当前位置:网站首页>Hash / (understanding, implementation and application)
Hash / (understanding, implementation and application)
2022-07-07 11:07:00 【Exy-】
Catalog
Hash concept
Common hash functions
direct addressing
Take a linear function of keyword as hash address :Hash(Key)= A*Key + Badvantage : Simple 、 uniformshortcoming : It needs to be done in advance Know the distribution of keywordsUse scenarios : It is suitable for finding relatively small and continuous cases
Division and remainder
Set the number of addresses allowed in the hash table to m, Take one not greater than m, But closest to or equal to m The prime number of p As divisor , According to the hash function Count :Hash(key) = key% p(p<=m), Convert key to hash address
So how to solve hash conflicts ?
Closed hash and open hash
Closed hash
It's also called open addressing , When a hash conflict occurs , If the hash table is not full , It means that there must be a space in the hash table , that You can put key Stored in a conflict location “ next ” Go to an empty place .
So how to find this location ?
- Linear detection
- Second detection
Linear detection : The positions mapped by hash have conflicts , Then you need to find an empty space to store data in the future
Hash(key)=key%len + i(i=0,1,2,3...)Second detection : The positions mapped by hash have conflicts , Then we need to find a space to store data in the later power
Hash(key)=key%len + i^2(i=0,1,2,3...)Closed hash implementation
namespace CLOSE_HASH
{
enum State{EMPTY,EXITS,DELETE};
template<class K,class V>
struct HashDate
{
pair<K,V> _kv;
State _state=EMPTY;
};
// specialized
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
template<>
struct Hash<string>
{
// "int" "insert"
// The string is converted to a corresponding integer value , Because of shaping, we can get the modular mapping position
// expect -> String is different , The shaping value transferred out shall be as different as possible
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
template<class K,class V,class KHashFunc=Hash<string>>
class HashTable
{
public:
bool Insert(const pair<K, V>& kv)
{
HashDate<K, V>* ret = find(kv.first);
if (_table.size() == 0)
{
_table.resize(10);
}
else if(_size*10 / _table.size() > 7)
{
HashTable<K, V, KHashFunc> newHT;
newHT._table.resize(_table.size() * 2);
for (auto& e : _table)
{
newHT.Insert(e._kv);
}
_table.swap(newHT._table);
}
KHashFunc hf;
size_t start = hf(kv.first) % _table.size();
size_t index = start;
size_t i = 1;
while (_table[index]._state == EXITS)
{
index = start + i;
index %= _table.size();
++i;
//index += i ^ 2;
}
_table[index]._kv = kv;
_table[index]._state = EXITS;
++_size;
return true;
}
HashDate<K,V>* find(const K& key)
{
KHashFunc hf;
if (_table.size() == 0)
{
return nullptr;
}
size_t i = 1;
size_t start = hf(key) % _table.size();
size_t index = start;
while (_table[index]._state != EMPTY)
{
if (_table[index]._kv.first==key&&_table[index]._state==EXITS)
{
return &_table[index];
}
index = start + i;
index %= _table.size();
++i;
}
return nullptr;
}
bool Erase(const K& key)
{
HashDate<K, V>* ret = find(key);
if (ret == nullptr)
{
return false;
}
else
{
ret->_state = DELETE;
return true;
}
}
private:
vector<HashDate<K,V>> _table;
size_t _size=0;// Number of valid data stored
};
}Hash
Hash method is also called chain address method ( Open chain method ), First, we use hash function to calculate hash address for key set , Keys with the same address Belong to the same subset , Each subset is called a bucket , The elements in each bucket are linked by a single chain table , The head knot of each linked list Points are stored in a hash table , It's also called the Hashi bucket
namespace OpenHash
{
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
// specialized
template<>
struct Hash < string >
{
// "int" "insert"
// The string is converted to a corresponding integer value , Because of shaping, we can get the modular mapping position
// expect -> String is different , The shaping value transferred out shall be as different as possible
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
template<class T>
struct HashNode
{
HashNode<T>* _next;
T _data;
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
};
// Forward declaration
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;
// iterator
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
struct __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, KeyOfT, HashFunc> Self;
typedef HashTable<K, T, KeyOfT, HashFunc> HT;
Node* _node;
HT* _pht;
__HTIterator(Node* node, HT* pht)
:_node(node)
, _pht(pht)
{}
Self& operator++()
{
// 1、 There is still data in the current bucket , Then go back in the current bucket
if (_node->_next)
{
_node = _node->_next;
}
// 2、 The current bucket is finished , Need to go to the next bucket .
else
{
//size_t index = HashFunc()(KeyOfT()(_node->_data)) % _pht->_table.size();
KeyOfT kot;
HashFunc hf;
size_t index = hf(kot(_node->_data)) % _pht->_table.size();
++index;
while (index < _pht->_table.size())
{
if (_pht->_table[index])
{
_node = _pht->_table[index];
return *this;
}
else
{
++index;
}
}
_node = nullptr;
}
return *this;
}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator != (const Self& s) const
{
return _node != s._node;
}
bool operator == (const Self& s) const
{
return _node == s.node;
}
};
template<class K, class T, class KeyOfT, class HashFunc = Hash<K>>
class HashTable
{
typedef HashNode<T> Node;
template<class K, class T, class KeyOfT, class HashFunc>
friend struct __HTIterator;
public:
typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;
HashTable() = default; // Displays the default construction for the specified build
HashTable(const HashTable& ht)
{
_n = ht._n;
_table.resize(ht._table.size());
for (size_t i = 0; i < ht._table.size(); i++)
{
Node* cur = ht._table[i];
while (cur)
{
Node* copy = new Node(cur->_data);
// Insert the head into the new table
copy->_next = _table[i];
_table[i] = copy;
cur = cur->_next;
}
}
}
HashTable& operator=(HashTable ht)
{
_table.swap(ht._table);
swap(_n, ht._n);
return *this;
}
~HashTable()
{
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
iterator begin()
{
size_t i = 0;
while (i < _table.size())
{
if (_table[i])
{
return iterator(_table[i], this);
}
++i;
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < PRIMECOUNT; ++i)
{
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
pair<iterator, bool> Insert(const T& data)
{
KeyOfT kot;
// eureka
auto ret = Find(kot(data));
if (ret != end())
return make_pair(ret, false);
HashFunc hf;
// Load factor to 1 when , Increase capacity
if (_n == _table.size())
{
vector<Node*> newtable;
//size_t newSize = _table.size() == 0 ? 8 : _table.size() * 2;
//newtable.resize(newSize, nullptr);
newtable.resize(GetNextPrime(_table.size()));
// Traverse and get the nodes in the old table , Recalculate the position mapped to the new table , Hang in a new table
for (size_t i = 0; i < _table.size(); ++i)
{
if (_table[i])
{
Node* cur = _table[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hf(kot(cur->_data)) % newtable.size();
// Head insertion
cur->_next = newtable[index];
newtable[index] = cur;
cur = next;
}
_table[i] = nullptr;
}
}
_table.swap(newtable);
}
size_t index = hf(kot(data)) % _table.size();
Node* newnode = new Node(data);
// Head insertion
newnode->_next = _table[index];
_table[index] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}
iterator Find(const K& key)
{
if (_table.size() == 0)
{
return end();
}
KeyOfT kot;
HashFunc hf;
size_t index = hf(key) % _table.size();
Node* cur = _table[index];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
else
{
cur = cur->_next;
}
}
return end();
}
bool Erase(const K& key)
{
size_t index = hf(key) % _table.size();
Node* prev = nullptr;
Node* cur = _table[index];
while (cur)
{
if (kot(cur->_data) == key)
{
if (_table[index] == cur)
{
_table[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
--_n;
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _table;
size_t _n = 0; // Number of valid data
};
}
encapsulation unordered_map
namespace ljx
{
template<class K, class V>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename OpenHash::HashTable<K, pair<K, V>, MapKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
private:
OpenHash::HashTable<K, pair<K, V>, MapKeyOfT> _ht;
};
}encapsulation unordered_set
namespace ljx
{
template<class K>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& k)
{
return k;
}
};
public:
typedef typename OpenHash::HashTable<K, K, SetKeyOfT >::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const K k)
{
return _ht.Insert(k);
}
private:
OpenHash::HashTable<K, K, SetKeyOfT> _ht;
};
}
The application of hash
Bitmap
namespace Y
{
template<size_t N>
class BitSet
{
public:
BitSet()
{
_bits.resize(N / 32 + 1, 0);
}
// hold x The mapped bits are marked as 1
void Set(size_t x)
{
assert(x < N);
// Work out x The mapped bit is at i It's an integer
// Work out x The mapped bit is in the... Of this integer j bits
size_t i = x / 32;
size_t j = x % 32;
// _bits[i] Of the j The bit is marked as 1, And it doesn't affect his other positions
_bits[i] |= (1 << j);
}
void Reset(size_t x)
{
assert(x < N);
size_t i = x / 32;
size_t j = x % 32;
// _bits[i] Of the j The bit is marked as 0, And it doesn't affect his other positions
_bits[i] &= (~(1 << j));
}
bool Test(size_t x)
{
assert(x < N);
size_t i = x / 32;
size_t j = x % 32;
// If the first j Is it 1, The result is right and wrong 0, Not 0 It's true
// If the first j be for the purpose of 0, The result is 0,0 It's fake
return _bits[i] & (1 << j);
}
private:
vector<int> _bits;
};
}Apply to finding intersection , Quickly find out whether a number is in a set .
advantage : Save a space , Fast shortcoming : Can only handle shaping
The bloon filter
The bloom filter is made of bloom (Burton Howard Bloom) stay 1970 Put forward in A compact 、 More ingenious Probabilistic data structure structure , Characteristic is Insert and query efficiently , It can be used to tell you “ Something must not exist or may exist ”, It uses multiple hash functions Count , Map a data into a bitmap structure . This method can not only improve the query efficiency , It can also save a lot of memory space
The idea of Bloom filter is to map an element into a bitmap with multiple hash functions , Therefore, the bit of the mapped position must be 1. So you can find it in the following way : Calculate whether the stored bit position corresponding to each hash value is zero , As long as one is zero , Indicates that the element must not be in the hash table , Otherwise, it may be in the hash table .
Judgment is not accurate , There is a miscalculation , Judgment is not there , accuracy ; For more strings
Generally, deletion is not supported
There is a way to delete , Use multiple bits as counters , When mapping multiple values ,++ Count , deleted ,-- Count ;
struct HashBKDR
{
// "int" "insert"
// The string is converted to a corresponding integer value , Because of shaping, we can get the modular mapping position
// expect -> String is different , The shaping value transferred out shall be as different as possible
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const std::string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
struct HashAP
{
// "int" "insert"
// The string is converted to a corresponding integer value , Because of shaping, we can get the modular mapping position
// expect -> String is different , The shaping value transferred out shall be as different as possible
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const std::string& s)
{
// AP Hash
register size_t hash = 0;
size_t ch;
for (long i = 0; i < s.size(); i++)
{
ch = s[i];
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
}
};
struct HashDJB
{
// "int" "insert"
// The string is converted to a corresponding integer value , Because of shaping, we can get the modular mapping position
// expect -> String is different , The shaping value transferred out shall be as different as possible
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const std::string& s)
{
// BKDR Hash
register size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N, class K = std::string,
class Hash1 = HashBKDR,
class Hash2 = HashAP,
class Hash3 = HashDJB>
class BloomFilter
{
public:
void Set(const K& key)
{
//Hash1 hf1;
//size_t i1 = hf1(key);
size_t i1 = Hash1()(key) % N;
size_t i2 = Hash2()(key) % N;
size_t i3 = Hash3()(key) % N;
cout << i1 << " " << i2 << " " << i3 << endl;
_bitset.Set(i1);
_bitset.Set(i2);
_bitset.Set(i3);
}
bool Test(const K& key)
{
size_t i1 = Hash1()(key) % N;
if (_bitset.Test(i1) == false)
{
return false;
}
size_t i2 = Hash2()(key) % N;
if (_bitset.Test(i2) == false)
{
return false;
}
size_t i3 = Hash3()(key) % N;
if (_bitset.Test(i3) == false)
{
return false;
}
// here 3 Everyone is , It could be something else key Account for the , It is not accurate in , There is a miscalculation
// No, it's accurate
return true;
}
private:
bit::BitSet<N> _bitset;
bit::vector<char> _bitset;
};
void TestBloomFilter()
{
/*BloomFilter<100> bf;
bf.Set(" Zhang San ");
bf.Set(" Li Si ");
bf.Set(" But the king bull ");
bf.Set(" Red boy ");
cout << bf.Test(" Zhang San ") << endl;
cout << bf.Test(" Li Si ") << endl;
cout << bf.Test(" But the king bull ") << endl;
cout << bf.Test(" Red boy ") << endl;
cout << bf.Test(" The Monkey King ") << endl;*/
BloomFilter<600> bf;
size_t N = 100;
std::vector<std::string> v1;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += std::to_string(1234 + i);
v1.push_back(url);
}
for (auto& str : v1)
{
bf.Set(str);
}
for (auto& str : v1)
{
cout << bf.Test(str) << endl;
}
cout << endl << endl;
std::vector<std::string> v2;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";
url += std::to_string(6789 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (auto& str : v2)
{
if (bf.Test(str))
{
++n2;
}
}
cout << " Similar string misjudgment rate :" << (double)n2 / (double)N << endl;
std::vector<std::string> v3;
for (size_t i = 0; i < N; ++i)
{
std::string url = "https://zhuanlan.zhihu.com/p/43263751";
url += std::to_string(6789 + i);
v3.push_back(url);
}
size_t n3 = 0;
for (auto& str : v3)
{
if (bf.Test(str))
{
++n3;
}
}
cout << " Misjudgment rate of dissimilar strings :" << (double)n3 / (double)N << endl;
}Hash cut
Hash cutting is an idea of hash cutting , By cutting into uneven parts , Convenient operation
Put the same elements into the same subscript file through segmentation , And then compare
such as Give one more than 100G The size of log fifile, log There is IP Address , Design algorithm to find the most frequent IP Address ?
Method :
- Suppose to generate A0~A99 100 Small file , Read... In turn ip, Calculate each ip Mapped file number ,i=HashBKDR()(ip)%100 This ip Just go in Ai Small file No , same ip It must have entered a small file , So we can directly count the times in the small file
- To deal with A0~A99, Read Ai file , If the file is larger than 2G, You can slice it again , If it is less than 2G, Then use a map<string,int> Count the times
边栏推荐
- Cmake learning manual
- 单调性约束与反单调性约束的区别 monotonicity and anti-monotonicity constraint
- Arduino board description
- Mysql的json格式查询
- July 10, 2022 "five heart public welfare" activity notice + registration entry (two-dimensional code)
- Kitex 重试机制
- Deeply understand the characteristics of database transaction isolation
- Ffmpeg record a video command from RTSP
- Simple and easy to modify spring frame components
- Deconstruction and assignment of variables
猜你喜欢

【机器学习 03】拉格朗日乘子法
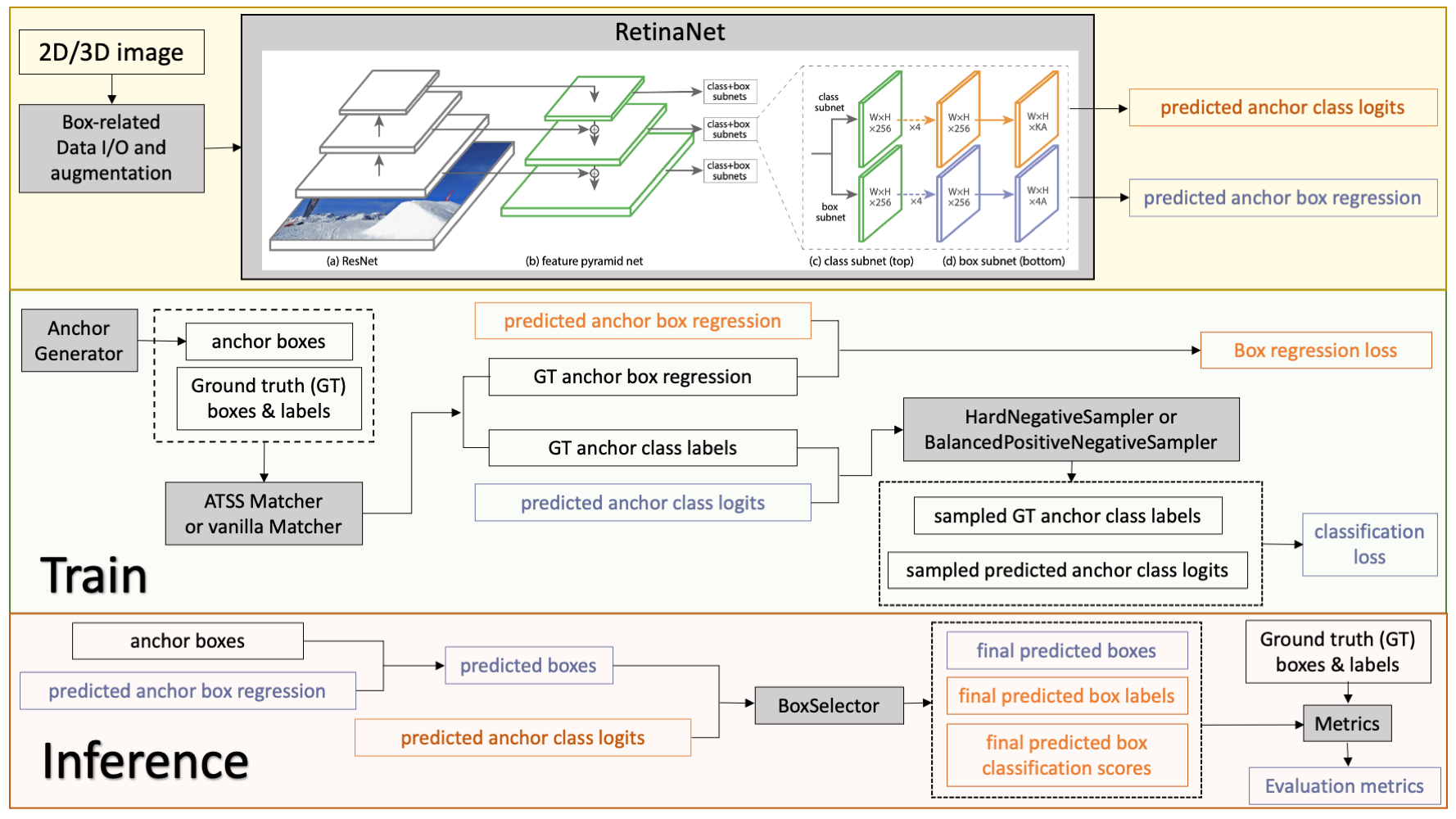
Monai version has been updated to 0.9. See what new functions it has
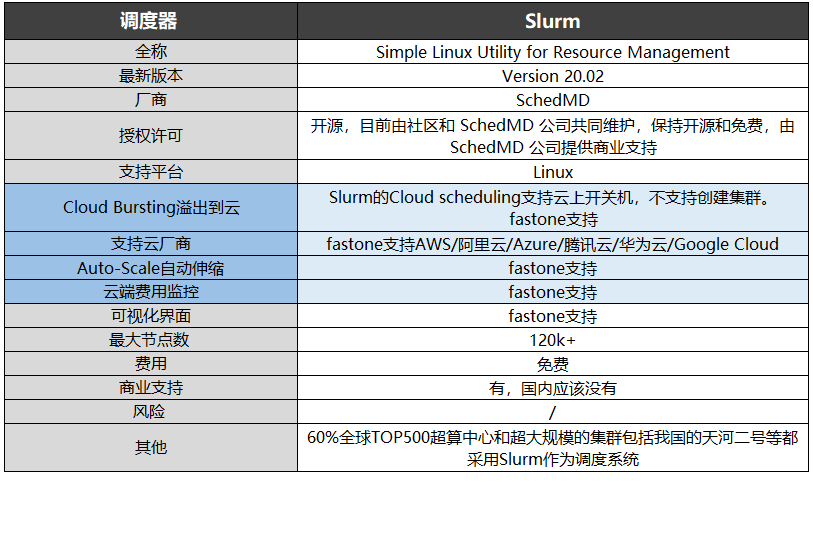
Cluster task scheduling system lsf/sge/slurm/pbs based on HPC scenario

2022年7月10日“五心公益”活动通知+报名入口(二维码)
Seata 1.3.0 four modes to solve distributed transactions (at, TCC, Saga, XA)
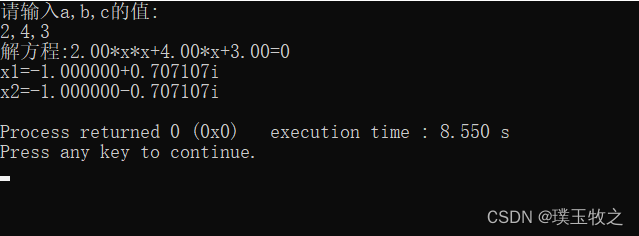
Find the root of equation ax^2+bx+c=0 (C language)
![[pro test feasible] error while loading shared libraries solution](/img/e2/688ffa07861f38941cbf2cafdd9939.png)
[pro test feasible] error while loading shared libraries solution
SQL Server 知识汇集9 : 修改数据
【STM32】实战3.1—用STM32与TB6600驱动器驱动42步进电机(一)
Find the greatest common divisor and the least common multiple (C language)
随机推荐
[untitled]
China Southern Airlines pa3.1
如何顺利通过下半年的高级系统架构设计师?
Go-Redis 中间件
Kitex retry mechanism
2022.7.5DAY597
中级网络工程师是什么?主要是考什么,有什么用?
[untitled]
深入理解Apache Hudi异步索引机制
A simple example of delegate usage
2022.7.6DAY598
SQL Server knowledge gathering 9: modifying data
Qtcreator sets multiple qmake
SQL Server knowledge collection 11: Constraints
[pro test feasible] error while loading shared libraries solution
Différences entre les contraintes monotones et anti - monotones
[untitled]
【推薦系統 01】Rechub
Deep understanding of Apache Hudi asynchronous indexing mechanism
2021 summary and 2022 outlook