当前位置:网站首页>Flink analysis (II): analysis of backpressure mechanism
Flink analysis (II): analysis of backpressure mechanism
2022-07-06 17:28:00 【Stray_ Lambs】
Catalog
Flink TaskManager Memory structure
Span TaskManager The back pressure process of the system
be based on Credit The back pressure process of the system
TM Internal backpressure process
Flink Back pressure monitoring
Flink Back pressure mechanism
Backpressure is a dynamic feedback mechanism about processing capacity in a flow system , And it is feedback from downstream to upstream , Usually in the process of real-time data processing , The production speed of the upstream node is greater than the consumption speed of the downstream node . stay Flink in , Back pressure has two main parts : Span TaskManager The back pressure process and TaskManager Back pressure process in .

Flink TaskManager Memory structure
Let's see first Flink Memory management in the network transmission scenario .
First , every last Task It's all in TaskManager(TM) Run in , Every TM There's always A memory area is called NetworkBufferPool, This field exists by default 2048 Memory block MemorySegment( A default 32K), Indicates available memory .
then , every last Task There are input fields in tasks InputGate(IG) And output area ResultPartition(RP), It's all transmitted Bytes of data ( Because of network transmission , So you need to serialize ), And it's there Buffer in ,Buffer yes MemorySegment The wrapper class .
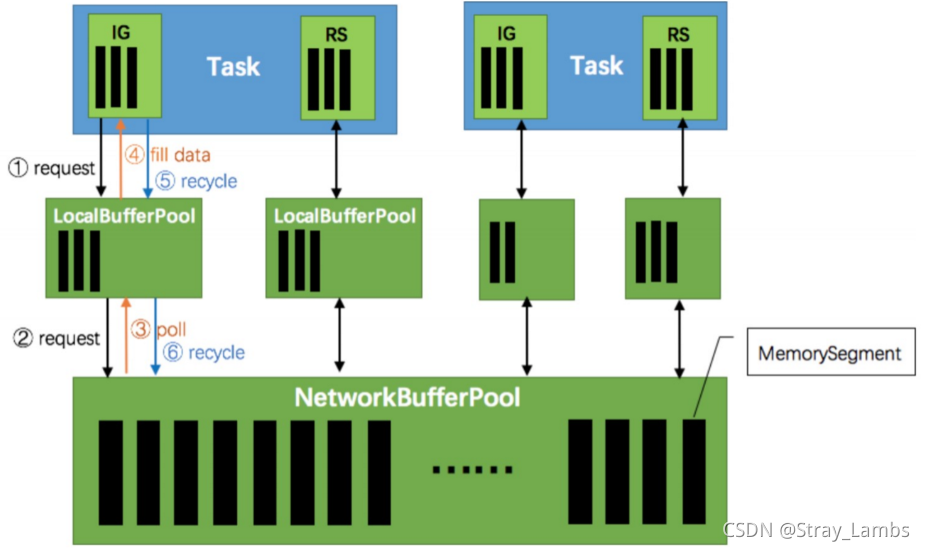
- According to the configuration ,Flink Will be in NetworkBufferPool Generate a certain number in 量( Default 2048, One 32K) Memory block MemorySegment, Total number of memory blocks 量 On behalf of 了 All available memory in network transmission .NetworkEnvironment and NetworkBufferPool yes Task Shared between , Every node (TaskManager - The process of running the task , Be similar to spark Of executor) It will only be true 例 Turn one .
- Task When the thread starts , Will send to NetworkEnvironment register ,NetworkEnvironment Would be Task Of InputGate(IG) and ResultPartition(RP) Create a... Respectively LocalBufferPool( Buffer pool ) And set up... That can be applied for MemorySegment( Memory block ) Count 量( It is generally evenly distributed ).IG The initial number of memory blocks of the corresponding buffer pool 量 And IG in InputChannel Count 量 Agreement ,RP The initial number of memory blocks of the corresponding buffer pool 量 And RP Medium ResultSubpartition Count 量 Agreement .不 too , Whenever a buffer pool is created or destroyed ,NetworkBufferPool Calculate the number of remaining free memory blocks 量, and Average distribution To the created buffer pool . Be careful , This process only specifies 了 The number of memory blocks that the buffer pool can use 量, There is no real allocation of memory blocks , Assign only when needed ( Dynamic distribution on demand ). by 什 Do you want to dynamically expand the buffer pool ? Because the more memory , It means that the system can 更 Easily deal with transient pressure 力( Such as GC),不 It will enter the backpressure state frequently , So we're gonna 利 Use that spare memory block .
- stay Task Thread execution 行 In the process , When Netty When the receiver receives data , by 了 take Netty Copy to Task in , InputChannel( the truth is that RemoteInputChannel) A memory block is requested from its corresponding buffer pool ( In the picture above ①). If there are no memory blocks available in the buffer pool and the number of requested 量 It's not up to the upper limit of the pool , Will go to NetworkBufferPool Apply for memory block ( In the picture above ②) And to InputChannel Fill in the data ( In the picture above ③ and ④). If the number of buffer pools applied 量 Reach the upper limit 了 Well ? perhaps NetworkBufferPool There are no memory blocks available 了 Well ? Now ,Task Of Netty Channel Will pause reading , The upstream sender will immediately respond to stop sending ,拓 Flutter will enter the backpressure state . When Task Thread writes data to ResultPartition when , It also requests memory blocks from the buffer pool , If there is no available memory block , It will block where the memory block is requested , To achieve the purpose of pause writing .
- When a block of memory is consumed ( At the input end, the bytes in the memory block are in reverse order 列 Become an object 了, At the output end, it refers to Bytes are written to Netty Channel 了), Would call Buffer.recycle() Method , Will return the memory block to LocalBufferPool ( In the picture above ⑤). If LocalBufferPool Number of current applications in 量 exceed 了 Chi Zirong 量( Due to the dynamic content mentioned above 量, Due to the newly registered Task Cause the pool to contain 量 smaller ), be LocalBufferPool The memory block will be recycled to NetworkBufferPool( In the picture above ⑥). If it doesn't exceed Chi Zirong 量, Will continue 留 In the pool , Reduce the cost of repeated applications .
Span TaskManager The back pressure process of the system

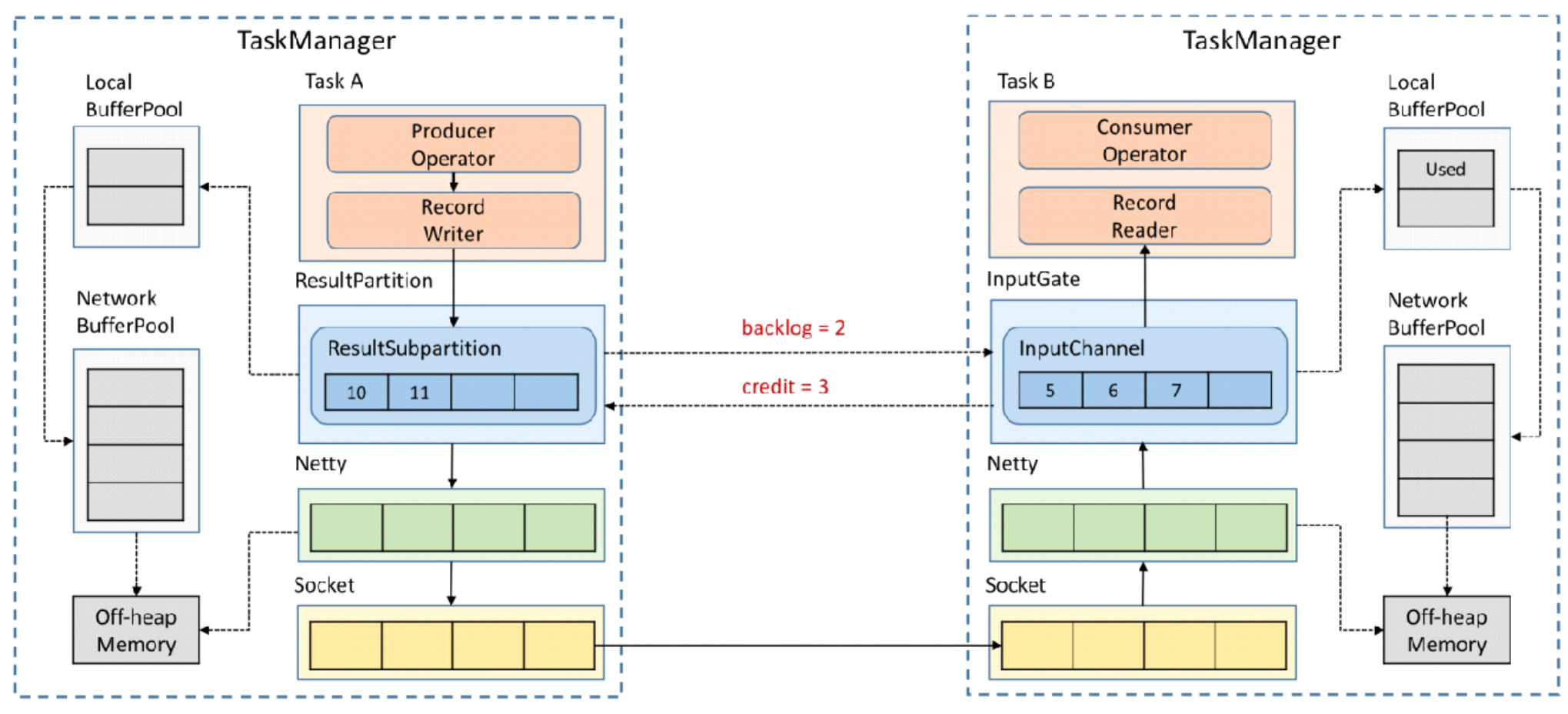
First ,TM in A Mission to TM in B Task sends data , therefore A As a producer ,B As a consumer . In the figure ResultPartition Medium ResultSubPartition and InputGate Medium InputChannel All are Task Exclusive , The memory blocks in it are all forward LocalBufferPool Apply for Buffer Space , then LocalBufferPool When it's not enough , Again to NetWorkBufferPool Apply for memory space , and NetWorkBufferPool yes TM Shared external memory ( stay TM Applied during initialization ). You can see the diagram of memory structure above .
then , after netty Of buffer after , The data will be copied to Socket Of Send Buffer in , Finally through Socket Send network request , hold Send Buffer Data from to Consumer Terminal Receive Buffer, And as shown in the figure , stay Consumer End up until Consumer Operator.
The normal production and consumption process is carried out according to the above figure . that , What is the cause of backpressure ?
Consider a situation , Production and consumption are twice as fast as consumption , That is to say, it is too late to consume , Look at the backpressure upstream TaskManager The transfer .
- InputChannel There will be a backlog of untimely consumption data , When the memory block is low , towards LocalBufferPool Apply for memory blocks .
- When LocalBufferPool When there are not enough memory blocks , Go further to NetWorkBufferPool Apply for memory block .
- When NetWorkBufferPool When the memory block is insufficient , Increased backlog of data , Lead to Netty In the middle of Buffer It's full, too , Then it leads to TCP Of Socket in Receiver The report Window=0( stay TCP Sliding window mechanism in the protocol ). here TM in B The task can no longer accommodate new data .
- that , The backlog of data is fed back to TM in A Within the mission , The order of memory full is ,Socket in send buffer->Netty Buffer->ResultSubPartition->LocalBufferPool->NetWorkBufferPool. Eventually led to producers Operator Medium Record Writer stop it , No longer write data .
Above is Flink1.5 Before the release , It's using buffer For storage , When buffer After full , Block the upstream flow . But the problem is , May cause multiplexing TCP The channel is occupied , Put the others in the same TCP Channel without flow pressure subTask It's blocked . therefore , stay 1.5 After the version , It uses be based on Credit Mechanism , Feedback from downstream Credit value , Indicates that upstream... Can be received buffer The number of , Upstream send on demand .
be based on Credit The back pressure process of the system

every time TesultSubPartition towards InputChannel When sending a message , Will send one back log size, Tell downstream how many messages to send , The downstream will calculate the remaining buffer Space , If buffer enough , Return to the upstream to inform the size of the message that can be sent ( Communication is still through Netty and Socket To communicate ). If there is not enough memory , Then tell us how many can be received at most credit, Even return 0, It means there is no space downstream , So that the upstream does not need to send data , Until downstream buffer Make room .
be based on credit The back pressure process of the system , Efficiency is higher than before , because As long as downstream InputChannel Run out of space , You can pass credit Let upstream ResultSubPartition Perceive , You don't have to go through netty and socket Layer by layer transmission . in addition , It also solves the problem due to a Task Back pressure causes TaskManager and TaskManager Between Socket Blocking problem .
TM Internal backpressure process

because operator The downstream buffer Run out of , here Record Writer Will be blocked , And because of Record Reader、Operator、Record Writer All belong to the same thread , therefore Record Reader It's also blocked . At this time, the upstream data is still being written , Before long network buffer Will be used up , Then similar to the previous , Jing Shi netty and socket, Pressure will be transmitted upstream .
Flink Back pressure monitoring
Flink In the implementation of , Only when Web The page switches to some Job Of Backpressure page , To this Job Trigger back pressure detection , Because back pressure detection is still very expensive .JobManager Will pass Akka For each TaskManager send out TriggerStackTraceSample news . By default ,TaskManager Will trigger 100 Time stack trace sampling , Each interval 50ms( That is to say, a back pressure test has to wait at least 5 Second ). And take this 100 The result of sub sampling is returned to JobManager, from JobManager To calculate the back pressure ratio ( The number of times back pressure appears / The number of samples taken ), In the end UI On .UI The default refresh period is one minute , The purpose is not to TaskManager Cause too much burden .
The cause of backpressure
According to the above Back pressure monitoring perhaps Task Metrics, You can locate the node of the backpressure problem , That is, the bottleneck of data processing , Then we can analyze the cause of backpressure . Here are some basic to complex reasons . Also note that , Backpressure may also be transient , such as , The short-term load is too large , Deal with the backlog of data when checkpoint generation or task restart , Will cause backpressure , But these scenes can usually be ignored . Another thing to note , The process of analyzing and solving the backpressure problem will also be affected by the discontinuity of the bottleneck itself .
System resources
First , You need to check the resource usage of the machine , image CPU、 The Internet 、 disk I/O etc. . If some resources are overloaded , You can do the following :
1、 Try to optimize your code ;
2、 For specific resource pairs Flink tuning ;
3、 Increase concurrency or add machines
Garbage collection
Performance problems often arise from long GC Duration . In this case, you can print GC journal , Or use some memory /GC Analyze tools to locate problems .
CPU/ Thread bottleneck
occasionally , If one or more threads cause CPU bottleneck , And then , Of the whole machine CPU The utilization rate is still relatively low , such CPU Bottlenecks are not easy to find . such as , If one 48 Nuclear CPU, There is a thread that becomes a bottleneck , At this time CPU The utilization rate of is only 2%. In this case, you can consider using code analysis tools to locate hot threads .
Thread contention
Follow up CPU/ The thread bottleneck problem is similar to , A subtask may become a bottleneck due to high thread contention for shared resources . alike ,CPU Analysis tools are also useful for probing such problems .
Uneven load
If the bottleneck is caused by data skew , You can try deleting skew data , Or by changing the data partition strategy, the data will be key Value splitting , Or you can perform local aggregation / Prepolymerization .
The above items are not all scenarios . Usually , Solve the bottleneck problem in the process of data processing , And then eliminate the back pressure , First, you need to locate the problem node ( The bottleneck is ), Then find the reason , Find out why , Generally, check the resource overload .
Reference resources
Flink Detailed series 9 -- Back pressure mechanism and treatment - Simple books
边栏推荐
- 吴军三部曲见识(四) 大家智慧
- Only learning C can live up to expectations top2 P1 variable
- Data transfer instruction
- À propos de l'utilisation intelligente du flux et de la carte
- JVM garbage collection overview
- Activiti directory (IV) inquiry agency / done, approved
- Flink 解析(一):基础概念解析
- [mmdetection] solves the installation problem
- 关于Stream和Map的巧用
- [ciscn 2021 South China]rsa writeup
猜你喜欢

Activiti directory (V) reject, restart and cancel process
Flink源码解读(三):ExecutionGraph源码解读
轻量级计划服务工具研发与实践
JVM运行时数据区之程序计数器
03个人研发的产品及推广-计划服务配置器V3.0
Flink 解析(二):反压机制解析

Deploy flask project based on LNMP
Program counter of JVM runtime data area
Jetpack compose 1.1 release, based on kotlin's Android UI Toolkit

关于Selenium启动Chrome浏览器闪退问题
随机推荐
CentOS7上Redis安装
[ciscn 2021 South China]rsa writeup
Resume of a microservice architecture teacher with 10 years of work experience
Control transfer instruction
Flink 解析(四):恢复机制
【逆向中级】跃跃欲试
Final review of information and network security (based on the key points given by the teacher)
8086 segmentation technology
Prototype chain inheritance
暑假刷题嗷嗷嗷嗷
PostgreSQL 14.2, 13.6, 12.10, 11.15 and 10.20 releases
Deploy flask project based on LNMP
mysql 基本增删改查SQL语句
Set up the flutter environment pit collection
Akamai浅谈风控原理与解决方案
Wu Jun's trilogy insight (V) refusing fake workers
Learn the wisdom of investment Masters
Activiti directory (IV) inquiry agency / done, approved
自动答题 之 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
JVM之垃圾回收器下篇