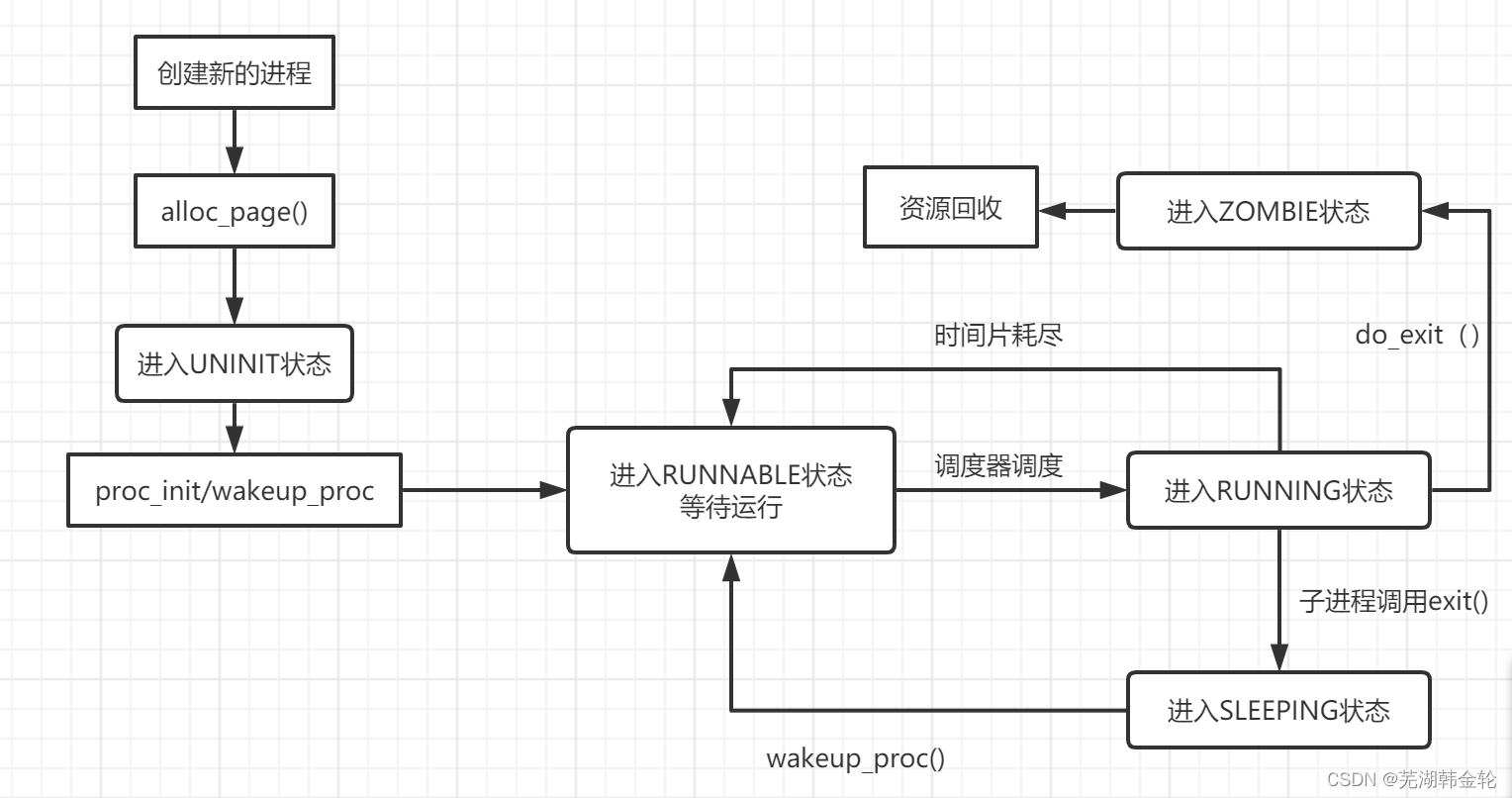
UCORE lab5 user process management experiment report

C4D quick start tutorial - creating models
What if software testing is too busy to study?
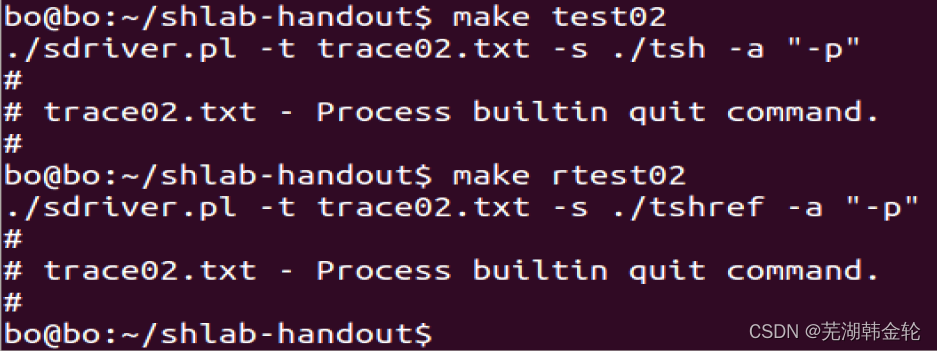
CSAPP shell lab experiment report
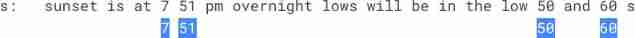
Leetcode simple question: check whether the numbers in the sentence are increasing
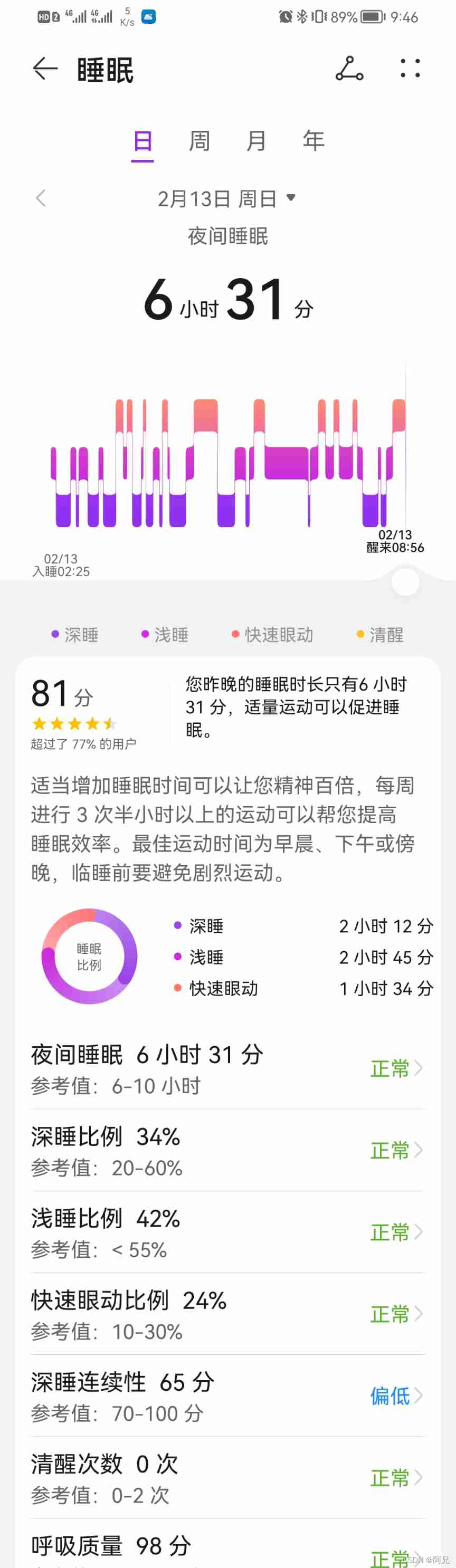
Sleep quality today 81 points
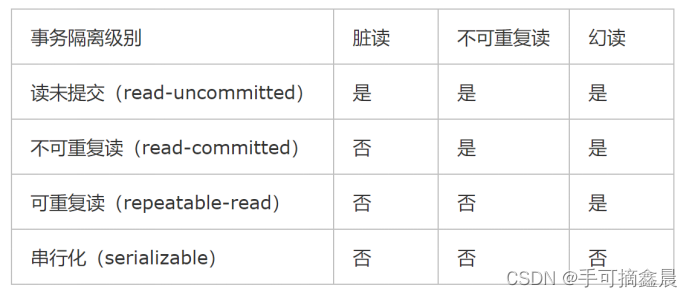
MySQL数据库(四)事务和函数
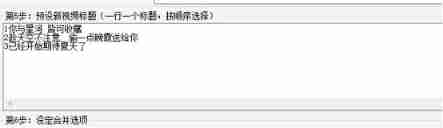
Nest and merge new videos, and preset new video titles
软件测试行业的未来趋势及规划

The maximum number of words in the sentence of leetcode simple question


随机推荐
Video scrolling subtitle addition, easy to make with this technique
Investment should be calm
Global and Chinese markets of Iam security services 2022-2028: Research Report on technology, participants, trends, market size and share
The number of reversing twice in leetcode simple question
How to rename multiple folders and add unified new content to folder names
Servlet
Example 071 simulates a vending machine, designs a program of the vending machine, runs the program, prompts the user, enters the options to be selected, and prompts the selected content after the use
Expanded polystyrene (EPS) global and Chinese markets 2022-2028: technology, participants, trends, market size and share Research Report
Cc36 different subsequences
想跳槽?面试软件测试需要掌握的7个技能你知道吗
Face and eye recognition based on OpenCV's own model
Rearrange spaces between words in leetcode simple questions
Mysql database (V) views, stored procedures and triggers
How to use Moment. JS to check whether the current time is between 2 times
C language do while loop classic Level 2 questions
Servlet
Description of Vos storage space, bandwidth occupation and PPS requirements
Interface test interview questions and reference answers, easy to grasp the interviewer
Stc-b learning board buzzer plays music
MySQL development - advanced query - take a good look at how it suits you