当前位置:网站首页> 如果不知道這4種緩存模式,敢說懂緩存嗎?
如果不知道這4種緩存模式,敢說懂緩存嗎?
2022-07-04 10:18:00 【程序新視界】
概述
在系統架構中,緩存可謂提供系統性能的最簡單方法之一,稍微有點開發經驗的同學必然會與緩存打過交道,最起碼也實踐過。
如果使用得當,緩存可以减少響應時間、减少數據庫負載以及節省成本。但如果緩存使用不當,則可能出現一些莫名其妙的問題。
在不同的場景下,所使用的緩存策略也是有變化的。如果在你的印象和經驗中,緩存還只是簡單的查詢、更新操作,那麼這篇文章真的值得你學習一下。
在這裏,為大家系統地講解4種緩存模式以及它們的使用場景、流程以及優缺點。
緩存策略的選擇
本質上來講,緩存策略取决於數據和數據訪問模式。換句話說,數據是如何寫和讀的。
例如:
- 系統是寫多讀少的嗎?(例如,基於時間的日志)
- 數據是否是只寫入一次並被讀取多次?(例如,用戶配置文件)
- 返回的數據總是唯一的嗎?(例如,搜索查詢)
選擇正確的緩存策略才是提高性能的關鍵。
常用的緩存策略有以下五種:
- Cache-Aside Pattern:旁路緩存模式
- Read Through Cache Pattern:讀穿透模式
- Write Through Cache Pattern:寫穿透模式
- Write Behind Pattern:又叫Write Back,异步緩存寫入模式
上述緩存策略的劃分是基於對數據的讀寫流程來區分的,有的緩存策略下是應用程序僅和緩存交互,有的緩存策略下應用程序同時與緩存和數據庫進行交互。因為這個是策略劃分比較重要的一個維度,所以在後續流程學習時大家需要特別留意一下。
Cache Aside
Cache Aside是最常見的緩存模式,應用程序可直接與緩存和數據庫對話。Cache Aside可用來讀操作和寫操作。
讀操作的流程圖:
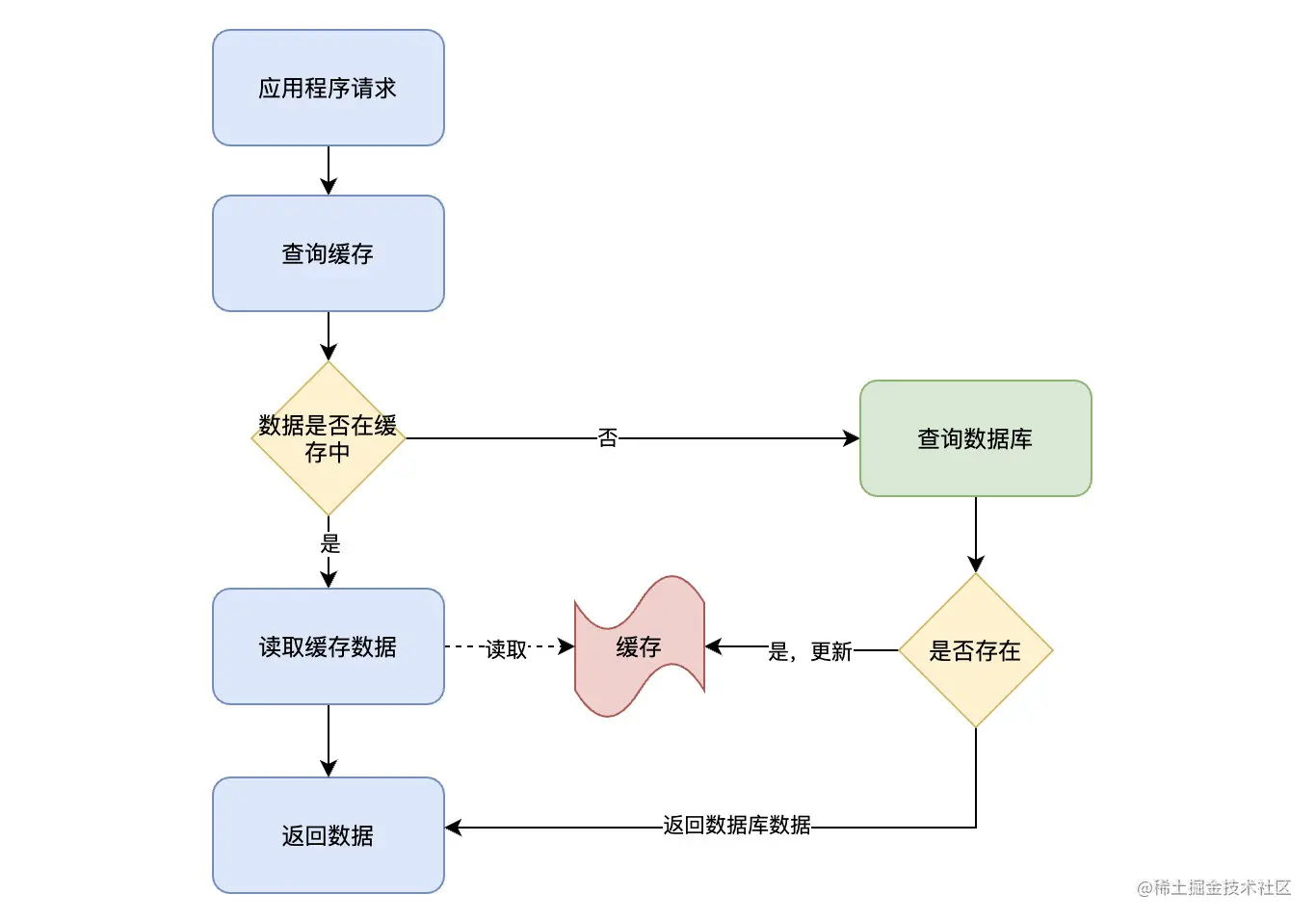
讀操作的流程:
應用程序接收到數據查詢(讀)請求;
應用程序所需查詢的數據是否在緩存上:
- 如果存在(Cache hit),從緩存上查詢出數據,直接返回;
- 如果不存在(Cache miss),則從數據庫中檢索數據,並存入緩存中,返回結果數據;
這裏我們需要留意一個操作的邊界,也就是數據庫和緩存的操作均由應用程序直接進行操作。
寫操作的流程圖:
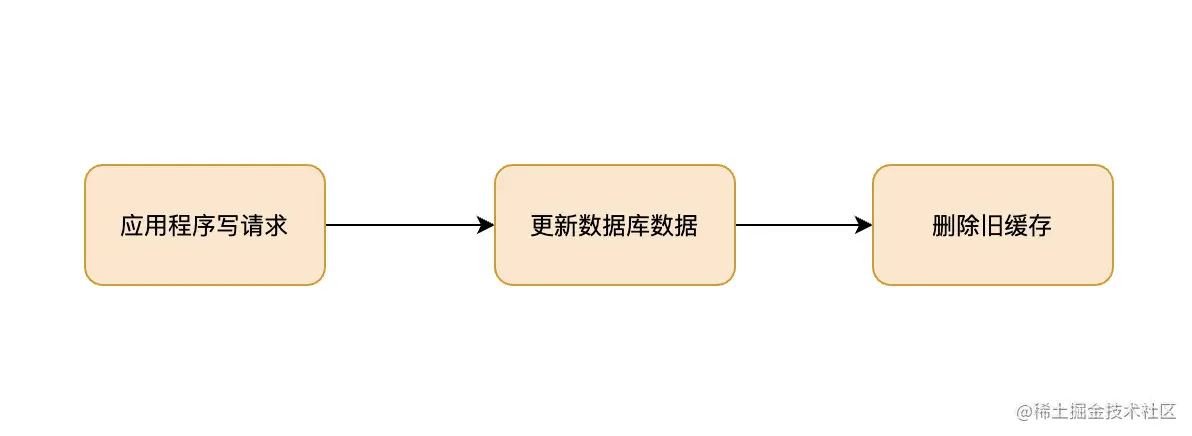
這裏的寫操作,包括創建、更新和删除。在寫操作的時候,Cache Aside模式是先更新數據庫(增、删、改),然後直接删除緩存。
Cache Aside模式可以說適用於大多數的場景,通常為了應對不同類型的數據,還可以有兩種策略來加載緩存:
- 使用時加載緩存:當需要使用緩存數據時,從數據庫中查詢出來,第一次查詢之後,後續請求從緩存中獲得數據;
- 預加載緩存:在項目啟動時或啟動後通過程序預加載緩存信息,比如”國家信息、貨幣信息、用戶信息,新聞信息“等不是經常變更的數據。
Cache Aside適用於讀多寫少的場景,比如用戶信息、新聞報道等,一旦寫入緩存,幾乎不會進行修改。該模式的缺點是可能會出現緩存和數據庫雙寫不一致的情况。
Cache Aside也是一個標准的模式,像Facebook便是采用的這種模式。
Read Through
Read-Through和Cache-Aside很相似,不同點在於程序不需要關注從哪裏讀取數據(緩存還是數據庫),它只需要從緩存中讀數據。而緩存中的數據從哪裏來是由緩存决定的。
Cache Aside是由調用方負責把數據加載入緩存,而Read Through則用緩存服務自己來加載,從而對應用方是透明的。Read-Through的優勢是讓程序代碼變得更簡潔。
這裏就涉及到我們上面所說的應用程序操作邊界問題了,直接來看流程圖:
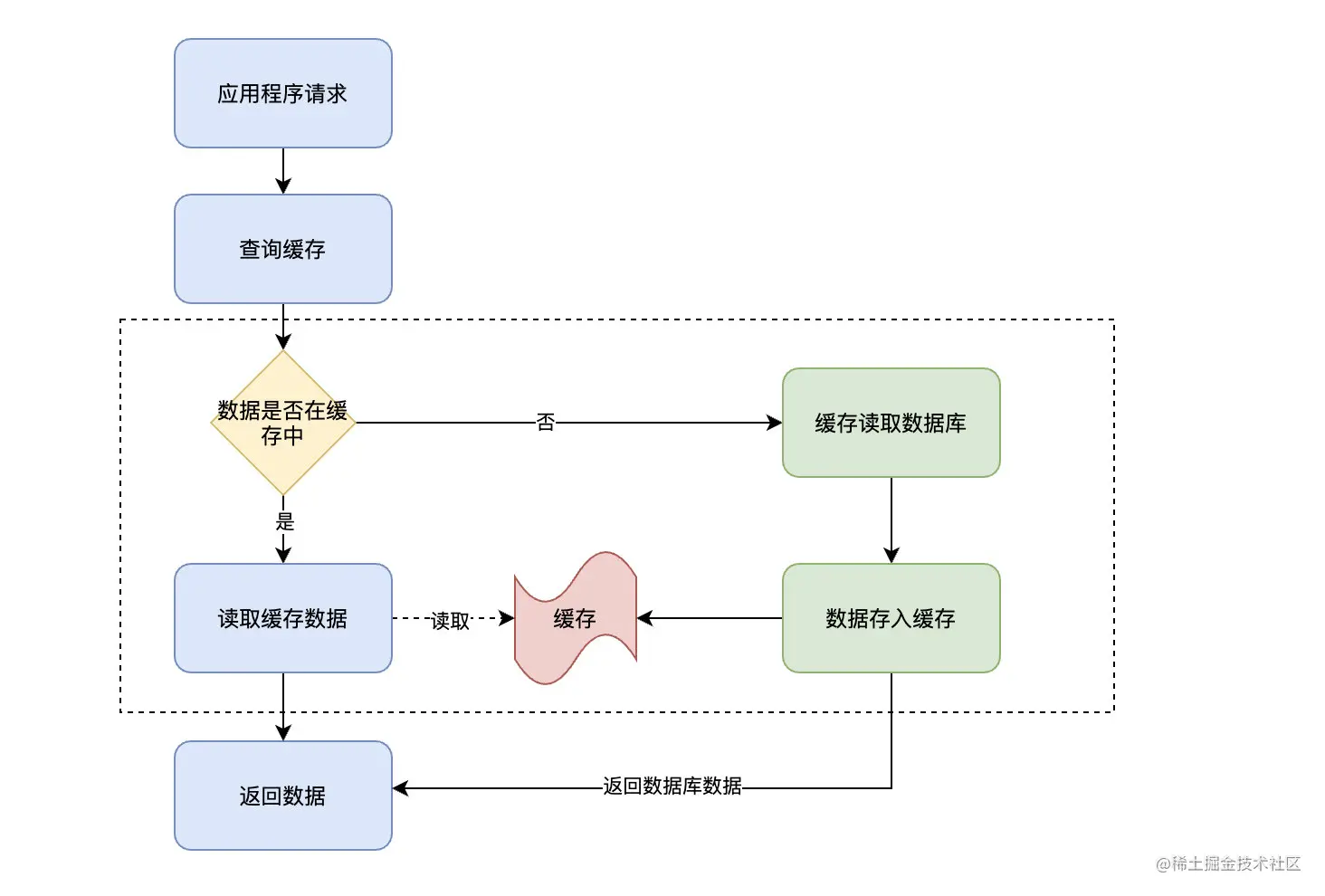
在上述流程圖中,重點關注一下虛線框內的操作,這部分操作不再由應用程序來處理,而是由緩存自己來處理。也就是說,當應用從緩存中查詢某條數據時,如果數據不存在則由緩存來完成數據的加載,最後再由緩存返回數據結果給應用程序。
Write Through
在Cache Aside中,應用程序需要維護兩個數據存儲:一個緩存,一個數據庫。這對於應用程序來說,有一些繁瑣。
Write-Through模式下,所有的寫操作都經過緩存,每次向緩存中寫數據時,緩存會把數據持久化到對應的數據庫中去,且這兩個操作在一個事務中完成。因此,只有兩次都寫成功了才是最終寫成功了。壞處是有寫延遲,好處是保證了數據的一致性。
可以理解為,應用程序認為後端就是一個單一的存儲,而存儲自身維護自己的Cache。
因為程序只和緩存交互,編碼會變得更加簡單和整潔,當需要在多處複用相同邏輯時這點就變得格外明顯。
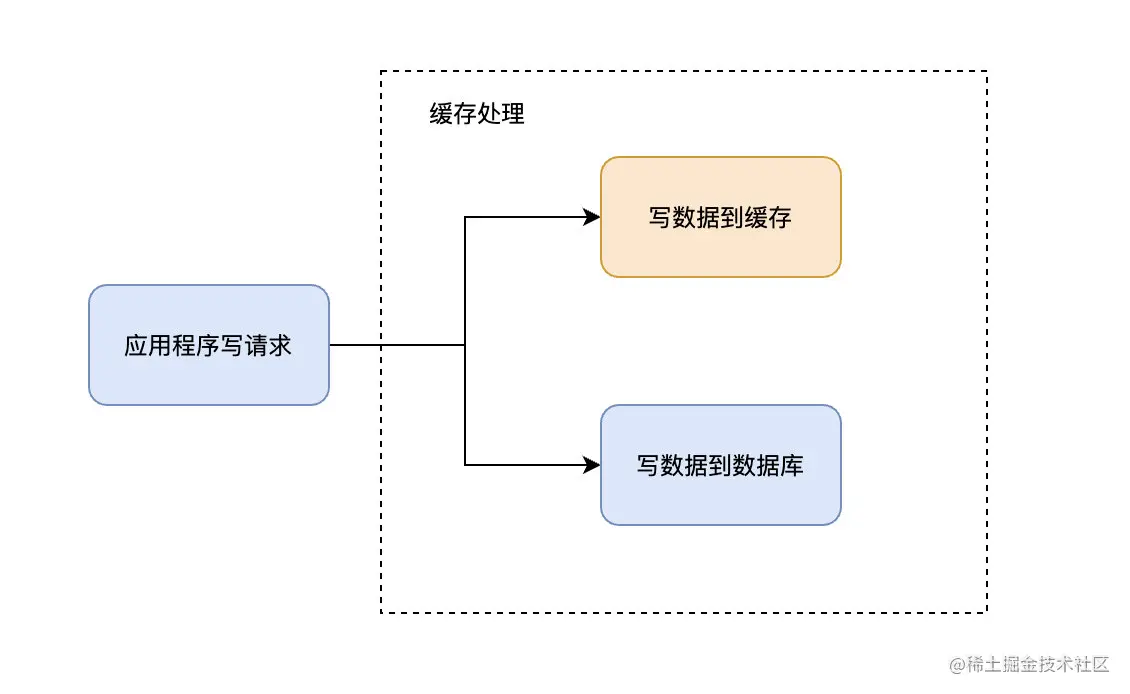
當使用Write-Through時,一般都配合使用Read-Through來使用。Write-Through的潜在使用場景是銀行系統。
Write-Through適用情况有:
- 需要頻繁讀取相同數據
- 不能忍受數據丟失(相對Write-Behind而言)和數據不一致
在使用Write-Through時要特別注意的是緩存的有效性管理,否則會導致大量的緩存占用內存資源。甚至有效的緩存數據被無效的緩存數據給清除掉。
Write-Behind
Write-Behind和Write-Through在”程序只和緩存交互且只能通過緩存寫數據“這方面很相似。不同點在於Write-Through會把數據立即寫入數據庫中,而Write-Behind會在一段時間之後(或是被其他方式觸發)把數據一起寫入數據庫,這個异步寫操作是Write-Behind的最大特點。
數據庫寫操作可以用不同的方式完成,其中一個方式就是收集所有的寫操作並在某一時間點(比如數據庫負載低的時候)批量寫入。另一種方式就是合並幾個寫操作成為一個小批次操作,接著緩存收集寫操作一起批量寫入。
异步寫操作極大的降低了請求延遲並减輕了數據庫的負擔。同時也放大了數據不一致的。比如有人此時直接從數據庫中查詢數據,但是更新的數據還未被寫入數據庫,此時查詢到的數據就不是最新的數據。
小結
不同的緩存模式有不同的考量點和特征,根據應用程序需求場景的不同,需要靈活的選擇適配的緩存模式。在實踐的過程中往往也是多種模式相結合來使用。
博主簡介:《SpringBoot技術內幕》技術圖書作者,酷愛鑽研技術,寫技術幹貨文章。
公眾號:「程序新視界」,博主的公眾號,歡迎關注~
技術交流:請聯系博主微信號:zhuan2quan
边栏推荐
- Mmclassification annotation file generation
- Velodyne configuration command
- Use the data to tell you where is the most difficult province for the college entrance examination!
- [200 opencv routines] 218 Multi line italic text watermark
- system design
- Exercise 7-4 find out the elements that are not common to two arrays (20 points)
- AUTOSAR from getting started to mastering 100 lectures (106) - SOA in domain controllers
- System.currentTimeMillis() 和 System.nanoTime() 哪个更快?别用错了!
- Es entry series - 6 document relevance and sorting
- Hands on deep learning (36) -- language model and data set
猜你喜欢
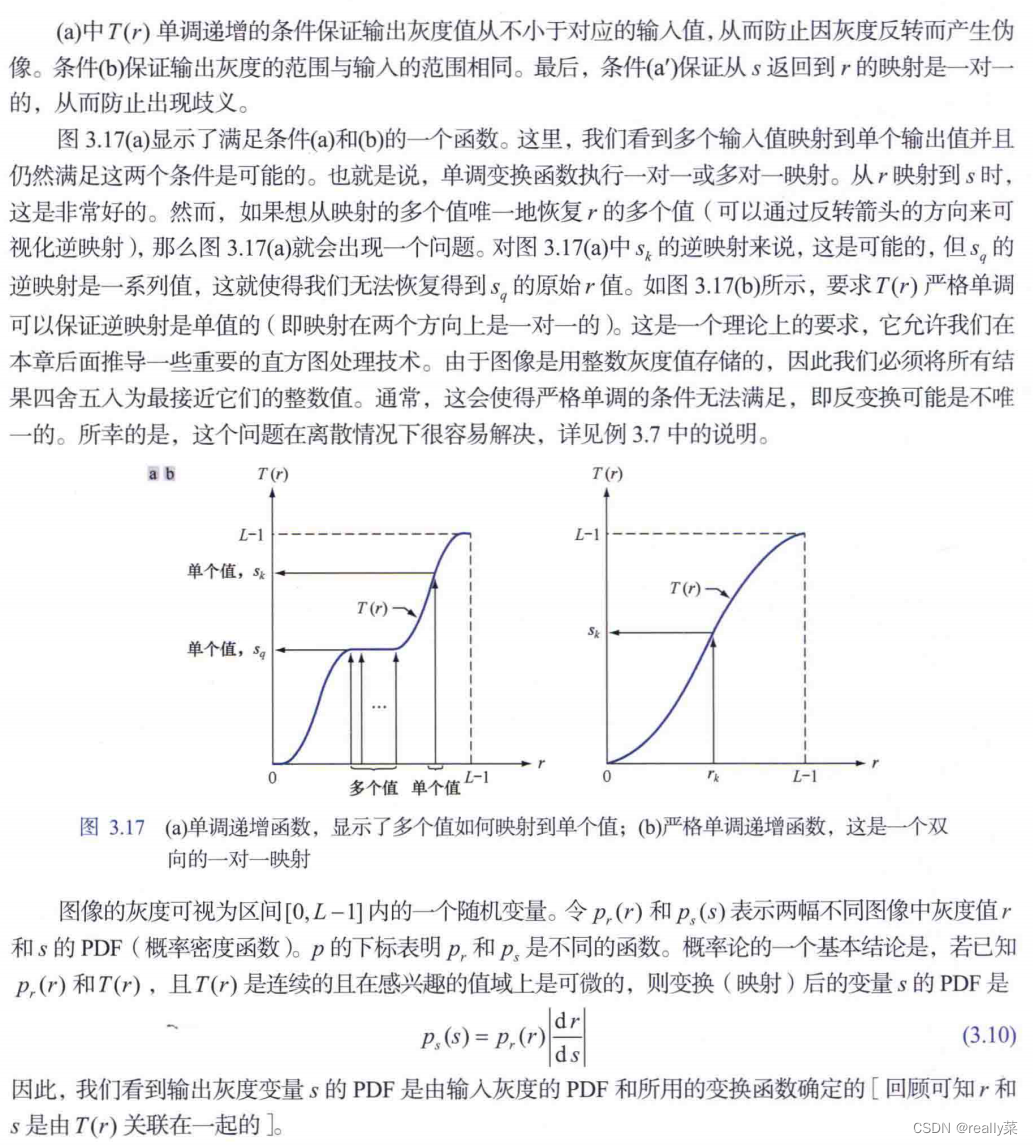
Histogram equalization
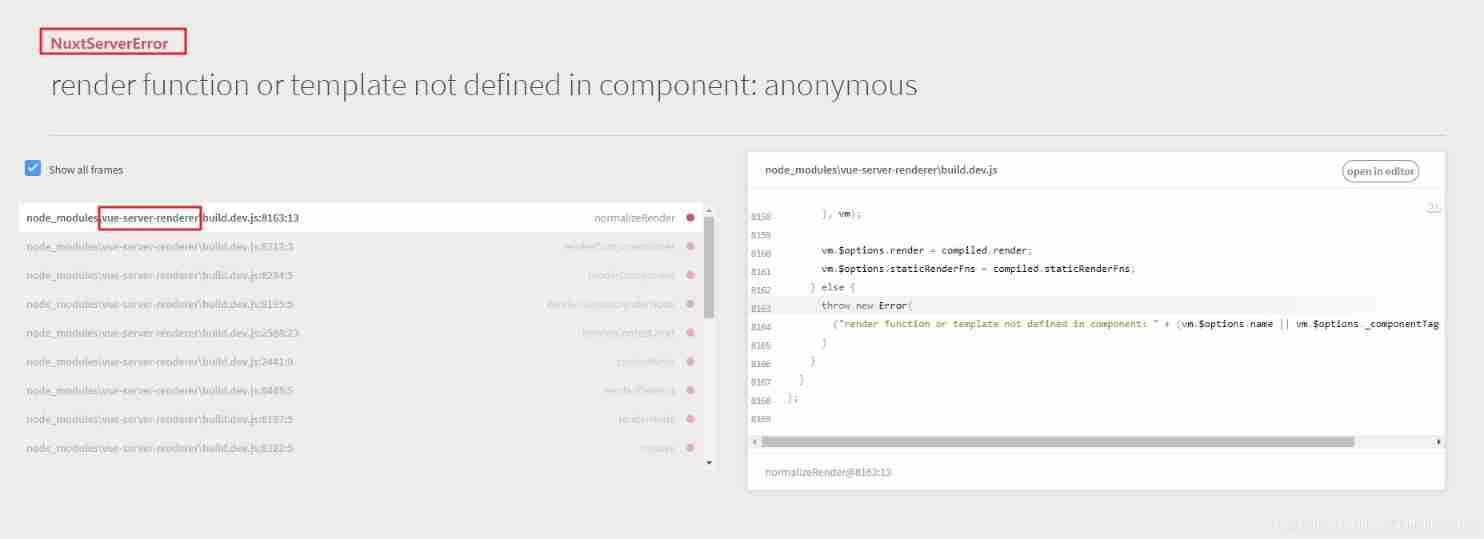
Nuxt reports an error: render function or template not defined in component: anonymous
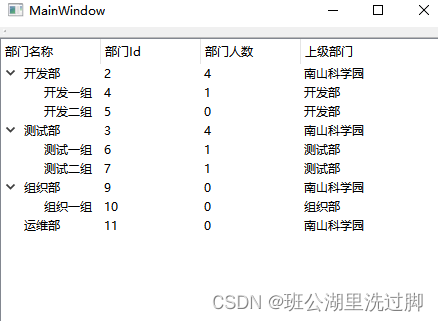
Qtreeview+ custom model implementation example
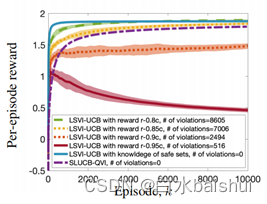
Safety reinforcement learning based on linear function approximation safe RL with linear function approximation translation 2

Development guidance document of CMDB

Basic principle of servlet and application of common API methods
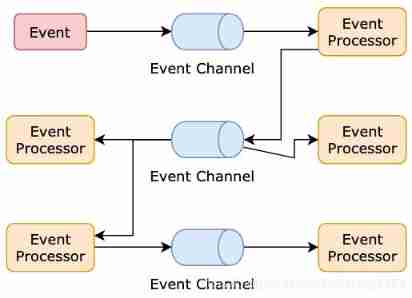
Architecture introduction
基于线性函数近似的安全强化学习 Safe RL with Linear Function Approximation 翻译 2
PHP code audit 3 - system reload vulnerability
Pcl:: fromrosmsg alarm failed to find match for field 'intensity'
随机推荐
leetcode842. Split the array into Fibonacci sequences
转载:等比数列的求和公式,及其推导过程
使用 C# 提取 PDF 文件中的所有文字(支持 .NET Core)
Exercise 7-8 converting strings to decimal integers (15 points)
百度研发三面惨遭滑铁卢:面试官一套组合拳让我当场懵逼
技术管理进阶——如何设计并跟进不同层级同学的绩效
Check 15 developer tools of Alibaba
Use C to extract all text in PDF files (support.Net core)
C language pointer classic interview question - the first bullet
uniapp 小于1000 按原数字显示 超过1000 数字换算成10w+ 1.3k+ 显示
AUTOSAR从入门到精通100讲(106)-域控制器中的SOA
Velodyne configuration command
Realsense of d435i, d435, d415, t265_ Matching and installation of viewer environment
Exercise 9-5 address book sorting (20 points)
2021-08-11 function pointer
Hands on deep learning (37) -- cyclic neural network
Golang defer
Hands on deep learning (42) -- bi-directional recurrent neural network (BI RNN)
【Day1】 deep-learning-basics
[FAQ] summary of common causes and solutions of Huawei account service error 907135701