当前位置:网站首页>The performance and efficiency of the model that can do three segmentation tasks at the same time is better than maskformer! Meta & UIUC proposes a general segmentation model with better performance t
The performance and efficiency of the model that can do three segmentation tasks at the same time is better than maskformer! Meta & UIUC proposes a general segmentation model with better performance t
2022-07-07 18:34:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
Share this article CVPR2022 The paper 『Masked-attention Mask Transformer for Universal Image Segmentation』 A model that can do three segmentation tasks at the same time , Better performance and efficiency than MaskFormer!Meta&UIUC Propose a general segmentation model , Performance is better than task specific models ! The code is open source !
The details are as follows :

Address of thesis :https://arxiv.org/abs/2112.01527[1]
Code address :https://bowenc0221.github.io/mask2former/[2]
01
Abstract
Image segmentation is about grouping pixels using different semantics , Such as category or instance , Each of these semantic choices defines a task . Although only the semantics of each task are different , But the current research focus is to design a special structure for each task .
The author proposes a method that can handle any image segmentation task ( panorama 、 Instance or semantics ) The new structure of ——Masked-attention Mask Transformer(Mask2Former). Its key components include masking attention (masked attention), It passes through the predicted mask Cross attention is constrained in the region to extract local features . In addition to reducing the research workload by at least three times , Its performance on four popular data sets is also much better than the best task specific structure .
The most remarkable thing is ,Mask2Former Divide for panorama (COCO Up for 57.8 PQ)、 Instance segmentation (COCO Up for 50.1 AP) And semantic segmentation (ADE20K Up for 57.7 mIoU) Reach a new level in the task SOTA level .
02
Motivation
Image segmentation studies pixel grouping . Different semantics of pixel grouping ( Such as category or instance ) It leads to different types of segmentation tasks , For example, panorama 、 Instance or semantic segmentation . Although these tasks are only semantically different , But current methods develop specific structures for each task . Based on full convolution network (FCN) Pixel by pixel classification architecture for semantic segmentation , The mask classification structure that predicts a set of binary masks dominates the instance segmentation . Although this specialized structure improves each individual task , But they lack the flexibility to extend to other tasks . for example , be based on FCN The structure of has difficulties in instance segmentation . therefore , Repeated research and hardware optimization efforts are spent on each task specific structure .
In order to solve this segmentation problem , Recent work has attempted to design a generic architecture , Be able to handle all split tasks with the same architecture ( General image segmentation ). These structures are usually based on end-to-end set prediction targets ( for example ,DETR), And without modifying the structure 、 Successfully handle multiple tasks in case of loss or training process . Be careful , Although it has the same architecture , However, the general structure is still trained separately for different tasks and data sets . In addition to flexibility , The general structure has recently shown the most advanced results in terms of semantics and panoramic segmentation . However , Recent work is still focused on promoting dedicated structures , This raises a question : Why does the general structure not replace the special structure ?

Although the existing general structure is flexible enough , It can handle any subdivision task , As shown in the figure above , But in practice , Their performance lags behind the best professional structures . In addition to poor performance , Universal structures are also more difficult to train . They usually need more advanced hardware and longer training time . for example , Training MaskFormer need 300 individual epoch To achieve 40.1 AP, And it can only be in one 32G In memory GPU Contains an image . by comparison , Special Swin-HTC++ Only in 72 individual epoch Get better performance in . Both performance and training efficiency problems hinder the deployment of general architecture .
In this work , The author proposes a general architecture of image segmentation , be known as Masked attention Mask Transformer(Mask2Former), It is superior to the special structure in different segmentation tasks , At the same time, it is easy to train on every task . The model is based on a simple meta architecture , The architecture consists of a backbone feature extractor 、 Pixel decoder and Transformer Decoder composition . The author proposes key improvements , To achieve better results and effective training .
First , The author in Transformer Masking attention is used in the decoder (masked attention), Limit attention to local features centered on predicted segments , These prediction segments can be objects , It can also be a region , It depends on the specific semantics of the grouping . With the standard Transformer The cross attention used in the decoder is compared to , The masking attention in this paper can converge faster , And improve performance .
secondly , The author uses multi-scale high-resolution features to help the model segment small objects / Area .
Third , The author puts forward some optimization improvements , Such as switching the order of self attention and cross attention , Make query features learnable , And eliminate omissions ; All of these can improve performance without additional calculation . Last , Without affecting performance , By calculating the mask loss at random sampling points , Saved 3× Training video memory . These improvements not only improve the performance of the model , And it makes training very easy , Make the general structure easier for users with limited computing power .
The author uses four popular data sets (COCO、Cityscapes、ADE20K and Mapillary Vistas) Assessed Mask2Former In three image segmentation tasks ( panorama 、 Instance and semantic segmentation ) Performance on . On all these benchmarks , The performance of the single structure in this paper is equal to or better than that of the special structure for the first time .Mask2Former Adopt the same structure , stay COCO Panoramic segmentation has reached 57.8 PQ Of SOTA level , stay COCO The instance segmentation has reached 50.1 AP, stay ADE20K Semantic segmentation has reached 57.7 mIoU.
03
Method
3.1. Mask classification preliminaries
The mask classification structure is predicted N Binary masks and N Corresponding category labels , Group pixels into N A fragment . Mask classification has enough versatility , You can do this by creating different segments (segment) Assign different semantics ( Such as category or instance ) To solve any split tasks . However , The challenge is to find good performance for each segmentation task . for example ,Mask RCNN Use a bounding box as a representation , This limits its application to semantic segmentation .
suffer DETR Inspired by the , Each segment in the image can be represented as C Dimension eigenvector (“ Object query ”), And can be Transformer The decoder processes , Use the set prediction goal for training . A simple meta structure will consist of three components : The method of extracting low resolution features from images Backbone network ; Gradually sample low resolution features upward from the trunk output , To generate high resolution per pixel embedded Pixel decoder ; Operating on image features to process object queries Transformer decoder . The final binary mask prediction is embedded and decoded from each pixel through object query . A successful example of this meta structure is MaskFormer.
3.2. Transformer decoder with masked attention
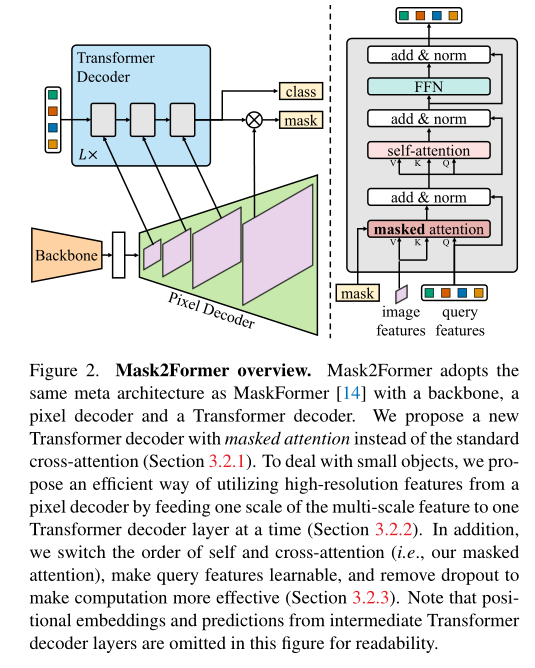
Mask2Former Adopt the above meta structure , What this article puts forward Transformer decoder ( Top right ) Replaces the standard decoder .Transformer The key components of the decoder include a masked attention operator , The operator limits the cross attention to the prediction of each query mask To extract local features in the foreground area , instead of attend Complete feature mapping . To handle small objects , The author proposes an effective multiscale strategy to utilize high-resolution features . It feeds the continuous feature mapping in the feature pyramid of the pixel decoder to the continuous Transformer In the decoder layer . Last , The author added optimization improvements , The performance of the model is improved without introducing additional calculations .
3.2.1 Masked attention
Context feature is very important for image segmentation . However , Recent research shows that , be based on Transformer The slow convergence of the model is due to the global environment in the cross attention layer , Because cross attention requires a lot of training epoch Can learn to pay attention to local object areas . The author believes that local features are sufficient to update query features , And context information can be collected through self attention . So , The author proposed masking attention (masked attention), This is a variant of cross attention , Only appear in the prediction of each query mask In the foreground area .
Standard cross attention ( Path with residuals ) The calculation for the :
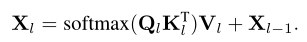
here ,l Is the layer subscript , It means the first one l Layer of N individual C Dimension query feature ,. Express Transformer Input query characteristics of decoder . They are the image features under and transformation , And are the spatial resolution of image features ., And are linear transformations .
In this paper, the mask Attention adjusts the attention matrix in the following ways :
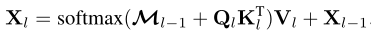
Besides ,attention mask At the feature location (x,y) The value at is :
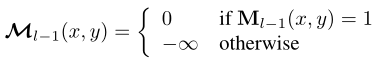
among , yes l-1 layer Transformer Binary output of decoder layer ( The threshold for 0.5). It is resized to the same resolution as .
3.2.2 High-resolution features
High resolution features improve model performance , Especially for small objects . However , This is computationally demanding . therefore , The author proposes an effective multiscale strategy to introduce high-resolution features , At the same time, control the increase of calculation . Authors do not always use high-resolution feature mapping , Instead, a feature pyramid consisting of low resolution and high resolution features is used , And send one resolution of multi-scale features to one at a time Transformer Decoder layer .
say concretely , The author uses the feature pyramid generated by the pixel decoder , The resolution is... Of the original image 1/32、1/16 and 1/8. For each resolution , The authors have added sine position embedding , And learnable scale-level The embedded . From the lowest resolution to the highest resolution , For the corresponding Transformer Decoder layer , As shown on the left above . Repeat this three layers Transformer decoder L Time . therefore , The final Transformer The decoder has 3L layer .
More specifically , The receiving resolution of the first three layers is
402 Payment Required
and Characteristic graph , among H and W Is the original image resolution . For all layers below , This pattern repeats in a circular fashion .3.2.3 Optimization improvements
standard Transformer The decoder layer consists of three modules , Process query features in the following order : Self attention module 、 Cross attention and feedforward networks (FFN). Besides , Query features () Being sent Transformer The decoder was zero initialized , And it is associated with learnable location embedding . Besides ,dropout Apply to residual connections and attention map.
In order to optimize the Transformer Decoder design , The author has made the following three improvements . First , Switch the order of self attention and cross attention ( namely masked attention) To improve the efficiency of calculation : The query feature of the first self attention layer does not depend on image features , Therefore, the application of self attention will not generate any meaningful features .
secondly , Make the query feature () You can also learn ( Still retain the learnable query location ), And learnable query features are used in Transformer The decoder predicts mask() Was directly supervised before . The author finds that the functions of these learnable query features are similar to region proposal The Internet , And can generate mask proposal. Last , The author found dropout It's not necessary , It usually reduces performance . therefore , The author completely eliminated the dropout.
3.3. Improving training efficiency
One limitation of the training common architecture is , Due to high resolution mask forecast , Video memory consumption is large , This makes them more difficult to use than video memory friendly dedicated architectures . for example ,MaskFormer Only in the presence of 32G The memory GPU Put a single image in the middle . suffer PointRend and Implicit PointRend Inspired by the , The author uses sampling point calculation in both matching and final loss calculation mask Loss .
To be specific , Building for bipartite matching cost In the matching loss of the matrix , The author is for all predictions and ground truth mask Uniformly sample the same K Point set . In predicting what it matches ground truth In the final loss between , The author uses importance sampling to evaluate different predictions and ground truth Different K Point sets are sampled . among , Set up K=12544, namely 112×112 spot . This new training strategy effectively reduces the training memory 3 times , From each image 18GB Reduced to 6GB.
04
experiment
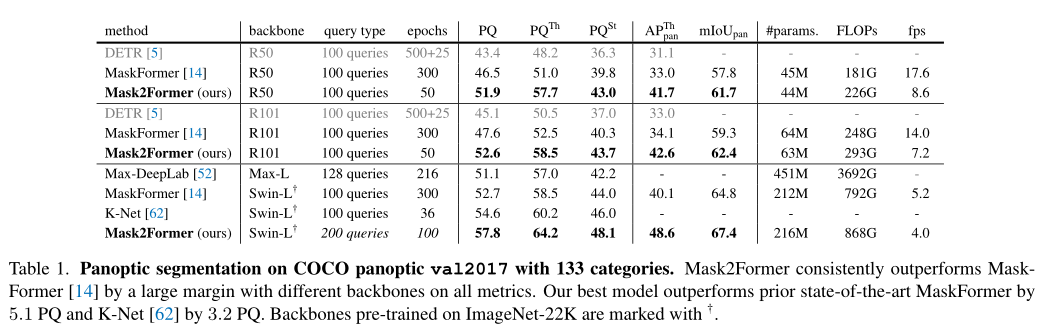
In the above table , The author will Mask2Former And COCO The most advanced panoramic segmentation models on the panoramic segmentation dataset are compared .Mask2Former It is always better than MaskFormer Higher than 5 individual PQ above , At the same time, the convergence speed is fast 6 times .
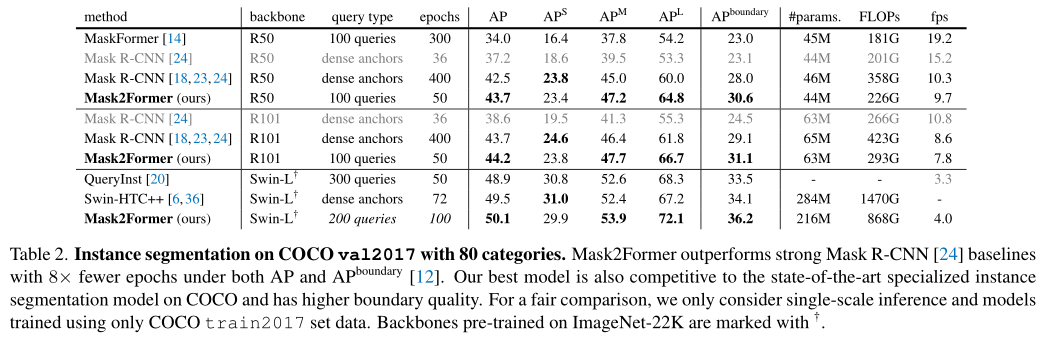
In the above table , The author will Mask2Former And COCO The latest models on the instance segmentation dataset are compared . With the help of ResNet Backbone network ,Mask2Former In the use of large-scale jittering(LSJ) In the case of enhancement , Better performance than the Mask R-CNN, Simultaneous need 8× Less training iterations . rely on Swin-L Backbone network ,Mask2Former Its performance is superior to the most advanced HTC++.
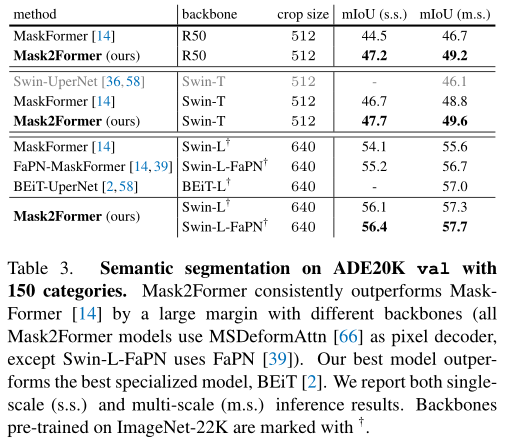
The above table , The author will Mask2Former And ADE20K The most advanced semantic segmentation models on the dataset are compared .Mask2Former The performance on different trunks is better than MaskFormer, This shows that the proposed improvement even improves the result of semantic segmentation .
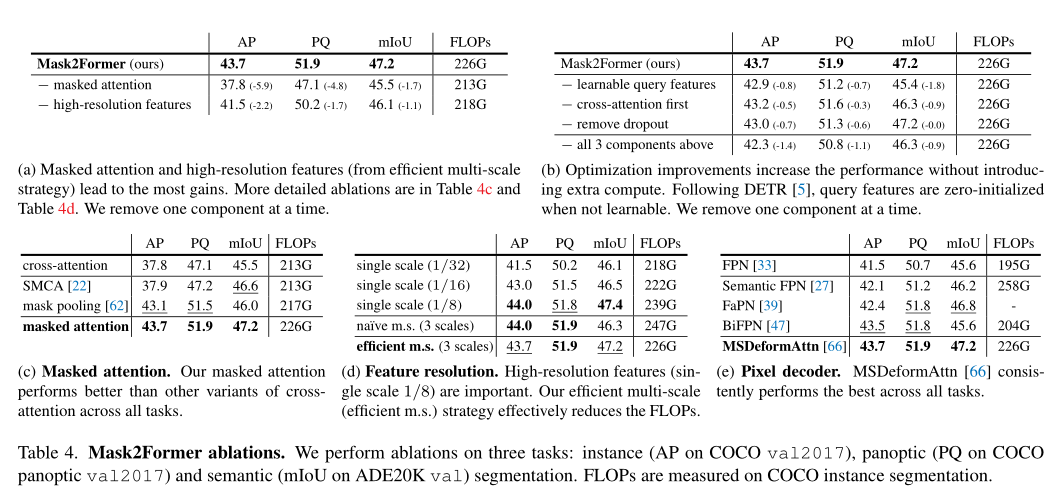
The above table shows the ablation experimental results of the module proposed in this paper , It can be seen that , The module proposed in this paper can promote the accuracy and efficiency of segmentation .
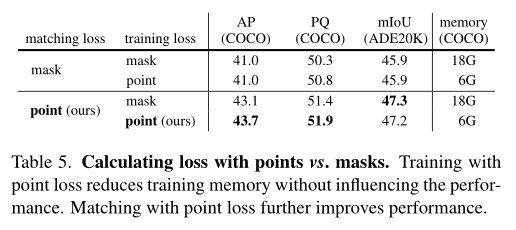
In the above table, the author studied the impact of computing losses based on masks or sampling points on performance and training video memory . Use the sampling points to calculate the final training loss , You can reduce the training memory without affecting the performance 3 times . Besides , Using sample points to calculate the matching loss can improve the performance of all three tasks .
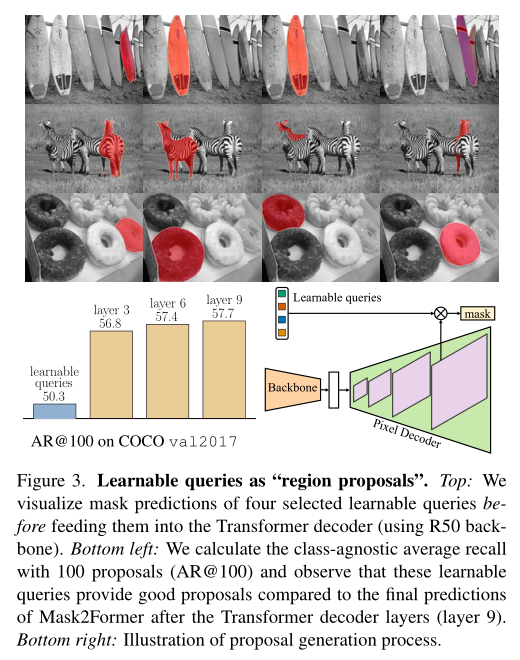
In the diagram above , The author visualizes the mask prediction of selected learnable queries , Then enter it Transformer decoder . By calculation COCO val2017 On 100 The predicted class unknowable average recall, Further to these proposal The quality of . It can be seen that , These learnable queries have achieved very good results .
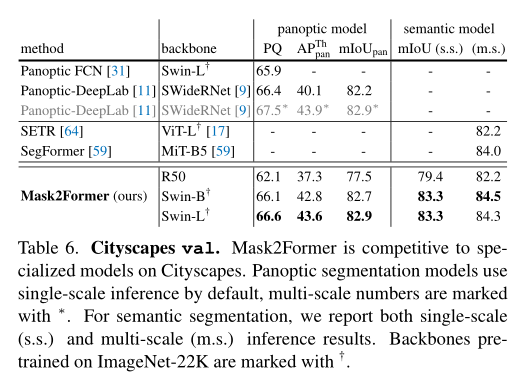
In order to prove the Mask2Former It can be extended to COCO Outside the data set , The author further carried out experiments on other popular image segmentation data sets . In the above table , The author shows Cityscapes Result .
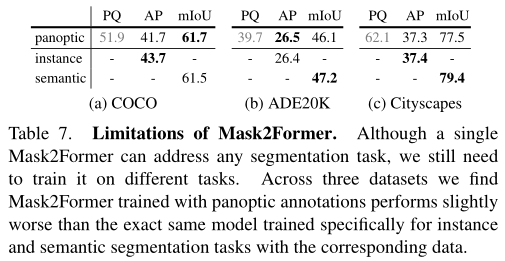
The ultimate goal of this paper is to train a single model for all image segmentation tasks . In the above table , The author found that training on panoramic segmentation Mask2Former It is only slightly worse than the identical model trained with corresponding annotations on the three data sets , For example, semantic segmentation task . This shows that , Even though Mask2Former It can be extended to different tasks , But you still need to train for these specific tasks .
05
summary
The author proposes a method for general image segmentation Mask2Former.Mask2Former Based on a simple meta framework , A new Transformer decoder , The decoder uses the proposed masked attention, On four popular datasets , In all three main image segmentation tasks ( panorama 、 Instances and semantics ) Both achieved the best results , Even better than the best specialized models designed for each benchmark , At the same time, it maintains the performance that is easy to train . Compared with designing a dedicated model for each task ,Mask2Former Saved 3 Times the research workload , And users can use it with limited computing resources .
Reference material
[1]https://arxiv.org/abs/2112.01527
[2]https://bowenc0221.github.io/mask2former/

END
Welcome to join 「 Image segmentation 」 Exchange group notes : Division

边栏推荐
- [4500 word summary] a complete set of skills that a software testing engineer needs to master
- 性能测试过程和计划
- 直播软件搭建,canvas文字加粗
- Understanding of 12 methods of enterprise management
- Chapter 3 business function development (to remember account and password)
- AI defeated mankind and designed a better economic mechanism
- 小程序中实现付款功能
- C语言中匿名的最高境界
- socket编程之常用api介绍与socket、select、poll、epoll高并发服务器模型代码实现
- Discuss | frankly, why is it difficult to implement industrial AR applications?
猜你喜欢

Backup Alibaba cloud instance OSS browser

性能测试过程和计划
socket编程之常用api介绍与socket、select、poll、epoll高并发服务器模型代码实现

CVPR 2022丨学习用于小样本语义分割的非目标知识
Nunjuks template engine

The report of the state of world food security and nutrition was released: the number of hungry people in the world increased to 828million in 2021
C语言中匿名的最高境界
Kubernetes DevOps CD工具对比选型
小试牛刀之NunJucks模板引擎
Introduction of common API for socket programming and code implementation of socket, select, poll, epoll high concurrency server model
随机推荐
Five simple ways to troubleshoot with Stace
[network attack and defense principle and technology] Chapter 4: network scanning technology
4种常见的缓存模式,你都知道吗?
Idea completely uninstalls installation and configuration notes
万字保姆级长文——Linkedin元数据管理平台Datahub离线安装指南
Backup Alibaba cloud instance OSS browser
SQLite SQL exception near "with": syntax error
socket编程之常用api介绍与socket、select、poll、epoll高并发服务器模型代码实现
Performance test process and plan
Yearning-SQL审核平台
Disk storage chain B-tree and b+ tree
Tips of this week 135: test the contract instead of implementation
More than 10000 units were offline within ten days of listing, and the strength of Auchan Z6 products was highly praised
[principle and technology of network attack and Defense] Chapter 6: Trojan horse
高考填志愿规则
保证接口数据安全的10种方案
Summary of evaluation indicators and important knowledge points of regression problems
Chapter 1 Introduction to CRM core business
Slider plug-in for swiper left and right switching
PIP related commands