当前位置:网站首页>oracle一次性说清楚,多种分隔符的一个字段拆分多行,再多行多列多种分隔符拆多行,最终处理超亿亿。。亿级别数据量
oracle一次性说清楚,多种分隔符的一个字段拆分多行,再多行多列多种分隔符拆多行,最终处理超亿亿。。亿级别数据量
2022-07-07 06:01:00 【他们叫我技术总监】
目录
前言:
本次在进行大数据需求分析时,接到了一个“简单”的需求,统计多个检测人员的工作量。即成品检测时,我们需分析80-90个检测指标来判定它是否合格,合格后才允许出厂放行。当然要完成这些检测项目,需要多人协作。比如完成主含量的检测,需要甲乙丙丁四个人,完成杂质的检测需要甲乙魑魅魍魉6人、完成粒度检测需要乙丙丁魅魍5人。。。。等等等。假设一共就甲乙丙丁魑魅魍魉8人,因涉及80-90个检测项目,他们都有涉及对应的检测项目,但是具体谁的工作量饱和,谁的不饱和无从得知,因此通过表单统计将检测项目和对应检测人员的信息保存到了表里,只需分析,每个人每天对应每个检测项目检测了多少次,就可以分析对应的工作量饱和情况。哈哈哈,这个需求是不是超级easy~,然而噩梦才刚刚开始。。。

一、多种分隔符的一个字段拆分多行
首先我们来看,怎么将一行数据拆分为多行,在这里我们用到了 REGEXP_SUBSTR的这个函数,通过 REGEXP_SUBSTR和对应正则表达式来完成我们拆分的目的。
为了让大家快速理解代码,对应代码中[^]代表不是某某开头的,即我们拆分的时候,只会拆分列如“1,2,3”的数据,而不会去拆分“,1,2,3”的数据,其中的“+”代表多次匹配,“|”是或者的意思,即当我们有多种分隔符的时候就可以用到,例如拆分“1,2\3,4,5\6”的数据时就需要用到了。具体用法感兴趣的可以去理解oracle正则表达式的内容。
1、拆分的第一种办法
代码:
--第一种写法
SELECT
REGEXP_SUBSTR ('1,2,3',
'[^,]+',
1,
rownum)
FROM dual
CONNECT BY
rownum <= LENGTH ('1,2,3') - LENGTH (regexp_replace('1,2,3', ',', ''))+ 1;
效果:
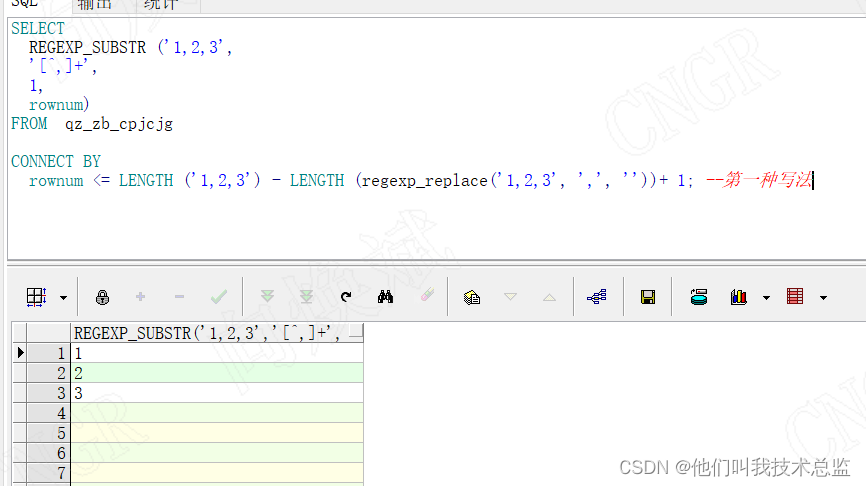
解析:
如上图所示我们成功,将‘1,2,3’拆分为了1 2 3 的3行,但是此种办法细心的小伙伴会发现有很多空行。因此强烈不推荐!!!
2、第二种办法
代码:
--第二种写法
SELECT
REGEXP_SUBSTR ('1,2,3','[^,]+',1,
rownum)
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2,3','[^,]+',1,LEVEL) is not null 效果:
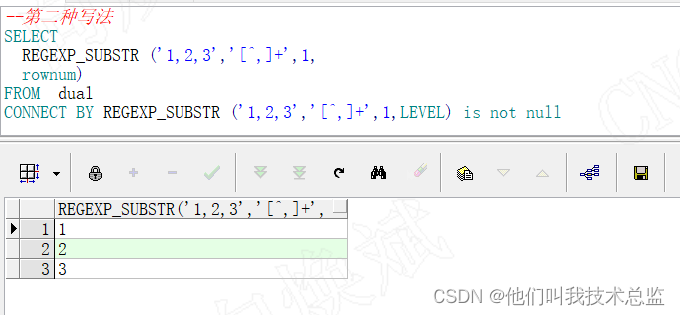
解析:
此种写法代码简洁,出来的结果和我们预想的一致,只出现了我们需要的,1,2,3的3行数据。因此推荐此种写法。
3、多种分隔符的写法
代码:
--第二种写法
SELECT
REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,
rownum)
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) is not null效果:
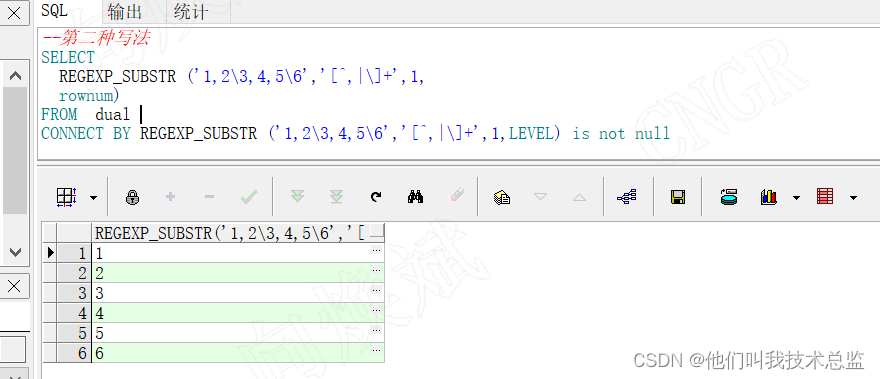
解析:
如图所示,我们只需在正则表达式中将[^,]改成[^,|\]即可,即通过“|”分隔将分隔符依次罗列即可。是不是脑瓜子嗡嗡嗡的,哈哈哈,别急,更嗡嗡嗡的在后面。

二、多行多列多种分隔符拆多行
哈哈哈,经过上面的学习,相信普通的拆分已经难不住你了,因此估计你已经觉得自己可以上天了,此时业务部门告诉你这种情况不知一列,有多列,而且有多种分隔符,此时你会发现你的小脑袋瓜子不够用了。怎么办?不急,我们先瞅瞅现场。
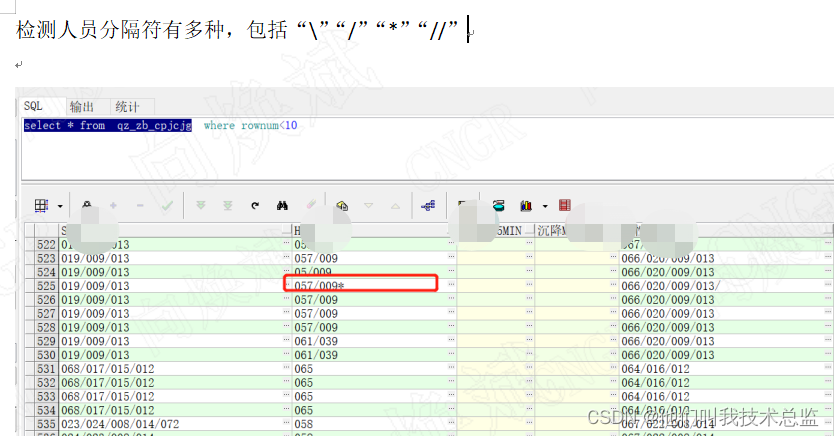
1、单行多列多分隔符拆分
代码:
--多列拆分
SELECT
REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) a,
REGEXP_SUBSTR ('7,8\3,5,9,0,6,4','[^,|\]+',1,LEVEL) a1
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) is not null
or REGEXP_SUBSTR ('7,8\3,5,9,0,6,4','[^,|\]+',1,LEVEL) is not null
效果:

解析:
如图所示,当我们拆分单行,多列的数据时,最终的数据会按最多数据列拆分为多行,然后数据一一对应,依次是[(1,7),(2,8),(3,3),(4,5),(5,9),(6,0),('',6),('',4)] ,为了显示所有的数据,因此在CONNECT BY中,用or将多列连接计算。将有3...n列时也是通过or分隔。
2、多行多列多分隔符拆分
我们先来看看原始数据的,再来尝试拆分
代码:
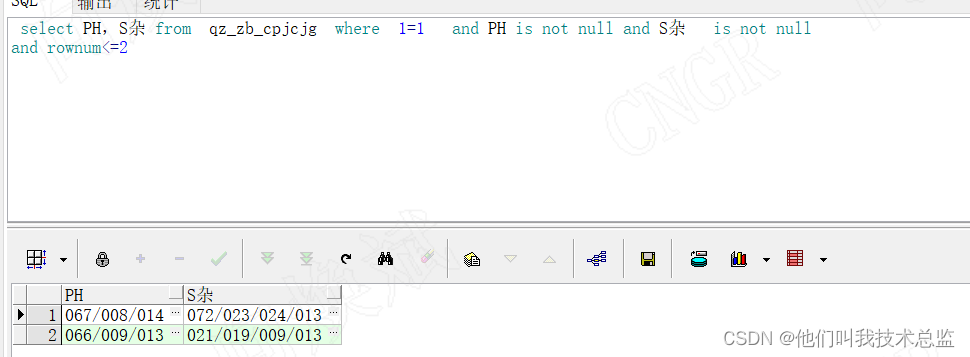
SELECT REGEXP_SUBSTR (PH,'[^/|\|//|*]+',1,LEVEL) PH,
REGEXP_SUBSTR (S杂,'[^/|\|//|*]+',1,LEVEL) S杂
from ( select PH,S杂 from qz_zb_cpjcjg where 1=1
and PH is not null and S杂 is not null
and rownum<=2
) qz_zb_cpjcjg
CONNECT BY REGEXP_SUBSTR (PH,'[^/|\|//|*]+',1,LEVEL) is not null or
REGEXP_SUBSTR (S杂,'[^/|\|//|*]+',1,LEVEL) is not null效果:
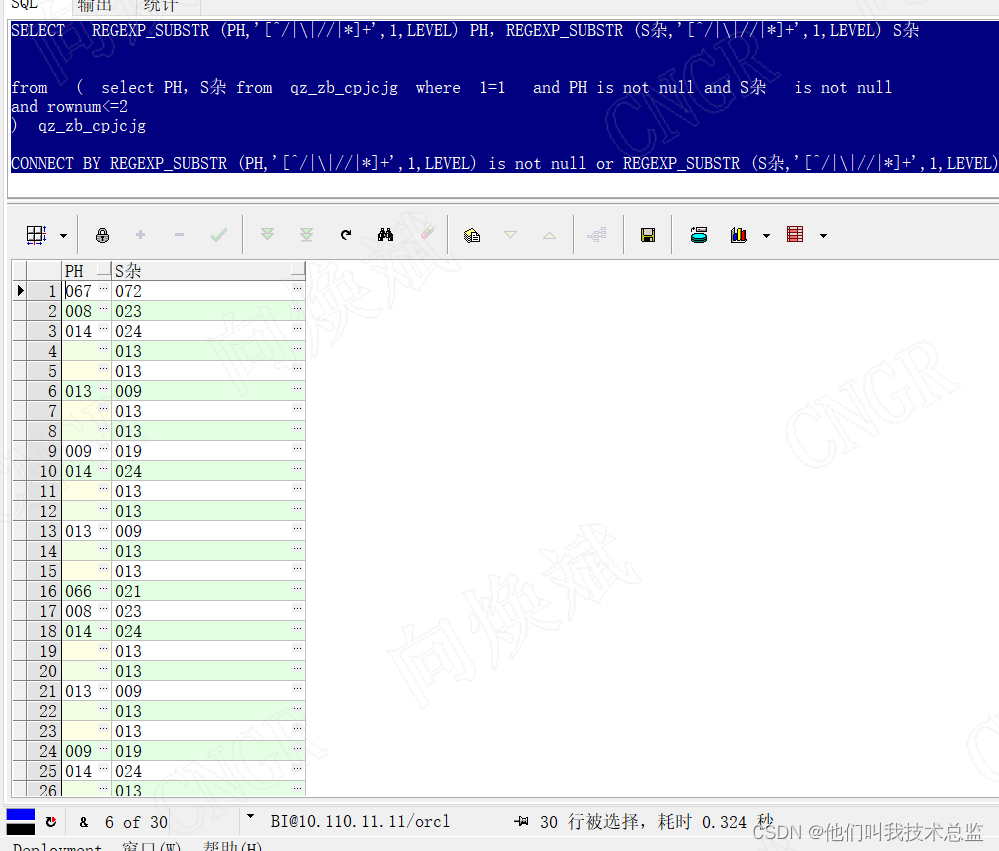
解析:
当出现2行,第一列为3个值,第二列为4个值,此时拆分的总行数为(1+2+4+8)*2行=30行,当我们把行数改为3行的时候发现拆分后的结果为(1+3+9+27)*3行=120行,当我们将行数改成4行时拆分结果为(1+4+16+64)*4=340行。此时我们发现当行数增加时,我们拆分的总行数会出现规律性的增长,即 (1+n+n²+n³)*n=n+n²+n³+n^4,其中n为你计算的行数,最大次幂为最大的拆分项。因此当我们的行数越多,并且拆分的项目越多时,我们最后拆分出的项数也会越大,当我们的行数为64行,拆分的项10个时,此时拆分的效率就会非常低。
三、 处理超亿亿。。。亿级别数据量
如图所示,我们拆分一个项目用了一个小时都没计算出来,后来测试我将所有的缓存区占用了也没计算出来。看来我们直接用上面拆分的办法好像针对这种多行的情况有点行不通了。
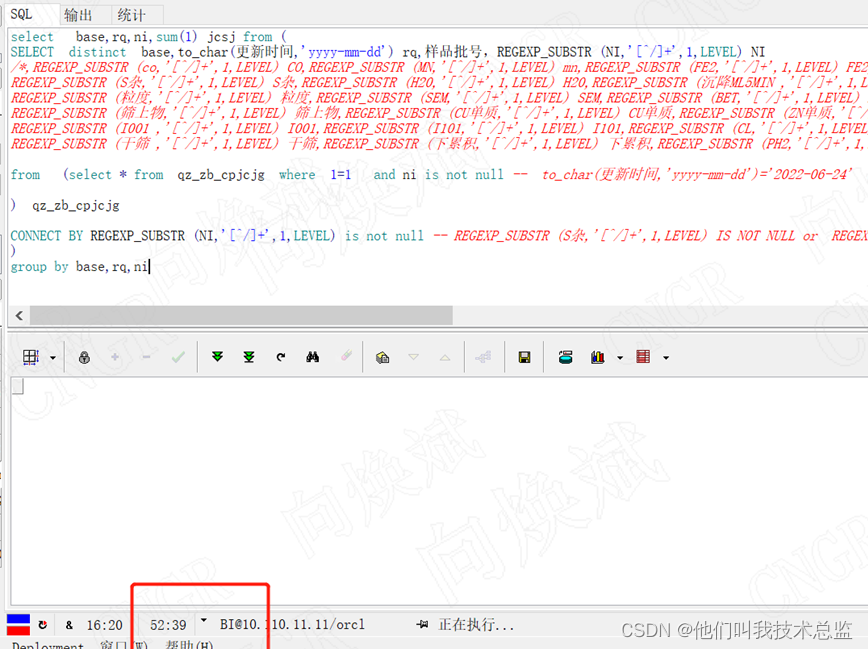
现实中我们有80-90项,并且至少有几百行,因此如此庞大的数据,最后拆分出来的结果会是超亿亿。。。亿级别,即会比10^64还要多的多。如果我们将10^64定义为不可思议,因此我们将这个拆分结果叫做“太不可思议”吧。因为它是上亿个不可思议组成的。所以,面对我们只有128G内存的服务器来处理这种级别的数据量看来是行不通了,难道只有放弃了嘛?
1、我们思考下?
我们发现我们拆分单行数据的时候效率还是非常高的,因此我们需要找到统计的最小单元,并且最小单元的行数不能超过10行,不能拆分的计算结果耗时将是你不能接受的。我们思考我们本次的需求为统计每人每天的工作量,因此我们最先想到的是按天为最小维度来统计。即我们先统计昨天的工作量,再来统计今天的工作量。再汇总历史的工作量和今天的工作量就对应是每个人的所有工作量,再取个平均值就可知工作量是否饱和了。

2、但是这合理吗?
开始小编也是这么去做的,然而发现数据量还是不小,因为。。。。

3、多行转换为单行拆分结果后统计
因为业务说,这情况就是这样,而且不能改变。因此我去找到了最小单位。即按单行拆分,最终在不到1秒就完成了所有工作量的拆分。最终保存每个检测项目对应日期的人的工作量数据。
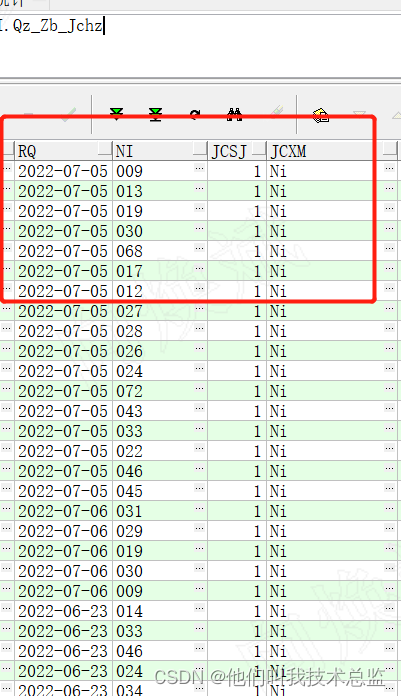
4、最终效果
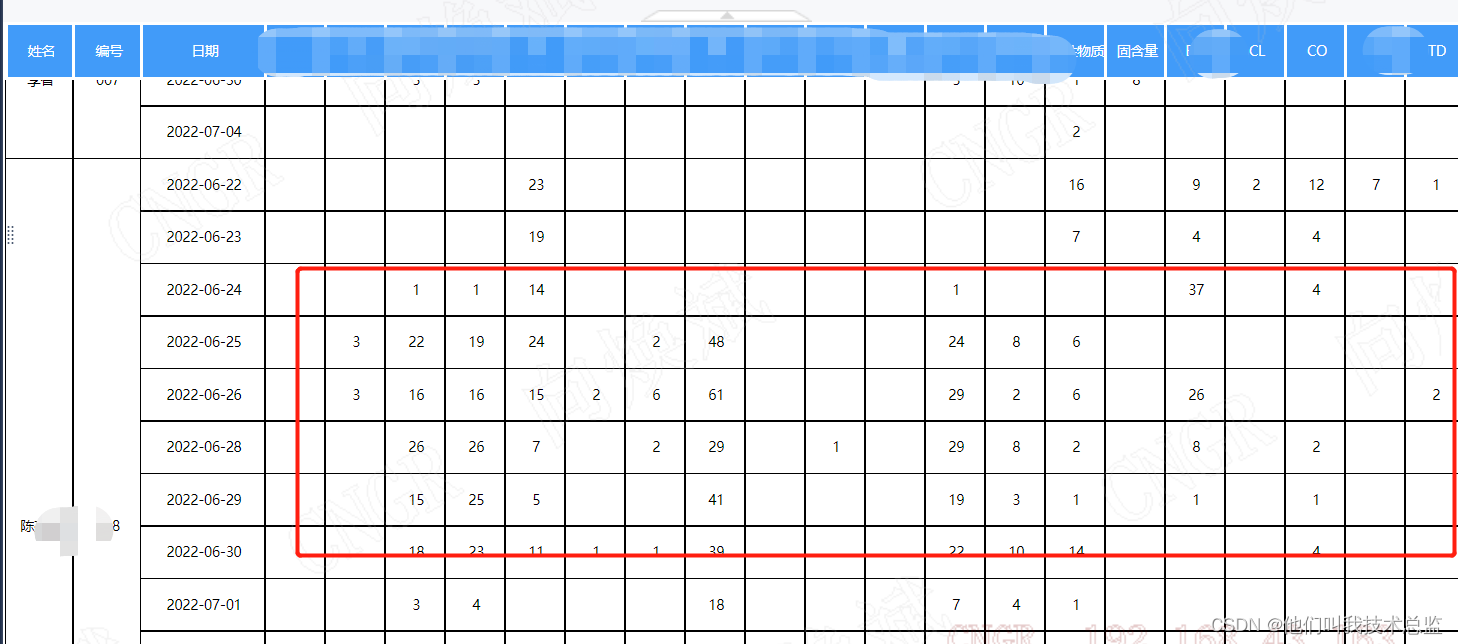
5、解析
最终拆分通过存储过程的游标循环拆分,将对应拆分明细保存到同一个表中再汇总分析,得出最后的工作量,因太晚了,就暂时不介绍详细的拆分逻辑了。如想获取最终的存储过程拆分逻辑,欢迎留言讨论~
边栏推荐
- POJ - 3784 running medium
- GFS distributed file system
- Thirteen forms of lambda in kotlin
- Using helm to install rainbow in various kubernetes
- MES系统,是企业生产的必要选择
- Opencv learning notes 1 -- several methods of reading images
- Arm GIC (IV) GIC V3 register class analysis notes.
- 数据中台落地实施之法
- 下载和安装orcale database11.2.0.4
- JEditableTable的使用技巧
猜你喜欢

Pvtv2--pyramid vision transformer V2 learning notes
Virtual address space
SSM integration
Installation and configuration of PLSQL
详解华为应用市场2022年逐步减少32位包体上架应用和策略
![[paper reading] icml2020: can autonomous vehicles identify, recover from, and adapt to distribution shifts?](/img/ff/81a7b2ec08a6a422a5cf578c1fed13.jpg)
[paper reading] icml2020: can autonomous vehicles identify, recover from, and adapt to distribution shifts?

归并排序和非比较排序
MySQL introduction - crud Foundation (establishment of the prototype of the idea of adding, deleting, changing and searching)
Merge sort and non comparison sort
Learn how to compile basic components of rainbow from the source code
随机推荐
IP-guard助力能源企业完善终端防泄密措施,保护机密资料安全
使用AGC重签名服务前后渠道号信息异常分析
[paper reading] icml2020: can autonomous vehicles identify, recover from, and adapt to distribution shifts?
21 general principles of wiring in circuit board design_ Provided by Chengdu circuit board design
Composer change domestic image
POJ - 3616 Milking Time(DP+LIS)
String operation
grpc、oauth2、openssl、双向认证、单向认证等专栏文章目录
Tips for using jeditabletable
数据分析方法论与前人经验总结2【笔记干货】
Redis summary
Implementation of navigation bar at the bottom of applet
[machine learning] watermelon book data set_ data sharing
如何在HarmonyOS应用中集成App Linking服务
mysql分区讲解及操作语句
A method for quickly viewing pod logs under frequent tests (grep awk xargs kuberctl)
Golang compilation constraint / conditional compilation (/ / +build < tags>)
对API接口或H5接口做签名认证
In go language, function is a type
IP guard helps energy enterprises improve terminal anti disclosure measures to protect the security of confidential information