当前位置:网站首页>打卡第 2 天: urllib简记
打卡第 2 天: urllib简记
2022-08-04 21:33:00 【抄代码抄错的小牛马】

目录
活动地址:CSDN21天学习挑战赛
一、urllib
urllib库是python内置的HTTP请求库,它包含如下4个模块:
- request :请求模块
- parse : 一个工具模块,提供许多URL的处理方法
- error :异常处理模块
- robotparser : 主要用于识别网站的robots.txt文件,一般不用
1.1、urlopen
模拟浏览器向服务器发送请求: urlopen()其参数可以是字符串也可以是一个Request object
import urllib.request
url = 'https://www.baidu.com'
res = urllib.request.urlopen(url=url)
print(type(res)) # HTTPResponse 这里可以看到响应的是一个:HTTPResponse类型的对象,而他主要有如下属性与方法。
属性:
# HTTPResponse 属性
print(res.status) # 状态码
print(res.reason) # 状态信息
print(res.msg) # 访问成功返回 ok
print(res.version) # HTTP版本信息 11 => 1.1
print(res.debuglevel) # 调试等级
方法:
# HTTPResponse 方法
'''
read(): 获取响应体内容,bytes类型,但只能使用一次
getheaders(): 获取响应头信息,返回列表元组
getheader(key): 返回指定键的响应头信息
getcode(): 返回响应的HTTP状态码
geturl(): 返回检索的URL
readinto(): 返回网页头信息
fileno(): 返回文件描述信息
'''
print(res.getheaders())
print(res.getheader('Server'))
print(res.getcode())
print(res.geturl())
print(res.readinto())
print(res.fileno())1.2、get请求参数的编码
例子
- get请求:在url中参数如果有中文,则需要我们转码
- urllib.parse.quote() ==> parse.quote('周杰伦')
- urllib.parse.urlencode() ==> args = parse.urlencode({'wd': '周杰伦', 'ie': 'utf-8'}) 以字典传参
"""
2022年
CSDN:抄代码抄错的小牛马
"""
from random import choice
from urllib import request
from urllib import parse
# get请求:在url中参数如果有中文,则需要我们转码
# urllib.parse.quote() ==> parse.quote('周杰伦')
# urllib.parse.urlencode() ==> args = parse.urlencode({'wd': '周杰伦', 'ie': 'utf-8'}) 以字典传参
user_agents = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
]
headers = {
'User-Agent': choice(user_agents)
}
# args = parse.quote('周杰伦')
# url = f'https://www.baidu.com/s?&wd={args}'
# args = {
# 'wd': '周杰伦',
# 'ie': 'utf-8',
# }
args = parse.urlencode({'wd': '周杰伦', 'ie': 'utf-8'})
url = f'https://www.baidu.com/s?&wd={args}'
req = request.Request(url=url, headers=headers)
res = request.urlopen(req).read().decode('utf-8')
print(res)
1.3、post请求
"""
2022年
CSDN:抄代码抄错的小牛马
"""
import urllib.request
import urllib.parse
from random import choice
user_agents = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
]
headers = {
'User-Agent': choice(user_agents)
}
url = 'https://www.baidu.com'
args = {
'user': '123456789',
'password': '1111111'
}
data = urllib.parse.urlencode(args).encode() # post请求时,data要编码 ,要求为 bytes 数据类型
req = urllib.request.Request(url=url, data=data, headers=headers)
res = urllib.request.urlopen(req).read().decode('utf-8')
print(res)
1.6、多个user——agent随机使用
直接导入包 from fake_useragent import UserAgent
random 中的 choice
"""
2022年
CSDN:抄代码抄错的小牛马
"""
from urllib import request
from random import choice
# 或者是直接导入包
from fake_useragent import UserAgent
#
# # 随机chrome浏览器
# print(UserAgent().ie)
# # 随机firefox浏览器
# print(UserAgent().firefox)
# # 随机请求头
# print(UserAgent().random)
# url = 'https://baidu.com/'
url = 'http://httpbin.org/get'
user_agents = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv,2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Mobile Safari/537.36',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
]
headers = {
'User-Agent': choice(user_agents)
}
# req = request.Request(url=url, headers=headers)
# res = request.urlopen(req).read().decode('utf-8')
print(headers)
1.5、proxyHandler代理使用
"""
2022年
CSDN:抄代码抄错的小牛马
"""
import urllib.request
from urllib.request import ProxyHandler
from urllib.request import build_opener
from fake_useragent import UserAgent
url = 'https://www.baidu.com/'
headers = {'User-Agent': UserAgent().chrome}
request = urllib.request.Request(url=url, headers=headers)
proxy = {
# 'type': 'ip:port' ==> 类型:IP:端口
'http': '202.55.5.209:8090'
# 'type': 'name:[email protected]:port' ==> 独享IP 会有一个账号
}
handler = ProxyHandler(proxy)
opener = build_opener(handler)
response = opener.open(request)
content = response.read().decode()
print(content)
拜~~~
边栏推荐
- dotnet 使用 lz4net 压缩 Stream 或文件
- Exploration and Practice of Database Governance
- webmine网页挖矿木马分析与处置
- PyTorch Geometric (PyG) 安装教程
- Android 面试——如何写一个又好又快的日志库?
- SPSS-System Clustering Hand Calculation Practice
- How to solve the problem that the alarm information cannot be transmitted after EasyGBS is connected to the latest version of Hikvision camera?
- 可视化工作流引擎开发OA系统,让企业少花冤枉钱
- dotnet 通过 WMI 获取系统安装软件
- 【PCBA program design】Grip dynamometer program
猜你喜欢
如何根据“前序遍历,中序遍历”,“中序遍历,后序遍历”构建按二叉树

buu web
Re24:读论文 IOT-Match Explainable Legal Case Matching via Inverse Optimal Transport-based Rationale Ext
ROS播包可视化
JdbcTemplate概述和测试
JWT actively checks whether the Token has expired
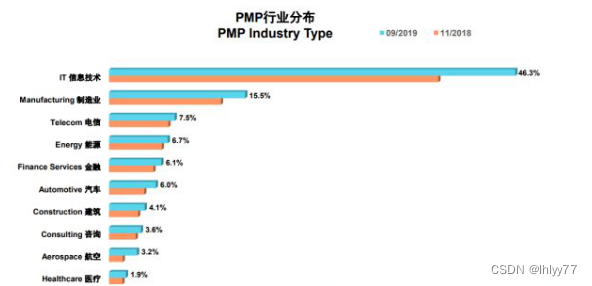
In which industries is the PMP certificate useful?
开发deepstram的自定义插件,使用gst-dseaxmple插件进行扩充,实现deepstream图像输出前的预处理,实现图像自定义绘制图(精四)
PMP证书在哪些行业有用?
Codeforces Round #811 (Div. 3)
随机推荐
PowerCLi batch configuration of NTP
热力学相关的两个定律
ROS packages visualization
Yolov7:Trainable bag-of-freebies sets new state-of-the-art for real-time objectdetectors
ES6高级-Promise的用法
moke、动态图片资源打包显示
visual studio 2015 warning MSB3246
AI/ML无线通信
PCBA方案设计——厨房语音秤芯片方案
dotnet enables JIT multi-core compilation to improve startup performance
Dotnet using WMI software acquisition system installation
dotnet 启动 JIT 多核心编译提升启动性能
visual studio 2015 warning MSB3246
ES6高级-async的用法
如何一键重装win7系统?重装win7系统详细教程
Configure laravel queue method using fort app manager
经验分享|盘点企业进行知识管理时的困惑类型
数字重塑客观世界,全空间GIS发展正当其时
Android 面试——如何写一个又好又快的日志库?
零基础都能拿捏的七夕浪漫代码,快去表白或去制造惊喜吧