当前位置:网站首页>Safety reinforcement learning based on linear function approximation safe RL with linear function approximation translation 2
Safety reinforcement learning based on linear function approximation safe RL with linear function approximation translation 2
2022-07-04 10:05:00 【Baishui】
The paper :Safe Reinforcement Learning with Linear Function Approximation
Download address :http://proceedings.mlr.press/v139/amani21a/amani21a.pdf
meeting / year :PMLR / 2021
Word Version download address ( Hard work ):https://download.csdn.net/download/baishuiniyaonulia/85863332
The translation of this article belongs to semi manual , Please forgive me for any mistakes .
List of articles
Abstract 、1、2、3
Safety reinforcement learning based on linear function approximation Safe RL with Linear Function Approximation translate 1 —— https://blog.csdn.net/baishuiniyaonulia/article/details/125504660
4. Extend to randomized policy choices Extension to randomized policy selection
The first 2 Section SLUCB-QVI Only deterministic strategies can be output . In this section , We show that our results can be extended to the setting of random policy selection , This may be desirable in practice . Random strategy π : S × [ H ] → Δ A \pi :\mathcal{S}\times [H]\to { {\Delta }_{\mathcal{A}}} π:S×[H]→ΔA Map States and time steps to distributions on actions , bring a ∼ π ( s , h ) a\sim \pi (s,h) a∼π(s,h) It's a strategy π It is suggested that the agent is in a state s ∈ S s\in \mathcal{S} s∈S Time is in the time step h ∈ [ H ] h\in [H] h∈[H] The action performed . In every plot k And time steps h ∈ [ H ] h\in [H] h∈[H] in , When in state s h k s_{h}^{k} shk when , The agent must start from a Extract its action a h k a_{h}^{k} ahk The security policy π k ( s h k , h ) { {\pi }_{k}}\left( s_{h}^{k},h \right) πk(shk,h) bring E a h k ∼ π k ( s h k , h ) c h ( s h k , a h k ) ≤ τ { {\mathbb{E}}_{a_{h}^{k}\sim{ {\pi }_{k}}\left( s_{h}^{k},h \right)}}{ {c}_{h}}\left( s_{h}^{k},a_{h}^{k} \right)\le \tau Eahk∼πk(shk,h)ch(shk,ahk)≤τ The probability is high . Accordingly, we define a set of unknown security policies Π ~ safe : = { π : π ( s , h ) ∈ Γ h safe ( s ) , ∀ ( s , h ) ∈ S × [ H ] } { {\tilde{\Pi }}^{\text{safe }}}:=\left\{ \pi :\pi (s,h)\in \Gamma _{h}^{\text{safe }}(s),\forall (s,h)\in \mathcal{S}\times [H] \right\} Π~safe :={ π:π(s,h)∈Γhsafe (s),∀(s,h)∈S×[H]}
among Γ h safe ( s ) : = { θ ∈ Δ A : E a ∼ θ c h ( s , a ) ≤ τ } \Gamma _{h}^{\text{safe}}(s):=\left\{ \theta \in { {\Delta }_{\mathcal{A}}}:{ {\mathbb{E }}_{a\sim\theta }}{ {c}_{h}}(s,a)\le \tau \right\} Γhsafe(s):={ θ∈ΔA:Ea∼θch(s,a)≤τ}. therefore , In the k Time step of round h ∈ [ H ] h\in [H] h∈[H] Observation state s h k s_{h}^{k} shk after , The strategy selection of the agent must belong to Γ h safe ( s h k ) \Gamma _{h}^{\text {safe}}(s_{h}^{k}) Γhsafe(shk) The probability is high . In this formula , Strategy π Of ( action ) The expected value in the definition of value function exceeds the environment and strategy π The randomness of . We use it V ~ h π \tilde{V}_{h}^{\pi } V~hπ and Q ~ h π \tilde{Q}_{h}^{\pi } Q~hπ To represent them , Distinguish from V ~ h π \tilde{V}_{h }^{\pi } V~hπ and Q ~ h π \tilde{Q}_{h}^{\pi } Q~hπ stay (2) and (3) In the definition of , For deterministic strategies π. Make π ∗ { {\pi }_{*}} π∗ Is the optimal security policy , bring V ~ h π ∗ ( s ) : = V ~ h ∗ ( s ) = sup π ∈ Π ~ safe V ~ h π ( s ) \tilde{V}_{h}^{ { {\pi }_{*}}}(s):=\tilde {V}_{h}^{*}(s)=\underset{\pi \in { { {\tilde{\Pi }}}^{\text{safe }}}}{\mathop{\sup } }\,\tilde{V}_{h}^{\pi }(s) V~hπ∗(s):=V~h∗(s)=π∈Π~safe supV~hπ(s) For all ( s , h ) ∈ S × [ H ] (s,h)\in \mathcal{S}\times [H] (s,h)∈S×[H]. therefore , For all ( a , s , h ) ∈ A × S × [ H ] (a,s,h)\in \mathcal{A}\times \mathcal{S}\times [H] (a,s,h)∈A×S×[H], Behrman equation of security policy π ∈ Π ~ safe \pi \in { {\tilde{ \Pi }}^{\text{safe }}} π∈Π~safe And the optimal security policy is
Q ~ h π ( s , a ) = r h ( s , a ) + [ P h V ~ h + 1 π ] ( s , a ) , V ~ h π ( s ) = E a ∼ π ( s , h ) [ Q ~ h π ( s , a ) ] , \begin{aligned} & \tilde{Q}_{h}^{\pi }(s,a)={ {r}_{h}}(s,a)+\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{\pi } \right](s,a), \\ & \quad \tilde{V}_{h}^{\pi }(s)={ {\mathbb{E}}_{a\sim\pi (s,h)}}\left[ \tilde{Q}_{h}^{\pi }(s,a) \right], \\ \end{aligned} Q~hπ(s,a)=rh(s,a)+[PhV~h+1π](s,a),V~hπ(s)=Ea∼π(s,h)[Q~hπ(s,a)], Q ~ h ∗ ( s , a ) = r h ( s , a ) + [ P h V ~ h + 1 ∗ ] ( s , a ) , V ~ h ∗ ( s ) = max θ ∈ Γ h safe ( s ) E a ∈ θ [ Q ~ h ∗ ( s , a ) ] , \begin{aligned} & \tilde{Q}_{h}^{*}(s,a)={ {r}_{h}}(s,a)+\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{*} \right](s,a), \\ & \tilde{V}_{h}^{*}(s)={ {\max }_{\theta \in \Gamma _{h}^{\text{safe }(s)}}}{ {\mathbb{E}}_{a\in \theta }}\left[ \tilde{Q}_{h}^{*}(s,a) \right], \\ \end{aligned} Q~h∗(s,a)=rh(s,a)+[PhV~h+1∗](s,a),V~h∗(s)=maxθ∈Γhsafe (s)Ea∈θ[Q~h∗(s,a)],
among V ~ H + 1 π ( s ) = V ~ H + 1 ∗ ( s ) = 0 \tilde{V}_{H+1}^{\pi }(s)=\tilde{V}_{H+1}^{*}(s)=0 V~H+1π(s)=V~H+1∗(s)=0, Defines cumulative regret Such as R K : = ∑ k = 1 K V ~ 1 ∗ ( s 1 k ) − V ~ 1 π k ( s 1 k ) { {R}_{K}}:=\sum\limits_{k=1}^{K}{\tilde{V}_{1}^{*}}(s_{1}^{k})-\tilde{V}_{1}^{ { {\pi }_{k}}}(s_{1}^{k}) RK:=k=1∑KV~1∗(s1k)−V~1πk(s1k). (11) The definition of security constraints in enables us to get rid of the set D ( s ) : = { ϕ ( s , a ) : a ∈ A } \mathcal{D}(s):=\{\phi (s,a):a\in \mathcal{A}\} D(s):={ ϕ(s,a):a∈A} Star convexity hypothesis ( hypothesis 5), This is necessary for the deterministic strategy selection method . We suggest that SLUCB-QVI Make changes , To adapt to this new formula , It's called random SLUCB-QVI (RSLUCB-QVI). This new algorithm also realizes the comparison with SLUCB-QVI Sublinear regret of the same order , namely O ~ ( κ d 3 H 3 T ) \widetilde{\mathcal{O}}\left( \kappa \sqrt{ { {d}^{3}} { {H}^{3}}T} \right) O(κd3H3T).
Although with SLUCB-QVI( See (1)) Compared with the safety constraints considered in ,RSLUCB-QVI Respect the more moderate definition of security constraints ( See (11)), But it is still better than other existing algorithms through random strategy selection CMDP Has significant advantages (Efroni wait forsomeone ,2020;Turchetta wait forsomeone ,2020;Garcelon wait forsomeone ,2020;Zheng and Ratliff,2020;Ding wait forsomeone ,2020a;Qiu wait forsomeone ,2020;Ding wait forsomeone ,2020b;Xu wait forsomeone ,2020 year ;Kalagarla wait forsomeone ,2020 year ). First , The security constraints considered in these algorithms are defined by the cumulative expected cost in the time range below a certain threshold , and RSLUCB-QVI Make sure that at every time step of the action ( Not in a time frame ) Expected costs incurred Less than threshold . secondly , Even this looser definition of safety constraints , The best method that these algorithms can guarantee in terms of constraint satisfaction is the sublinear limit of the number of constraint violations , and RSLUCB-QVI Make sure there is no constraint violation .
4.1. Random SLUCB-QVI Randomized SLUCB-QVI
We now describe the algorithm 2 As summarized in RSLUCB-QVI. Make ϕ θ ( s ) : = E a ∼ θ ϕ ( s , a ) { {\phi }^{\theta }}(s):={ {\mathbb{E}}_{a\sim\theta }}\phi (s ,a) ϕθ(s):=Ea∼θϕ(s,a). In every plot k ∈ [ K ] k\in [K] k∈[K] in , In the first cycle , Agents calculate all $s The real unknown set of Γ h safe ( s ) \Gamma _{h}^{\text{safe}}(s) Γhsafe(s) Estimation set of s ∈ S s\in \mathcal{S} s∈S as follows :
Γ h k ( s ) : = { θ ∈ Δ A : E a ∼ θ [ * Φ 0 ( s , ϕ ( s , a ) ) , ϕ ~ ( s , a 0 ( s ) ) * ∥ ϕ ( s , a 0 ( s ) ) ∥ 2 τ h ( s ) ] + max ν ∈ C h k ( s ) * Φ 0 ⊥ ( s , E a ∼ θ [ ϕ ( s , a ) ] ) , ν * ≤ τ } \Gamma _{h}^{k}(s):=\left\{ \theta \in { {\Delta }_{\mathcal{A}}}:{ {\mathbb{E}}_{a\sim\theta }}\left[ \frac{\left\langle { {\Phi }_{0}}(s,\phi (s,a)),\widetilde{\phi }\left( s,{ {a}_{0}}(s) \right) \right\rangle }{ { {\left\| \phi \left( s,{ {a}_{0}}(s) \right) \right\|}_{2}}}{ {\tau }_{h}}(s) \right] \right.\left. +\underset{\nu \in \mathcal{C}_{h}^{k}(s)}{\mathop{\max }}\,\left\langle \Phi _{0}^{\bot }\left( s,{ {\mathbb{E}}_{a\sim\theta }}[\phi (s,a)] \right),\nu \right\rangle \le \tau \right\} Γhk(s):=⎩⎨⎧θ∈ΔA:Ea∼θ⎣⎡∥ϕ(s,a0(s))∥2*Φ0(s,ϕ(s,a)),ϕ(s,a0(s))*τh(s)⎦⎤+ν∈Chk(s)max*Φ0⊥(s,Ea∼θ[ϕ(s,a)]),ν*≤τ}
= { θ ∈ Δ A : * Φ 0 ( s , ϕ θ ( s ) ) , ϕ ~ ( s , a 0 ( s ) ) * ∥ ϕ ( s , a 0 ( s ) ) ∥ 2 τ h ( s ) + * γ h , s k , Φ 0 ⊥ ( s , ϕ θ ( s ) ) * + β ∥ Φ 0 ⊥ ( s , ϕ θ ( s ) ) ∥ ( A h , s k ) − 1 ≤ τ } =\left\{ \theta \in { {\Delta }_{\mathcal{A}}}:\frac{\left\langle { {\Phi }_{0}}\left( s,{ {\phi }^{\theta }}(s) \right),\tilde{\phi }\left( s,{ {a}_{0}}(s) \right) \right\rangle }{ { {\left\| \phi \left( s,{ {a}_{0}}(s) \right) \right\|}_{2}}}{ {\tau }_{h}}(s)+\left\langle \gamma _{h,s}^{k},\Phi _{0}^{\bot }\left( s,{ {\phi }^{\theta }}(s) \right) \right\rangle +\beta { {\left\| \Phi _{0}^{\bot }\left( s,{ {\phi }^{\theta }}(s) \right) \right\|}_{ { {\left( \mathbf{A}_{h,s}^{k} \right)}^{-1}}}}\le \tau \right\} =⎩⎨⎧θ∈ΔA:∥ϕ(s,a0(s))∥2*Φ0(s,ϕθ(s)),ϕ~(s,a0(s))*τh(s)+*γh,sk,Φ0⊥(s,ϕθ(s))*+β∥∥Φ0⊥(s,ϕθ(s))∥∥(Ah,sk)−1≤τ⎭⎬⎫
Please note that , because MDP The linear structure of , We can go through the linear form again * w ~ h ∗ , ϕ ( s , a ) * \left\langle \mathbf{\tilde{w}}_{h}^{*},\phi (s,a) \right\rangle *w~h∗,ϕ(s,a)* A parameterized Q ~ h ∗ ( s , a ) \tilde{Q}_{h}^{*}(s,a) Q~h∗(s,a) , among w ~ h ∗ : = θ h ∗ + ∫ S V ~ h + 1 ∗ ( s ′ ) d μ ( s ′ ) \mathbf{\tilde{w}}_{h}^{*}:=\theta _{ h}^{*}+\int_{\mathcal{S}}{\tilde{V}_{h+1}^{*}}({s}')d\mu ({s}') w~h∗:=θh∗+∫SV~h+1∗(s′)dμ(s′). In the next step , For all ( s , a ) ∈ S × A (s,a)\in \mathcal{S}\times \mathcal{A} (s,a)∈S×A, Agent computing Q ~ h k ( s , a ) = * w ~ h k , ϕ ( s , a ) * + κ h ( s ) β ∥ ϕ ( s , a ) ∥ ( A h k ) − 1 \tilde{Q}_{h}^{k}(s,a)=\left\langle \mathbf{\tilde{w}}_{h}^{k},\phi (s,a) \right\rangle +{ {\kappa }_{h}}(s)\beta { {\left\| \phi (s,a) \right\|}_{ { {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}}} Q~hk(s,a)=*w~hk,ϕ(s,a)*+κh(s)β∥ϕ(s,a)∥(Ahk)−1
among w ~ h ∗ : = ( A h k ) − 1 w i d e t i l d e b h k \mathbf{\tilde{w}}_{h}^{*}:={ {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}\ widetilde{\mathbf{b}}_{h}^{k} w~h∗:=(Ahk)−1 widetildebhk By Gram matrix $ Calculated w ~ h ∗ \mathbf{\tilde{w}}_{h}^{*} w~h∗ Regularized least squares estimator of \mathbf{A}_{h}^{k}$ and b ~ h k : = ∑ j = 1 k − 1 ϕ h j [ r h j + min { max θ ∈ Γ h + 1 k ( s h + 1 j ) E a ∼ θ [ Q ~ h + 1 k ( s h + 1 j , a ) ] , H } ] \widetilde{\mathbf{b}}_{h}^{k}:=\sum\limits_{j=1}^{k-1} {\phi _{h}^{j}}\left[ r_{h}^{j}+\min \left\{ { {\max }_{\theta \in \Gamma _{h+1}^ {k}\left( s_{h+1}^{j} \right)}}{ {\mathbb{E}}_{a\sim\theta }}\left[ \tilde{Q}_{h+ 1}^{k}\left( s_{h+1}^{j},a \right) \right],H \right\} \right] bhk:=j=1∑k−1ϕhj[rhj+min{ maxθ∈Γh+1k(sh+1j)Ea∼θ[Q~h+1k(sh+1j,a)],H}]. After these calculations in the first cycle , Agents are distributed Γ h k ( s h k ) \Gamma _{h}^{k}\left( s_{h}^{k} \right) Γhk(shk) Draw actions in a h k a_{h}^{k} ahk In the second cycle . Definition V ~ h k ( s ) : = min { max θ ∈ Γ h k ( s ) E a ∼ θ [ Q ~ h k ( s , a ) ] , H } \tilde{V}_{h}^{k}(s):=\min \left\{ { {\max }_{\theta \in \Gamma _{h}^{k}(s) }}{ {\mathbb{E}}_{a\sim\theta }}\left[ \tilde{Q}_{h}^{k}(s,a) \right],H \right\} V~hk(s):=min{ maxθ∈Γhk(s)Ea∼θ[Q~hk(s,a)],H} , and E 3 : = { ∣ * w ~ h k , ϕ ( s , a ) * − Q ~ h π ( s , a ) − [ P h V ~ h + 1 π − V ~ h + 1 k ] ( s , a ) ∣ ≤ β ∥ ϕ ( s , a ) ∥ ( A h k ) − 1 , ∀ ( a , s , h , k ) ∈ A × S × [ H ] × [ K ] } { {\mathcal{E}}_{3}}:=\left\{ \left| \left\langle \mathbf{\tilde{w}}_{h}^{k},\phi (s,a) \right\rangle -\tilde{Q}_{h}^{\pi } \right. \right.\left. (s,a)-\left[ { {\mathbb{P}}_{h}}\tilde{V}_{h+1}^{\pi }-\tilde{V}_{h+1}^{k} \right](s,a) \right|\left. \le \beta { {\left\| \phi (s,a) \right\|}_{ { {\left( \mathbf{A}_{h}^{k} \right)}^{-1}}}},\forall (a,s,h,k)\in \mathcal{A}\times \mathcal{S}\times [H]\times [K] \right\} E3:={ ∣∣∣*w~hk,ϕ(s,a)*−Q~hπ(s,a)−[PhV~h+1π−V~h+1k](s,a)∣∣∣≤β∥ϕ(s,a)∥(Ahk)−1,∀(a,s,h,k)∈A×S×[H]×[K]}.
It can be easily proved , Theorem 2 The results described in apply to settings that focus on random strategies , That is to say 1、2、3 and 4 Next , And according to the theorem 1 in β The definition of , The probability is at least 1 − 2 δ 1- 2\delta 1−2δ, event E ~ : = E 1 ⋂ E 3 \widetilde{\mathcal{E}}:={ {\mathcal{E}}_{1}}\bigcap { {\mathcal{E}}_{3}} E:=E1⋂E3 establish . therefore , As a proposition 1 The direct conclusion of , Promise to E 1 { {\mathcal{E}}_{1}} E1 On condition that , Γ h k ( s ) \Gamma _{h}^{k}(s) Γhk(s) All policies within are secure , namely Γ h k ( s ) ⊂ Γ h safe ( s ) \Gamma _{h}^{k}(s)\subset \Gamma _{h}^{\text{safe}}(s) Γhk(s)⊂Γhsafe(s). Now? , In the following lemma , We quantified κ h ( s ) { {\kappa }_{h}}(s) κh(s).
lemma 2 ( face RSLUCB-QVI Optimistic attitude towards safety constraints ) Lemma 2 (Optimism in the face of safety constraint in RSLUCB-QVI)
Make κ h ( s ) : = 2 H τ − τ h ( s ) + 1 { {\kappa }_{h}}(s):=\frac{2H}{\tau -{ {\tau }_{h}}(s)}+1 κh(s):=τ−τh(s)2H+1 And assumptions 1,2,3 ,4 keep . then , With events E ~ \widetilde{\mathcal{E}} E On condition that , It thinks V ~ h ∗ ( s ) ≤ V ~ h k ( s ) , ∀ ( s , h , k ) ∈ S × [ H ] × [ K ] \tilde{V}_{h}^{*}(s)\le \tilde{V}_{h}^{ k}(s),\forall (s,h,k)\in \mathcal{S}\times [H]\times [K] V~h∗(s)≤V~hk(s),∀(s,h,k)∈S×[H]×[K].
The certificate is contained in Appendix B.1 in . Using lemmas 2, We prove Q ~ h ∗ ( s , a ) ≤ Q ~ h k ( s , a ) \tilde{Q}_{h}^{*}(s,a)\le \tilde{Q}_{h}^{k}(s,a) Q~h∗(s,a)≤Q~hk(s,a), f o r a l l ( a , s , h , k ) ∈ A × S × [ H ] × [ K ] \ forall (a,s,h,k)\in \mathcal{A}\times \mathcal{S}\times [H]\times [K] forall(a,s,h,k)∈A×S×[H]×[K]. This highlights the RSLUCB-QVI Of UCB characteristic , So that we can take advantage of unsafe LSVI-UCB (Jin et al., 2020) Standard analysis to establish regret circles .
Theorem 3 (RSLUCB-QVI Regret of ) Theorem 3 (Regret of RSLUCB-QVI)
Assuming 1、2、3 and 4 Next , There is an absolute constant c β > 0 { {c}_{\beta }}>0 cβ>0 So that for any fixed δ ∈ ( 0 , 1 / 3 ) \delta \in (0,1/3) δ∈(0,1/3), also Theorem 1 in β The definition of , If we set κ h ( s ) : = 2 H τ − τ h ( s ) + 1 { {\kappa }_{h}}(s):=\frac{2H}{\tau -{ {\tau }_{h}}(s)} +1 κh(s):=τ−τh(s)2H+1,
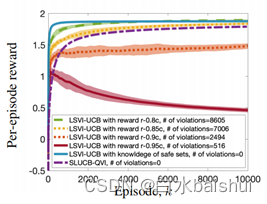
chart 1. SLUCB-QVI Comparison and verification with unsafe state-of-the-art technology :1) When LSVI-UCB (Jin et al., 2020) know γ h ∗ \gamma _{h}^{*} γh∗ , It is expected to be better than SLUCB-QVI( I do not know! γ h ∗ \gamma _{h}^{*} γh∗); 2) When LSVI-UCB I do not know! γ h ∗ \gamma _{h}^{*} γh∗( Such as SLUCB-QVI The situation of ) And its goal is to maximize r − λ ′ c r-{\lambda }'c r−λ′c instead of r , The larger λ ′ {\lambda }' λ′ As a result, the number of reward and constraint violations per round is small , and SLUCB-QVI The number of constraint violations for is zero .
Then at least 1 − 3 δ 1-3\delta 1−3δ Probability , It thinks R K ≤ 2 H T log ( d T δ ) + 2 ( 1 + κ ) β 2 d H T log ( 1 + K d λ ) { {R}_{K}}\le 2H\sqrt{T\log \left( \frac{dT}{\delta } \right)} +2(1+\kappa )\beta\sqrt{2dHT\log \left( 1+\frac{K}{d\lambda } \right)} RK≤2HTlog(δdT)+2(1+κ)β2dHTlog(1+dλK), among κ : = max ( s , h ) ∈ S × [ H ] κ h ( s ) \kappa :={ {\max } _{(s,h)\in \mathcal{S}\times [H]}}{ {\kappa }_{h}}(s) κ:=max(s,h)∈S×[H]κh(s). The certificate is attached in Appendix B.2.
5. experiment Experiments
In this section , We propose numerical simulation to supplement and confirm our theoretical findings . We evaluate SLUCB-QVI Performance in synthetic environments , And in OpenAI Gym Of Frozen Lake Implement... In the environment RSLUCB-QVI(Brockman wait forsomeone ,2016 year ).
5.1. In synthetic environment SLUCB-QVI SLUCB-QVI on synthetic environments
chart 1 The results shown in describe 20 Average value of times realized , So we chose δ = 0.01 , σ = 0.01 , λ = 1 , d = 5 , τ = 0.5 , H = 3 \delta =0.01,\sigma =0.01,\lambda =1,d=5,\tau =0.5,H=3 δ=0.01,σ=0.01,λ=1,d=5,τ=0.5,H=3 and $K= 10000 dollar . Parameters { θ h ∗ } h ∈ [ H ] { {\left\{ \theta _{h}^{*} \right\}}_{h\in [H]}} { θh∗}h∈[H] and { γ h ∗ } h ∈ [ H ] { {\left\{ \gamma _{h}^ {*} \right\}}_{h\in [H]}} { γh∗}h∈[H] come from N ( 0 , I d ) \mathcal{N}\left( 0,{ {I}_{d}} \right) N(0,Id). To tune parameters { μ h ∗ ( . ) } h ∈ [ H ] { {\left\{ \mu _{h}^{*}(.) \right\}}_{h\in [H]}} { μh∗(.)}h∈[H] And feature maps ϕ \phi ϕ such They are related to assumptions 1 compatible , We think that feature space { ϕ ( s , a ) : ( s , a ) ∈ S × A } \{\phi (s,a):(s,a)\in \mathcal{S}\times \mathcal{A}\} { ϕ(s,a):(s,a)∈S×A} Is a subset d Dimensional simplex and e i ⊤ μ h ∗ ( . ) \mathbf{e}_{i}^{\top }\mu _{h}^{*}(.) ei⊤μh∗(.) It's right S \mathcal{S} S Any probability measure of all i ∈ [ d ] i\in [d] i∈[d]. This guarantees the assumption 1 establish .
stay SLUCB-QVI The first cycle of ( The first 6 That's ok ) Calculate the security set in A h k ( s ) \mathcal{A}_{h}^{k}(s) Ahk(s), Then choose the action of maximizing the linear function ( In feature mapping $ \phi $) In feature space D h k ( s h k ) : = { ϕ ( s h k , a ) : a ∈ A h k ( s h k ) } \mathcal{D}_{h}^{k}\left( s_{h}^{k} \right):=\left\{ \phi \left( s_{h }^{k},a \right):a\in \mathcal{A}_{h}^{k}\left( s_{h}^{k} \right) \right\} Dhk(shk):={ ϕ(shk,a):a∈Ahk(shk)} In the second cycle ( The first 10 That's ok ). Unfortunately , Even if the feature space { ϕ ( s , a ) : ( s , a ) ∈ S × A } \{\phi (s,a):(s,a)\in \mathcal{S}\times \mathcal{A}\} { ϕ(s,a):(s,a)∈S×A} It's convex , aggregate D h k ( s h k ) \mathcal{D }_{h}^{k}\left( s_{h}^{k} \right) Dhk(shk) Can have forms that are difficult to maximize linear functions . In our experiment , We define mapping $\phi $ Make the set D ( s ) \mathcal{D}(s) D(s) stay ϕ ( s , a 0 ( s ) ) \phi \left( s,{ {a}_{0}}(s ) \right) ϕ(s,a0(s)) And N = 100 N=100 N=100 ( See definition 1), therefore , We can prove that SLUCB-QVI Of the 10 The optimization problem in the row can be effectively solved ( See appendix C The proof of ).
Definition 1 ( Finite star convex set ) Definition 1 (Finite star convex set)
Around one x 0 ∈ R d { {x}_{0}}\in { {\mathbb{R}}^{d}} x0∈Rd Star convex set of D \mathcal{D} D It is limited. , If there are finite vectors { x i } i = 1 N \left \{ { {\mathbf{x}}_{i}} \right\}_{i=1}^{N} { xi}i=1N bring D = ⋃ i = 1 N [ x 0 , x i ] \mathcal{D}=\bigcup _{i=1}^{N }\left[ { {\mathbf{x}}_{0}},{ {\mathbf{x}}_{i}} \right] D=⋃i=1N[x0,xi], among [ x 0 , x i ] \left[ { {\mathbf{x}}_ {0}},{ {\mathbf{x}}_{i}} \right] [x0,xi] Is the connection x 0 { {\mathbf{x}}_{0}} x0 and x Of Line i { {\mathbf{x} Line }_{i}} x Of Line i.
chart 1 It depicts SLUCB-QVI The average reward per round , And compare it with the baseline , And emphasized SLUCB-QVI Value in respecting the safety constraints of all time steps . say concretely , We will SLUCB-QVI And 1) LSVI-UCB (Jin et al., 2020) Compare , Because it has knowledge of security constraints , namely γ h ∗ \gamma _{h}^{*} γh∗; 2) LSVI-UCB, When it doesn't know γ h ∗ \gamma _{h}^{*} γh∗( Such as SLUCB-QVI The situation of ) And its goal is to maximize the function r − λ ′ c r-{\lambda }' c r−λ′c, Constraints are pushed into the objective function , about λ ′ = 0.8 , 0.85 , 0.9 {\lambda }'=0.8,0.85,0.9 λ′=0.8,0.85,0.9 and 0.95 Different values of . therefore , Discourage costly actions through low incentives . The figure verifies that γ h ∗ \gamma _{h}^{*} γh∗ Knowledgeable LSVI-UCB I don't know γ h ∗ \gamma _{h}^{*} γh∗ Better than... As expected SLUCB-QVI. Besides , When LSVI-UCB Trying to maximize r − λ ′ c r-{\lambda }'c r−λ′c( I do not know! γ h ∗ \gamma _{h} ^{*} γh∗) and SLUCB-QVI The number of constraint violations of is zero .
5.2. Frozen lake environment RSLUCB-QVI RSLUCB-QVI on Frozen Lake environment
We assessed RSLUCB-QVI stay Frozen Lake Performance in the environment . Agents seek to 10 × 10 2D Achieve the goal in the map ( chart 2a), At the same time, avoid danger .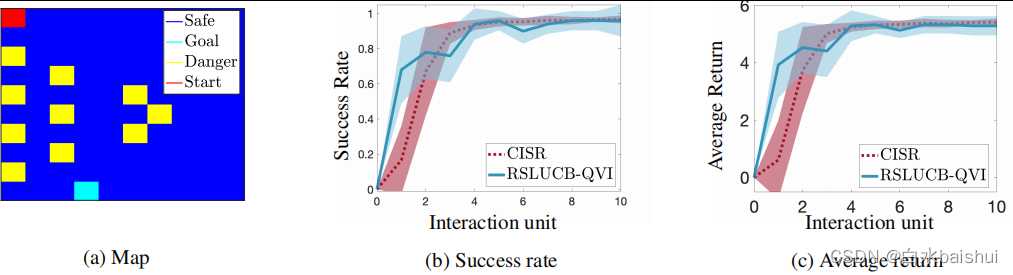
chart 2.RSLUCB-QVI and CISR (Turchetta et al., 2020) stay Frozen Lake Comparison in the environment .
At each time step , Agents can move in four directions , namely A = { a 1 : left, a 2 : right, a 3 : down, a 4 : up } \mathcal{A}=\{ { {a}_{1}}:\text{left, }{ {a}_{2}}:\text{right, }{ {a}_{3}}:\text{down, }{ {a}_{4}}:\text{up}\} A={ a1:left, a2:right, a3:down, a4:up}. It uses 0.9 The probability of moving in the desired direction , With 0.05 The probability of moving in any orthogonal direction . We set up H = 1000 , K = 10 , d = ∣ S ∣ = 100 H=1000,K=10,d=|\mathcal{S}|=100 H=1000,K=10,d=∣S∣=100, AND μ ∗ ( s ) ∼ N ( 0 , I d ) { {\mu }^{*}}(s)\sim\mathcal{N}\left( 0,{ {I}_{d}} \right) μ∗(s)∼N(0,Id) for all s ∈ S = { s 1 , … , s 100 } s\in \mathcal{S}=\left\{ { {s}_{1}},\ldots ,{ {s}_{100}} \right\} s∈S={ s1,…,s100}. then , We correctly specify all by solving a set of linear equations ( s , a ) ∈ S × A (s,a)\in \mathcal{S}\times \mathcal{A} (s,a)∈S×A Feature mapping of ϕ ( s , a ) \phi (s,a) ϕ(s,a), Make the transformation respect the details of the above environment . In order to interpret the requirement of avoiding danger as a form (11) Constraints , We will γ ∗ { {\gamma }^{*}} γ∗ and $\tau $ The adjustment is as follows : The cost of performing actions $a\in \ state s ∈ S s\in \mathcal{S} s∈S Situated mathcal{A}$ Is the probability that the agent moves to one of the dangerous states . therefore , The security policy ensures that the expected value of the probability of moving to a dangerous state is a small value . So , We set up γ ∗ = ∑ s ∈ Danger states μ ∗ ( s ) { {\gamma }^{*}}=\sum\limits_{s\in \text{ Danger states }}{ { {\mu }^{*}}}(s) γ∗=s∈ Danger states ∑μ∗(s) and τ = 0.1 \tau =0.1 τ=0.1. Besides , For each state s ∈ S s\in \mathcal{S} s∈S, Will be a safe action , That is, it leads to a small probability ( τ = 0.1 \tau =0.1 τ=0.1) One of the dangerous states of the game is given to the agent . We solve a set of linear equations to adjust θ ∗ { {\theta }^{*}} θ∗, Make in every state s ∈ S s\in \mathcal{S} s∈S, The direction to the state closest to the goal state to agent Reward 1, And play the other three directions to reward it 0.01. The model persuades agents to move towards their goals .
In the specified characteristic diagram ϕ \phi ϕ And adjust all parameters , We are 10 Interaction units (episodes)( namely K = 10 K=10 K=10) Realized RSLUCB-QVI, Each interaction unit consists of 1000 Time steps (horizon) form , namely $H= 1000 dollar ). In each interaction unit ( The plot ) During and after each move , The agent can finally be in one of the following three states :1) The goal is , This leads to the successful termination of the interaction unit ; 2) dangerous , Cause the interaction unit to fail and then terminate ; 3) Security . The agent will receive 6 The return of , Or you'll get 0.01.
In the figure 2 in , We reported more than 20 The average success rate and return of agents , We implemented for each agent 10 Time RSLUCB-QVI, And compare our results with (Turchetta et al., 2020) Proposed CISR The results are compared , Among them, the teacher provided help Agents choose safe actions through intervention . although RSLUCB-QVI and CISR The performance of these two methods is equivalent , But the important thing to consider is ,CISR Each interaction unit in ( The plot ) from 10000 Time steps , And in the RSLUCB-QVI The number in is 1000 individual . It is worth noting that ,RSLUCB-QVI Learning rate ratio CISR fast . It is also worth noting that , When using optimization intervention, we will RSLUCB-QVI And CISR Made a comparison , Compared with other types of interventions , It gives the best result .
6. Conclusion Conclusion
In this paper , We developed SLUCB-QVI and RSLUCB-QVI, These two kinds of safety RL The algorithm is linear at finite level MDP In the setting of . For these algorithms , We provide a sublinear regret boundary O ~ ( κ d 3 H 3 T ) \widetilde{\mathcal{O}}\left( \kappa \sqrt{ { {d}^{3}}{ {H}^{3}}T} \right) O(κd3H3T), among H Is the duration of each episode ,d Is the dimension of feature mapping ,κ Is a constant that characterizes security constraints , T = K H T=KH T=KH Is the total number of action scenes . We have proved that they will probably never violate unknown security constraints . Last , We are synthesizing and Frozen Lake In the environment SLUCB-QVI and RSLUCB-QVI, This proves that our algorithm has the same performance as the algorithms that understand security constraints or use existing technology Teacher advice to help agents avoid unsafe behavior .
边栏推荐
猜你喜欢

Four common methods of copying object attributes (summarize the highest efficiency)
2. Data type
MySQL develops small mall management system
Web端自动化测试失败原因汇总

Hands on deep learning (32) -- fully connected convolutional neural network FCN

智慧路灯杆水库区安全监测应用

5g/4g wireless networking scheme for brand chain stores

libmysqlclient. so. 20: cannot open shared object file: No such file or directory
leetcode1-3
Pcl:: fromrosmsg alarm failed to find match for field 'intensity'

随机推荐
Hands on deep learning (42) -- bi-directional recurrent neural network (BI RNN)
转载:等比数列的求和公式,及其推导过程
Exercise 9-5 address book sorting (20 points)
Hands on deep learning (45) -- bundle search
Summary of the most comprehensive CTF web question ideas (updating)
C language pointer interview question - the second bullet
Fabric of kubernetes CNI plug-in
Exercise 9-3 plane vector addition (15 points)
A little feeling
Kotlin: collection use
AUTOSAR from getting started to mastering 100 lectures (106) - SOA in domain controllers
Golang defer
C # use smtpclient The sendasync method fails to send mail, and always returns canceled
Deep learning 500 questions
lolcat
对于程序员来说,伤害力度最大的话。。。
Dynamic address book
Legion is a network penetration tool
Exercise 9-1 time conversion (15 points)
Write a jison parser from scratch (4/10): detailed explanation of the syntax format of the jison parser generator