当前位置:网站首页>Encodermappreduce notes
Encodermappreduce notes
2022-07-06 11:44:00 【@Little snail】
Catalog
- 1、MapReduce Definition
- 2、MapReduce Statistics in two text files , The number of times each word appears
- hadoop Of MapReduce And hdfs Be sure to start it first start-dfs.sh
- 3、 use MapReduce Calculate the best grades of each student in the class
- 4、 MapReduce The contents of the document are merged and duplicated
1、MapReduce Definition
Cut the data into three pieces , Then calculate and process these data separately (Map),
After processing, it is sent to a machine for merging (merge),
Then calculate the merged data , inductive (reduce) And the output .
Java Contained in the 3 A function :
map Split the dataset
reduce Processing data
job Object to run MapReduce Homework ,
2、MapReduce Statistics in two text files , The number of times each word appears
First, we create two files in the current directory :
establish file01 Input content :
Hello World Bye World
establish file02 Input content :
Hello Hadoop Goodbye Hadoop
Upload files to HDFS Of /usr/input/ Under the table of contents :
Don't forget to start DFS:
start-dfs.sh
public class WordCount {
//Mapper class
/* Because the file has the number of lines by default ,LongWritable Is used to accept the number of lines in the file , first Text It is used to accept the contents of the file , the second Text Is used to output to Reduce Class key, IntWritable Is used to output to Reduce Class value*/
public static class TokenizerMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// Creating configuration objects
Configuration conf = new Configuration();
// establish job object
Job job = new Job(conf, "word count");
// Set up run job Class
job.setJarByClass(WordCount.class);
// Set up Mapper Class
job.setMapperClass(TokenizerMapper.class);
// Set up Reduce Class
job.setReducerClass(IntSumReducer.class);
// Set output key value Format
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Set the input path
String inputfile = "/usr/input";
// Set output path
String outputFile = "/usr/output";
// Perform input
FileInputFormat.addInputPath(job, new Path(inputfile));
// Execution output
FileOutputFormat.setOutputPath(job, new Path(outputFile));
// Whether it runs successfully or not ,true Output 0,false Output 1
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
hadoop Of MapReduce And hdfs Be sure to start it first start-dfs.sh
3、 use MapReduce Calculate the best grades of each student in the class
import java.io.IOException;
import java.util.StringTokenizer;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
/********** Begin **********/
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private int maxValue = 0;
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(),"\n");
while (itr.hasMoreTokens()) {
String[] str = itr.nextToken().split(" ");
String name = str[0];
one.set(Integer.parseInt(str[1]));
word.set(name);
context.write(word,one);
}
//context.write(word,one);
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
**int maxAge = 0;
int age = 0;
for (IntWritable intWritable : values) {
maxAge = Math.max(maxAge, intWritable.get());
}
result.set(maxAge);**
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
String inputfile = "/user/test/input";
String outputFile = "/user/test/output/";
FileInputFormat.addInputPath(job, new Path(inputfile));
FileOutputFormat.setOutputPath(job, new Path(outputFile));
job.waitForCompletion(true);
/********** End **********/
}
}
4、 MapReduce The contents of the document are merged and duplicated
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Merge {
/** * @param args * Yes A,B Merge two files , And get rid of the repetition , Get a new output file C */
// Reload here map function , Directly input the value Copy to output data key On Pay attention to map Method to throw an exception :throws IOException,InterruptedException
/********** Begin **********/
public static class Map extends Mapper<LongWritable, Text, Text, Text >
{
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
String str = value.toString();
String[] data = str.split(" ");
Text t1= new Text(data[0]);
Text t2 = new Text(data[1]);
context.write(t1,t2);
}
}
/********** End **********/
// Reload here reduce function , Directly input the key Copy to output data key On Pay attention to reduce Throw an exception on the method :throws IOException,InterruptedException
/********** Begin **********/
public static class Reduce extends Reducer<Text, Text, Text, Text>
{
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
List<String> list = new ArrayList<>();
for (Text text : values) {
String str = text.toString();
if(!list.contains(str)){
list.add(str);
}
}
Collections.sort(list);
for (String text : list) {
context.write(key, new Text(text));
}
}
/********** End **********/
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = new Job(conf, "word count");
job.setJarByClass(Merge.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String inputPath = "/user/tmp/input/"; // Set the input path here
String outputPath = "/user/tmp/output/"; // Set the output path here
FileInputFormat.addInputPath(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
边栏推荐
- 01 project demand analysis (ordering system)
- [yarn] CDP cluster yarn configuration capacity scheduler batch allocation
- [蓝桥杯2020初赛] 平面切分
- Codeforces Round #753 (Div. 3)
- 人脸识别 face_recognition
- Solve the problem of installing failed building wheel for pilot
- Learn winpwn (3) -- sEH from scratch
- Codeforces Round #771 (Div. 2)
- express框架详解
- [Flink] Flink learning
猜你喜欢
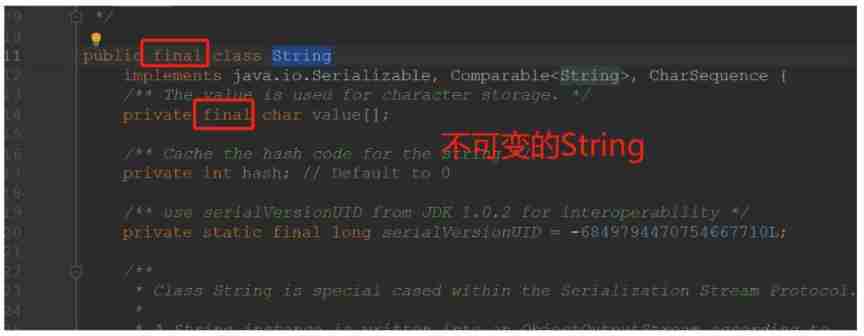
About string immutability
vs2019 桌面程序快速入门

Connexion sans mot de passe du noeud distribué
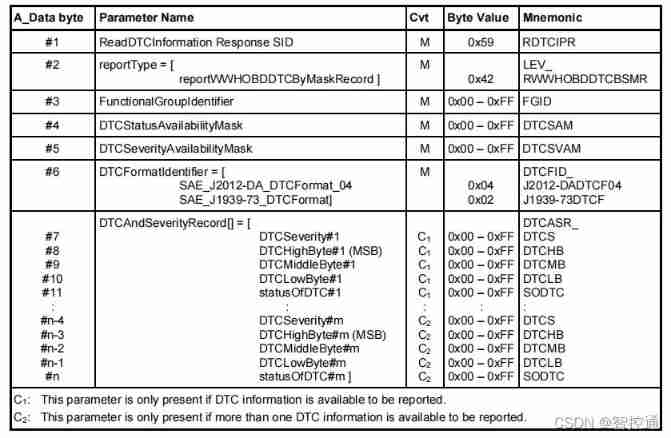
UDS learning notes on fault codes (0x19 and 0x14 services)
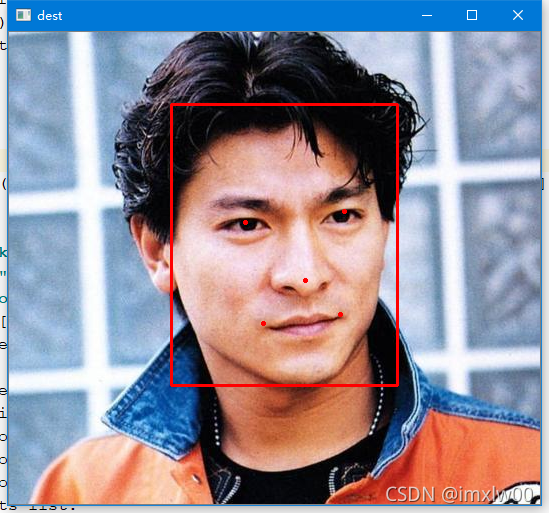
Mtcnn face detection
Wangeditor rich text reference and table usage

Come and walk into the JVM
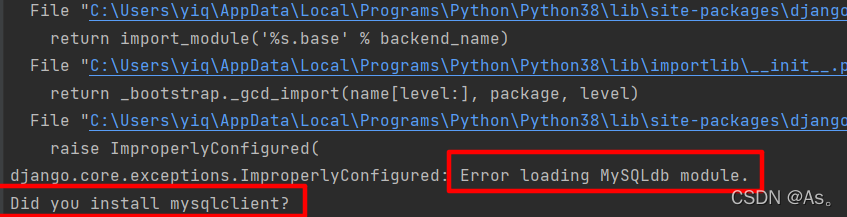
Django running error: error loading mysqldb module solution

Solve the problem of installing failed building wheel for pilot
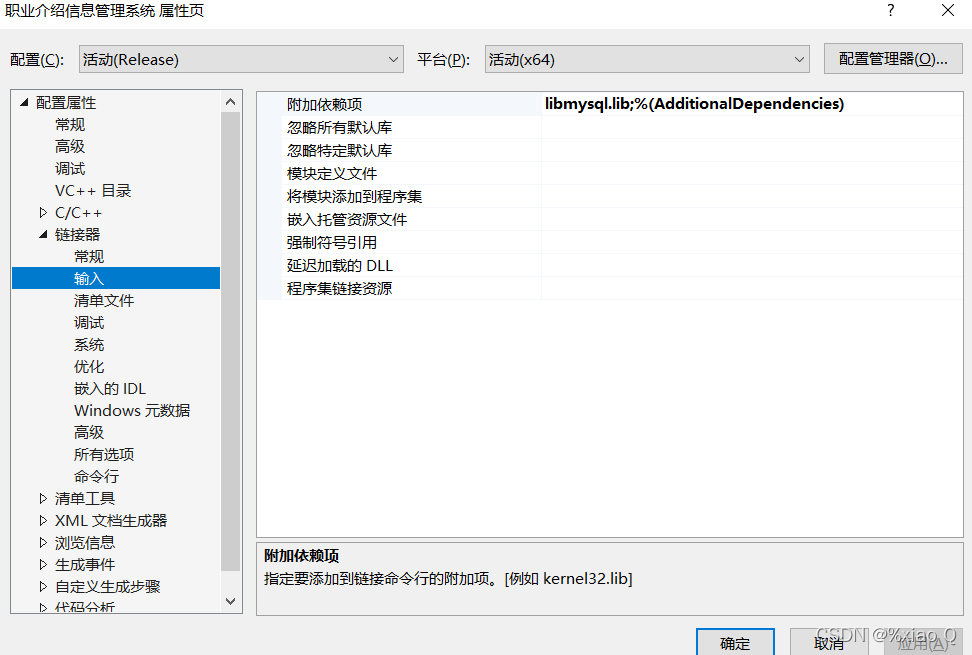
MySQL与c语言连接(vs2019版)
随机推荐
ES6 promise object
Nanny level problem setting tutorial
error C4996: ‘strcpy‘: This function or variable may be unsafe. Consider using strcpy_s instead
Codeforces Round #753 (Div. 3)
2019 Tencent summer intern formal written examination
Valentine's Day flirting with girls to force a small way, one can learn
How to set up voice recognition on the computer with shortcut keys
AcWing 179. Factorial decomposition problem solution
AcWing 1294.樱花 题解
02 staff information management after the actual project
Solution of deleting path variable by mistake
天梯赛练习集题解LV1(all)
机器学习笔记-Week02-卷积神经网络
牛客Novice月赛40
[Flink] Flink learning
常用正则表达式整理
QT creator test
Codeforces Round #753 (Div. 3)
Why can't STM32 download the program
TypeScript