当前位置:网站首页>elastic stack
elastic stack
2022-07-03 02:02:00 【Cucumber stained with blood】
One What is a search engine
- Is based on customer needs , Use a certain algorithm to present the data to customers through retrieval
Two Inverted index
- Put a piece of text according to certain rules , Conduct
participle, Split into differententryThen record the unique identification of the entry and data (ID) Relationship . - give an example
If we were jd Search for “mobile phone” key word , At this time, we areclient,Server sideVarious brands of mobile phones will be displayed , Its names are various , Such as huaweimobile phone、 nokiamobile phone、 Applemobile phoneetc. , This is the timeServer sidewill “xx mobile phone” Split intoentry, The server will search for thisentryReturn toclient.
3、 ... and elasticsearch Concept
ES=elaticsearch Abbreviation , Elasticsearch It is an open source and highly extensible distributed full-text retrieval engine , It can store almost in real time 、 Retrieving data ; It's very extensible , It can be extended to hundreds of servers , Handle PB Level of data .
Four elasticsearch The core concept
- Indexes :
es Where to store data , It can be understood as a database in a relational database - mapping :
Defines the type of each field , It can be understood as table structure in relational database - file :
es The smallest data unit in , Often in json Format display , A document is equivalent to a row of data in a relational database - Inverted index :
Put a piece of text according to certain rules , Carry out word segmentation , Split into different entries, and then record the unique identification of entries and data (ID) Relationship . - type :
A kind of type It's like a table
1:es5 In a index There can beMultipletype.
2:es6 In a index Only byOnetype.
3:es7 Already in theremove了 type, Default _doc.
5、 ... and elasticsearch Use scenarios
- Original link
https://blog.csdn.net/laoyang360/article/details/52227541
- summary :es The role in the whole architecture is “
Search engine” Role , You need to convert the data in the databaseReal time synchronizationTo es in , Supply clientsretrieval.
6、 ... and elasticsearch Official website
https://www.elastic.co/
7、 ... and install es
edition :elasticsearch-7.4.0es Is based on jdk Environmental Science , however es Included in the deployment jdk Environmental Science , No need for us to install it again , also es Corresponding jdk Version environment , It is recommended to use the jdk edition
1. Upload and unzip
tar xvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C ~/APP
2. Modify the configuration file
cat << EOF >> /home/finance/APP/elasticsearch-7.4.0/config/elasticsearch.yml # To configure elasticsearch Cluster name , It is suggested to change it to a meaningful name . cluster.name: elasticsearch # The name of the node ,elasticsearch A random name is assigned , It is suggested to change it to a meaningful name , Easy to manage . node.name: node-1 # Set to 0.0.0.0 Allow Internet access . network.host: 0.0.0.0 #es Of http port http.port: 9200 # This configuration is required to initialize the cluster master The election cluster.initial_master_nodes: ["node-1"] # Data directory location path.data: /home/finance/data/es7 # Log path path.logs: /home/finance/logs/es7 EOF
2.1 Other configurable parameters
| Parameters | explain |
|---|---|
| cluster.name | To configure elasticsearch The cluster name of , The default is elasticsearch. It is suggested to change it to a meaningful name . |
| node.name | The node name ,es A name will be randomly assigned by default , It is recommended to specify a meaningful name , Easy to manage |
| path.conf | Set the storage path of the configuration file ,tar or zip Package installation defaults to es In the root directory config Folder ,rpm Installation defaults to /etc/ elasticsearch |
| path.data | Set the storage path of index data , The default is es In the root directory data Folder , Multiple storage paths can be set , Separated by commas |
| path.logs | Set the storage path of the log file , The default is es In the root directory logs Folder |
| path.plugins | Set the storage path of the plug-in , The default is es In the root directory plugins Folder |
| bootstrap.memory_lock | Set to true Can lock up ES Memory used , Avoid memory swap |
| network.host | Set up bind_host and publish_host, Set to 0.0.0.0 Allow Internet access |
| http.port | Set up external service http port , The default is 9200. |
| transport.tcp.port | Communication ports between cluster nodes |
| discovery.zen.ping.timeout | Set up ES Auto discover node connection timeout time , The default is 3 second , If the network delay is high, it can be set to be larger |
| discovery.zen.minimum_master_nodes | The minimum number of main nodes , The formula for this value is :(master_eligible_nodes / 2) + 1 , such as : Yes 3 Main nodes that meet the requirements , So here it's set to 2 |
3. Optimize system parameters
Use root user
# modify limit Maximum number of openings
cat << EOF >> /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096 EOF
# Modify the maximum virtual memory size
cat << EOF >> /etc/sysctl.conf vm.max_map_count=655360 fs.file-max=655360 EOF
# Effective configuration
sysctl -p
4. Optimize jvm Parameters
# Default 1G Change it to 512, It can also be changed according to business needs
vim config/jvm.options
-Xms512m
-Xmx512m
5. Configure environment variables and start
For safety's sake ,es Don't allow root User start .
echo 'export PATH=$PATH:/home/finance/APP/elasticsearch-7.4.0/bin' >> /etc/profile.d/elasticsearch.sh
source /etc/profile.d/elasticsearch.sh
# start-up
elasticsearch -d
# verification , You can also use web page
curl -I localhost:9200
8、 ... and es Index related operations
1. Interface request mode
- Get
Make a request to a specific resource ( Request specific page information , And return the entity body ) - Post
Submit data to the specified resource for processing request ( Submit Form 、 Upload files ), It may also lead to the establishment of new resources or the modification of existing resources - Put
Upload the latest content to the specified resource location ( The content of the specified document is replaced by the data transmitted from the client to the server ) - Head
With the server get Request a consistent response , The response body will not return , Get the original information contained in the small message header ( And get The request is similar to , There is no specific content in the response returned , For getting headers ) - Delete
Request server delete request-URL Resources marked *( Ask the server to delete the page ) - Trace
Echo requests received by server , For testing and diagnosis - opions
Returns the server's support for a specific resource HTML Request method or web Server send * Test server function ( Allow clients to view server performance )
2. es Common interface requests
Tools for postman
get: check
put: increase
post: Change
delete: Delete
2.1 Add index

2.2 Look at the index

2.3 Delete index

2.4 Close index

2.5 Open the index
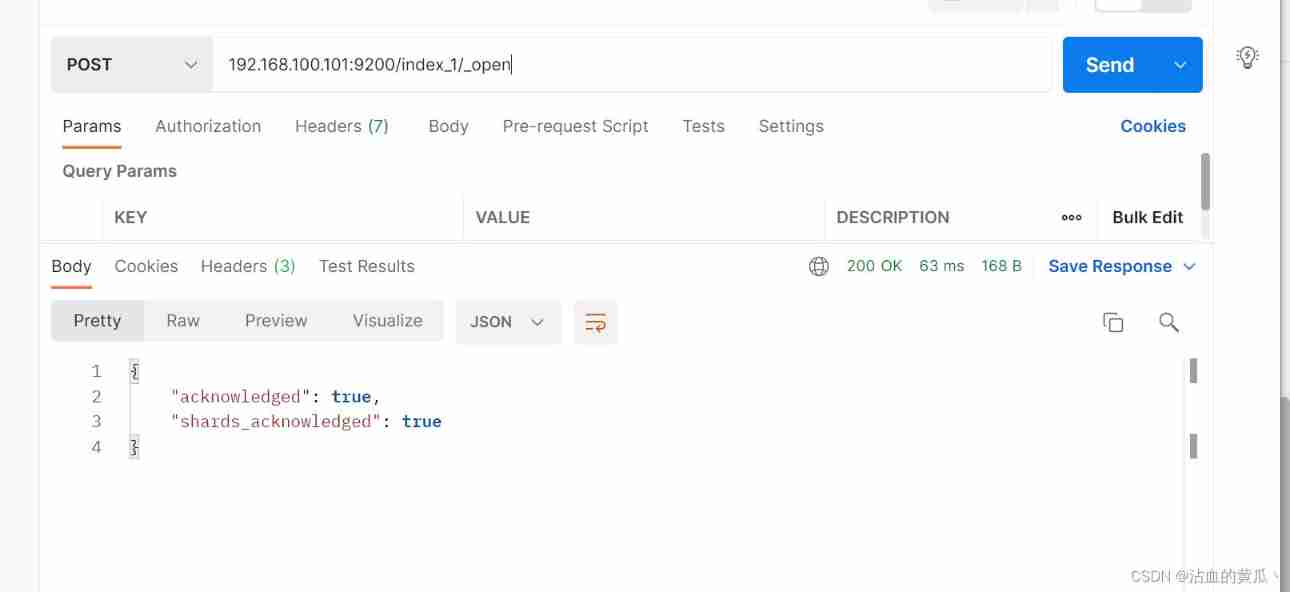
Nine es Cluster distributed architecture
1. Cluster deployment
1.1 Host distribution
| clsuter name | node name | IP | PORT |
|---|---|---|---|
| elasticsearch | node-1 | 192.168.100.101 | 9200 |
| elasticsearch | node-2 | 192.168.100.102 | 9200 |
| elasticsearch | node-3 | 192.168.100.102 | 9200 |
1.2 Profile changes
node-1
# Cluster name
cluster.name: elasticsearch
# The name of the node
node.name: node-1
# binding IP Address
network.host: 0.0.0.0
# Specify the service access port
http.port: 9200
# Appoint API End to end call port
transport.tcp.port: 9300
# Cluster address
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
# Cluster initialization can participate in the selection of node information
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
# Enable cross domain access support , The default is false
http.cors.enabled: true
## Cross domain access allowed domain names , Allow all domain names
http.cors.allow-origin: "*"
# Data directory location
path.data: /home/finance/data/es7
# Log path
path.logs: /home/finance/logs/es7
node-2
# Cluster name
cluster.name: elasticsearch
# The name of the node
node.name: node-2
# binding IP Address
network.host: 0.0.0.0
# Specify the service access port
http.port: 9200
# Appoint API End to end call port
transport.tcp.port: 9300
# Cluster address
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9301","192.168.100.103:9302"]
# Cluster initialization can participate in the selection of node information
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9301","192.168.100.103:9302"]
# Enable cross domain access support , The default is false
http.cors.enabled: true
## Cross domain access allowed domain names , Allow all domain names
http.cors.allow-origin: "*"
# Data directory location
path.data: /home/finance/data/es7
# Log path
path.logs: /home/finance/logs/es7
node-3
cluster.name: elasticsearch
# The name of the node
node.name: node-3
# binding IP Address
network.host: 0.0.0.0
# Specify the service access port
http.port: 9200
# Appoint API End to end call port
transport.tcp.port: 9300
# Cluster address
discovery.seed_hosts: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
# Cluster initialization can participate in the selection of node information
cluster.initial_master_nodes: ["192.168.100.101:9300", "192.168.100.102:9300","192.168.100.103:9300"]
# Enable cross domain access support , The default is false
http.cors.enabled: true
## Cross domain access allowed domain names , Allow all domain names
http.cors.allow-origin: "*"
# Data directory location
path.data: /home/finance/data/es7
# Log path
path.logs: /home/finance/logs/es7
1.3 View node and status
# Check your health
curl localhost:9200/_cat/health?v
curl localhost:9200/_cat/nodes
1.3.1 Health status echo description
cluster
Cluster namestatus
State of the cluster , There are three states , , respectively, green( normal )、red( It means that the main partition cannot , Data may have been lost )、yellow( Represents the main partition , But at least one copy is missing , At this time, the cluster data is still complete )node.total
Total number of online nodesnode.data
Total number of online data nodesshards
The number of fragments alivepri
The number of main fragments alive , Under normal circumstances ,pri yes shards Twice as manyrelo
Number of slices in migration , Normally 0init
Number of slices in initialization , Normally 0unassign
Unallocated shards , Normally 0pending_tasks
The task in preparation , Tasks refer to fragmentation in migration , Normally 0max_task_wait_time
The longest waiting time for a taskactive_shards_percent
Percentage of normal slices , The normal situation is 100%
2. Cluster concept
2.1 colony
elasticsearch A cluster is a collection of one or more nodes . Each cluster has a unique name . The default is elasticsearch, We can set it ourselves cluster_name Value ,cluster_name The value of is very important , A node is added to the cluster through the name of the cluster . then , Each node has its own name . Nodes can store data , Participate in cluster index data , And independent services for searching data .
2.2 Fragmentation
because ES It's a distributed search engine , So the index is usually broken down into different parts , And the data distributed in different nodes is called fragmentation . ES Automatic management and organization of fragmentation , And when necessary, rebalance the partition data , So basically, users don't have to worry about the details of sharding .
2.3 copy
ES The default is to create an index 5 Main segments , And create a replica partition for each . That is, each index is composed of 5 The cost of one main partition , Each main partition has a corresponding copy. For distributed search engines , Sharding and replica allocation will be the design core of high availability and fast search response . Both the master shard and the replica can handle query requests , The only difference between them is that only the primary shard can handle index requests . Replicas are important for search performance , At the same time, users can add or delete copies at any time . Additional copies can give you more capacity , Higher swallowing ability and stronger fault recovery ability .
Ten kibina
1. Deploy
1.1 download kibina
kibana The version should be the same as es Version match , Otherwise, there will be compatibility problems , Of this deployment es7x
# see es edition
elasticsearch -V
#kibana download
https://www.elastic.co/cn/downloads/past-releases
1.2 Deploy kibana
tar xvf kibana-7.4.0-linux-x86_64.tar.gz -C APP/
cd APP/
mv kibana-7.4.0-linux-x86_64/ kibana
cat >> /home/finance/APP/kibana/config/kibana.yml << EOF # Open Chinese i18n.locale: "zh-CN" #http port server.port: 5601 # Address , Don't write here 127.0.0.1, Otherwise web The page is inaccessible server.host: "192.168.100.101" # The service name server.name: kibana #es Address elasticsearch.hosts: ["http://localhost:9200/"] EOF
1.3 Global variables
cat >> /etc/profile.d/kibana.sh << EOF export PATH=$PATH:/home/finance/APP/kibana/bin EOF
source /etc/profile.d/kibana.sh
1.4 Start and verify
kibana >> /home/finance/logs/kibana.log &
#jobs See if running state
# see 5601 port
#web visit IP:5601
2. management es colony
2.1 modify kibana To configure
# Here is es The cluster address , Restart after modification kibana
elasticsearch.hosts: ["http://localhost:9200","http://192.168.100.101:9200","http://192.168.100.102:9200"]
11、 ... and Cluster management
1. Slice configuration
When the index is created , If no partition is specified , The default primary partition is 1, The copy is divided into 1.
1.1 Create tiles
3 Main segments , A replica fragment 
View index slices and copies
You can see the master partition and replica partition , It already exists on all three nodes , If node-1 The node is down , You can also get the index fragment through the other two nodes .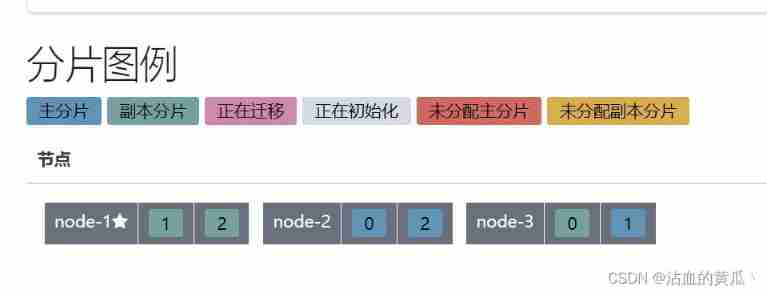
2. Split brain
One es In the cluster , Started several master, It's called cleft brain
2.1 Network problems
Cluster communication due to network delay 、 Fluctuation, etc ,node Node and master Node lost connection , There will be an election master, At this time, there is the problem of brain crack .
2.1.1 Avoid cleft brain
discovery.zen.ping.timeout Set the timeout larger , The default is 3s
2.2 Node load
The role of the master node is master For date, When the amount of data access is large , There may be a false death .
Profile parameters :
# Whether there is master node qualification
node.master: true
# Store data or not
node.date: true
2.2.1 Avoid cleft brain
Role separation strategy
- Candidate master node configuration
# Whether there is master node qualification
node.master: true
# Store data or not
node.date: false
- Data node configuration
# Whether there is master node qualification
node.master: false
# Store data or not
node.date: true
2.3 jvm Recycling
When master Node settings jvm Small memory , trigger jvm A lot of memory recycling , cause es Loss of response
2.3.1 Avoid cleft brain
elasticsearch-7.4.0/config/jvm.options in -Xms,-Xmx
Twelve logstash
1. logstash sketch
logstash It's a Data collection engine , yes data source And Data analysis storage analysis tools Important between bridge , He has a wealth of filter plug-ins .
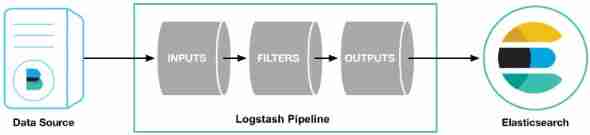
2.logstash Component explanation
logstash It's made up of three parts ,imput、filter、output
2.1 input Input plug-ins
The function of this plug-in is send Logstash Be able to read specific event sources , And Using this plug-in, you can choose to extract data from different data sources
Optional plug-ins on the official website :https://www.elastic.co/guide/en/logstash/current/input-plugins.html
2.2 filter Filter plug in
This plug-in is take input The data obtained by the plug-in is filtered by specific conditions
Optional plug-ins on the official website https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
2.3 output Output plug-in
The function of this plug-in is Output the event data to the specified destination , in other words Will imput Data read , after filter Filter , And then through output The plug-in outputs to the specified place
Optional plug-ins on the official website :https://www.elastic.co/guide/en/logstash/current/output-plugins.html
2.4 flow chart
边栏推荐
- 小程序开发的部分功能
- 全链路数字化转型下,零售企业如何打开第二增长曲线
- Hard core observation 547 large neural network may be beginning to become aware?
- Query product cases - page rendering data
- 【Camera专题】手把手撸一份驱动 到 点亮Camera
- 去除网页滚动条方法以及内外边距
- ByteDance data Lake integration practice based on Hudi
- Introduce in detail how to communicate with Huawei cloud IOT through mqtt protocol
- [data mining] task 1: distance calculation
- Network security - dynamic routing protocol rip
猜你喜欢
The testing process that software testers should know

MySQL learning 03
Certaines fonctionnalités du développement d'applets
网络安全-漏洞与木马
MySQL学习03
Take you ten days to easily complete the go micro service series (II)
![[error record] an error is reported in the fluent interface (no mediaquery widget ancestor found. | scaffold widgets require a mediaquery)](/img/fd/d862412db43a641537fd67f7910741.jpg)
[error record] an error is reported in the fluent interface (no mediaquery widget ancestor found. | scaffold widgets require a mediaquery)
![[error record] navigator operation requested with a context that does not include a naviga](/img/53/e28718970a2f7226ed53afa27f6725.jpg)
[error record] navigator operation requested with a context that does not include a naviga
Network security - vulnerabilities and Trojans

"Jetpack - livedata parsing"
随机推荐
Caused by: com.fasterxml.jackson.databind.exc.MismatchedInputException: Cannot construct instance o
可視化yolov5格式數據集(labelme json文件)
How do it students find short-term internships? Which is better, short-term internship or long-term internship?
小程序开发黑马购物商城中遇到的问题
Answers to ten questions about automated testing software testers must see
[leetcode] 797 and 1189 (basis of graph theory)
How to find summer technical internship in junior year? Are you looking for a large company or a small company for technical internship?
网络安全-破解系统密码
Method of removing webpage scroll bar and inner and outer margins
NCTF 2018 part Title WP (1)
[Appendix 6 Application of reflection] Application of reflection: dynamic agent
Cloud native topic sorting (to be updated)
leetcode961. Find the elements repeated N times in the array with length 2n
网络安全-漏洞与木马
PS remove watermark details
Reprint some Qt development experience written by great Xia 6.5
ByteDance data Lake integration practice based on Hudi
Network security - Information Collection
What are the key points often asked in the redis interview
Internal connection query and external connection