当前位置:网站首页>Lab 8 文件系统
Lab 8 文件系统
2022-07-06 09:25:00 【湖大金胜宇】
Lab 8 文件系统
实验目的
通过完成本次实验,希望能达到以下目标
- 了解基本的文件系统系统调用的实现方法;
- 了解一个基于索引节点组织方式的Simple FS文件系统的设计与实现;
- 了解文件系统抽象层-VFS的设计与实现;
实验内容
实验七完成了在内核中的同步互斥实验。本次实验涉及的是文件系统,通过分析了解ucore文件系统的总体架构设计,完善读写文件操作,从新实现基于文件系统的执行程序机制(即改写do_execve),从而可以完成执行存储在磁盘上的文件和实现文件读写等功能。
练习
对实验报告的要求:
- 基于markdown格式来完成,以文本方式为主
- 填写各个基本练习中要求完成的报告内容
- 完成实验后,请分析ucore_lab中提供的参考答案,并请在实验报告中说明你的实现与参考答案的区别
- 列出你认为本实验中重要的知识点,以及与对应的OS原理中的知识点,并简要说明你对二者的含义,关系,差异等方面的理解(也可能出现实验中的知识点没有对应的原理知识点)
- 列出你认为OS原理中很重要,但在实验中没有对应上的知识点
练习0:填写已有实验
本实验依赖实验1/2/3/4/5/6/7。请把你做的实验1/2/3/4/5/6/7的代码填入本实验中代码中有“LAB1”/“LAB2”/“LAB3”/“LAB4”/“LAB5”/“LAB6”
/“LAB7”的注释相应部分。并确保编译通过。注意:为了能够正确执行lab8的测试应用程序,可能需对已完成的实验1/2/3/4/5/6/7的代码进行进一步改进。
使用meld软件将lab7和lab8文件夹进行比较:
发现以下文件需要复制:
- proc.c
- default_pmm.c
- pmm.c
- swap_fifo.c
- vmm.c
- trap.c
- sche.c
- monitor.c
- check_sync.c
- kdebug.c
其余文件不用修改,直接使用即可。
练习1: 完成读文件操作的实现(需要编码)
首先了解打开文件的处理流程,然后参考本实验后续的文件读写操作的过程分析,编写在sfs_inode.c中sfs_io_nolock读文件中数据的实现代码。
请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
UNIX文件系统
UNIX提出了四个文件系统抽象概念:文件(file)、目录项(dentry)、索引节点(inode)和安装点(mount point):
- 文件:UNIX文件中的内容可理解为是一有序字节buffer,文件都有一个方便应用程序识别的文件名 称(也称文件路径名)。典型的文件操作有读、写、创建和删除等。
- 目录项:目录项不是目录(又称文件路径),而是目录的组成部分。在UNIX中目录被看作一种特 定的文件,而目录项是文件路径中的一部分。如一个文件路径名是“/test/testfile”,则包含的目录 项为:根目录“/”,目录“test”和文件“testfile”,这三个都是目录项。一般而言,目录项包含目录项 的名字(文件名或目录名)和目录项的索引节点(见下面的描述)位置。
- 索引节点:UNIX将文件的相关元数据信息(如访问控制权限、大小、拥有者、创建时间、数据内 容等等信息)存储在一个单独的数据结构中,该结构被称为索引节点。
- 安装点:在UNIX中,文件系统被安装在一个特定的文件路径位置,这个位置就是安装点。所有的 已安装文件系统都作为根文件系统树中的叶子出现在系统中。
上述抽象概念形成了UNIX文件系统的逻辑数据结构,并需要通过一个具体文件系统的架构设计与实现把 上述信息映射并储存到磁盘介质上,从而在具体文件系统的磁盘布局(即数据在磁盘上的物理组织)上 具体体现出上述抽象概念。比如文件元数据信息存储在磁盘块中的索引节点上。当文件被载入内存时, 内核需要使用磁盘块中的索引点来构造内存中的索引节点。
ucore文件系统
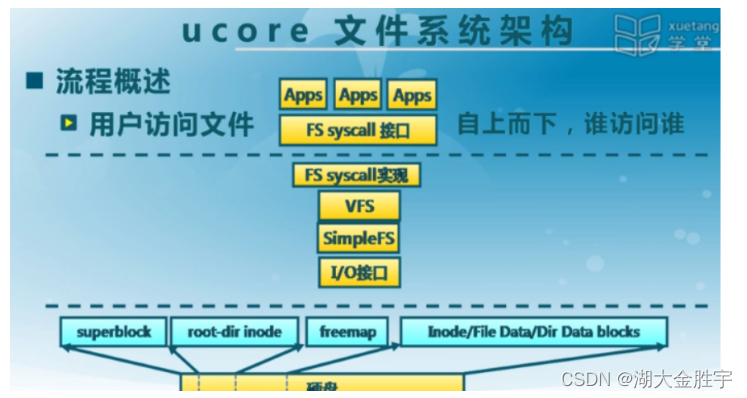
ucore模仿了UNIX的文件系统设计,ucore的文件系统架构主要由四部分组成:
- 通用文件系统访问接口层:该层提供了一个从用户空间到文件系统的标准访问接口。这一层访问接口让应用程序能够通过一个简单的接口获得ucore内核的文件系统服务。
- 文件系统抽象层:向上提供一个一致的接口给内核其他部分(文件系统相关的系统调用实现模块和其他内核功能模块)访问。向下提供一个同样的抽象函数指针列表和数据结构屏蔽不同文件系统的实现细节。
- Simple FS文件系统层:一个基于索引方式的简单文件系统实例。向上通过各种具体函数实现以对应文件系统抽象层提出的抽象函数。向下访问外设接口
- 外设接口层:向上提供device访问接口屏蔽不同硬件细节。向下实现访问各种具体设备驱动的接口,比如disk设备接口/串口设备接口/键盘设备接口等。
对照上面的层次我们再大致介绍一下文件系统的访问处理过程,加深对文件系统的总体理解。
假如应用程序操作文件(打开/创建/删除/读写),首先需要通过文件系统的通用文件系统访问接口层给 用户空间提供的访问接口进入文件系统内部,接着由文件系统抽象层把访问请求转发给某一具体文件系 统(比如SFS文件系统),具体文件系统(Simple FS文件系统层)把应用程序的访问请求转化为对磁盘 上的block的处理请求,并通过外设接口层交给磁盘驱动例程来完成具体的磁盘操作。结合用户态写文件 函数write的整个执行过程,我们可以比较清楚地看出ucore文件系统架构的层次和依赖关系
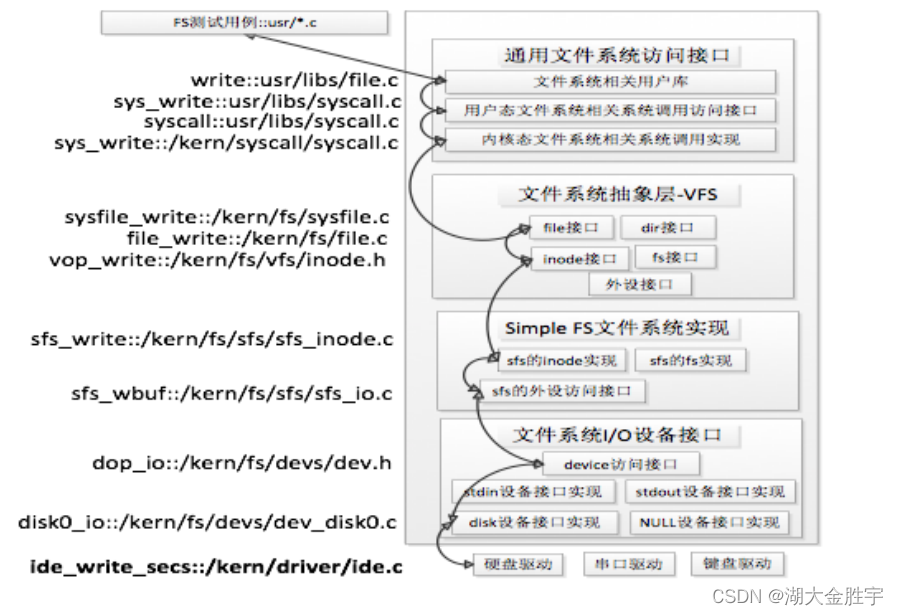
ucore文件系统总体结构
从ucore操作系统不同的角度来看,ucore中的文件系统架构包含四类主要的数据结构, 它们分别是:
- 超级块(SuperBlock),它主要从文件系统的全局角度描述特定文件系统的全局信息。它的作用范 围是整个OS空间。
- 索引节点(inode):它主要从文件系统的单个文件的角度它描述了文件的各种属性和数据所在位 置。它的作用范围是整个OS空间。
- 目录项(dentry):它主要从文件系统的文件路径的角度描述了文件路径中的一个特定的目录项 (注:一系列目录项形成目录/文件路径)。它的作用范围是整个OS空间。对于SFS而言,inode(具 体为struct sfs_disk_inode)对应于物理磁盘上的具体对象,dentry(具体为struct sfs_disk_entry)是一个内存实体,其中的ino成员指向对应的inode number,另外一个成员是file name(文件名).
- 文件(file),它主要从进程的角度描述了一个进程在访问文件时需要了解的文件标识,文件读写 的位置,文件引用情况等信息。它的作用范围是某一具体进程。
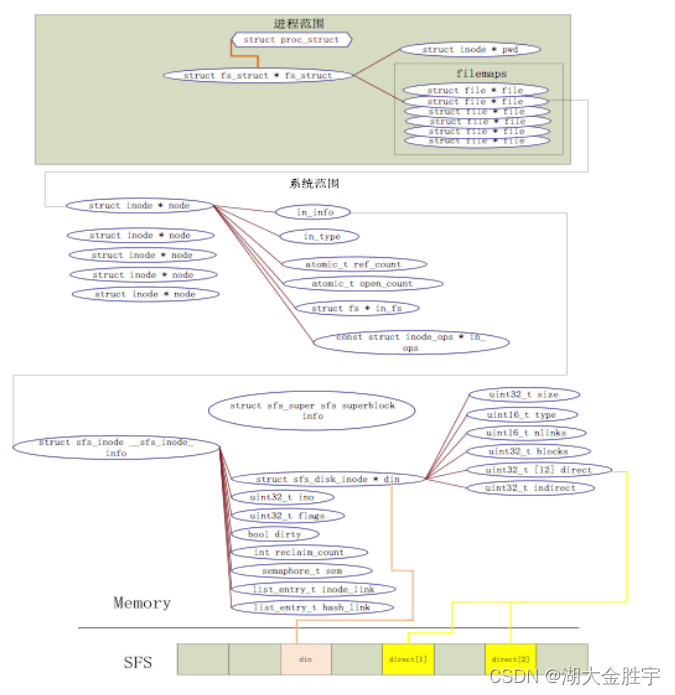
重要数据结构
file文件结构:
struct file {
enum {
FD_NONE, FD_INIT, FD_OPENED, FD_CLOSED,
} status; //访问文件的执行状态
bool readable; //文件是否可读
bool writable; //文件是否可写
int fd; //文件在filemap中的索引值
off_t pos; //访问文件的当前位置
struct inode *node; //该文件对应的内存inode指针
atomic_t open_count; //打开此文件的次数
};
inode:inode数据结构,它是位于内存的索引节点,把不同文件系统的特定索引节点信息(甚至不能算是一个索引节点)统一封装起来,避免了进程直接访问具体文件系统。
struct inode {
union {
//不同文件系统特定inode信息的union域
struct device __device_info; //设备文件系统内存inode信息
struct sfs_inode __sfs_inode_info; //SFS文件系统内存inode信息
} in_info;
enum {
inode_type_device_info = 0x1234,
inode_type_sfs_inode_info,
} in_type; //此inode所属文件系统类型
atomic_t ref_count; //此inode的引用计数
atomic_t open_count; //打开此inode对应文件的个数
struct fs *in_fs; //抽象的文件系统,包含访问文件系统的函数指针
const struct inode_ops *in_ops; //抽象的inode操作,包含访问inode的函数指针
};
打开文件的处理流程
先假定用户进程需要打开的文件已经存在在硬盘上。以user/sfs_filetest1.c为例,首先用户进程会调用在main函数中的如下语句:
int fd1 = safe_open("/test/testfile", O_RDWR | O_TRUNC);
如果ucore能够正常查找到这个文件,就会返回一个代表文件的文件描述符fd1,这样在接下来的读写文件过程中,就直接用这样fd1来代表就可以了。
通用文件系统访问接口
- 在文件操作方面,最基本的相关函数是open、close、read、write。在读写一个文件之前,首先要 用open系统调用将其打开。
- open的第一个参数指定文件的路径名,可使用绝对路径名;第二个参数指定打开的方式,可设置 为O_RDONLY、O_WRONLY\O_RDWR,分别表示只读、只写、可读可写。
- 在打开一个文件后,就可以使用它返回的文件描述符fd对文件进行相关操作。在使用完一个文件 后,还要用close系统调用把它关闭,其参数就是文件描述符fd。这样它的文件描述符就可以空出 来,给别的文件使用。
- 读写文件内容的系统调用是read和write。read系统调用有三个参数:一个指定所操作的文件描述 符,一个指定读取数据的存放地址,最后一个指定读多少个字节。在C程序中调用该系统调用的方法如下:
count = read(filehandle, buffer, nbytes);
该系统调用会把实际读到的字节数返回给count变量。在正常情形下这个值与nbytes相等,但有时可能 会小一些。例如,在读文件时碰上了文件结束符,从而提前结束此次读操作。
- 如果由于参数无效或磁盘访问错误等原因,使得此次系统调用无法完成,则count被置为-1。而 write函数的参数与之完全相同。
- 对于目录而言,最常用的操作是跳转到某个目录,这里对应的用户库函数是chdir。然后就需要读 目录的内容了,即列出目录中的文件或目录名,这在处理上与读文件类似,即需要通过opendir函 数打开目录,通过readdir来获取目录中的文件信息,读完后还需通过closedir函数来关闭目录。由 于在ucore中把目录看成是一个特殊的文件,所以opendir和closedir实际上就是调用与文件相关的 open和close函数。只有readdir需要调用获取目录内容的特殊系统调用sys_getdirentry。而且这里 没有写目录这一操作。在目录中增加内容其实就是在此目录中创建文件,需要用到创建文件的函数。
SFS文件系统层的处理流程
在第二步中,vop_lookup函数调用了sfs_lookup函数。
下面分析sfs_lookup函数:
static int sfs_lookup(struct inode *node, char *path, struct inode **node_store) {
struct sfs_fs *sfs = fsop_info(vop_fs(node), sfs);
assert(*path != '\0' && *path != '/'); //以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。
vop_ref_inc(node);
struct sfs_inode *sin = vop_info(node, sfs_inode);
if (sin->din->type != SFS_TYPE_DIR) {
vop_ref_dec(node);
return -E_NOTDIR;
}
struct inode *subnode;
int ret = sfs_lookup_once(sfs, sin, path, &subnode, NULL); //循环进一步调用sfs_lookup_once查找以“test”子目录下的文件“testfile1”所对应的inode节点。
vop_ref_dec(node);
if (ret != 0) {
return ret;
}
*node_store = subnode; //当无法分解path后,就意味着找到了需要对应的inode节点,就可顺利返回了。
return 0;
}
sfs_lookup函数先以“/”为分割符,从左至右逐一分解path获得各个子目录和最终文件对应的inode节点。然后循环进一步调用sfs_lookup_once查找以“test”子目录下的文件“testfile1”所对应的inode节点。最后当无法分解path后,就意味着找到了需要对应的inode节点,就可顺利返回了。
完成sfs_io_nolock函数
sfs_io_nolock函数主要用来将磁盘中的一段数据读入到内存中或者将内存中的一段数据写入磁盘。
该函数会进行一系列的边缘检查,检查访问是否越界、是否合法。之后将具体的读/写操作使用函数指针统一起来,统一成针对整块的操作。然后完成不落在整块数据块上的读/写操作,以及落在整块数据块上的读写。下面是该函数的代码(包括补充的代码,其中将有较为详细的注释)
static int
sfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write)
{
//创建一个磁盘索引节点指向要访问文件的内存索引节点
struct sfs_disk_inode *din = sin->din;
assert(din->type != SFS_TYPE_DIR);
//确定读取的结束位置
off_t endpos = offset + *alenp, blkoff;
*alenp = 0;
// 进行一系列的边缘,避免非法访问
if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) {
return -E_INVAL;
}
if (offset == endpos) {
return 0;
}
if (endpos > SFS_MAX_FILE_SIZE) {
endpos = SFS_MAX_FILE_SIZE;
}
if (!write) {
if (offset >= din->size) {
return 0;
}
if (endpos > din->size) {
endpos = din->size;
}
}
int (*sfs_buf_op)(struct sfs_fs *sfs, void *buf, size_t len, uint32_t blkno, off_t offset);
int (*sfs_block_op)(struct sfs_fs *sfs, void *buf, uint32_t blkno, uint32_t nblks);
//确定是读操作还是写操作,并确定相应的系统函数
if (write) {
sfs_buf_op = sfs_wbuf, sfs_block_op = sfs_wblock;
}
else {
sfs_buf_op = sfs_rbuf, sfs_block_op = sfs_rblock;
}
//
int ret = 0;
size_t size, alen = 0;
uint32_t ino;
uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block
uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
//--------------------------补充部分----------------------------------------------
// 判断被需要操作的区域的数据块中的第一块是否是完全被覆盖的,
// 如果不是,则需要调用非整块数据块进行读或写的函数来完成相应操作
if ((blkoff = offset % SFS_BLKSIZE) != 0) {
// 第一块数据块中进行操作的偏移量
blkoff = offset % SFS_BLKSIZE;
// 第一块数据块中进行操作的数据长度
size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset);
//获取这些数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, blkoff)) != 0) {
goto out;
}
//已经完成读写的数据长度
alen += size;
if (nblks == 0) {
goto out;
}
buf += size, blkno++; nblks--;
}
读取中间部分的数据,将其分为大小为size的块,然后一块一块操作,直至完成
size = SFS_BLKSIZE;
while (nblks != 0)
{
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
//对数据块进行读或写操作
if ((ret = sfs_block_op(sfs, buf, ino, 1)) != 0) {
goto out;
}
//更新相应的变量
alen += size, buf += size, blkno++, nblks--;
}
// 最后一页,可能出现不对齐的现象:
if ((size = endpos % SFS_BLKSIZE) != 0)
{
// 获取该数据块对应到磁盘上的数据块的编号
if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) {
goto out;
}
// 进行非整块的读或者写操作
if ((ret = sfs_buf_op(sfs, buf, size, ino, 0)) != 0) {
goto out;
}
alen += size;
}
out:
*alenp = alen;
if (offset + alen > sin->din->size) {
sin->din->size = offset + alen;
sin->dirty = 1;
}
return ret;
}
总的来说就是分为三部分来读取文件,每次通过sfs_bmap_load_nolock函数获取文件索引编号,然后调用sfs_buf_op或者sfs_block_op完成实际的文件读写操作。
回答问题
- 请在实验报告中给出设计实现”UNIX的PIPE机制“的概要设方案,鼓励给出详细设计方案
管道可用于具有亲缘关系进程间的通信,管道是由内核管理的一个缓冲区,相当于我们放入内存中的一个纸条。管道的一端连接一个进程的输出。这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。一个缓冲区不需要很大,它被设计成为环形的数据结构,以便管道可以被循环利用。当管道中没有信息的话,从管道中读取的进程会等待,直到另一端的进程放入信息。当管道被放满信息的时候,尝试放入信息的进程会等待,直到另一端的进程取出信息。当两个进程都终结的时候,管道也自动消失。
在 Linux 中,管道的实现并没有使用专门的数据结构,而是借助了文件系统的file结构和VFS的索引节点inode。通过将两个 file 结构指向同一个临时的 VFS 索引节点,而这个 VFS 索引节点又指向一个物理页面而实现的。
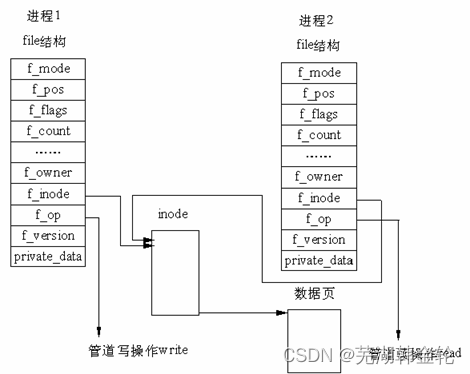
在Linux中,管道是一种使用非常频繁的通信机制。从本质上说,管道也是一种文件,但它又和一般的文 件有所不同,管道可以克服使用文件进行通信的两个问题,具体表现为:
- 限制管道的大小。实际上,管道是一个固定大小的缓冲区。在Linux中,该缓冲区的大小为1页,即 4K字节,使得它的大小不象文件那样不加检验地增长。使用单个固定缓冲区也会带来问题,比如在 写管道时可能变满,当这种情况发生时,随后对管道的write()调用将默认地被阻塞,等待某些数据 被读取,以便腾出足够的空间供write()调用写。
- 读取进程也可能工作得比写进程快。当所有当前进程数据已被读取时,管道变空。当这种情况发生 时,一个随后的read()调用将默认地被阻塞,等待某些数据被写入,这解决了read()调用返回文件 结束的问题。
实现
管道可以看作是由内核管理的一个缓冲区,一端连接进程A的输出,另一端连接进程B的输入。进程A会 向管道中放入信息,而进程B会取出被放入管道的信息。当管道中没有信息,进程B会等待,直到进程A 放入信息。当管道被放满信息的时候,进程A会等待,直到进程B取出信息。当两个进程都结束的时候, 管道也自动消失。管道基于fork机制建立,从而让两个进程可以连接到同一个PIPE上
基于此,我们可以模仿UNIX,设计一个PIPE机制:
- 在磁盘上保留一定的区域用来作为PIPE机制的缓冲区,或者创建一个文件为PIPE机制服务
- 对系统文件初始化时将PIPE也初始化并创建相应的inode 在内存中为PIPE留一块区域,以便高效完成缓存
- 当两个进程要建立管道时,那么可以在这两个进程的进程控制块上新增变量来记录进程的这种属性
- 当其中一个进程要对数据进行写操作时,通过进程控制块的信息,可以将其先对临时文件PIPE进行修改
- 当一个进行需要对数据进行读操作时,可以通过进程控制块的信息完成对临时文件PIPE的读取
- 增添一些相关的系统调用支持上述操作
管道可以看作是由内核管理的一个缓冲区,一端连接进程A的输出,另一端连接进程B的输入。进程A会向管道中放入信息,而进程B会取出被放入管道的信息。当管道中没有信息,进程B会等待,直到进程A放入信息。当管道被放满信息的时候,进程A会等待,直到进程B取出信息。当两个进程都结束的时候,管道也自动消失。管道基于fork机制建立,从而让两个进程可以连接到同一个PIPE上。
基于此,我们可以模仿UNIX,设计一个PIPE机制。
- 首先我们需要在磁盘上保留一定的区域用来作为PIPE机制的缓冲区,或者创建一个文件为PIPE机制服务
- 对系统文件初始化时将PIPE也初始化并创建相应的inode
- 在内存中为PIPE留一块区域,以便高效完成缓存
- 当两个进程要建立管道时,那么可以在这两个进程的进程控制块上新增变量来记录进程的这种属性
- 当其中一个进程要对数据进行写操作时,通过进程控制块的信息,可以将其先对临时文件PIPE进行修改
- 当一个进行需要对数据进行读操作时,可以通过进程控制块的信息完成对临时文件PIPE的读取
- 增添一些相关的系统调用支持上述操作
至此,PIPE的大致框架已经完成。
练习2: 完成基于文件系统的执行程序机制的实现(需要编码)
改写proc.c中的load_icode函数和其他相关函数,实现基于文件系统的执行程序机制。执行:make qemu。如果能看看到sh用户程序的执行界面,则基本成功了。如果在sh用户界面上可以执行”ls”,”hello”等其他放置在sfs文件系统中的其他执行程序,则可以认为本实验基本成功。
请在实验报告中给出设计实现基于”UNIX的硬链接和软链接机制“的概要设方案,鼓励给出详细设计方案
修改alloc_proc
在 proc.c 中,根据注释我们需要先初始化fs中的进程控制结构,即在 alloc_proc 函数中我们需要做一 下修改,加上一句 proc->filesp = NULL; 从而完成初始化。
static struct proc_struct *
alloc_proc(void) {
struct proc_struct *proc = kmalloc(sizeof(struct proc_struct));
if (proc != NULL) {
// Lab7内容
// ...
//LAB8:EXERCISE2 YOUR CODE HINT:need add some code to init fs in proc_struct, ...
// LAB8 添加一个filesp指针的初始化
proc->filesp = NULL;
}
return proc;
}
为什么要这样做的呢,因为我们之前讲过,一个文件需要在 VFS 中变为一个进程才能被执行。
实现 load_icode 函数
load_icode函数的主要工作就是给用户进程建立一个能够让用户进程正常运行的用户环境。基本流程:
- 调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化;
- 调用setup_pgdir来申请一个页目录表所需的一个页大小的内存空间,并把描述ucore内核虚空间映射的内核页表(boot_pgdir所指)的内容拷贝到此新目录表中,最后让mm->pgdir指向此页目录表,这就是进程新的页目录表了,且能够正确映射内核虚空间;
- 将磁盘中的文件加载到内存中,并根据应用程序执行码的起始位置来解析此ELF格式的执行程序,并根据ELF格式的执行程序说明的各个段(代码段、数据段、BSS段等)的起始位置和大小建立对应的vma结构,并把vma插入到mm结构中,从而表明了用户进程的合法用户态虚拟地址空间;
- 调用根据执行程序各个段的大小分配物理内存空间,并根据执行程序各个段的起始位置确定虚拟地址,并在页表中建立好物理地址和虚拟地址的映射关系,然后把执行程序各个段的内容拷贝到相应的内核虚拟地址中
- 需要给用户进程设置用户栈,并处理用户栈中传入的参数
- 先清空进程的中断帧,再重新设置进程的中断帧,使得在执行中断返回指令“iret”后,能够让CPU转到用户态特权级,并回到用户态内存空间,使用用户态的代码段、数据段和堆栈,且能够跳转到用户进程的第一条指令执行,并确保在用户态能够响应中断;
大致可以简单分为以下部分:
将文件加载到内存中执行,根据注释的提示分为了一共七个步骤:
- 建立内存管理器
- 建立页目录
- 将文件逐个段加载到内存中,这里要注意设置虚拟地址与物理地址之间的映射
- 建立相应的虚拟内存映射表
- 建立并初始化用户堆栈
- 处理用户栈中传入的参数
- 最后很关键的一步是设置用户进程的中断帧
完整代码如下:
//从磁盘上读取可执行文件,并且加载到内存中,完成内存空间的初始化
static int load_icode(int fd, int argc, char **kargv)
{
//判断当前进程的内存管理是否已经被释放掉了,我们需要要求当前内存管理器为空
if (current->mm != NULL)
{
panic("load_icode: current->mm must be empty.\n");
}
int ret = -E_NO_MEM;
//1.调用mm_create函数来申请进程的内存管理数据结构mm所需内存空间,并对mm进行初始化
struct mm_struct *mm;
if ((mm = mm_create()) == NULL) {
goto bad_mm;
}
//2.申请新目录项的空间并完成目录项的设置
if (setup_pgdir(mm) != 0) {
goto bad_pgdir_cleanup_mm;
}
//创建页表
struct Page *page;
//3.从文件从磁盘中加载程序到内存
struct elfhdr __elf, *elf = &__elf;
//3.1调用load_icode_read函数读取ELF文件
if ((ret = load_icode_read(fd, elf, sizeof(struct elfhdr), 0)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
//判断这个文件是否合法
if (elf->e_magic != ELF_MAGIC) {
ret = -E_INVAL_ELF;
goto bad_elf_cleanup_pgdir;
}
struct proghdr __ph, *ph = &__ph;
uint32_t i;
uint32_t vm_flags, perm;
//e_phnum代表程序段入口地址数目
for (i = 0; i < elf->e_phnum; ++i)
{
//3.2循环读取程序的每个段的头部
if ((ret = load_icode_read(fd, ph, sizeof(struct proghdr), elf->e_phoff + sizeof(struct proghdr) * i)) != 0)
{
goto bad_elf_cleanup_pgdir;
}
if (ph->p_type != ELF_PT_LOAD) {
continue ;
}
if (ph->p_filesz > ph->p_memsz) {
ret = -E_INVAL_ELF;
goto bad_cleanup_mmap;
}
if (ph->p_filesz == 0) {
continue ;
}
//3.3建立对应的VMA
vm_flags = 0, perm = PTE_U; //建立虚拟地址与物理地址之间的映射
// 根据ELF文件中的信息,对各个段的权限进行设置
if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC;
if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE;
if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ;
if (vm_flags & VM_WRITE) perm |= PTE_W;
//虚拟内存地址设置为合法的
if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
//3.4为数据段代码段等分配页
off_t offset = ph->p_offset;
size_t off, size;
//计算数据段和代码段的开始地址
uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE);
ret = -E_NO_MEM;
//计算数据段和代码段终止地址
end = ph->p_va + ph->p_filesz;
while (start < end)
{
// 为TEXT/DATA段逐页分配物理内存空间
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL)
{
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将磁盘上的TEXT/DATA段读入到分配好的内存空间中去
//每次读取size大小的块,直至全部读完
if ((ret = load_icode_read(fd, page2kva(page) + off, size, offset)) != 0)
{
goto bad_cleanup_mmap;
}
start += size, offset += size;
}
//3.5为BBS段分配页
//计算BBS的终止地址
end = ph->p_va + ph->p_memsz;
if (start < la) {
if (start == end) {
continue ;
}
off = start + PGSIZE - la, size = PGSIZE - off;
if (end < la)
{
size -= la - end;
}
memset(page2kva(page) + off, 0, size);
start += size;
assert((end < la && start == end) || (end >= la && start == la));
}
// 如果没有给BSS段分配足够的页,进一步进行分配
while (start < end) {
if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) {
goto bad_cleanup_mmap;
}
off = start - la, size = PGSIZE - off, la += PGSIZE;
if (end < la) {
size -= la - end;
}
// 将分配到的空间清零初始化
memset(page2kva(page) + off, 0, size);
start += size;
}
}
sysfile_close(fd);//关闭文件,加载程序结束
// 4.设置用户栈
vm_flags = VM_READ | VM_WRITE | VM_STACK; //设置用户栈的权限
//将用户栈所在的虚拟内存区域设置为合法的
if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) {
goto bad_cleanup_mmap;
}
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL);
assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL);
//设置当前进程的mm、cr3等
mm_count_inc(mm);
current->mm = mm;
current->cr3 = PADDR(mm->pgdir);
lcr3(PADDR(mm->pgdir));
//为用户空间设置trapeframe
uint32_t argv_size=0, i;
//确定传入给应用程序的参数具体应当占用多少空间
uint32_t total_len = 0;
for (i = 0; i < argc; ++i)
{
total_len += strnlen(kargv[i], EXEC_MAX_ARG_LEN) + 1;
// +1表示字符串结尾的'\0'
}
// 用户栈顶减去所有参数加起来的长度,与4字节对齐找到真正存放字符串参数的栈的位置
char *arg_str = (USTACKTOP - total_len) & 0xfffffffc;
//存放指向字符串参数的指针
int32_t *arg_ptr = (int32_t *)arg_str - argc;
// 根据参数需要在栈上占用的空间来推算出,传递了参数之后栈顶的位置
int32_t *stacktop = arg_ptr - 1;
*stacktop = argc;
for (i = 0; i < argc; ++i)
{
uint32_t arg_len = strnlen(kargv[i], EXEC_MAX_ARG_LEN);
strncpy(arg_str, kargv[i], arg_len);
*arg_ptr = arg_str;
arg_str += arg_len + 1;
++arg_ptr;
}
//6.设置进程的中断帧
//设置tf相应的变量的设置,包括:tf_cs、tf_ds tf_es、tf_ss tf_esp, tf_eip, tf_eflags
struct trapframe *tf = current->tf;
memset(tf, 0, sizeof(struct trapframe));
tf->tf_cs = USER_CS;
tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS;
tf->tf_esp = stacktop;
tf->tf_eip = elf->e_entry;
tf->tf_eflags |= FL_IF;
ret = 0;
out:
return ret;
//一些错误的处理
bad_cleanup_mmap:
exit_mmap(mm);
bad_elf_cleanup_pgdir:
put_pgdir(mm);
bad_pgdir_cleanup_mm:
mm_destroy(mm);
bad_mm:
goto out;
}
运行结果:
输入ls和hello:
运行make grade查看成绩:
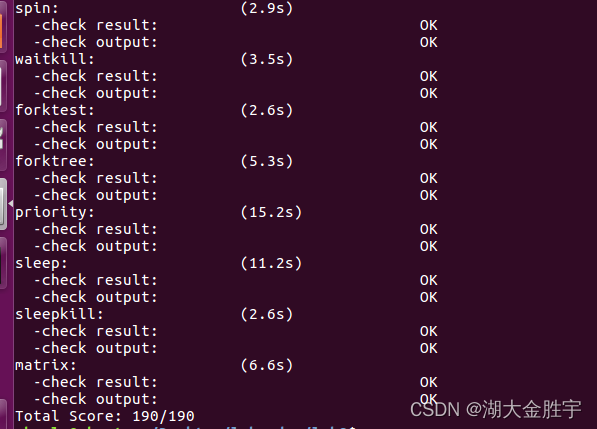
回答问题
请在实验报告中给出设计实现基于”UNIX的硬链接和软链接机制“的概要设方 案,鼓励给出详细设计方案;
1.软链接和硬链接
链接简单说实际上是一种文件共享的方式,是 POSIX 中的概念,主流文件系统都支持链接文件。
链接可以简单地理解为 Windows 中常见的快捷方式(或是 OS X 中的替身),Linux 中常用它来解决一 些库版本的问题,通常也会将一些目录层次较深的文件链接到一个更易访问的目录中。在这些用途上, 我们通常会使用到软链接(也称符号链接)
硬链接: 与普通文件没什么不同, inode 都指向同一个文件在硬盘中的区块
- 硬链接,以文件副本的形式存在。但不占用实际空间。
- 不允许给目录创建硬链接。
- 硬链接只有在同一个文件系统中才能创建。
- 删除其中一个硬链接文件并不影响其他有相同 inode 号的文件。
软链接: 保存了其代表的文件的绝对路径,是另外一种文件,在硬盘上有独立的区块,访问时替换 自身路径。
- 软链接是存放另一个文件的路径的形式存在。
- 软链接可以 跨文件系统 ,硬链接不可以。
- 软链接可以对一个不存在的文件名进行链接,硬链接必须要有源文件。
- 软链接可以对目录进行链接。
2.实现思路
在磁盘上的 inode 信息均存在一个 nlinks 变量用于表示当前文件的被链接的计数,因而支持实现硬链接 和软链接机制;
- 如果在磁盘上创建一个文件 A 的软链接 B,那么将 B 当成正常的文件创建 inode,然后将 TYPE 域 设置为链接,然后使用剩余的域中的一个,指向 A 的 inode 位置,然后再额外使用一个位来标记 当前的链接是软链接还是硬链接;
- 当访问到文件 B(read,write 等系统调用),判断如果 B 是一个链接,则实际是将对B指向的文 件A(已经知道了 A 的 inode 位置)进行操作;
- 当删除一个软链接 B 的时候,直接将其在磁盘上的 inode 删掉即可;
- 如果在磁盘上的文件 A 创建一个硬链接 B,那么在按照软链接的方法创建完 B 之后,还需要将 A 中的被链接的计数加 1;
- 访问硬链接的方式与访问软链接是一致的;
- 当删除一个硬链接B的时候,除了需要删除掉 B 的 inode 之外,还需要将 B 指向的文件 A 的被链接 计数减 1,如果减到了 0,则需要将 A 删除掉;
对比与分析
本实验的实现与答案类似
本实验中重要的知识点,以及与对应的OS原理中的知识点
- 管道
- 虚拟文件系统框架
- 文件描述符
- 目录
- inode、打开的文件等结构体
- inode缓存
- 简单文件系统
- ucore特定的文件系统架构
本实验中没有对应的:
- 其他进程间通信机制,例如信号、消息队列和共享内存
- RAID
- 磁盘调度算法
- 磁盘缓存
- I/O
实验总结
通过本次实验,我熟悉了基本的文件系统系统调用的实现方法,了解了一个基于索引节点组织方式的 Simple FS文件系统的设计与实现,了解文件系统抽象层-VFS的设计与实现,其中让我印象深刻的是管道 和软链接和硬链接的实现思路。
系统调用),判断如果 B 是一个链接,则实际是将对B指向的文 件A(已经知道了 A 的 inode 位置)进行操作;
- 当删除一个软链接 B 的时候,直接将其在磁盘上的 inode 删掉即可;
- 如果在磁盘上的文件 A 创建一个硬链接 B,那么在按照软链接的方法创建完 B 之后,还需要将 A 中的被链接的计数加 1;
- 访问硬链接的方式与访问软链接是一致的;
- 当删除一个硬链接B的时候,除了需要删除掉 B 的 inode 之外,还需要将 B 指向的文件 A 的被链接 计数减 1,如果减到了 0,则需要将 A 删除掉;
对比与分析
本实验的实现与答案类似
本实验中重要的知识点,以及与对应的OS原理中的知识点
- 管道
- 虚拟文件系统框架
- 文件描述符
- 目录
- inode、打开的文件等结构体
- inode缓存
- 简单文件系统
- ucore特定的文件系统架构
本实验中没有对应的:
- 其他进程间通信机制,例如信号、消息队列和共享内存
- RAID
- 磁盘调度算法
- 磁盘缓存
- I/O
实验总结
通过本次实验,我熟悉了基本的文件系统系统调用的实现方法,了解了一个基于索引节点组织方式的 Simple FS文件系统的设计与实现,了解文件系统抽象层-VFS的设计与实现,其中让我印象深刻的是管道 和软链接和硬链接的实现思路。
最后,感谢老师和助教所花费的时间,谢谢老师的解疑答惑。
边栏推荐
- {1,2,3,2,5} duplicate checking problem
- What to do when programmers don't modify bugs? I teach you
- 自动化测试中敏捷测试怎么做?
- How to transform functional testing into automated testing?
- [pytorch] simple use of interpolate
- What are the software testing methods? Show you something different
- Global and Chinese market of RF shielding room 2022-2028: Research Report on technology, participants, trends, market size and share
- Heap, stack, queue
- ucore lab6 调度器 实验报告
- 软件测试有哪些常用的SQL语句?
猜你喜欢
Eigen User Guide (Introduction)

The number of reversing twice in leetcode simple question

Servlet
Portapack application development tutorial (XVII) nRF24L01 launch B

China's county life record: go upstairs to the Internet, go downstairs' code the Great Wall '

線程及線程池
Soft exam information system project manager_ Project set project portfolio management --- Senior Information System Project Manager of soft exam 025
![[200 opencv routines] 98 Statistical sorting filter](/img/ba/9097df20f6d43dfce9fc1e374e6597.jpg)
[200 opencv routines] 98 Statistical sorting filter
Mysql database (I)
UCORE lab8 file system experiment report
随机推荐
About the garbled code problem of superstar script
Investment should be calm
Emqtt distribution cluster and node bridge construction
Practical cases, hand-in-hand teaching you to build e-commerce user portraits | with code
Install and run tensorflow object detection API video object recognition system of Google open source
安全测试入门介绍
Cadence physical library lef file syntax learning [continuous update]
How to transform functional testing into automated testing?
Oracle foundation and system table
HackTheBox-Emdee five for life
Currently, mysql5.6 is used. Which version would you like to upgrade to?
Automated testing problems you must understand, boutique summary
JDBC introduction
线程及线程池
150 common interview questions for software testing in large factories. Serious thinking is very valuable for your interview
软件测试面试回答技巧
Future trend and planning of software testing industry
Soft exam information system project manager_ Project set project portfolio management --- Senior Information System Project Manager of soft exam 025
Pedestrian re identification (Reid) - data set description market-1501
软件测试方法有哪些?带你看点不一样的东西