当前位置:网站首页>Pvtv2--pyramid vision transformer V2 learning notes
Pvtv2--pyramid vision transformer V2 learning notes
2022-07-07 08:21:00 【Fried dough twist ground】
PVTV2–Pyramid Vision TransformerV2 Learning notes
PVTv2: Improved Baselines with Pyramid Vision Transformer
Abstract
Transformer Recently, encouraging progress has been made in computer vision . In this work , We improve the original pyramid visual converter by adding three designs (PVTv1), Proposed a new baseline , Include **(1) Linear complexity attention layer ,(2) Overlapping patch embedding and (3) Convolutional feedforward network **. Through these modifications ,PVTv2 take PVTv1 The computational complexity of is reduced to linear , And in basic visual tasks ( Such as classification 、 Detection and segmentation ) Has achieved significant improvements . It is worth noting that , The proposed PVTv2 Achieved with recent work ( Such as Swin transformer ) Equivalent or better performance . We hope this work will promote the most advanced transformer research in the field of computer vision . Code is located https://github.com/whai362/PVT.
1. Introduction
Recently, the research on vision converter is converging on the backbone network [8、31、33、34、23、36、10、5] On , The backbone network is used for downstream visual tasks , For example, image classification 、 Object detection 、 Instance and semantic segmentation . so far , Some promising results have been achieved . for example , Vision Converter (ViT)[8] First of all, it is proved that the pure converter can maintain the most advanced performance in image classification . Pyramid vision converter (PVTv1)[33] indicate , Pure converter backbone in intensive prediction tasks ( Such as detection and segmentation tasks )[22,41,?] Aspects can also exceed CNN. after ,Swin Transformer[23]、CoaT[36]、LeViT[10] and Twins[5] Further improved Transformer Classification of trunk 、 Detection and segmentation performance .
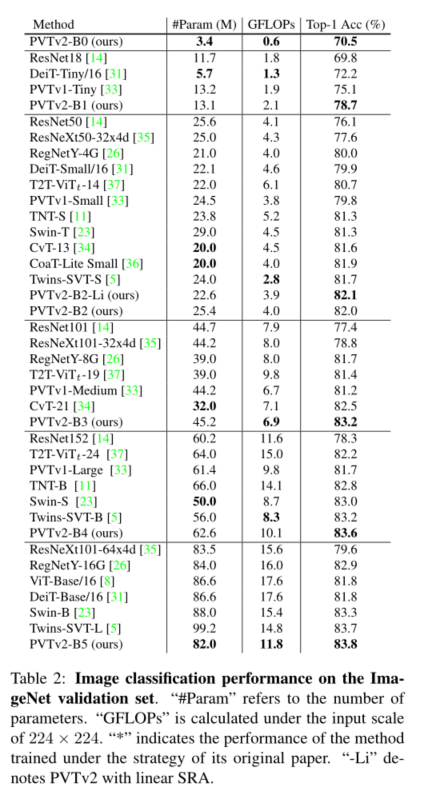
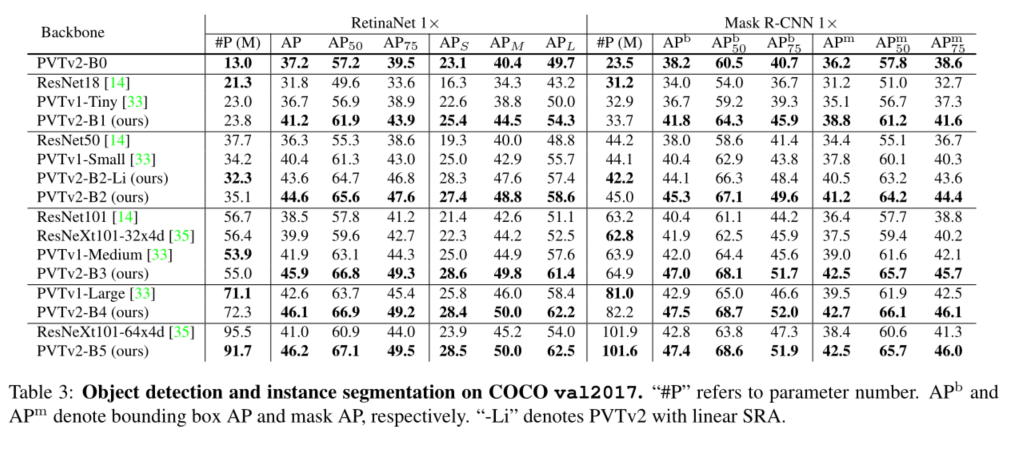
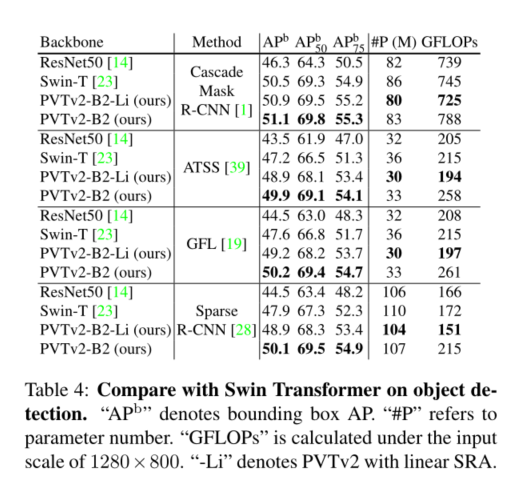
The purpose of this work is to PVTv1 Build stronger on the framework 、 A more viable baseline . We report three design improvements , namely **(1) Linear complexity attention layer 、(2) Overlapping patch embedding and (3) Convolution feedforward network and PVTv1 The frame is orthogonal **, When and PVTv1 When used together , They can bring better image classification 、 Object detection 、 Instance and semantic segmentation performance . The improved framework is called PVTv2. say concretely ,PVTv2-B51 stay ImageNet produce 83.8% Of top-1 error , be better than Swin-B[23] and Twins-SVT-L[5], Our model has fewer parameters and GFLOP. Besides , have PVT-B2 Of GFL[19] stay COCO val2017 It's recorded on the 50.2 AP, It's better than having Swin-T Of GFL[23] high 2.6 AP, It's better than having ResNet50 Of GFL[13] high 5.7 AP. We hope that these improved baselines will provide reference for the future research of visual converter .
2. Related Work
We mainly discuss the transformer backbone related to this work .ViT[8] Treat each image as a token sequence with a fixed length ( Patch ), Then feed it to multiple Transformer Layer to perform classification . This is the first time that , When the training data is enough ( for example ImageNet-22k[7],JFT300M), pure Transformer You can also archive the most advanced performance in image classification .DeiT[31] Further explore ViT Data efficient training strategies and distillation methods .
In order to improve the performance of image classification , The latest method is to ViT Customized changes made .T2T ViT[37] Connect the tokens in the overlapping sliding window step by step into a token .TNT[11] Using internal and external transform blocks to generate pixels and patches respectively .CPVT[6] Replace with conditional location code ViT Embedded in a fixed size position in , It makes it easier to process images of any resolution .CrossViT[2] Image blocks of different sizes are processed by double branch transformers .LocalViT[20] Combine the depth convolution into the visual converter , To improve local continuity of features .
Adapt to intensive forecasting tasks , Such as object data recognition , Instance and semantic segmentation , There are other ways [33、23、34、36、10、5] take CNN The pyramid structure in introduces the design of transformer backbone .PVTv1 It is the first pyramid converter , It proposes a hierarchical converter with four stages , It shows that the pure converter backbone can be like CNN As common as the trunk , And perform better in detection and segmentation tasks . then , Yes [23、34、36、10、5] Some improvements have been made , To enhance the local continuity of features , And eliminate fixed size position embedding . for example ,Swin Transformer[23] The fixed size position embedding is replaced by the relative position deviation , It also limits the self attention in the mobile window .CvT[34]、CoaT[36] and LeViT[10] The convolution operation is introduced into the visual converter .Twins[5] Combine local attention and global attention mechanisms , To get stronger features .
3. Methodology
3.1. Limitations in PVTv1
PVTv1[33] There are three main limitations :(1) And ViT[8] similar , When processing high-resolution input ( for example , The short side is 800 Pixels ) when ,PVTv1 The computational complexity of is relatively large .(2) PVTv1[33] Treat the image as a sequence of non overlapping patches , This loses the local continuity of the image to a certain extent ;(3) PVTv1 The location code in is fixed , It is not flexible for processing images of any size . These problems limit PVTv1 Performance on visual tasks .
To solve these problems , We proposed PVTv2, It passes through the 3.2、3.3 and 3.4 The three designs listed in section improve PVTv1.
3.2. Linear Spatial Reduction Attention
First , In order to reduce the high computing cost caused by attention operation , We propose linear spatial attention (SRA) The floor is as shown in the figure 1 Shown . And using convolution for space reduction SRA[33] Different , linear SRA Before attention manipulation Use the average pool to divide the space dimension ( namely h×w) Reduce to a fixed size ( namely P×P). therefore , linear SRA Like convolution layer, it has linear computing and memory cost . say concretely , Given size is h×w×c The input of ,SRA And linear SRA The complexity of is :
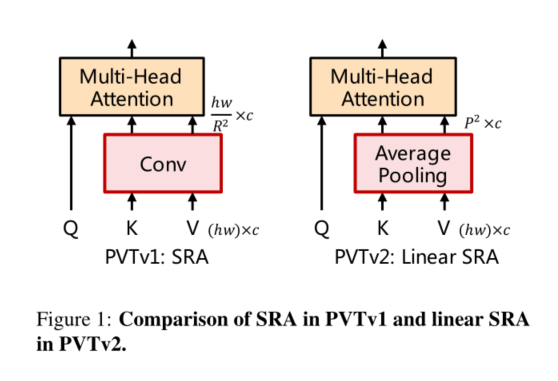
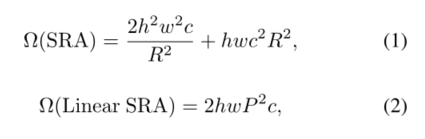
among R yes SRA Space reduction rate [33].P It's linear SRA Pool size , Set to 7.
3.3. Overlapping Patch Embedding
secondly , To model local continuity information , We use overlapping patch embedding to mark images . Pictured 2(a) Shown ,** We enlarged the patch window , Overlap the adjacent windows by half , And fill the feature map with zero to maintain the resolution . In this work , We use zero fill convolution to realize overlapping patch embedding .** say concretely , Given a size of h×w×c The input of , We enter it into S Convolution of steps , The nuclear size is 2S− 1.S− 1 Fill size and c ′ c^{'} c′ The number of nuclear . The output size is h / S × w / S × C ′ h/S×w/S×C^{'} h/S×w/S×C′.
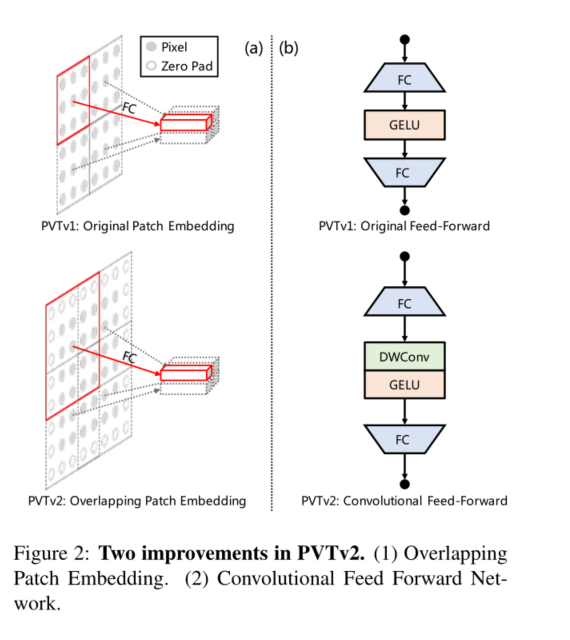
3.4. Convolutional Feed-Forward
** Third , suffer [17,6,20] Inspired by the , We removed the fixed size location code [8], And zero fill position coding is introduced into PVT in .** Pictured 2(b) Shown , Our first complete connection in the feedforward network (FC) Layer and the GELU[15] Added between 3×3 Deep convolution [16], The fill size is 1.
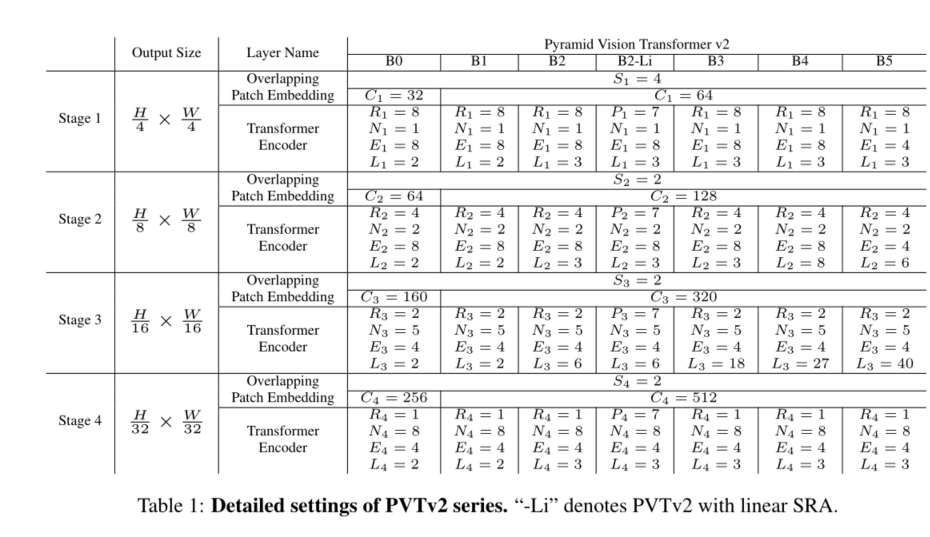
3.5. Details of PVTv2 Series
By changing the super parameter, we will PVTv2 from B0 Extended to B5. As follows :
S i S_i Si: The first stage overlapped patch embedding step
C i C_i Ci: The number of channels output in the first stage
L i L_i Li: Number of encoder layers in the first stage
R i R_i Ri: The first stage SRA The deceleration ratio of
P i P_i Pi: Stage i Medium linearity SRA Adaptive average pool size
N i N_i Ni: The number of heads of effective self-attention in the first stage
E i E_i Ei: The first stage feedforward layer [32] Expansion ratio ;
tab .1 Shows PVTv2 Details of the series . Our design follows ResNet[14] Principles .(1) As the layer deepens , Channel dimension increases , And the spatial resolution shrinks .(2) The first 3 Phases are allocated to most of the calculated costs .
3.6. Advantages of PVTv2
Combined with these improvements ,PVTv2 Sure **(1) Get more local continuity of images and feature maps ;(2) More flexible handling of variable resolution inputs ;(3) Enjoy and CNN Same linear complexity .**
4. Experiment

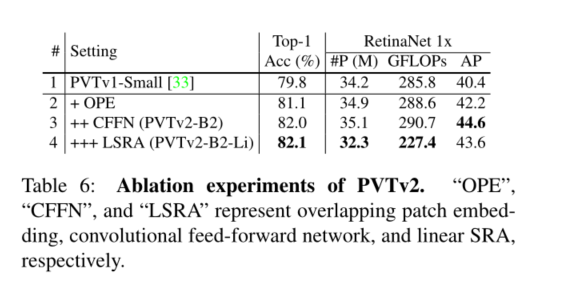
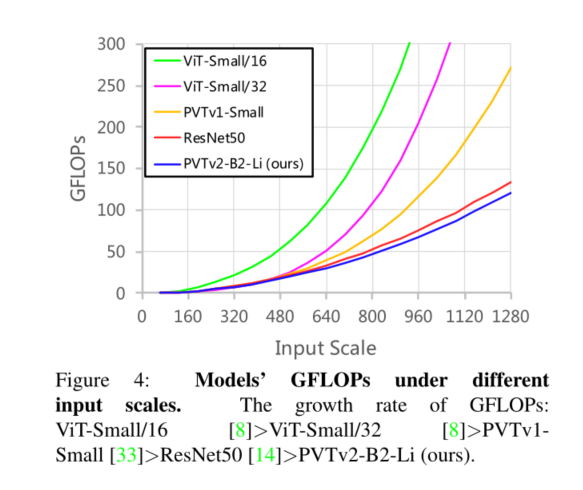
5. Conclusion
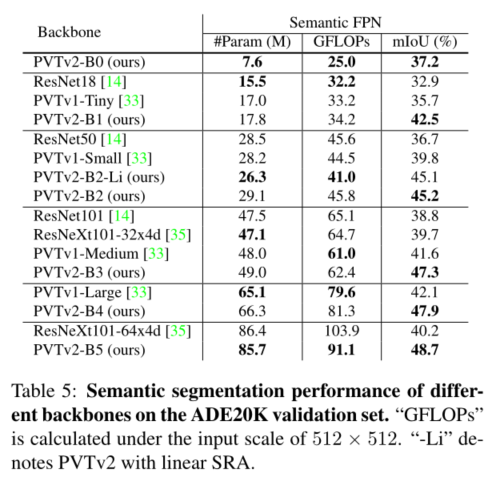
We study the pyramid vision converter (PVTv1) The limitations of , And it is improved through three designs , That is, overlapping patches are embedded 、 Convolution feedforward network and linear space reduction attention layer . In image classification 、 A large number of experiments on different tasks such as target detection and semantic segmentation show , Under the same number of parameters , The proposed PVTv2 Than its predecessor PVT And other most advanced converter based backbones are stronger . We hope that these improved baselines will provide reference for the future research of visual converter .
边栏推荐
- opencv学习笔记四——膨胀/腐蚀/开运算/闭运算
- 藏书馆App基于Rainbond实现云原生DevOps的实践
- JS copy picture to clipboard read clipboard
- Excel import function of jeesite form page
- Analysis of maker education in innovative education system
- 柯基数据通过Rainbond完成云原生改造,实现离线持续交付客户
- 快解析内网穿透为文档加密行业保驾护航
- Function extension, attribute extension and non empty type extension in kotlin
- 复杂网络建模(二)
- Splunk子查询模糊匹配csv中字段值为*
猜你喜欢

解析机器人科技发展观对社会研究论
OpenVSCode云端IDE加入Rainbond一体化开发体系
![[quick start of Digital IC Verification] 13. SystemVerilog interface and program learning](/img/d8/ffc1b7527f0269cecb2946ab402a2e.png)
[quick start of Digital IC Verification] 13. SystemVerilog interface and program learning
jeeSite 表单页面的Excel 导入功能
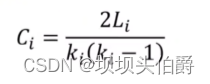
Complex network modeling (I)

Unityhub cracking & unity cracking
单场带货涨粉10万,农村主播竟将男装卖爆单?
【无标题】
Analyzing the influence of robot science and technology development concept on Social Research
数据库实时同步利器——CDC(变化数据捕获技术)
随机推荐
Pytoch (VI) -- model tuning tricks
Four items that should be included in the management system of integral mall
Application of slip ring of shipborne radar antenna
opencv学习笔记三——图像平滑/去噪处理
Using helm to install rainbow in various kubernetes
Empire CMS collection Empire template program general
Full text query classification
Unityhub cracking & unity cracking
Explore creativity in steam art design
[quick start of Digital IC Verification] 13. SystemVerilog interface and program learning
Standard function let and generic extension function in kotlin
What is the function of paralleling a capacitor on the feedback resistance of the operational amplifier circuit
BiSeNet的特點
Give full play to the wide practicality of maker education space
一文了解如何源码编译Rainbond基础组件
漏洞复现-easy_tornado
Basic use of CTF web shrink template injection nmap
Leetcode medium question my schedule I
GFS分布式文件系统
Bayes' law