当前位置:网站首页>强化學習基礎記錄
强化學習基礎記錄
2022-07-06 13:52:00 【喜歡庫裏的强化小白】
强化學習中Q-learning和Saras的對比
多智能體强化學習小白一枚,最近在學習强化學習基礎,在此記錄,以防忘記。
一、Q-learning
Q-learing最基礎的强化學習算法,通過Q錶存儲狀態-動作價值,即Q(s,a),可以用在狀態空間較小的問題上,當狀態空間維度很大時,需要配合神經網絡,擴展成DQN算法,處理問題。
- Value-based
- Off-Policy
看了很多有關On-Policy和Off-Policy的博客,一直沒太理解二者的區別,搞得一頭霧水,前兩天看了一個博主的回答,才有了更深入的理解,這裏附上鏈接。
鏈接: on-policy和off-policy有什麼區別?
當Q-learning更新時,雖然用到的數據是當前policy產生的,但是所更新的策略不是產生這些數據的策略(注意更新公式中的max),這裏可以這樣理解:這裏的max操作是為了選取能够獲得更大Q值的動作,更新Q錶,但實際回合未必會采取改改動,所以是Off-Policy的。 - 偽代碼

- 實現
這裏用的環境是莫煩老師教程裏的尋寶遊戲,通過列錶進行維護,—#-T,其中最後一個比特置T是寶藏,#代錶玩家現處的比特置,走到最右格,發現寶藏,遊戲結束。
代碼實現參考了一個博主,找不到鏈接了。。。。。
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6個狀態,一維數組長度
ACTIONS = [-1, 1] # 兩個狀態,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # 學習率
gamma = 0.9 # 獎勵遞减值
max_episodes = 10 # 最大回合數
fresh_time = 0.3 # 移動間隔時間
# q_table
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action: 1. 隨機探索以及對於沒有探索過的比特置進行探索,否則選擇reward最大的那個動作
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
#新狀態 = 當前狀態 + 移動狀態
new_state = state + action
reward = 0
#右移加0.5
#往右移動,更靠近寶藏,獲得+0.5獎勵
if action > 0:
reward += 0.5
#往左移動,遠離寶藏,獲得-0.5獎勵
if action < 0:
reward -= 0.5
#下一步到達寶藏,給予最高獎勵+1
if new_state == N_STATES - 1:
reward += 1
#如果向左走到頭,還要左移,獲得最低負獎勵-1
#同時注意,要定義一下新狀態還在此,不然會報錯
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# 達到目的地
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
def q_learning():
for epoch in range(max_episodes):
step = 0 # 移動步驟
state = 0 # 初始狀態
update_env(state, epoch, step)
while state != N_STATES - 1:
cur_action = choose_action(state, q_table)
new_state, reward = get_env_feedback(state, cur_action)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, :].max()
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state = new_state
update_env(state, epoch, step)
step += 1
return q_table
q_learning()
二、Saras
Saras也是强化學習中最基礎的算法,同時也是用Q錶存儲Q(s,a),這裏之所以叫Saras,是因為一個transition包含(s,a,r,a,s)五元組,即Saras。
- Value-based
- On-Policy
這裏對比Q-learning,我們便可知道,這裏用到的數據是當前policy產生的,且更新Q值的時候,是基於新動作和新狀態的Q值,新動作會被執行(注意更新公式中沒有max),所以是On-Policy。 - 偽代碼

- 實現
這裏參考Q-learning做了簡單修改,這裏要基於新的狀態,重新選擇一次動作,而且要執行該動作,此外更新Q值的時候,直接基於該狀態和動作對應的Q值更新。
import numpy as np
import pandas as pd
import time
N_STATES = 6 # 6個狀態,一維數組長度
ACTIONS = [-1, 1] # 兩個狀態,-1:left, 1:right
epsilon = 0.9 # greedy
alpha = 0.1 # 學習率
gamma = 0.9 # 獎勵遞减值
max_episodes = 10 # 最大回合數
fresh_time = 0.3 # 移動間隔時間
# q_table
#生成(N_STATES,len(ACTIONS)))的Q值空錶
q_table = pd.DataFrame(np.zeros((N_STATES, len(ACTIONS))), columns=ACTIONS)
# choose action:
#0.9概率貪心,0.1概率隨機選擇動作,保持一定探索性
def choose_action(state, table):
state_actions = table.iloc[state, :]
if np.random.uniform() > epsilon or state_actions.all() == 0:
action = np.random.choice(ACTIONS)
else:
action = state_actions.argmax()
return action
def get_env_feedback(state, action):
#新狀態 = 當前狀態 + 移動狀態
new_state = state + action
reward = 0
#右移加0.5
#往右移動,更靠近寶藏,獲得+0.5獎勵
if action > 0:
reward += 0.5
#往左移動,遠離寶藏,獲得-0.5獎勵
if action < 0:
reward -= 0.5
#下一步到達寶藏,給予最高獎勵+1
if new_state == N_STATES - 1:
reward += 1
#如果向左走到頭,還要左移,獲得最低負獎勵-1
#同時注意,要定義一下新狀態還在此,不然會報錯
if new_state < 0:
new_state = 0
reward -= 1
return new_state, reward
#維護環境
def update_env(state, epoch, step):
env_list = ['-'] * (N_STATES - 1) + ['T']
if state == N_STATES - 1:
# 達到目的地
print("")
print("epoch=" + str(epoch) + ", step=" + str(step), end='')
time.sleep(2)
else:
env_list[state] = '#'
print('\r' + ''.join(env_list), end='')
time.sleep(fresh_time)
#更新Q錶
def Saras():
for epoch in range(max_episodes):
step = 0 # 移動步驟
state = 0 # 初始狀態
update_env(state, epoch, step)
cur_action = choose_action(state, q_table)
while state != N_STATES - 1:
new_state, reward = get_env_feedback(state, cur_action)
new_action = choose_action(new_state,q_table)
q_pred = q_table.loc[state, cur_action]
if new_state != N_STATES - 1:
q_target = reward + gamma * q_table.loc[new_state, new_action]
else:
q_target = reward
q_table.loc[state, cur_action] += alpha * (q_target - q_pred)
state,cur_action = new_state,new_action
update_env(state, epoch, step)
step += 1
return q_table
Saras()
第一次寫博客,可能理解存在問題,還望指正錯誤。
边栏推荐
- 抽象类和接口的区别
- Canvas foundation 2 - arc - draw arc
- 【九阳神功】2022复旦大学应用统计真题+解析
- The latest tank battle 2022 - full development notes-3
- Miscellaneous talk on May 27
- 仿牛客技术博客项目常见问题及解答(一)
- C language Getting Started Guide
- Mortal immortal cultivation pointer-2
- 2022 Teddy cup data mining challenge question C idea and post game summary
- 【九阳神功】2018复旦大学应用统计真题+解析
猜你喜欢
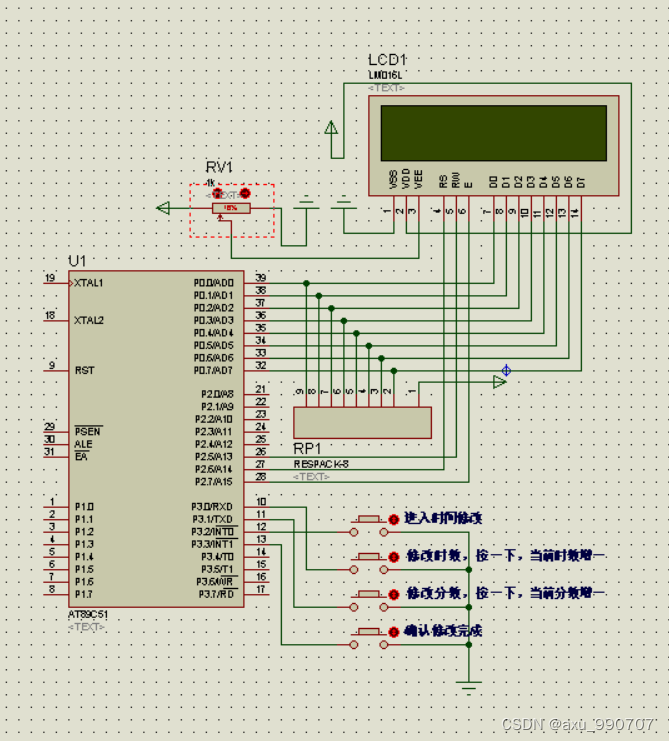
(original) make an electronic clock with LCD1602 display to display the current time on the LCD. The display format is "hour: minute: Second: second". There are four function keys K1 ~ K4, and the fun
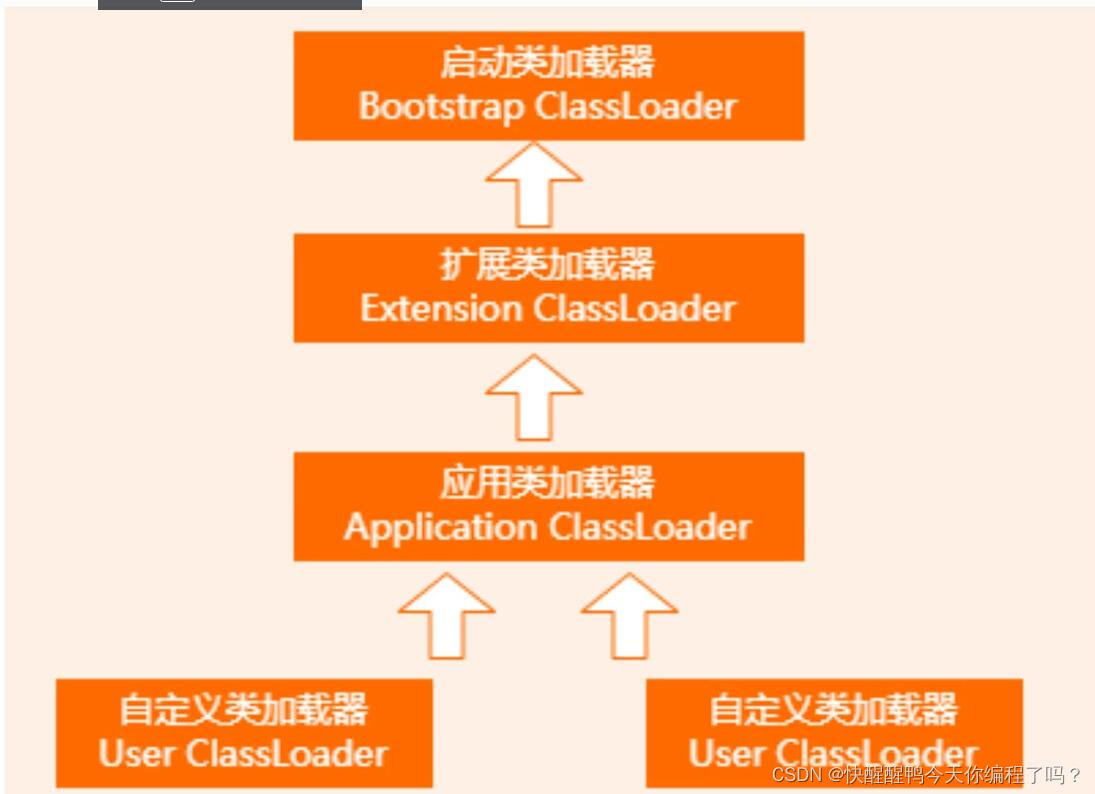
About the parental delegation mechanism and the process of class loading
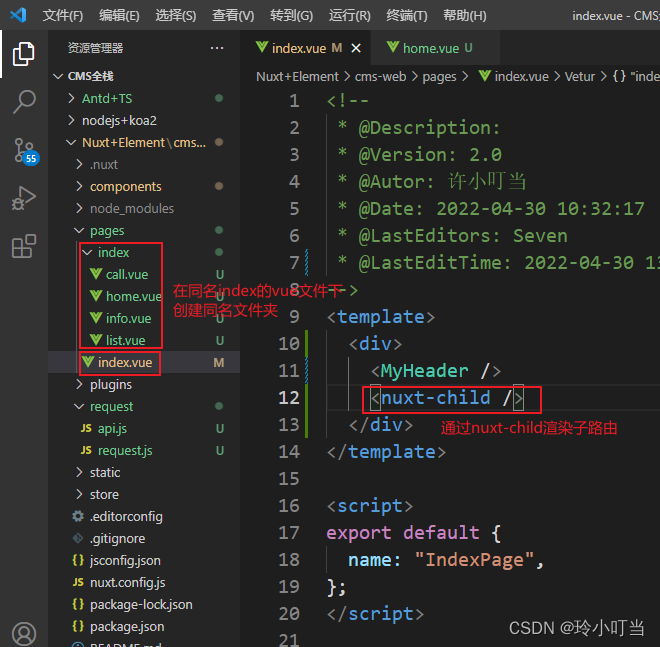
Nuxtjs quick start (nuxt2)
![[hand tearing code] single case mode and producer / consumer mode](/img/b3/243843baaf0d16edeab09142b4ac09.png)
[hand tearing code] single case mode and producer / consumer mode
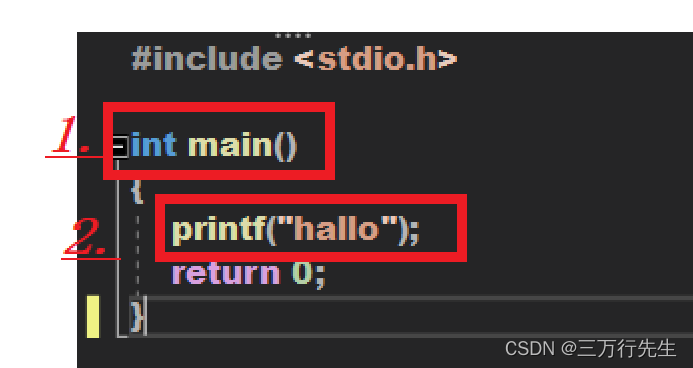
C language Getting Started Guide
一段用蜂鸣器编的音乐(成都)
Mortal immortal cultivation pointer-1
Cookie和Session的区别

The latest tank battle 2022 full development notes-1

Meituan dynamic thread pool practice ideas, open source
随机推荐
7-14 错误票据(PTA程序设计)
[the Nine Yang Manual] 2022 Fudan University Applied Statistics real problem + analysis
扑克牌游戏程序——人机对抗
7-4 散列表查找(PTA程序设计)
Mode 1 two-way serial communication is adopted between machine a and machine B, and the specific requirements are as follows: (1) the K1 key of machine a can control the ledi of machine B to turn on a
The latest tank battle 2022 - Notes on the whole development -2
1. C language matrix addition and subtraction method
The latest tank battle 2022 full development notes-1
Matlab opens M file garbled solution
3. C language uses algebraic cofactor to calculate determinant
The latest tank battle 2022 - full development notes-3
C语言入门指南
js判断对象是否是数组的几种方式
Poker game program - man machine confrontation
Miscellaneous talk on May 14
【九阳神功】2022复旦大学应用统计真题+解析
渗透测试学习与实战阶段分析
[hand tearing code] single case mode and producer / consumer mode
Caching mechanism of leveldb
Relationship between hashcode() and equals()