当前位置:网站首页>30. Few-shot Named Entity Recognition with Self-describing Networks 阅读笔记
30. Few-shot Named Entity Recognition with Self-describing Networks 阅读笔记
2022-07-07 10:02:00 【薰珞婷紫小亭子】
Author Information: ,
,  ,
,  ,
, ,

Institutions Information:
1. Chinese Information Processing Laboratory
2. State Key Laboratory of Computer Science, Institute of Software, Chinese Academy of Sciences, Beijing, China
3.University of Chinese Academy of Sciences, Beijing, China
4. Beijing Academy of Artifificial Intelligence, Beijing, China
ACL 2022
模型简称:SDNet
目录
3. Self-describing Networks for FS-NER
3.2 Entiry Recognition via Entity Generation
3.3 Type Description Construction via Mention Describing
Pre-training via Mention Describing and Entity Generation
4.2 Entity Recognition Fine-tuning
Abstract
小样本命名实体识别 (Few-shot NER)需要从有限的例子中精准捕获信息,并且能够从外部资源中转移有用得知识。本文,针对小样本NER,我们提出一个自描述机制 (self-describing mechanism),该机制能够有效的利用说明性实例,并通过使用通用概念集来描述实体类型和实体提及(mention), 精确地从外部资源转移知识。具体来说,我们设计了Self-describing Networks (SDNet), 该网络是一个Seq2Seq生成模型,其能够普遍使用概念描述mention,自动将新的实体类型隐射到概念,并自适应识别按需实体。
我们使用大规模的语料预训练SDNet,并且在8个不同领域的基准数据集上进行了实验。实验结果表明SDNet在8个基准数据集上,均取得了不错的性能,并在6个数据集上取得了SOTA的性能。 这也证明了该方法的有效性和鲁棒性。(effectiveness and robustness)
Mention通常被定义为自然语言文本中对实体的引用,该实体可以是命名(named)实体、名义(nominal)实体或代词(pronominal)实体。

1. Introduction
FS-NER (Few-shot NER)目的是通过几个例子来识别与新的实体类型对应的实体提及 (entity mention)。FS-NER是一种很有前途的开放域NER技术,它包含各种不可预见的类型和非常有限的例子,因此近年来引起了广泛的关注
FS-NER的主要挑战是怎样使用少量的例子精确建模不可见实体类型的语义。为了实现这个目标,FS-NER需要从少样本中有效的捕获信息,同时,从外部资源中开发和转移有用的知识。
挑战一:limited information challenge
在说明性的例子中所包含的信息是非常有限的,
挑战二:knowledge mismatch challenge
外部 知识通常与新任务不直接匹配,因为它可能包含不相关的、异构的、甚至是相互冲突的知识。
为此,本文提出了一种FS-NER的自描述机制。自描述机制背后的主要思想是,所有的实体类型都可以使用相同的概念集来描述,并且类型和概念之间的映射可以被普遍地建模和学习。这样,就可以使用相同的概念集,通过统一描述不同的实体类型来解决知识不匹配的问题。
例如:
在下图1中,不同主题类型(types)会与相同的概念集相匹配(e.g., park, garden, country……),因此,不同来源的知识可以被普遍地描述和转移。此外,由于概念映射是通用的,少数例子仅用于构造新类型和概念之间的映射,因此可以有效地解决有限的信息问题。
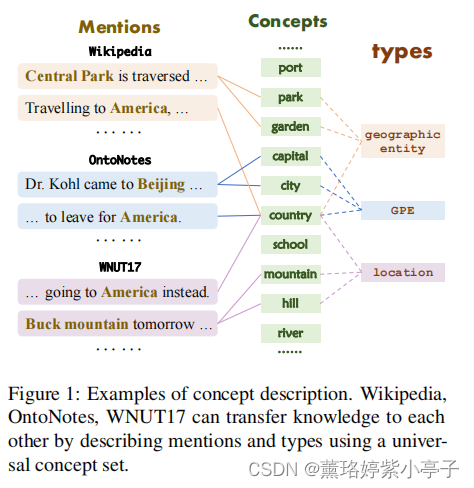
基于上述思想,我们提出了自描述网络SDNet,这是一种Seq2Seq生成网络,它可以普遍地使用概念来描述提及,自动将新的实体类型映射到概念上,并自适应地按需识别实体。 具体来说,1)为了捕获提及 (mention)的语义信息,SDNet生成一组通用的概念作为其描述。2)为了将实体类型映射到概念,SDNet生成并融合具有相同实体类型的提及的概念描述。 3)为了识别实体,SDNet通过一个丰富概念的前缀提示符(prefix prompt)直接生成句子中的所有实体,该提示符包含目标实体类型及其概念描述。
因为这个概念集是通用的,所以我们在大规模的、易于访问的web资源上对SDNet进行了预训练。具体地说,我们收集了一个链接,它包含了预训练的数据集,其中包含56M个句子,超过31K个概念。
SDNet通过将提及和实体类型投影到一个通用的概念空间,可以有效地丰富实体类型来解决有限的信息问题,普遍表示不同的模式来解决知识不匹配问题,并可以有效地进行统一的预训练。此外,上述任务均采用前缀提示 (prefix prompt)机制建模单一生成模型,区分不同的任务,使模型可控、通用,可以连续训练。
我们在8个不同领域的FS-NER基准测试上进行了实验。实验表明,SDNet具有非常强的性能,并在6个数据集上取得了SOTA性能。
本文主要贡献:
- 我们提出了一种FS-NER的自描述机制,通过使用通用概念集来描述实体类型和提及,可以有效地解决有限的信息挑战和知识不匹配的挑战。
- 我们提出了自描述网络SDNet,这是一种Seq2Seq生成网络,它可以普遍地使用概念来描述提及,自动将新的实体类型映射到概念上,并按需自适应地识别实体。
- 我们在大规模的开放数据集上对SDNet进行了预训练,这为Fs-NER提供了一个通用的知识,并可以有利于许多未来的NER研究。
2. Related Work
3. Self-describing Networks for FS-NER
在本节中,我们将描述如何使用自我描述网络来构建少量的实体识别器和识别实体。图3(b)展示了完整的过程。具体的,分为两个部分
1)Mention describing
生成mention的概念描述
2)Entity generation (实体生成)
自适应地生成对应于理想的新类型的实体提及 (entity mention)。
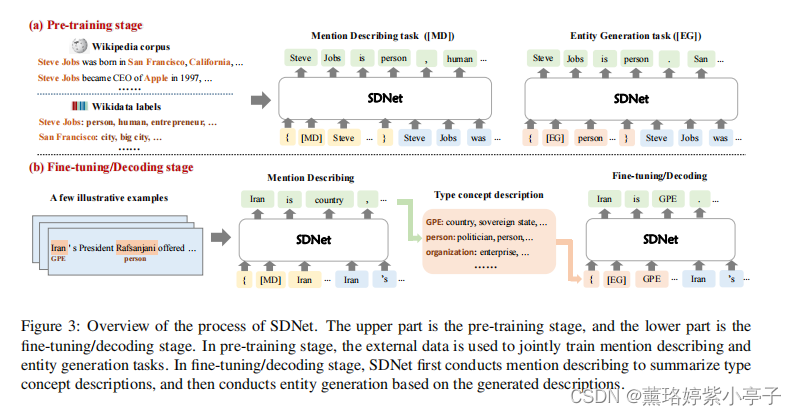
使用SDNet,NER可以在实体生成过程中输入类型描述,直接执行NER。给定一种新的类型,它的类型描述是通过提及描述其说明性实例来建立的。下面,我们将首先介绍SDNet,然后描述如何构建类型描述和构建few-shot实体识别器。
3.1 Self-describing Networks
SDNet主要有两个生成任务:mention describing 和Entity generation。提及描述是生成提及的概念描述,实体生成是自适应地生成实体提及。为了指导上述两个过程,SDNet使用了不同的prompts P, 生成不同的输出Y。如图2所示:
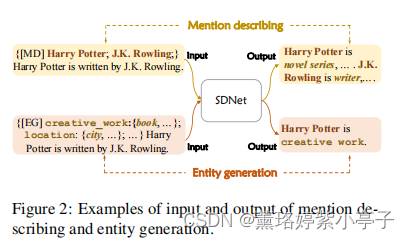
对mention describing而言, prompt包含一个任务描述器 [MD],以及目标实体mention。对实体识别而言,prompt包含一个任务描述器 [EG],以及一系列新的实体和它们对应的描述。
输入: prompt P 和句子sentence S (  = P
= P S)
S)
输出:SDNet会生成一个序列Y,Y包含提及描述 (mention describing)和实体生成(entity generation)结果。


我们可以看出,使用上述两代过程可以有效地执行few-shot 实体识别。对于实体识别,我们可以将目标实体类型的描述放到提示符 prompt中,然后通过实体生成过程自适应地生成实体。要构造一种新型的实体识别器,我们只需要其类型描述,通过总结其说明性实例的概念描述,就可以有效地构建其类型描述。
3.2 Entiry Recognition via Entity Generation
在SDNet中,实体识别是由实体生成来执行的,给定的实体生成提示为 和句子
和句子 。
。
![P_{EG} = \{ [EG] t_{1}: \{ {l_{1}^{1}, ...{l_{1}^{m_{1}}} \}; t_{2}: \{ l_{2}^{1}, ...{l_{2}^{m_{2}}} \}; ... \}](http://img.inotgo.com/imagesLocal/202207/07/202207071002353049_7.gif)

举例说明:
实例:" Harry Potter is written by J.K. Rowling.”
1) identify entity of PERSON type
输入格式:{[EG] person: {actor, writer}}
SDNet生成结果:“J.K. Rowling is person”
2) identity entity of CREATIVE_WORK type
输入格式:{[EG] creative_work: {book, music}}
结果:“Harry Potter is creative_work”
3.3 Type Description Construction via Mention Describing
为了用几个说明性示例来构建新类型的类型描述,SDNet首先通过提到描述来获得说明性示例中每个提到的概念描述。然后通过总结所有的概念描述,构建每种类型的类型描述。
Mention Describing
输入:![P_{MD} = \{ [MD] e_{1}; e_{2}; ... \}](http://img.inotgo.com/imagesLocal/202207/07/202207071002353049_5.gif%20%3D%20%5C%7B%20%5BMD%5D%20e_%7B1%7D%3B%20e_%7B2%7D%3B%20...%20%5C%7D) , 将
, 将  和X拼接作为输入。
和X拼接作为输入。
输出:“ is
is  , ...,
, ..., ;
;  is
is  , ...,
, ...,  ;...”
;...”
其中, 表示第i-th实体提及的第j-th概念。
表示第i-th实体提及的第j-th概念。
Type Description Construction
然后SDNet总结生成的概念来描述特定新类型的精确语义。具体来说,所有相同类型 t 的概念描述将融合到C,视为类型t的描述。并构造了类型描述M={(t,C)}。然后将所构造的类型描述合并到中,以指导实体的生成。
Filtering Strategy
由于下游新颖类型的多样化,SDNet可能没有足够的知识来描述这些类型,因此迫使SDNet描述它们可能会导致不准确的描述。为了解决这个问题,我们提出Filtering Strategy,使得SDNet能够拒绝生成不可靠的描述。
具体来说,针对不确定的实例,SDNet将其生成为other类。给定一个新的类型和一些说明性的实例,我们将在这些实例的概念描述中计算other实例的频率。如果在说明性实例上生成other实例的频率大于0.5,我们将删除类型描述,并直接使用类型名称作为。我们将在第4.1节中描述SDNet如何学习过滤策略。
4. Learning
4.1 SDNet Pre-training
本文使用wikipedia和wikidata作为外部知识源。 (本文使用20210401version的wikipedia )
Entity Mention Collection
SDNet的预训练,需要收集<e,T,X>,其中,e是实体提及,T是实体类型,X是句子。
e.g., <J.K. Rowling; person, writer, ...; J.K. Rowling writes ...>
共计获得31K 类型。
Type Descriptioon Building
为了训练SDNet, 我们需要概念描述 ,其中
,其中 ,
,  是类型
是类型 的相关概念。本文使用上述收集的实体类型作为概念,并构建如下类型描述。给定一个实体类型,我们收集它的所有同时出现的实体类型作为它的描述概念。这样,对于每个实体类型,我们都有一个描述的概念集。由于一些实体类型有一个非常大的描述概念集,我们在效率预训练中随机抽样不超过N(本文N取10个)的概念。
的相关概念。本文使用上述收集的实体类型作为概念,并构建如下类型描述。给定一个实体类型,我们收集它的所有同时出现的实体类型作为它的描述概念。这样,对于每个实体类型,我们都有一个描述的概念集。由于一些实体类型有一个非常大的描述概念集,我们在效率预训练中随机抽样不超过N(本文N取10个)的概念。
Pre-training via Mention Describing and Entity Generation
给定句子和它的提及-类型元组 : ,其中
,其中  是第i-th实体提及的类型集合。
是第i-th实体提及的类型集合。 是
是 的j-th类型。
的j-th类型。  是句子X中的实体提及。然后,我们构造类型描述,并将这些三元组转换为预训练的实例。
是句子X中的实体提及。然后,我们构造类型描述,并将这些三元组转换为预训练的实例。

4.2 Entity Recognition Fine-tuning
如上所述,SDNet可以使用手动设计的类型描述直接识别实体。但是SDNet也可以使用说明性实例自动构建类型描述,并通过微调进行进一步改进。具体来说 针对给定的<e,T,X>,我们首先构造不同类型的描述,接下来构造一个实体生成Prompt, 然后生成序列 , 通过最优化公式(2)来微调SDNet
, 通过最优化公式(2)来微调SDNet
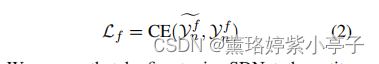
5 Experiment
5.1 Settings
Datasets

Baselines
1) BERT-base
2)T5-base
3)T5-base-prompt: 提示prompt的T5基版本,使用实体类型作为提示
4)T5-base-DS
5) RoBERTa-based
6) Prototypical network based RoBERTa model Proto and its distantly supervised pre-training version Proto-DS
7) MRC model SpanNER which needs to design the description for each label and its distantly supervised pre-training version SpanNER-DS
5.2 Main Results
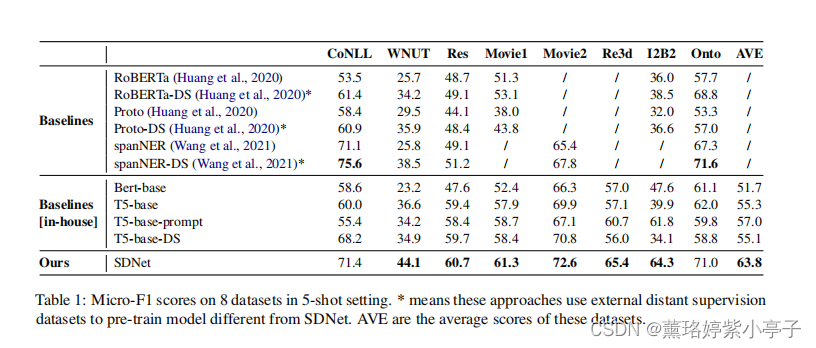
结论:
1)通过在生成体系结构中对NER知识进行普遍的建模和预训练,自描述网络可以有效地处理few-shotNER知识。
2) 由于信息有限的问题,将外部知识转移到FSNER模型是至关重要的。
3) 由于知识的不匹配,有效地将外部知识转移到新的下游类型中具有挑战性。
5.3 Effects of Shot Size
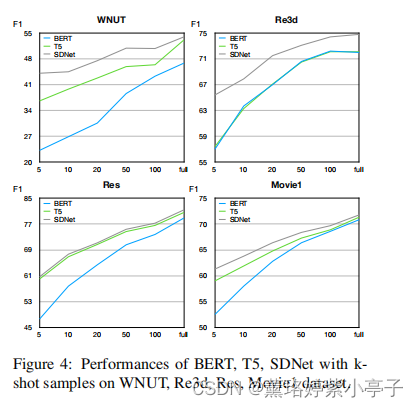
结论:
1)SDNet可以在所有不同的镜头设置下获得更好的性能。此外,这些改进在低镜头设置上更为显著,这验证了SDNet背后的直觉。
2)基于生成的模型通常比基于分类器的BERT模型具有更好的性能。我们认为,这是因为基于生成的模型可以通过利用标签话语更有效地捕获类型的语义,因此可以实现更好的性能,特别是在低镜头设置中。
3)除Res外,SDNet在几乎所有数据集上的性能都显著优于T5,这表明了所提出的自描述机制的有效性。
5.4 Ablation Study
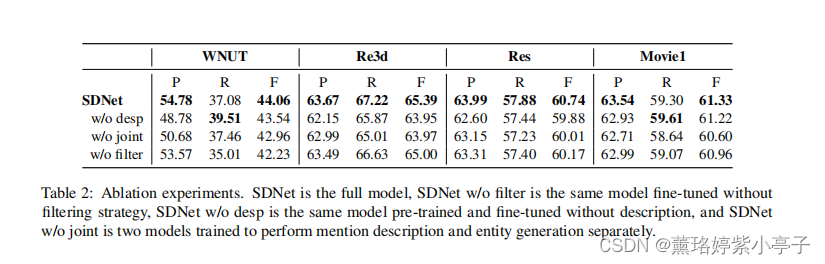
结论:
1)类型描述对于SDNet传输知识和捕获类型语义至关重要。
2)描述和实体生成网络中的联合学习过程是捕获类型语义的有效方法。
3)过滤策略可以有效地缓解不匹配知识的转移。
边栏推荐
- SwiftUI Swift 内功之如何在 Swift 中进行自动三角函数计算
- Use references
- In depth learning autumn recruitment interview questions collection (1)
- Rationaldmis2022 advanced programming macro program
- R语言使用quantile函数计算评分值的分位数(20%、40%、60%、80%)、使用逻辑操作符将对应的分位区间(quantile)编码为分类值生成新的字段、strsplit函数将学生的名和姓拆分
- Internet Protocol
- 《通信软件开发与应用》课程结业报告
- VIM command mode and input mode switching
- 一度辍学的数学差生,获得今年菲尔兹奖
- 千人规模互联网公司研发效能成功之路
猜你喜欢

MySQL安装常见报错处理大全

Automated testing framework
Complete collection of common error handling in MySQL installation
![110. Network security penetration test - [privilege promotion 8] - [windows sqlserver xp_cmdshell stored procedure authorization]](/img/62/1ec8885aaa2d4dca0e764b73a1e2df.png)
110. Network security penetration test - [privilege promotion 8] - [windows sqlserver xp_cmdshell stored procedure authorization]

OneDNS助力高校行业网络安全

请查收.NET MAUI 的最新学习资源

Rationaldmis2022 array workpiece measurement
Flet tutorial 17 basic introduction to card components (tutorial includes source code)
相机标定(2): 单目相机标定总结
Excel公式知多少?
随机推荐
2022年在启牛开华泰的账户安全吗?
Software design - "high cohesion and low coupling"
Suggestions on one-stop development of testing life
Matlab implementation of Huffman coding and decoding with GUI interface
Fleet tutorial 14 basic introduction to listtile (tutorial includes source code)
Ask about the version of flinkcdc2.2.0, which supports concurrency. Does this concurrency mean Multiple Parallelism? Now I find that mysqlcdc is full
sql里,我想设置外键,为什么出现这个问题
[full stack plan - programming language C] basic introductory knowledge
Blog moved to Zhihu
Zhou Yajin, a top safety scholar of Zhejiang University, is a curiosity driven activist
总结了200道经典的机器学习面试题(附参考答案)
R语言可视化分面图、假设检验、多变量分组t检验、可视化多变量分组分面箱图(faceting boxplot)并添加显著性水平、添加抖动数据点(jitter points)
防红域名生成的3种方法介绍
正在运行的Kubernetes集群想要调整Pod的网段地址
When sink is consumed in mysql, the self incrementing primary key has been set in the database table. How to operate in Flink?
Talk about SOC startup (11) kernel initialization
CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
Have you ever met flick Oracle CDC, read a table without update operation, and read it repeatedly every ten seconds
What is high cohesion and low coupling?
STM32 entry development uses IIC hardware timing to read and write AT24C08 (EEPROM)