当前位置:网站首页>Interviewer: how about shardingsphere
Interviewer: how about shardingsphere
2020-11-06 21:30:00 【Xiaoliu】
List of articles
[toc]
Before learning, first understand the concept of sub database and sub table :https://spiritmark.blog.csdn.net/article/details/109524713
One 、ShardingSphere brief introduction
In database design, consider vertical database and vertical table . As the amount of data in the database increases , Don't immediately think about horizontal segmentation , First consider cache processing , Read / write separation , send By indexing and so on , If these methods can't solve the problem at all , Then consider the horizontal sub database and horizontal sub table .
Problems caused by sub database and sub table :
- Cross node join query problem ( Pagination 、 Sort )
- Multiple data source management issues
Apache ShardingSphere Is a set of open source distributed database middleware solutions composed of the ecosystem , It consists of JDBC、 Proxy and Sidecar( Planning ) this 3 They are independent of each other , But it can mix deployment and use of product composition . They all provide standardized data fragmentation 、 Distributed transaction and database governance functions , It can be applied to such as Java isomorphism 、 Heterogeneous languages 、 Various application scenarios such as cloud native .
Apache ShardingSphere Positioning as a relational database middleware , Designed to be fully reasonable in distributed fields Using the computing and storage capabilities of relational databases , Instead of implementing a new relational database . It doesn't change through focus , And then grasp the essence of things . Relational databases still have a huge market today , It's the cornerstone of every company's core business , The future is hard to shake , At present, we pay more attention to the increment based on the original , Not subversion .
Two 、Sharding-JDBC
Sharding-JDBC It's lightweight java frame , It's an enhanced version of JDBC drive , Simplify the data related operations after sub database and sub table . 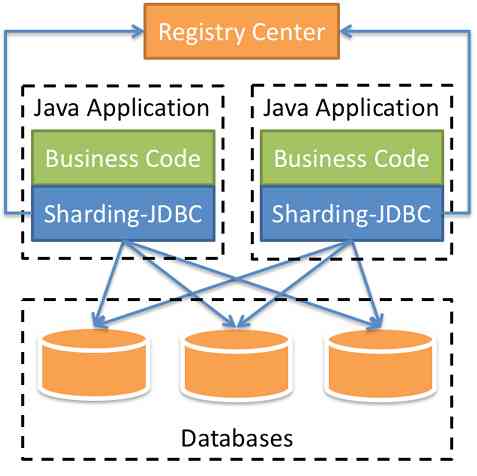 Create a new project and add dependencies :
Create a new project and add dependencies :
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-parentartifactId>
<version>2.2.1.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.20version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.0.0-RC1version>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.0.5version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
2.1 Sharding-JDBC Realize the level table
① According to the way of horizontal table , Create databases and database tables
Horizontal table rules : If you add cid It's even numbers that add data course_1, If it is an odd number, add it to course_2 
CREATE TABLE `course_1` (
`cid` bigint(16) NOT NULL,
`cname` varchar(255) ,
`userId` bigint(16),
`cstatus` varchar(16) ,
PRIMARY KEY (`cid`)
)
② Write entities and Mapper class
@Data
public class Course {
private Long cid;
private String cname;
private Long userId;
private String cstatus;
}
@Repository
public interface CourseMapper extends BaseMapper<Course> {
}
③ Detailed configuration file
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m1.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
table-strategy:
inline:
shardingcolumn: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ test
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 10; i++) {
Course course = new Course();
course.setCname("java" + i);
course.setUserId(100L);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid",493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
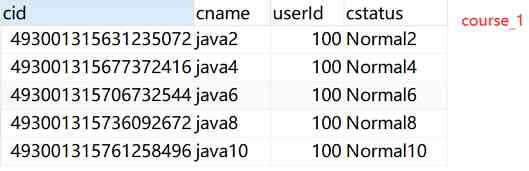
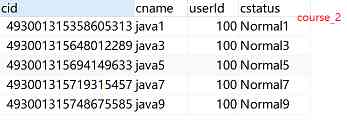
2.2 Sharding-JDBC Realize the horizontal sub database
① Demand analysis 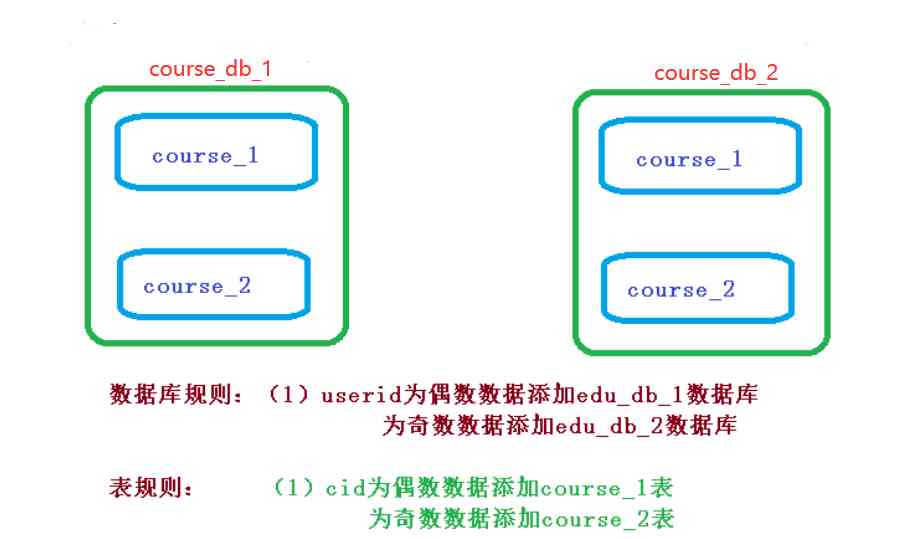 ② Create databases and tables
② Create databases and tables
③ Detailed configuration file
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ Test code
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
CourseMapper courseMapper;
@Test
public void addCourse() {
for (int i = 1; i 20; i++) {
Course course = new Course();
course.setCname("java" + i);
int random = (int) (Math.random() * 10);
course.setUserId(100L + random);
course.setCstatus("Normal" + i);
courseMapper.insert(course);
}
}
@Test
public void queryCourse() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("cid", 493001315358605313L);
Course course = courseMapper.selectOne(wrapper);
System.out.println(course);
}
}
Query the actual corresponding SQL: 
2.3 Sharding-JDBC Working with common tables
Public table :
- A table that stores fixed data , Table data rarely changes , Queries are often associated
- Create a common table with the same structure in each database
① Thought analysis 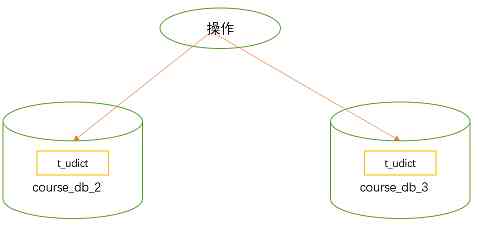 ② Create a common table in the corresponding database
② Create a common table in the corresponding database t_udict,并创建对应实体和 Mapper``
CREATE TABLE `t_udict` (
`dict_id` bigint(16) NOT NULL,
`ustatus` varchar(16) ,
`uvalue` varchar(255),
PRIMARY KEY (`dict_id`)
)
③ Detailed configuration file
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_2?serverTimezone=GMT%2B8
username: root
password: 1234
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db_3?serverTimezone=GMT%2B8
username: root
password: 1234
sharding:
tables:
course:
actual-data-nodes: m$->{1..2}.course_$->{1..2}
key-generator:
column: cid
type: SNOWFLAKE
database-strategy:
inline:
sharding-column: userId
algorithm-expression: m$->{userId%2+1}
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid%2+1}
t_udict:
key-generator:
column: dict_id
type: SNOWFLAKE
broadcast-tables: t_udict
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
④ To test
After testing : Data is inserted into each table in each library , Deleting will also delete all data .
@RunWith(SpringRunner.class)
@SpringBootTest
public class ShardingSphereTestApplication {
@Autowired
UdictMapper udictMapper;
@Test
public void addUdict() {
Udict udict = new Udict();
udict.setUstatus("a");
udict.setUvalue(" Enabled ");
udictMapper.insert(udict);
}
@Test
public void deleteUdict() {
QueryWrapper<Udict> wrapper = new QueryWrapper<>();
wrapper.eq("dict_id", 493080009351626753L);
udictMapper.delete(wrapper);
}
}
2.4 Sharding-JDBC Read and write separation
To ensure the stability of database products , Many databases have dual hot standby function . That is to say , The first database server is the production server that provides the business of adding, deleting and modifying ; The second database server is mainly used for reading operations .
Sharding-JDBC adopt sql Sentence semantic analysis , Realize the separation of reading and writing , No data synchronization , Data synchronization usually automatically synchronizes between database clusters .
Detailed configuration file :
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m0,s0
m0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3306/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
s0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.182.200:3307/course_db?serverTimezone=GMT%2B8
username: root
password: 1234
masterslave:
master-data-source-name: m0
slave-data-source-names: s0
props:
sql:
show: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: false
After testing : Add, delete and modify operations will pass master database , meanwhile master The database will synchronize data to slave database ; Check operations are all through slave database .
3、 ... and 、Sharding-Proxy
Sharding-Proxy It is positioned as Transparent database proxy side , Provide the server version that encapsulates the binary protocol of the database , Used to support heterogeneous languages , At present, only MySQL and PostgreSQL edition .
Sharding-Proxy It's a stand-alone application , Need to install Service , Perform sub database and sub table or read / write separation configuration , Startup and use . 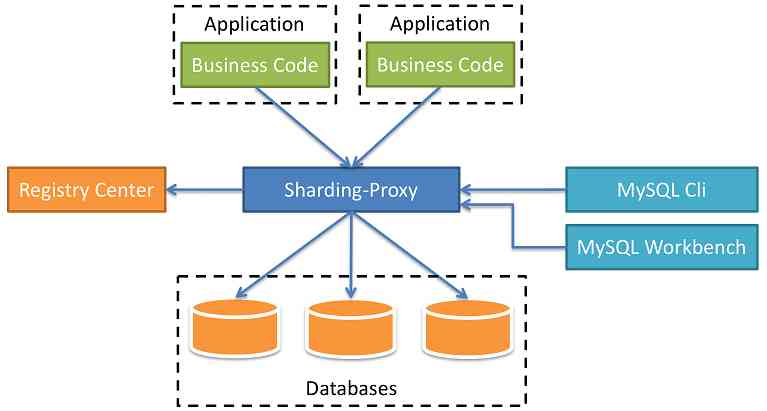 <br>
<br> Sharding-proxy The use of reference :Sharding-Proxy Basic use of . Search on wechat : Xiao Liu in the whole stack
版权声明
本文为[Xiaoliu]所创,转载请带上原文链接,感谢
边栏推荐
- Take you to learn the new methods in Es5
- 非易失性MRAM存储器应用于各级高速缓存
- Bitcoin once exceeded 14000 US dollars and is about to face the test of the US election
- MRAM高速缓存的组成
- 2020-08-30:裸写算法:二叉树两个节点的最近公共祖先。
- mongo 用户权限 登录指令
- How to start the hidden preferences in coda 2 on the terminal?
- 递归、回溯算法常用数学基础公式
- 打工人好物——磨炼钢铁意志就要这样高效的电脑
- How much disk space does a file of 1 byte actually occupy
猜你喜欢

2020-08-20:GO语言中的协程与Python中的协程的区别?
Vue communication and cross component listening state Vue communication
Why is quicksort so fast?
To teach you to easily understand the basic usage of Vue codemirror: mainly to achieve code editing, verification prompt, code formatting
Axios learning notes (2): easy to understand the use of XHR and how to package simple Axios
ES中删除索引的mapping字段时应该考虑的点
How much disk space does a new empty file take?
Building a new generation cloud native data lake with iceberg on kubernetes
Stickinengine architecture 12 communication protocol
Helping financial technology innovation and development, atfx is at the forefront of the industry
随机推荐
Elasticsearch database | elasticsearch-7.5.0 application construction
C language I blog assignment 03
ERD-ONLINE 免费在线数据库建模工具
What grammar is it? ]
磁存储芯片STT-MRAM的特点
How much disk space does a new empty file take?
[elastic search engine]
面试官: ShardingSphere 学一下吧
How to manage the authority of database account?
ES6 learning notes (3): teach you to use js object-oriented thinking to realize the function of adding, deleting, modifying and checking tab column
细数软件工程----各阶段必不可少的那些图
Zero basis to build a web search engine of its own
Introduction to the development of small game cloud
Zero basis to build a web search engine of its own
An article will introduce you to CSS3 background knowledge
ORA-02292: 违反完整约束条件 (MIDBJDEV2.SYS_C0020757) - 已找到子记录
GitHub: the foundation of the front end
谷歌浏览器实现视频播放加速功能
git远程库回退指定版本
(2) ASP.NET Core3.1 Ocelot routing