当前位置:网站首页>Graph embedding learning notes
Graph embedding learning notes
2022-07-05 20:36:00 【Salted fish lying flat occasionally】
List of articles
- 1 What is graph embedding ?
- 2 Graph embedding method
- 3 Challenges of graph embedding
- 4 Graph embedding surface test questions
1 What is graph embedding ?
Map the nodes or edges of a graph to a low dimensional vector space , namely Mass 、 High dimensional 、 isomerism 、 Complex and dynamic data are represented as unified 、 Low dimension 、 Dense vectors , To preserve the structure and properties of a graph , It aims to realize node classification and clustering 、 Link prediction 、 Visualization and reconstruction diagram etc. , Provide a method with lower computational complexity .
Include node 、 edge 、 Subgraphs 、 Full picture be based on Manual construction features 、 Matrix decomposition 、 Random walk 、 Figure neural network Graph embedding method .
2 Graph embedding method
2.0 Method basis — Word2vec Methods and Skip-Gram Model
Word2vec Methods and Skip-Gram Model is the basis of graph embedding method .
word2vec The thought of can be simply summed up in one sentence : Using massive text sequences , Predict the probability of target word co-occurrence according to the context word , Let a constructed network optimize to maximize probability , The resulting parameter matrix is the vector of words .
Word2vec It's a kind of The embedding method of converting words into embedded vectors , Similar words should have similar embeddedness . Using a layer of implicit neural network Skip-Gram The Internet , Enter the central word to predict the surrounding words 【CBOW Model , Use the surrounding words to predict the central word 】.Skip-Gram Be trained to predict adjacent words in sentences . This task is called pseudo task , Because it is only used in the training stage . The network accepts words at the input , And optimize it , So that it can predict the adjacent words in the sentence with high probability .
2.1 Deep swimming DeepWalk
word2vec Suppose adjacent words are similar , Random walk assumes that adjacent nodes are similar , It can be applied to .
Deep swimming ( DeepWalk) Is based on Word2vec A graph embedding method is proposed , It is an extension of language model and unsupervised learning from word sequence to graph , Firstly, the neighbor nodes of nodes in the network are randomly generated 、 Form a fixed length random walk sequence , Reuse Skip-Gram model The fixed length node sequence generated by the type pair is mapped into a low dimensional embedded vector . This method can learn the relationship information of node pairs , The time complexity is O( log | V| ) , The incremental learning of dynamic graph is realized .
The pseudo code is shown in the figure below :

DeepWalk There are two sets of weights :
①N Of nodes D dimension embedding ②(N-1) A logistic regression , Everyone with a D A weight
Advantages and disadvantages
【 advantage 】
① It is the first to apply the idea of deep learning and natural language processing to graph machine learning .
② In the sparse annotation node classification scenario , Excellent embedding performance .
③ Linear parallel sampling is possible 、 Online incremental training
【 shortcoming 】
① Uniform random walk , There is no biased swimming direction .(Node2Vec)
② Need a lot of random walk sequence training .
③ Based on random walk , To see only one spot . Two nodes far away cannot interact . Can't see the full picture information .( Figure neural network can ), That is, the limited step size will affect the integrity of the context information .
④ Unsupervised , Only encode the connection information of the diagram , The attribute characteristics of nodes are not used .
⑤ Neural networks and deep learning are not really used .
⑥ Not suitable for weighted graphs , Only the second-order similarity of graphs can be maintained ;
⑦ In the face of large-scale map , It is complicated to adjust the super parameters , And walk more than 2^5 The post embedding effect is not significant enough .
DeepWalk Method performs random steps , This means that embedding cannot well preserve the local neighborhood of nodes .Node2vec Method solved the problem .
2.2 node - Vector model node2vec
Node2vec yes DeepWalk An improvement of , By adjusting the breadth respectively, we can walk first ( Breadth-First Search,BFS) and Depth first swim ( Depth-First Search,DFS ) Policy parameters , To get the global structure and local structure of the graph .
The main steps are as follows :
① Calculate the transition probability , combination BFS and DFS Generate random walk sequence
② use Skip-Gram The model embeds the generated walk sequence
Advantages and disadvantages
【 advantage 】
Each step can be processed in parallel , Can maintain semantic information and structural information .
【 shortcoming 】
For nodes with specific attributes, the embedding effect still needs to be improved .
Node2vec vs DeepWalk
node2vec The difference in deepwalk, Mainly through the jump probability between nodes . The jump probability is a third-order relationship , That is, consider the current jump node , And the previous node To the next node “ distance ”, By returning parameters p And access ( Or far away ) Parameters q Control the direction of travel ( Return or continue forward )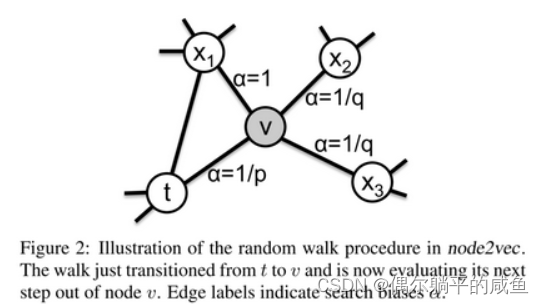
p and q Are all 1 When ,node2vec Degenerate to deepwalk, So in fact, we can know ,deepwalk Itself is pure random random walk , and node2vec More like based on deepwalk A flexible framework on , Because we can change what we want to do by specifying super parameters embedding Purpose .
therefore , It can only be said deepwalk It can capture the co-occurrence between nodes , This co-occurrence may include homogeneity or structure , and node2vec Users can flexibly define whether we want to capture more structure or more homogeneity . If you want to consider based on the whole graph Homogeneity of , For example, the same or similar roles in remote local communities mentioned above embedding problem , We need to consider using other embedding Algorithm to solve , For example, the computational complexity is very high, and it can't be used on a large scale graph Running on struc2vec.
2.3 LINE
It can be applied to large-scale graphs , Represents the structural information between nodes .
LINE Methods,
LINE Adopt breadth first search strategy to generate context nodes : Only a node that is at most two hops away from a given node is considered its neighbor . Besides , And DeepWalk The layering used in softmax comparison , It uses negative sampling to optimize Skip-gram Model .
characteristic :
First order similarity and second order similarity are considered 【 First order : Local structural information ; Second order : The neighbor of the node . Nodes sharing neighbors may be similar .】, Splice the first-order similarity and the second-order similarity .
Advantages and disadvantages
【 advantage 】
deepwork Only undirected graph 、 and LINE It can be a directed graph or an undirected graph .
【 shortcoming 】
In the low degree node embedding The effect of coding is not good ,
2.4 struc2vec
DeepWalk and Node2vec One disadvantage of is due to walk The sampling length of is limited , It is impossible to effectively model long-distance nodes with structural similarity . But the reason why the previous algorithm performs better is that most data sets tend to depict homogeneity , That is, the nodes with similar distance are also similar in the feature space , It is enough to cover most data sets .Struc2vec In the process of building the graph , There is no need for node location information and label information , Only rely on the concept of node degree to build a multi-layer graph .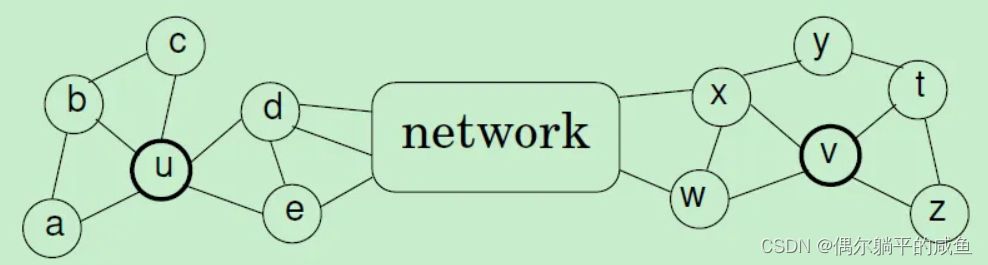
An intuitive concept , If two nodes have the same degree , Then these two nodes are more similar in structure , further , If all neighbor nodes of these two nodes also have the same degree , The two nodes should be more similar in structure .Struc2vec Based on the above intuitive concept , Use dynamic regularization , To construct the multi-layer graph and corresponding edges .
2.5 SDNE
Previous DeepWalk、LINE、node2vec、struc2vec Both use shallow structures , Shallow models often fail to capture highly nonlinear network structures . That is, there is SDNE Method , Use multiple nonlinear layers to capture node Of embedding, It does not perform random walks .SDNE The performance on different tasks is very stable .
Its structure is similar to a self encoder :
own —> vector —> neighbor
Its design keeps the embedding close to the first-order and second-order .
The first-order approximation is the local pairwise similarity between nodes connected by edges . It describes the characteristics of the local network structure . If two nodes in the network are connected to the edge , Then they are similar . When one paper quotes another , This means that they cover similar topics ;
Second order proximity represents the similarity of adjacent structures of nodes . It captures the global network structure . If two nodes share many neighbors , They are often similar .
SDNE The proposed neural network of automatic encoder has two parts - See the picture below . Automatic encoder ( Left 、 Right network ) Accept node adjacency vector , And after training to rebuild the node adjacency . These automatic encoders are named original automatic encoders , They learn secondary proximity . Adjacency vector ( A row in the adjacency matrix ) Have a positive value at the position that represents the connection to the selected node .
There is also a supervision part of the network —— The link between left and right . It calculates the embedding distance from left to right , And include it in the common loss of the network . The network has been trained like this , Left 、 The right automatic encoder gets all the node pairs connected by the input side . The loss of the distance part helps to maintain first-order proximity .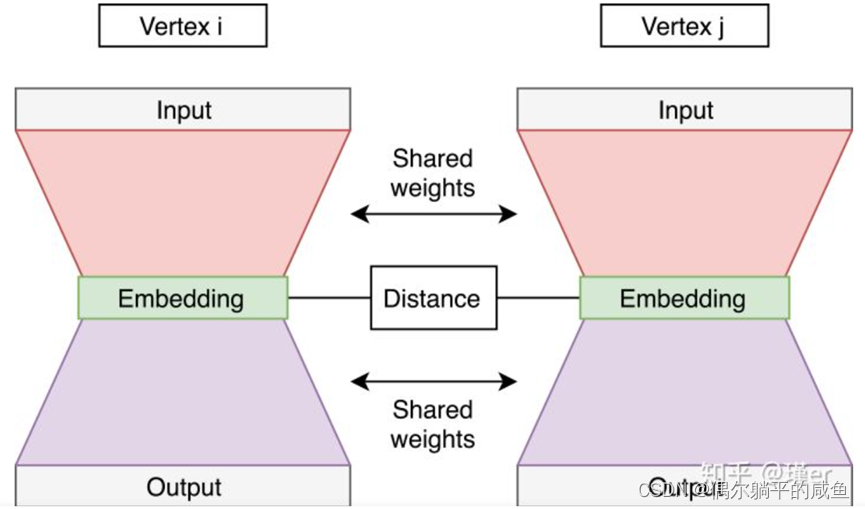
The total loss of the network is from left 、 It is calculated from the sum of the loss of the encoder and the loss of the middle part .
Summary of the above five methods and code implementation
summary
1.DeepWalk
Use random walk to form a sequence , use skip-gram Method to generate nodes embedding.
2.node2vec
Use different random walk strategies to form a sequence , similar skip-gram Method to generate nodes embedding.
3.LINE
Capture the first-order and second-order similarity of nodes , Solve respectively , Then splice the first and second order together , nodal embedding.
4.struc2vec
Capture the structure information of the graph , When its structural importance is greater than that of its neighbors , It has a good effect .
5.SDNE
Multiple nonlinear layers are used to capture the first-order and second-order similarity .
Code implementation
https://github.com/shenweichen/GraphEmbedding
2.6 graph2vec
This method is to embed the whole graph . It calculates a vector that describes the graph . In this part, choose graph2vec As a typical example , Because it is an excellent method to realize graph embedding .
Graph2vec be based on doc2vec The idea of method , It has been used. SkipGram The Internet . It gets the input document ID, And trained to maximize the probability of predicting random words from the document .
Graph2vec The method consists of three steps :
① Sample from the graph and relabel all subgraphs . A subgraph is a set of nodes that appear around the selected nodes . The distance between nodes in the subgraph does not exceed the number of selected edges .
② Training Jump Graph Model . The diagram is similar to the document . Because documents are collections of words , So a graph is a set of subgraphs . At this stage , Train the jump graph model . It is trained to predict the probability of subgraphs existing in the input graph to the greatest extent . The input graph is provided as a heat vector .
③ By providing a diagram at the input ID Calculate the embedding as a unique heat vector . Embedding is the result of hidden layers . Because the task is to predict the subgraph , Therefore, graphs with similar subgraphs and similar structures have similar embeddedness .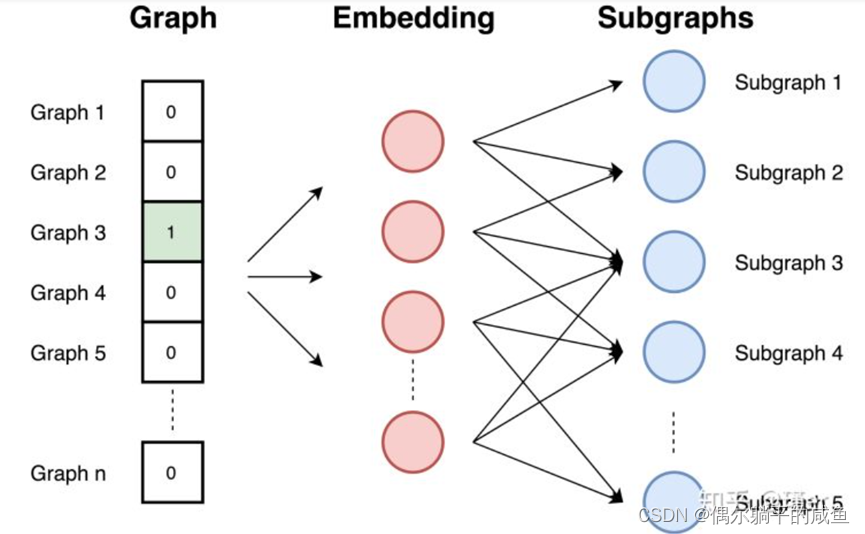
2.7 Other embedding methods
The above analysis is commonly used . Because this theme is very popular now , There are other methods available :
• Vertex embedding method :LLE, Laplacian characteristic mapping , Graph decomposition ,GraRep, HOPE, DNGR, GCN, LINE
• Graphic embedding method :Patchy-san, sub2vec (embed subgraphs), WL kernel and deep WL kernels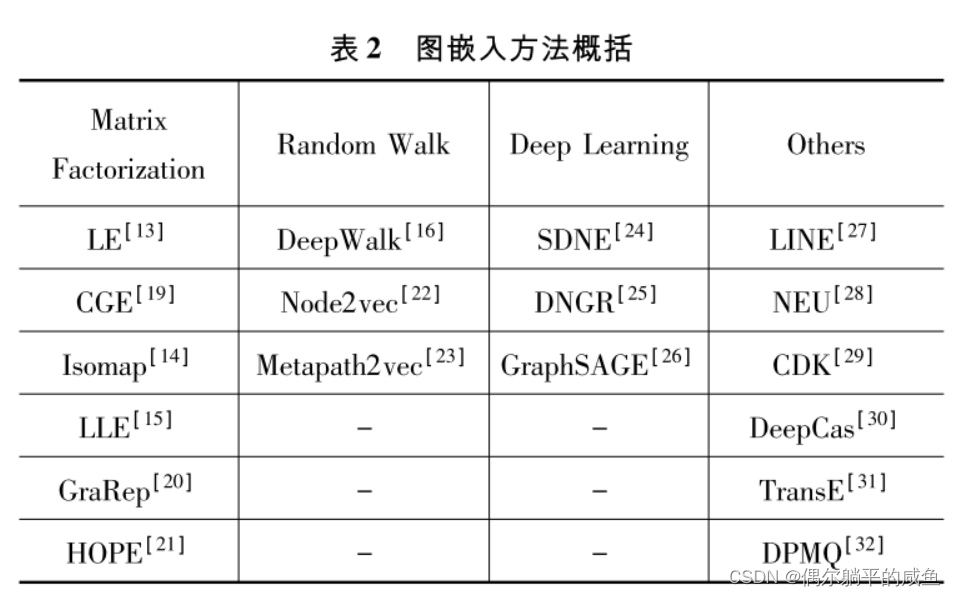
3 Challenges of graph embedding
As mentioned earlier , The goal of graph embedding is to find the low dimensional vector representation of high-dimensional graphs , It is very difficult to obtain the vector representation of each node in the graph , And there are several challenges , These challenges have been driving research in this field :
① Attribute selection : Node “ good ” Vector representation should preserve the structure of the graph and the connection between individual nodes . The first challenge is to select the graphic attributes that should be retained for embedding . Considering that there are too many distance measures and attributes defined in the diagram , This choice can be difficult , The performance may depend on the actual application scenario . They need to represent graph topology 、 Node connections and node neighbors . The performance of prediction or visualization depends on the quality of embedding .
② Extensibility : Most real networks are large , Contains a large number of nodes and edges . The embedding method should be extensible , Able to handle large drawings . Defining an extensible model is challenging , Especially when the model aims to maintain the global properties of the network . A good embedding method needs to be efficient on large graphs .
③ Embedded dimension : It is difficult to find the best dimension of representation in actual embedding . for example , Higher dimension may improve the reconstruction accuracy , But it has high time and space complexity . The lower dimension, although time 、 Low space complexity , But it will undoubtedly lose a lot of the original information in the figure . Users need to make trade-offs according to their needs . In some articles , They usually report that the embedded size is 128 To 256 Between is enough for most tasks . stay Word2vec In the method , They chose the embedding length 300.
4 Graph embedding surface test questions
The relationship between graph embedding and graph network
Reference resources :word2vec And fully connected neural networks
What information of graph is used in graph embedding , What information is discarded
Reference resources : Using topology information , Discard the internal attributes of the node
How does graph embedding algorithm deal with the problem of data sparsity
Reference resources : have access to LINE、SDNE Such algorithms that can make use of the first and second-order nearest neighbors
SDNE Model principle 、 Loss function and optimization mode
Reference resources : Using deep learning model , Use include self encoding (2 rank )+ Neighbors are similar (1 rank ) Loss function of , Capture global and local information ,SGD.
What are the ways of embedding graphs
Reference resources : Factorization 、 Random walk 、 Deep learning
How to calculate the vertex embedding of new nodes
Reference resources : If it is a direct push model , Need to sample new data to fine tune the training model , Or retrain the model . If it is an inductive trial model , You have the ability to process dynamic graphs , such as GraphSAGE.
SDNE Learning paradigm
Reference resources : It is thought in the paper that 1 Order similarity is supervision ,2 Order similarity is unsupervised , In general, it is semi supervised . Actually 1 The description of order similarity only uses the topological structure of graphs , The label of the node is not used , Think of it as self-supervised.
边栏推荐
- NPDP如何续证?操作指南来了!
- Abnova 环孢素A单克隆抗体,及其研究工具
- Mongodb/ document operation
- [record of question brushing] 1 Sum of two numbers
- Ros2 topic [01]: installing ros2 on win10
- [quick start of Digital IC Verification] 7. Basic knowledge of digital circuits necessary for verification positions (including common interview questions)
- 常用的视图容器类组件
- 怎么挑选好的外盘平台,安全正规的?
- Usaco3.4 "broken Gong rock" band raucous rockers - DP
- Common view container class components
猜你喜欢
【数字IC验证快速入门】9、Verilog RTL设计必会的有限状态机(FSM)
![[quick start of Digital IC Verification] 3. Introduction to the whole process of Digital IC Design](/img/92/7af0db21b3d7892bdc5dce50ca332e.png)
[quick start of Digital IC Verification] 3. Introduction to the whole process of Digital IC Design

1. Strengthen learning basic knowledge points
IC科普文:ECO的那些事儿
AI automatically generates annotation documents from code
Pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs
走入并行的世界

Mysql频繁操作出现锁表问题
Hongmeng OS' fourth learning

Duchefa细胞分裂素丨二氢玉米素 (DHZ)说明书
随机推荐
【数字IC验证快速入门】6、Questasim 快速上手使用(以全加器设计与验证为例)
Rainbond 5.7.1 支持对接多家公有云和集群异常报警
E. Singhal and Numbers(质因数分解)
Enter the parallel world
Classic implementation method of Hongmeng system controlling LED
Station B up builds the world's first pure red stone neural network, pornographic detection based on deep learning action recognition, Chen Tianqi's course progress of machine science compilation MLC,
强化学习-学习笔记4 | Actor-Critic
[quick start of Digital IC Verification] 9. Finite state machine (FSM) necessary for Verilog RTL design
kubernetes资源对象介绍及常用命令(五)-(ConfigMap&Secret)
常用的视图容器类组件
IC popular science article: those things about Eco
【数字IC验证快速入门】3、数字IC设计全流程介绍
Y57. Chapter III kubernetes from entry to proficiency -- business image version upgrade and rollback (30)
19 Mongoose模块化
Reinforcement learning - learning notes 4 | actor critical
mongodb基操的练习
【数字IC验证快速入门】1、浅谈数字IC验证,了解专栏内容,明确学习目标
全国爱眼教育大会,2022第四届北京国际青少年眼健康产业展会
Abnova丨CRISPR SpCas9 多克隆抗体方案
IC科普文:ECO的那些事儿