This is a why Technology 74 Original articles

Don't ask , No way to ask
You should know about distributed transactions . But this multithreaded transaction ......
Don't worry , I'll tell you slowly .

As shown in the figure , There is a partner who wants to implement multithreaded transactions .
I've seen this demand many times in different places , So I said : This problem has arisen again .
So is there a solution ?
Before that , My answers are all very positive : Beyond all doubt , There must be no .

Why? ?
Let's start by theorizing .
Come on , First of all, let me ask you , What are the characteristics of transactions ?
This is not difficult ? Eight part essay must be recited ,ACID You have to open your mouth :
-
Atomicity (Atomicity) -
Uniformity (Consistency) -
Isolation, (Isolation) -
persistence (Durability)
So here comes the question , Do you think if there are multithreaded transactions , So which feature have we broken ?
You can't think about multithreading , You just want to , Two different users each initiate an order request , There are transactions in the background implementation logic corresponding to this request .
Isn't this multi-threaded transaction ?
In this scenario, you haven't thought about how to control the transaction operation of two users separately ?
Because the two operations are completely isolated , Play with their own links .
So what's the basic principle between multiple transactions ?
Isolation, . Two transaction operations should not interfere with each other .
What multithreaded transactions want to achieve is A Thread exception .A,B The transactions of the thread are rolled back together .

In the characteristics of transaction, there is a dead card . therefore , Multithreaded transactions don't work in theory .
Practice guides theory through , So the code for multithreaded transactions can't be written .
I talked about isolation . So, please. ,Spring Source code inside , How is the isolation of transactions guaranteed ?
The answer is ThreadLocal.
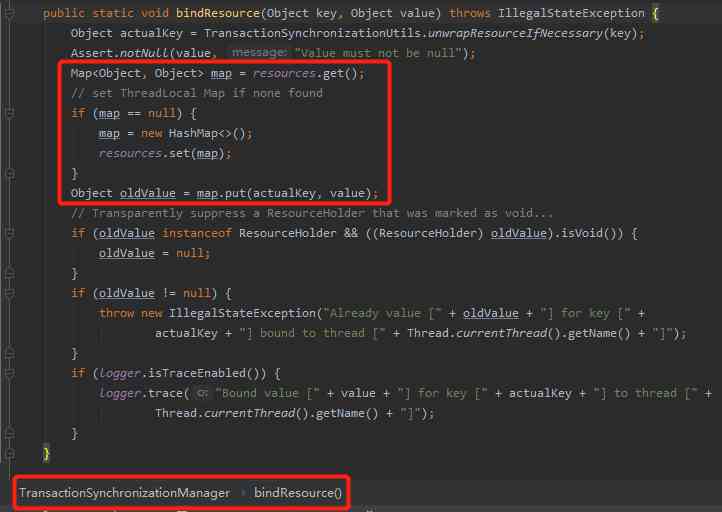
When the transaction is on , Save the current link in ThreadLocal Inside , This ensures the isolation between multiple threads :
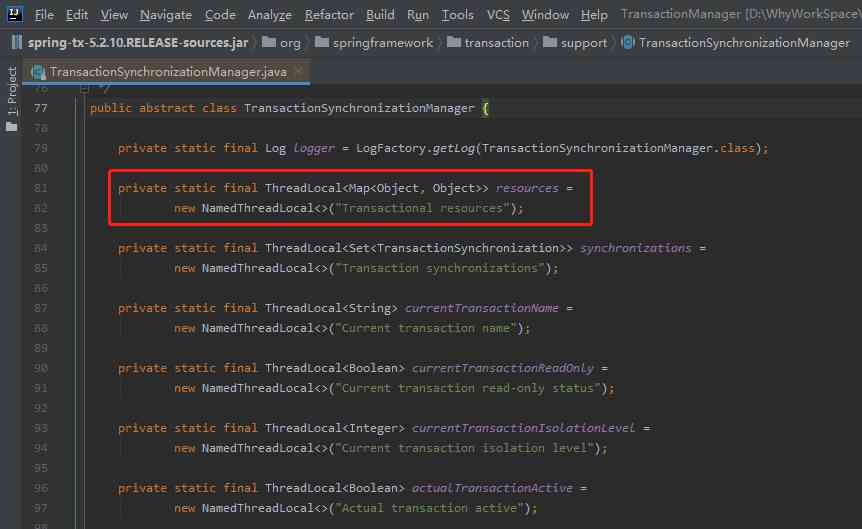
You can see , This resource Object is a ThreadLocal object .
In the following method, the assignment operation is performed :
org.springframework.jdbc.datasource.DataSourceTransactionManager#doBegin

Among them bindResource In the method , It is to bind the current link to the current thread , Among them resource That's what we just said ThreadLocal:
Each thread plays its own game , We can't break ThreadLocal Rules of use , Let each thread share the same ThreadLocal Well ?
Iron seed , If you do that , That's not a long way to go ?
therefore , In theory , Or code implementation , I don't think this requirement can be realized .
At least that's what I thought before .
But things , A little bit changed .

Say a scene , Regular implementation
Any behavior that discusses technology implementation out of context is playing rogue .
therefore , Let's take a look at the scene first .
Suppose we have a big data system , Set time every day , We need to pull from big data systems 50w Data , Do a cleaning operation on the data , Then save the data to the database of our business system .
For business systems , this 50w Data , All of them have to be left in the warehouse , Not one of them . Or you don't insert any of them .
In the process , It doesn't call other external interfaces , There will be no other process to manipulate the data in this table .
Since one of them is right , So for all of you, intuitively , There must be two solutions :
-
for Insert transaction by transaction in the loop . -
Directly insert a statement in batches .
For this need , Open transaction , And then in for The insertion of a loop can be said to be very low The solution to the problem .

Very inefficient , Let me show you .
such as , We have a Student surface , The table structure is very simple , as follows :
CREATE TABLE `student` (
`id` bigint(63) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
`home` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
In our project , We go through for Loop insert data , At the same time, this method has @Transactional annotation :
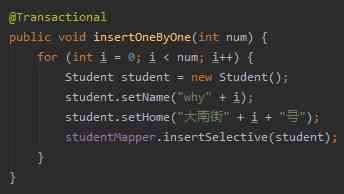
num Parameters are the data we pass through the front-end request , It means to insert num Data :
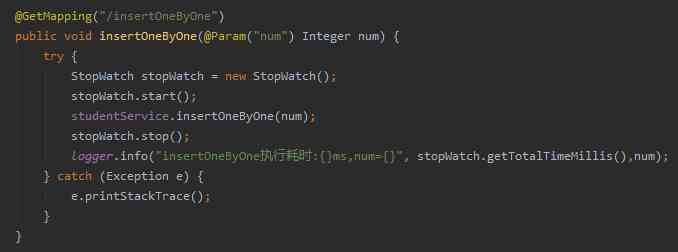
In this case , We can use the link below , Simulate the insertion of a specified amount of data :
http://127.0.0.1:8081/insertOneByOne?num=xxx
I tried to put num Set to 50w, Let it run slowly , But I'm still too young , I've been waiting for a long time, but I haven't got the result .
So I put num Change it to 5000, The operation results are as follows :
insertOneByOne Execution time consuming :133449ms,num=5000
Insert one by one 5000 Data , Time consuming 133.5 s The appearance of .
At this rate , Insert 50w It's got to be 13350s, It's about as many hours as that :
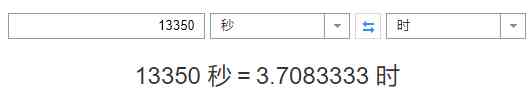
Who can resist this .
therefore , There's huge room for optimization .
For example, we optimize to insert in batches like this :
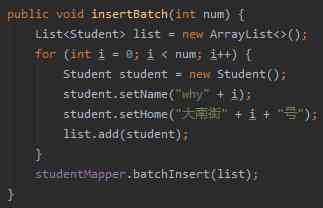
Their corresponding sql This is the sentence :
insert into table ([ Name ],[ Name ]) VALUES ([ The column value ],[ The column value ]), ([ The column value ],[ The column value ]);
We still call through the front-end interface :
When our num Set to 5000 When , My page has been refreshed 10 Time , You see, the time-consuming is basically 200ms Within milliseconds :
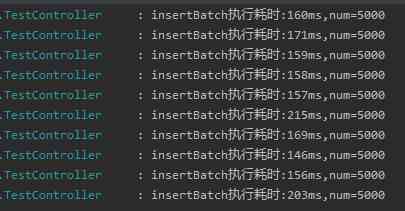
from 133.5s To 200ms, friends , What's this? ?
This is a qualitative leap . Performance has improved by nearly 667 Double the look .

Why can batch insertion make such a big leap ?
You want to. , Before for Circular insert , although SpringBoot 2.0 Default used HikariPool, The connection pool is for you by default 10 A connection .
But you just need a connection , Start a transaction . It's not time consuming .
The time-consuming part is you 5000 Time IO ah .
therefore , It is inevitable that it will take a long time .
And batch insertion is just a piece of sql sentence , So you just need a connection , You don't need to open the transaction yet .
Why don't you open a transaction ?
You have one sql There is a hammer to start a business ?
that , If we insert 50w Data , What would it be like ?
Come on , Do something about it , Have a try :
http://127.0.0.1:8081/insertBatch?num=500000
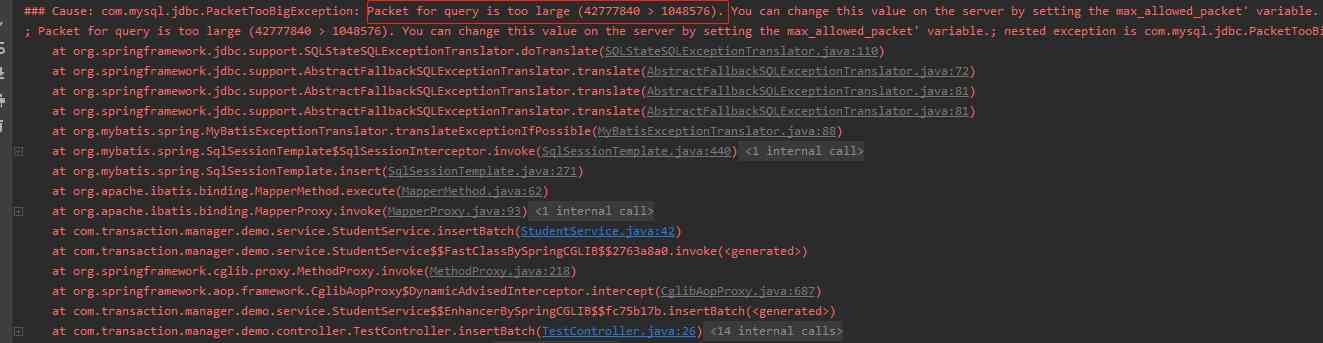
You can see an exception thrown . And the error message is very clear :
Packet for query is too large (42777840 > 1048576). You can change this value on the server by setting the max_allowed_packet' variable.; nested exception is com.mysql.jdbc.PacketTooBigException: Packet for query is too large (42777840 > 1048576).You can change this value on the server by setting the max_allowed_packet' variable.
Say your bag is too big . Can be set by max_allowed_packet To change the size of the bag .
We can query the current configuration size through the following statement :
select @@max_allowed_packet;
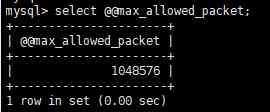
As you can see, yes 1048576, namely 1024*1024,1M size .
And the packet size we need to transfer is 42777840 byte , Probably 41M The appearance of .
So we need to change the configuration size .
This place is also a wake-up call : If your sql The sentence is very big , There are big fields in it , Remember to adjust mysql This parameter of .
You can modify the configuration file or execute it directly sql Change the way statements are made .
I'll use it here sql Statement modified to 64M:
set global max_allowed_packet = 1024*1024*64;
And then execute it again , You can see that the insertion succeeded :
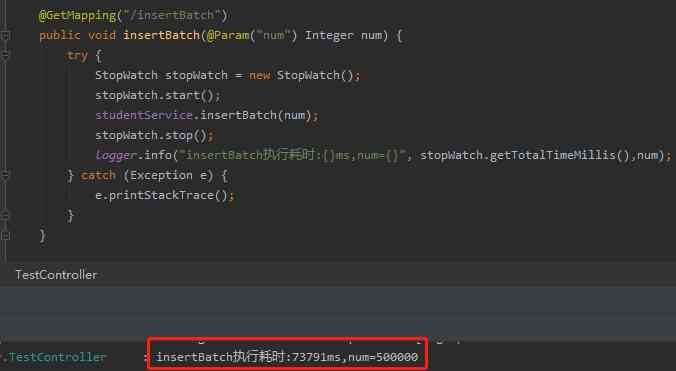
50w The data of ,74s The appearance of .
The data is either all submitted , Or none of them , The requirements are fulfilled .
In terms of time , It's a little long , But I can't think of any good promotion plan .
So how can we shorten the time ?

The idea of coquettish appeared
I can think of that , It's just multi thread .
50w data . We have five threads , A thread handles 10w data , Save and store without exception , Roll back when there is a problem .
This requirement is well implemented . It can be written in minutes .
But with a need : this 5 Data of threads , If there is a thread problem , You need to roll it all back .
Follow the train of thought , We found that this is the so-called multithreaded transaction .

I said it's impossible to do it because I think about transactions @Transactional Annotation to achieve .
We just need to use it correctly , Then the relational business logic can be , You don't need to and can't get involved in the transaction opening and committing or rolling back .
This kind of code is called declarative transaction .
A declarative transaction corresponds to a programmatic transaction .
Through programmatic transactions , We have full control over the opening and committing of transactions or rollback operations .
Can think of programming transactions , It's almost half done .
Would you , First of all, we have a global variable called Boolean type , By default, it can be submitted .
In child threads , We can start a transaction through a programmatic transaction , Then insert 10w After data , But don't submit . At the same time, tell the main thread , I'm ready on my side , Has reached the awaited .
If there is an exception in the child thread , So I'll tell the main thread , There's something wrong with me , And then roll back on your own .
Finally, the main thread collected 5 The state of the child thread .
If there is a problem with one thread , Then set the global variable to be uncommitted .
Then wake up all the waiting child threads , Roll back .
According to the above process , That's how you write simulation code , You can copy it directly and run it :
public class MainTest {
// Can I submit
public static volatile boolean IS_OK = true;
public static void main(String[] args) {
// The child thread waits for the main thread to notify
CountDownLatch mainMonitor = new CountDownLatch(1);
int threadCount = 5;
CountDownLatch childMonitor = new CountDownLatch(threadCount);
// The running result of the child thread is
List<Boolean> childResponse = new ArrayList<Boolean>();
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < threadCount; i++) {
int finalI = i;
executor.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + ": Start execution ");
// if (finalI == 4) {
// throw new Exception(" Something unusual happened ");
// }
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current().nextInt(1000));
childResponse.add(Boolean.TRUE);
childMonitor.countDown();
System.out.println(Thread.currentThread().getName() + ": Be ready , Wait for other thread results , Determine whether the transaction is committed ");
mainMonitor.await();
if (IS_OK) {
System.out.println(Thread.currentThread().getName() + ": Transaction submission ");
} else {
System.out.println(Thread.currentThread().getName() + ": Transaction rollback ");
}
} catch (Exception e) {
childResponse.add(Boolean.FALSE);
childMonitor.countDown();
System.out.println(Thread.currentThread().getName() + ": Something unusual happened , Start transaction rollback ");
}
});
}
// The main thread waits for all child threads to execute response
try {
childMonitor.await();
for (Boolean resp : childResponse) {
if (!resp) {
// If a child thread fails to execute , Then change mainResult, Let all child threads roll back
System.out.println(Thread.currentThread().getName()+": A thread failed to execute , The flag bit is set to false");
IS_OK = false;
break;
}
}
// The main thread got the result successfully , Let the child thread begin to execute according to the result of the main thread ( Commit or rollback )
mainMonitor.countDown();
// In order to block the main thread , Let the child thread execute .
Thread.currentThread().join();
} catch (Exception e) {
e.printStackTrace();
}
}
}
In the case that all child threads are normal , The output is like this :
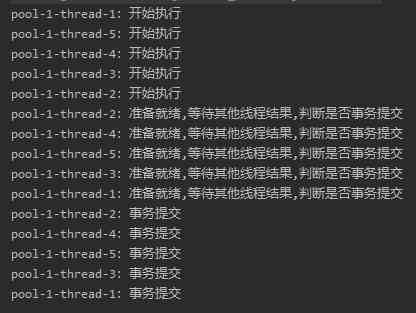
From the results , It's in line with our expectations .
Suppose there is an exception in a child thread , So the running result is like this :
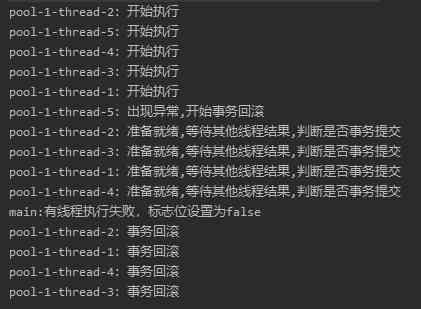
An exception occurred in a thread , All threads are rolled back , This seems to be in line with expectations .

If you write this code according to the previous requirements , So congratulations , A careless implementation of a similar two-phase commit (2PC) Consistency agreement for .
I mentioned earlier that you can think of programming transactions , It's almost half done .
And the other half , It's a two-stage submission (2PC).
I draw gourd by the gourd
With the scoop in front , Isn't it very easy for you to draw a gourd according to the picture ?
Just a little bit of code , The sample code can be downloaded from here Get , So let me cut a picture here :
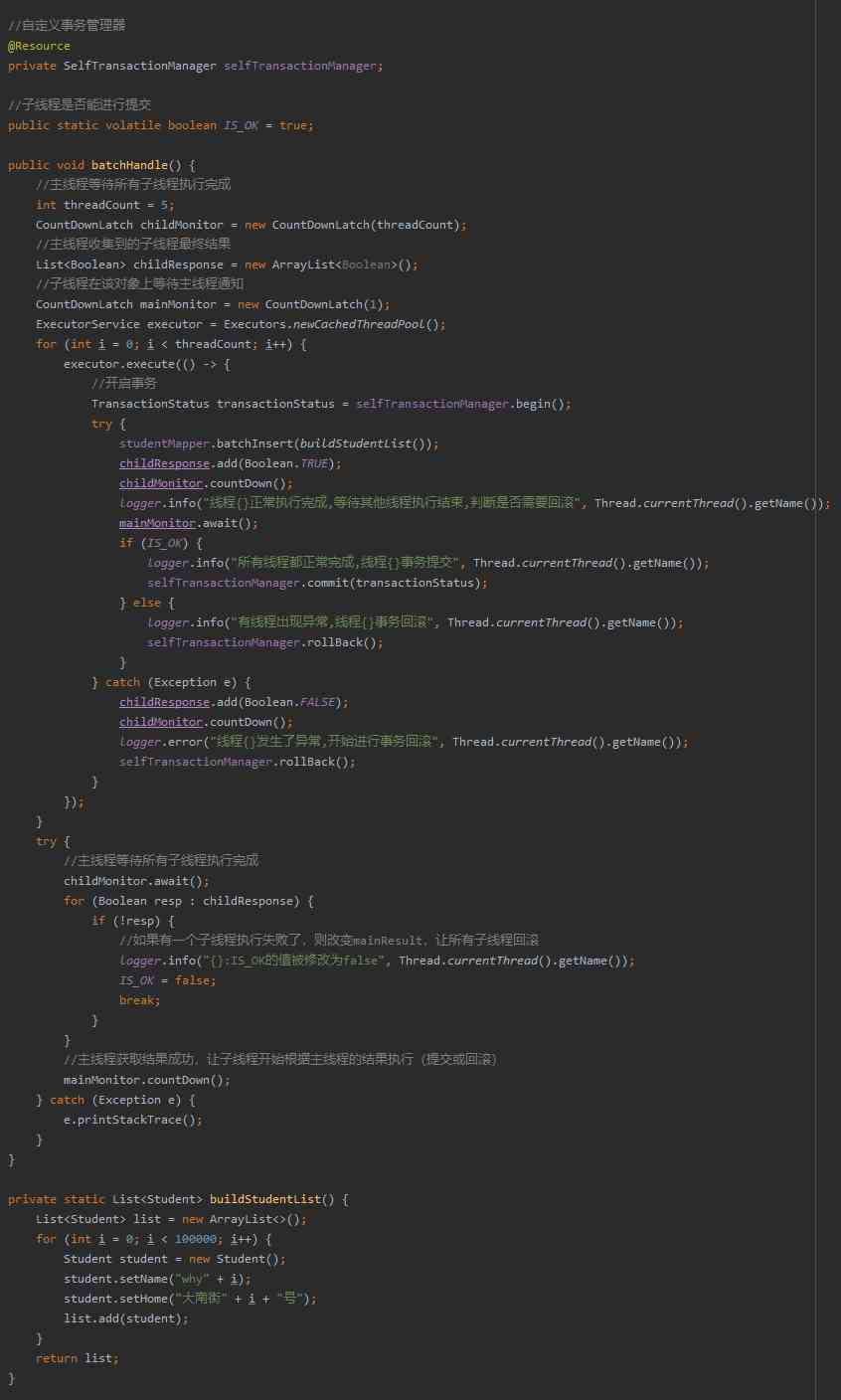
The above code should be very easy to understand , Start five threads , Each thread inserts 10w Data .
It goes without saying , Think with your toes , It's definitely better than one-time batch insertion 50w Data fast .
As for how fast , Don't talk nonsense , Look directly at the execution effect .
Because of our controller That's true :
So call the link :
http://127.0.0.1:8081/batchHandle
The output is as follows :
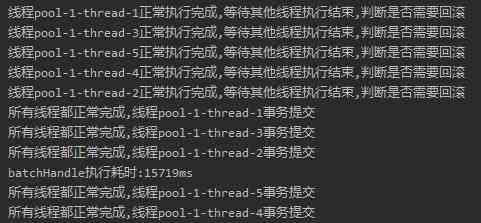
Remember the time it took us to insert in bulk ?
73791ms.
from 73791ms To 15719ms. fast 58s The appearance of .
It's already very good .
What if a thread throws an exception ? Such as this :
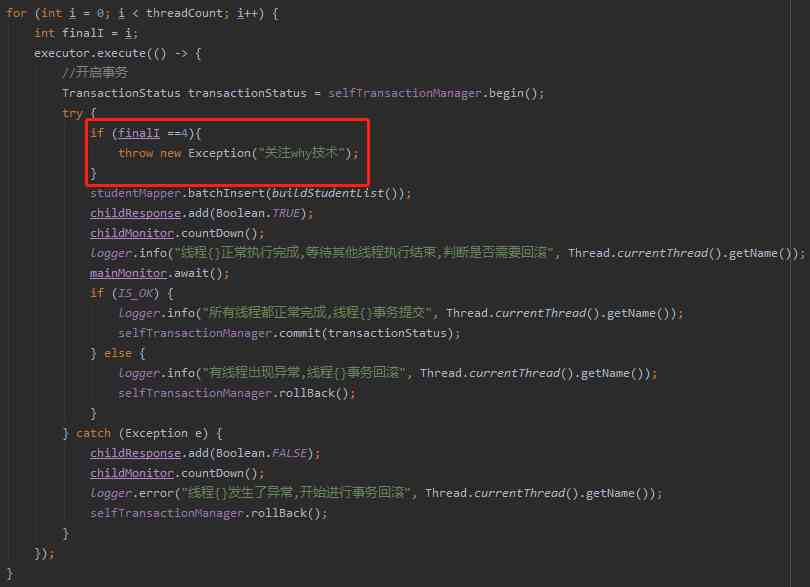
Let's look at the log output :
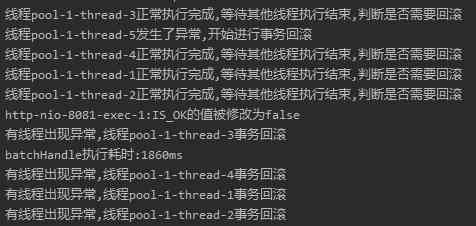
Through log analysis , It seems to meet the requirements .
But from the actual test effect of reader feedback , It's also very significant :
Do you really meet the requirements ?
Meet the requirements , It just looks .
Experienced readers must have seen the problem for a long time . Having raised his hands high : teacher , I know this question .

I said before , This implementation method is actually a programming transaction with two-phase commit (2PC) Use .
The flaw lies in 2PC On .
It's like I'm talking to readers about this :
You can't pull back any more , And then there will be 3PC,TCC,Seata This set of distributed transaction things .
Write it down , It's going to take tens of thousands of words . So I transferred an article from Poseidon , It's in the second push . If you are interested, you can have a look . Dry cargo is full. .
In fact, when we think of a subthread as a subsystem in a microservice , This is a distributed transaction scenario .
And the solution we came up with , It's not a perfect solution .
although , In a way , We bypass the isolation of transactions , But there is a certain probability of data consistency problems , Although the probability is relatively small .
So I call it this program, it's called : Programming based on luck , Change time with luck .
matters needing attention
About the code above , In fact, there are still a few things to pay attention to .
Let me remind you .
first : How many threads are enabled for allocation data insertion , This parameter can be adjusted .
For example, I changed it to 10 Threads , Each thread inserts 5w Data . So the execution time is fast again 2s:
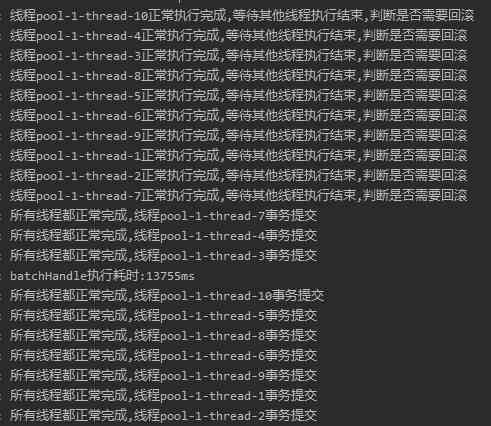
But I must remember that the bigger the better , Also remember to adjust the maximum number of connections to the database connection pool . In vain .
the second : It's because how many threads you start can be adjusted , It can even be calculated every time .
Then we must pay attention to a problem is not to let any task into the queue . Once in the queue , The program immediately cools .

Would you , If we need to turn on 5 Child threads , But the number of core threads is only 4 individual , A task has entered the queue .
So this 4 Core threads will be blocked all the time , Wait for the main thread to wake up .
And what the main thread is doing at this time ?
Waiting for 5 Running results of threads , But it can only collect 4 results .
So it's going to wait .
Third : This is where multiple threads start transactions and insert data into the table , Beware of database deadlock .
The fourth one : Pay attention to the code in the program ,countDown Installation standard writing is to put finally In the code block , I'm here for the beauty of the screenshot , This step is omitted :
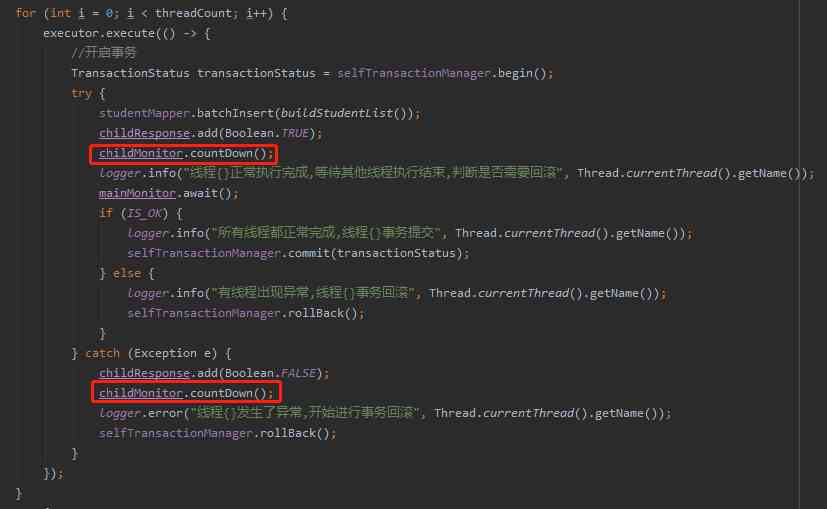
If you really want to use , Pay attention to . And this finally You have to think clearly and write , It's not random .
The fifth one : I'm just here to provide a way of thinking , And it's not a multithreaded transaction at all .
It also proves again that , Multithreading transaction is a pseudo proposition .
So it's not too much for me to give a pseudo consistency answer based on luck .
Sixth : Multithreading transaction: think about it from another angle , It can be understood as a distributed transaction ., You can use this case to understand distributed transactions . But the best way to solve distributed transactions is : Don't have distributed transactions !
Most of the solutions to distributed transactions are : Final consistency .
High cost performance , Most businesses can also accept .
Seventh : If you want to get this solution for production , Remember to communicate with business colleagues first , Can you accept this situation . The dilemma between speed and safety .
At the same time, keep a good interface for manual repair :

And finally
Pretty good , It's hard to avoid mistakes , If you find something wrong , You can bring it up in the message area , I'll modify it . Thank you for reading , I insist on originality , Thank you for your attention .
I am a why, A literary creator delayed by code , Not a big man , But like to share , He is a good Sichuan man who is warm and full of material .
also , Welcome to pay attention to me .