当前位置:网站首页>HKUST & MsrA new research: on image to image conversion, fine tuning is all you need
HKUST & MsrA new research: on image to image conversion, fine tuning is all you need
2022-07-07 06:22:00 【PaperWeekly】

author | Machine center editorial department
source | Almost Human
In the field of natural language processing , Network tuning has made a lot of progress , Now this idea extends to the field of image to image conversion .

Many content production projects need to convert simple sketches into realistic pictures , This involves image to image conversion (image-to-image translation), It uses a depth generation model to learn the conditional distribution of a given input natural image .
The basic concept of image to image conversion is to capture natural image manifolds using pre trained neural networks (manifold). Image transformation is similar to traversing manifolds and locating feasible input semantic points . The system uses many pictures to pre train the synthetic network , To provide reliable output from any sampling of its potential space . Synthetic network through pre training , Downstream training adjusts user input to the potential representation of the model .
these years , We have seen many task - specific approaches to achieve SOTA level , However, the current solution is still difficult to create high fidelity images for practical use .

In a recent paper , Researchers from Hong Kong University of science and technology and Microsoft Research Asia think that , For image to image conversion , Pre training is All you need. Previous approaches required specialized architecture design , And train a single transformation model from scratch , Therefore, it is difficult to generate complex scenes with high quality , Especially in the case of insufficient paired training data .
therefore , Researchers regard each image to image conversion problem as a downstream task , A simple general framework is introduced , The framework uses a pre trained diffusion model to adapt to various image to image transformations . They call the proposed pre training image to image conversion model PITI(pretraining-based image-to-image translation). Besides , The researchers also propose to enhance texture synthesis in diffusion model training by using confrontation training , It is combined with normalized guided sampling to improve the generation quality .
Last , Researchers at ADE20K、COCO-Stuff and DIODE And other challenging benchmarks to make extensive empirical comparisons of various tasks , indicate PITI The composite image shows unprecedented realism and fidelity .

Paper title :
Pretraining is All You Need for Image-to-Image Translation
Thesis link :
https://arxiv.org/pdf/2205.12952.pdf
Project home page :
https://tengfei-wang.github.io/PITI/index.html

GAN Is dead , The diffusion model persists
The author did not use the best in a particular field GAN, Instead, a diffusion model is used , Composes a wide variety of images . secondly , It should generate images from two types of potential code : A description of visual semantics , The other is to adjust the image fluctuation . semantics 、 Low dimensional potential is critical for downstream tasks . otherwise , It is impossible to transform modal inputs into complex potential spaces . In view of this , They use GLIDE As a pre training generating prior , This is a data-driven model that can generate different pictures . because GLIDE Potential text used , It allows semantic latent space .
Diffusion and score based methods show cross benchmark generation quality . In class condition ImageNet On , These models are different from those based on GAN The method is comparable to . lately , The diffusion model trained with large-scale text image pairing shows amazing ability . A well-trained diffusion model can provide a general generation prior for synthesis .
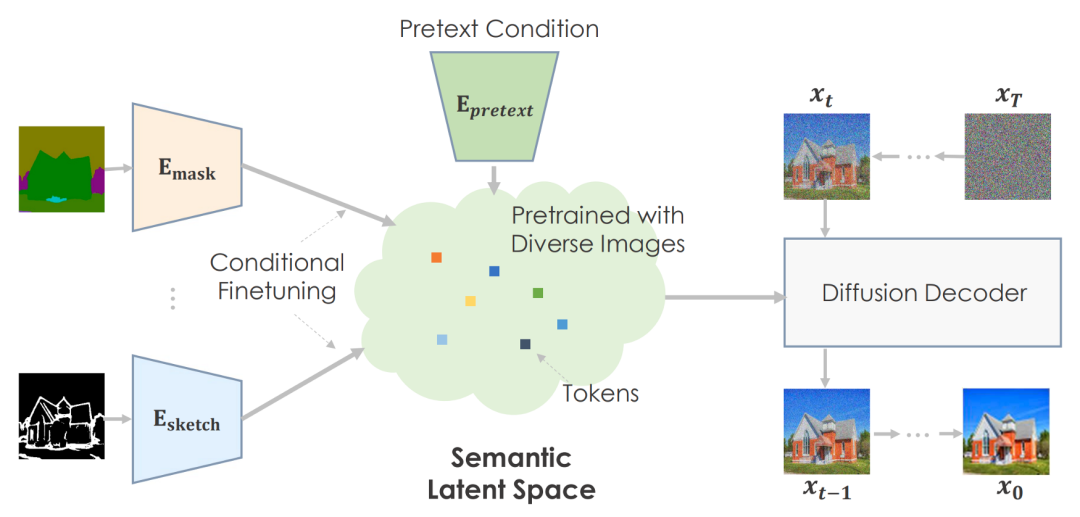

frame
Authors can use prepositions (pretext) The task is to pre train a large amount of data , And develop a very meaningful potential space to predict picture Statistics .
For downstream tasks , They conditionally fine tune the semantic space to map the task specific environment . The machine creates believable visual effects based on pre trained information .
The author suggests using semantic input to pre train the diffusion model . They use text conditions 、 Image training GLIDE Model .Transformer The network encodes text input , And output for diffusion model token. According to the plan , Text embedding space is meaningful .

The picture above is the author's work . Compared to starting from scratch , The pre training model improves the image quality and diversity . because COCO Datasets have many categories and combinations , Therefore, the basic approach cannot provide beautiful results through a compelling architecture . Their method can be difficult Create rich details with precise semantics . The picture shows the versatility of their approach .

Experiment and influence
surface 1 Show , The performance of the proposed method is always better than other models . And the more advanced OASIS comparison , From mask to image synthesis ,PITI stay FID Significant improvements have been made in . Besides , This method also shows good performance in sketch to image and geometry to image synthesis tasks .
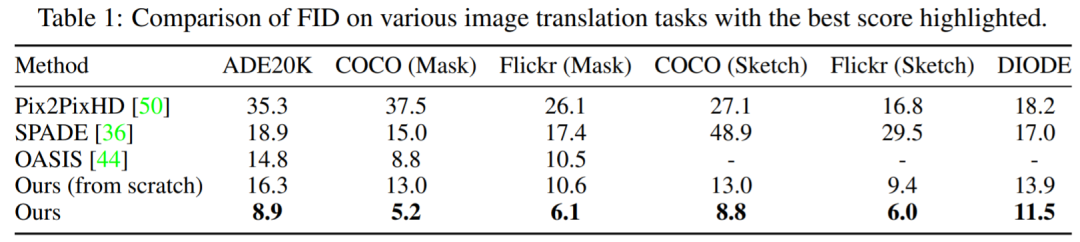
chart 3 The visualization results of the study on different tasks are shown . The result of the experiment is , Compared with the method of training from scratch , The pre training model significantly improves the quality and diversity of the generated images . The method used in this study can produce vivid details and correct semantics , Even challenging build tasks .

The study is still Amazon Mechanical Turk Upper COCO-Stuff Conducted a user study on mask to image synthesis , To obtain the 20 Of the participants 3000 ticket . Participants will get two pictures at a time , And were asked to choose a more realistic one to vote on . As shown in the table 2 Shown , The proposed approach is largely superior to the zero start model and other baselines .

Conditional image compositing creates high-quality images that meet the criteria . The fields of computer vision and graphics use it to create and manipulate information . Large scale pre training improves image classification 、 Object recognition and semantic segmentation . It is unknown whether large-scale pre training is beneficial to general generation tasks .
Energy use and carbon emissions are key issues in picture pre training . Pre training is energy consuming , But only once . Condition tuning allows downstream tasks to use the same pre training model . Pre training allows the generation model to be trained with less training data , When data is limited due to privacy issues or expensive annotation costs , It can improve the effect of image synthesis .
Link to the original text :https://medium.com/mlearning-ai/finetuning-is-all-you-need-d1b8747a7a98#7015
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column

边栏推荐
- C language sorting (to be updated)
- JVM命令之 jstat:查看JVM統計信息
- Sequential storage of stacks
- Cloud acceleration helps you effectively solve attack problems!
- Jstat pour la commande JVM: voir les statistiques JVM
- 对称的二叉树【树的遍历】
- 3531. 哈夫曼树
- 港科大&MSRA新研究:关于图像到图像转换,Fine-tuning is all you need
- Laravel uses Tencent cloud cos5 full tutorial
- Several key steps of software testing, you need to know
猜你喜欢

JVM monitoring and diagnostic tools - command line
How to set up in touch designer 2022 to solve the problem that leap motion is not recognized?

693. Travel sequencing

3531. Huffman tree

博士申请 | 上海交通大学自然科学研究院洪亮教授招收深度学习方向博士生
Ideas of high concurrency and high traffic seckill scheme
3428. 放苹果
3428. Put apples

LM小型可编程控制器软件(基于CoDeSys)笔记二十三:伺服电机运行(步进电机)相对坐标转换为绝对坐标

可极大提升编程思想与能力的书有哪些?
随机推荐
VIM mapping large K
博士申请 | 上海交通大学自然科学研究院洪亮教授招收深度学习方向博士生
Solve pod install error: FFI is an incompatible architecture
jvm命令之 jcmd:多功能命令行
Change the original style of UI components
Qt多线程的多种方法之一 QThread
JVM命令之 jstack:打印JVM中线程快照
CloudCompare-点对选取
雷特智能家居龙海祁:从专业调光到全宅智能,20年专注成就专业
字符串常量与字符串对象分配内存时的区别
改变ui组件原有样式
C语言整理(待更新)
你不知道的互联网公司招聘黑话大全
k8s运行oracle
Bypass open_ basedir
Peripheral driver library development notes 43: GPIO simulation SPI driver
Crudini profile editing tool
Talking about reading excel with POI
POI excel export, one of my template methods
K8s running Oracle