当前位置:网站首页>抽絲剝繭C語言(高階)數據的儲存+練習
抽絲剝繭C語言(高階)數據的儲存+練習
2022-07-07 07:19:00 【ℳℓ白ℳℓ夜ℳℓ】
深度剖析數據在內存中的存儲
導語
數據類型的變量是如何儲存到內存中的?正反補碼又是什麼?
本章會詳細講解數據的儲存。
本章用32比特平臺
1. 數據類型介紹
前面我們已經學習了基本的內置類型:
char //字符數據類型
short //短整型
int //整形
long //長整型
long long //更長的整形
float //單精度浮點數
double //雙精度浮點數
//C語言有沒有字符串類型?
以及他們所占存儲空間的大小。
類型的意義:
- 使用這個類型開辟內存空間的大小(大小决定了使用範圍)。
- 如何看待內存空間的視角。
1.1 類型的基本歸類
整形家族:
char //因為char類型儲存的是ASCII碼值,所以也屬於整形家族
unsigned char
signed char
short
unsigned short [int]
signed short [int]
int
unsigned int
signed int
long
unsigned long [int]
signed long [int]
浮點數家族:
float
double
構造類型:
數組類型
結構體類型 struct
枚舉類型 enum
聯合類型 union
指針類型:
int*pi;
char* pc;
float* pf;
void* pv;
空類型:
void 錶示空類型(無類型)
通常應用於函數的返回類型、函數的參數、指針類型.
2. 整形在內存中的存儲
我們之前講過一個變量的創建是要在內存中開辟空間的。空間的大小是根據不同的類型而决定的。
數據在所開辟內存中到底是如何存儲的?
比如:
int a = 20;
int b = -10;
我們知道為 a 分配四個字節的空間。
那如何存儲?
下來了解下面的概念:
2.1 原碼、反碼、補碼
計算機中的整數有三種2進制錶示方法,即原碼、反碼和補碼。
三種錶示方法均有符號比特和數值比特兩部分,符號比特都是用0錶示“正”,用1錶示“負”,而數值比特。
正數的原、反、補碼都相同。
負整數的三種錶示方法各不相同。
原碼
直接將數值按照正負數的形式翻譯成二進制就可以得到原碼。
反碼
將原碼的符號比特不變,其他比特依次按比特取反就可以得到反碼。
補碼//內存中儲存的值
反碼+1就得到補碼。
對於整形來說:數據存放內存中其實存放的是補碼。
為什麼呢?
在計算機系統中,數值一律用補碼來錶示和存儲。原因在於,使用補碼,可以將符號比特和數值域統一處理;
同時,加法和减法也可以統一處理(CPU只有加法器)此外,補碼與原碼相互轉換,其運算過程是相同的,不需要額外的硬件電路。
我們舉個例子:
int a=1;
int c=a-1;
上面說了,CPU只能處理加法,也就是說c=a+(-1),我們來用二進制的角度來看。
a的原碼是
00000000000000000000000000000001 //正數的原反補相同
-1的原碼是
10000000000000000000000000000001 //原碼
11111111111111111111111111111110 //反碼
11111111111111111111111111111111 //補碼
如果按照CPU的方法,a的原碼和-1的原碼相加發現:
10000000000000000000000000000010
但如果有了補碼,結果如下:

我們看看在內存中的存儲:
我們可以看到對於a和b分別存儲的是補碼。但是我們發現順序有點不對勁。
這是又為什麼?
2.2 大小端介紹
什麼是大端小端:
大端(存儲)模式,是指數據的低比特保存在內存的高地址中,而數據的高比特,保存在內存的低地址中;
小端(存儲)模式,是指數據的低比特保存在內存的低地址中,而數據的高比特,,保存在內存的高地址中。
內存中儲存的值是用十六進制來錶示,至於為什麼不用二進制錶示,因為二進制太長了,而且不好看,但是內存中實際儲存的還是二進制。
我們用0x11223344來舉例:
11是數據的高比特,44是數據的低比特
為什麼有大端和小端:
為什麼會有大小端模式之分呢?這是因為在計算機系統中,我們是以字節為單比特的,每個地址單元都對應著一個字節,一個字節為8 bit。但是在C語言中除了8 bit的char之外,還有16 bit的short型,32 bit的long型(要看具體的編譯器),另外,對於比特數大於8比特的處理器,例如16比特或者32比特的處理器,由於寄存器寬度大於一個字節,那麼必然存在著一個如何將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式。
例如:一個 16bit 的 short 型 x ,在內存中的地址為 0x0010 , x 的值為 0x1122 ,那麼 0x11 為高字節, 0x22 為低字節。對於大端模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中。小端模式,剛好相反。我們常用的 X86 結構是小端模式,而 KEIL C51 則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
百度2015年系統工程師筆試題:
請簡述大端字節序和小端字節序的概念,設計一個小程序來判斷當前機器的字節序。
首先考慮這個代碼應該實現的邏輯:
我們可以創建一個變量為1,然後取地址,强制類型轉換為char類型,因為取地址取的是第一個字節的地址,所以我們打印出來第一個字節裏面的裏面的值看是1還是0。
參考代碼:
#include <stdio.h>
int check_sys()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
}
代碼的運行結果是:
我電腦的硬件是小端儲存方式。
練習
下面的這些代碼,如果不經過簡單的思考,輸出的內容會讓你詫异。
下面程序輸出什麼?
//代碼1
#include <stdio.h>
int main()
{
char a = -1;
signed char b = -1;
unsigned char c = -1;
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}
代碼的運行結果如下: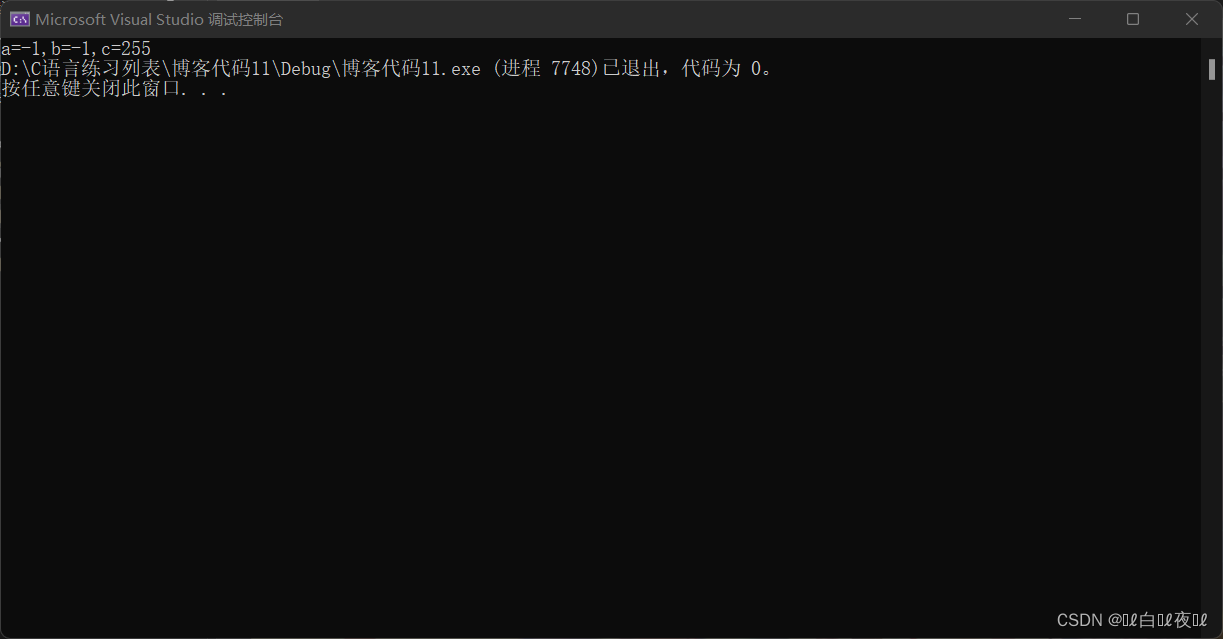
-1的補碼是
11111111111111111111111111111111
儲存進入a中,因為是char類型,所以這裏會截斷,也就是說取二進制的後八比特。
儲存進入b中,因為是signed char(有符號的char類型),和上面的char類型一樣。
儲存進入c中,因為是unsigned char(無符號的char類型),也就是說沒有符號比特。
我們打印的時候使用%d,需要整形提昇,a和b是有符號類型,所以整型提昇是左邊補1,最後和-1的補碼是一樣的。
然而c是無符號類型,左邊補0,補全之後的補碼是這樣的:
00000000000000000000000011111111
所以打印出來的才是255。
//代碼2
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
}
代碼的運行結果如下: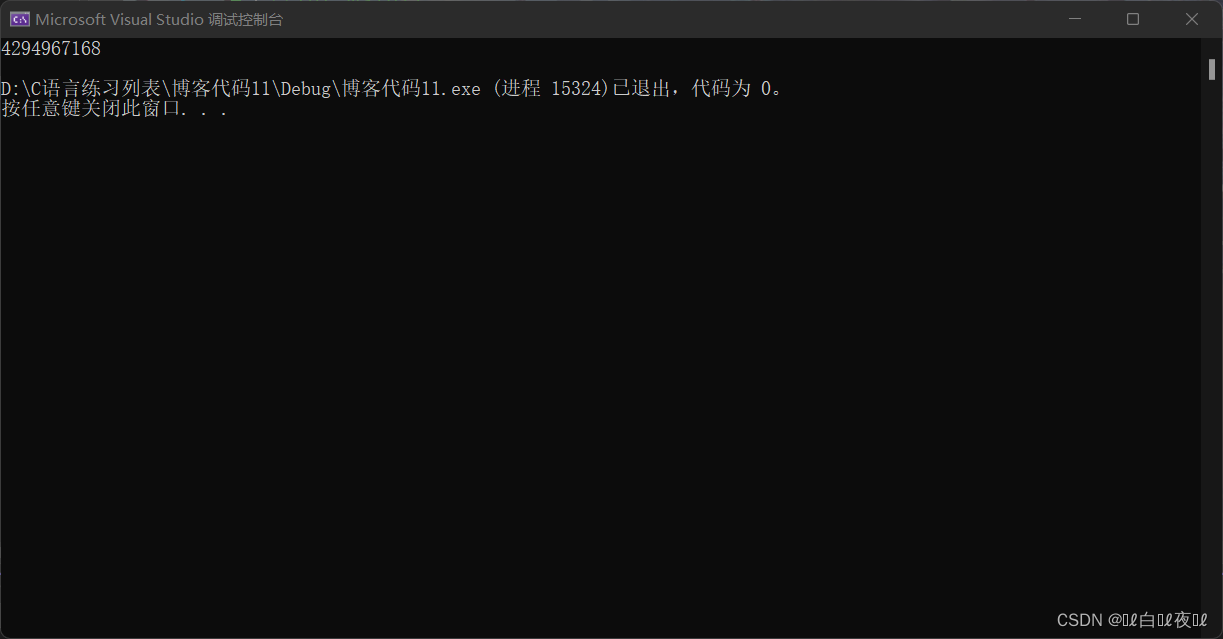
-128的補碼是:
11111111111111111111111110000000
儲存進入char類型的a中要截斷,10000000,這是有符號比特,我們打印的是無符號整形,所以要整型提昇,變成這個樣子。
11111111111111111111111110000000
因為是無符號整型,補碼等於原碼,結果就是上面很大的那個數了。
//代碼3
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n", a);
return 0;
}
這段代碼結果和上面一樣,只不過128的補碼是
00000000000000000000000010000000。
//代碼4
#include <stdio.h>
int main()
{
int i = -20;
unsigned int j = 10;
printf("%d\n", i + j);
//按照補碼的形式進行運算,最後格式化成為有符號整數
return 0;
}
代碼運行結果: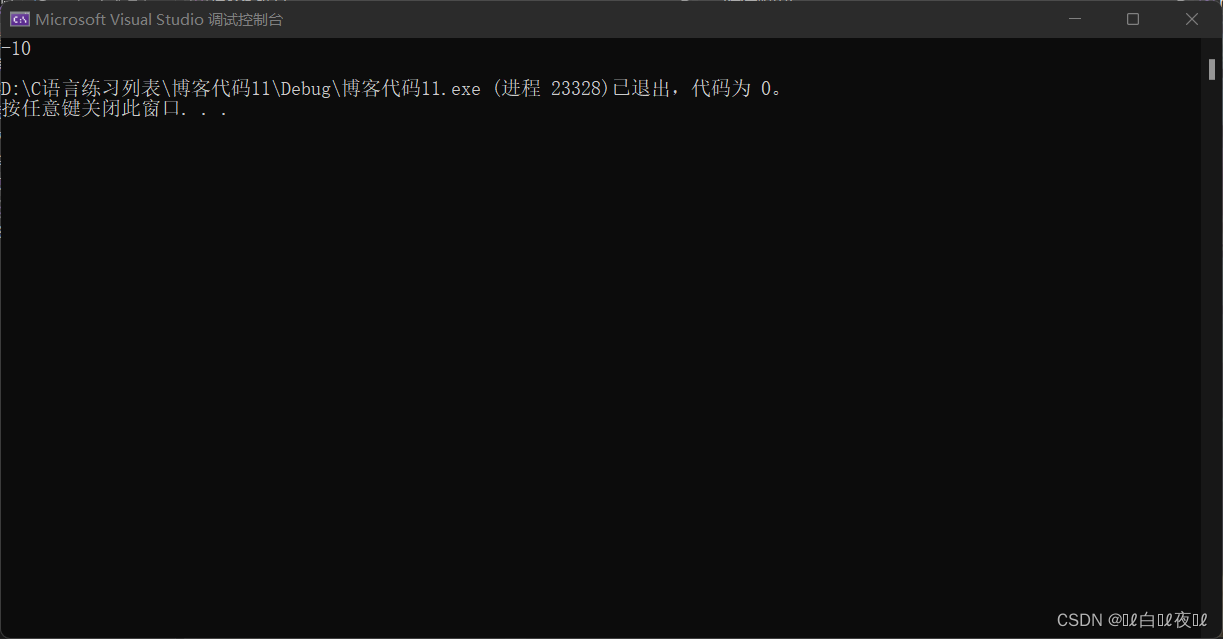
變量 i 的補碼是:
11111111111111111111111111101100
變量 j 的補碼是:
00000000000000000000000000001010
i+j的補碼是:
i+j的補碼變成原碼是
10000000000000000000000000001010
最後以%d方式打印。
//代碼5
#include <stdio.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
}
return 0;
}
這段代碼打印出來的結果是死循環。
因為 i 是unsigned int類型,無論怎麼樣都是正數,所以會死循環。
//代碼6
#include <stdio.h>
#include <string.h>
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
這段代碼的輸出結果是: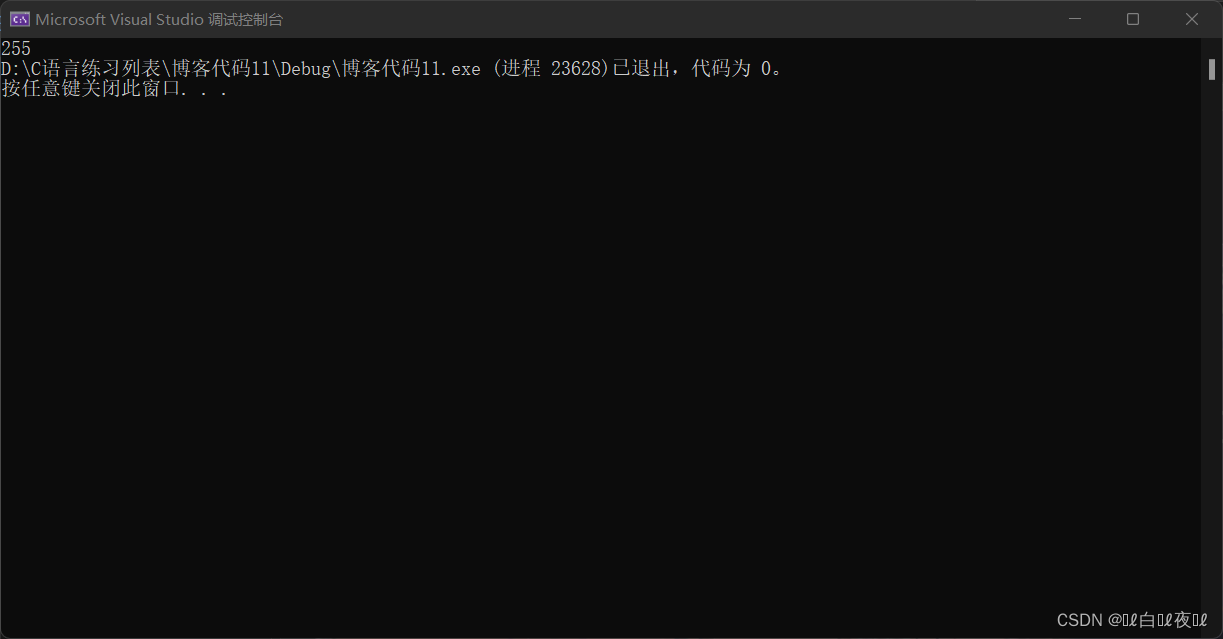
我們第一次進入循環的時候,char a[1000]這個數組裏面的第一個元素是:
-1,然後是-2…
以二進制的角度來看:
-1的補碼 11111111111111111111111111111111
-2的補碼 11111111111111111111111111111110
…
我們只能儲存進後八比特的數據,這裏要注意,strlen是遇到\0然後停止,不計算\0的比特置,‘\0’等於char裏面儲存的0。
也就是說二進制到這裏才會停止:
11111111111111111111111100000000
所以輸出結果是255。
這裏我們還發現一件事,有符號char類型的範圍是0~127和-1~-128
無符號的char類型範圍是是0~255。
//代碼7
#include <stdio.h>
unsigned char i = 0;
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
return 0;
}
這個代碼的運行結果也是死循環。
因為 i 是unsigned char類型,無論 i 怎麼加,都是正數,所以死循環。
3. 浮點型在內存中的存儲
常見的浮點數:
3.14159
1E10
浮點數家族包括: float、double、long double 類型。
浮點數錶示的範圍:float.h中定義
3.1 一個例子
浮點數存儲的例子:
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值為:%d\n", n);
printf("*pFloat的值為:%f\n", *pFloat);
return 0;
}
我們的輸出結果是: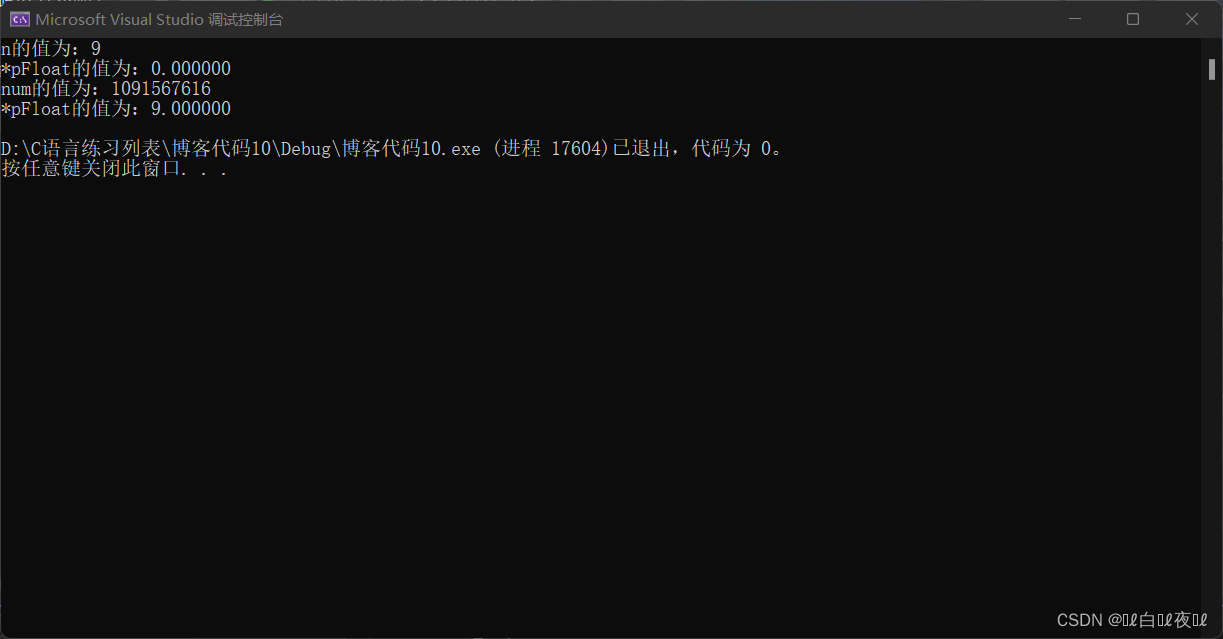
實際的結果是不是很不符合我們的預期結果?
這又是為什麼呢?我們往下看:
3.2 浮點數存儲規則
num 和 *pFloat 在內存中明明是同一個數,為什麼浮點數和整數的解讀結果會差別這麼大?
要理解這個結果,一定要搞懂浮點數在計算機內部的錶示方法。
詳細解讀:
根據國際標准IEEE(電氣和電子工程協會) 754,任意一個二進制浮點數V可以錶示成下面的形式:
(-1)^S * M * 2^E
(-1)^S錶示符號比特,當S=0,V為正數;當S=1,V為負數。
M錶示有效數字,大於等於1,小於2。
2^E錶示指數比特。
舉例來說:
十進制的5.0,寫成二進制是 101.0 ,相當於 1.01×2^2 。
那麼,按照上面V的格式,可以得出S=0,M=1.01,E=2。
十進制的-5.0,寫成二進制是 -101.0 ,相當於 -1.01×2^2 。那麼,S=1,M=1.01,E=2。
IEEE 754規定:
對於32比特的浮點數,最高的1比特是符號比特s,接著的8比特是指數E,剩下的23比特為有效數字M。
對於64比特的浮點數,最高的1比特是符號比特S,接著的11比特是指數E,剩下的52比特為有效數字M。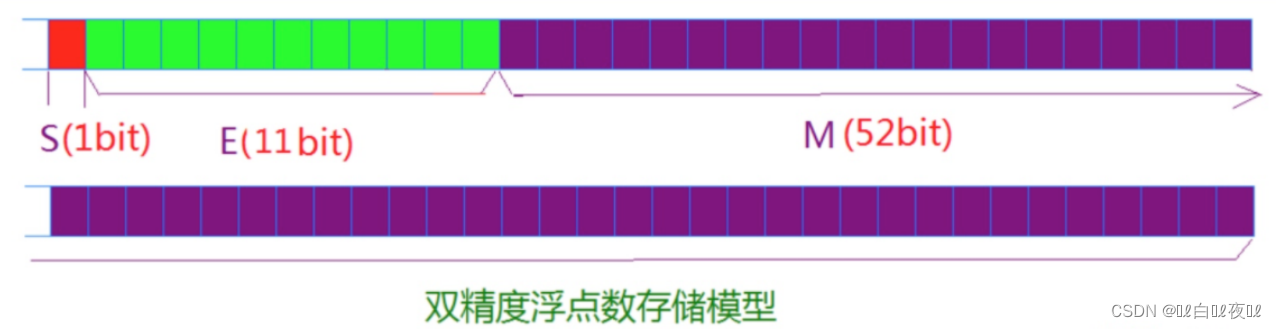
IEEE 754對有效數字M和指數E,還有一些特別規定。
前面說過, 1≤M<2 ,也就是說,M可以寫成 1.xxxxxx 的形式,其中xxxxxx錶示小數部分。
IEEE 754規定,在計算機內部保存M時,默認這個數的第一比特總是1,因此可以被舍去,只保存後面的xxxxxx部分。比如保存1.01的時候,只保存01,等到讀取的時候,再把第一比特的1加上去。這樣做的目的,是節省1比特有效數字。以32比特浮點數為例,留給M只有23比特,將第一比特的1舍去以後,等於可以保存24比特有效數字。
至於指數E,情况就比較複雜。
首先,E為一個無符號整數(unsigned int)
這意味著,如果E為8比特,它的取值範圍為0 ~ 255;如果E為11比特,它的取值範圍為0 ~ 2047。但是,我們知道,科學計數法中的E是可以出現負數的,所以IEEE 754規定,存入內存時E的真實值必須再加上一個中間數,對於8比特的E,這個中間數是127;對於11比特的E,這個中間數是1023。比如,2^10的E是10,所以保存成32比特浮點數時,必須保存成10+127=137,即10001001。
然後,指數E從內存中取出還可以再分成三種情况:
E不全為0或不全為1
這時,浮點數就采用下面的規則錶示,即指數E的計算值减去127(或1023),得到真實值,再將有效數字M前加上第一比特的1。
比如:
0.5(1/2)的二進制形式為0.1,由於規定正數部分必須為1,即將小數點右移1比特,則為1.0*2^(-1),其階碼為-1+127=126,錶示為
01111110,而尾數1.0去掉整數部分為0,補齊0到23比特00000000000000000000000,則其二進制錶示形式為:
0 01111110 00000000000000000000000
E全為0
這時,浮點數的指數E等於1-127(或者1-1023)即為真實值,有效數字M不再加上第一比特的1,而是還原為0.xxxxxx的小數。這樣做是為了錶示±0,以及接近於0的很小的數字。
E全為1
這時,如果有效數字M全為0,錶示±無窮大(正負取决於符號比特s);
這就是浮點型的數據儲存方式。
解釋前面的題目:
下面,讓我們回到一開始的問題:為什麼 0x00000009 還原成浮點數,就成了 0.000000 ?
首先,將 0x00000009 拆分,得到第一比特符號比特s=0,後面8比特的指數E=00000000 ,最後23比特的有效數字M=000 0000 0000 0000 0000 1001。
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由於指數E全為0,所以符合上一節的第二種情况。因此,浮點數V就寫成:
V=(-1)^0 × 0.00000000000000000001001×2^(-126)=1.001×2^(-146)
顯然,V是一個很小的接近於0的正數,所以用十進制小數錶示就是0.000000。(%f只打印小數點後面6比特的數)
再看例題的第二部分。
請問浮點數9.0,如何用二進制錶示?還原成十進制又是多少?
首先,浮點數9.0等於二進制的1001.0,即1.001×2^3。
9.0 -> 1001.0 ->(-1)^01.0012^3 -> s=0, M=1.001,E=3+127=130
那麼,第一比特的符號比特s=0,有效數字M等於001後面再加20個0,凑滿23比特,指數E等於3+127=130, 即10000010。
所以,寫成二進制形式,應該是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
這個32比特的二進制數,還原成十進制,正是 1091567616 。
結束語
請家人們點個贊,大佬們指點不足。
边栏推荐
- "Xiaodeng in operation and maintenance" meets the compliance requirements of gdpr
- LC interview question 02.07 Linked list intersection & lc142 Circular linked list II
- Flexible layout (II)
- Academic report series (VI) - autonomous driving on the journey to full autonomy
- Jetpack compose is much more than a UI framework~
- Paranoid unqualified company
- Complete process of MySQL SQL
- Project practice five fitting straight lines to obtain the center line
- Nesting and splitting of components
- OOM(内存溢出)造成原因及解决方案
猜你喜欢

FPGA course: application scenario of jesd204b (dry goods sharing)
虚拟机的作用
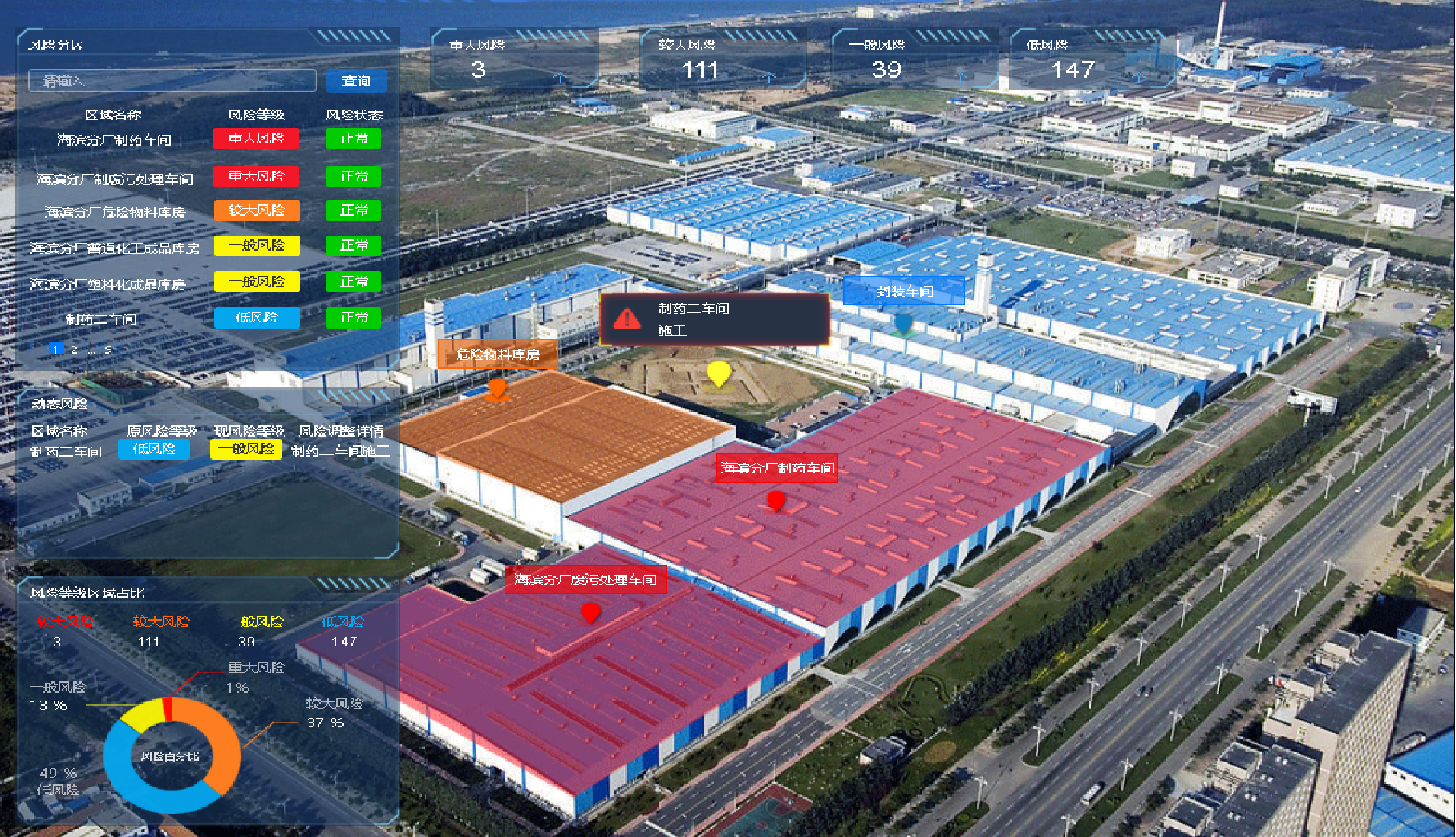
Four goals for the construction of intelligent safety risk management and control platform for hazardous chemical enterprises in Chemical Industry Park

Communication between non parent and child components
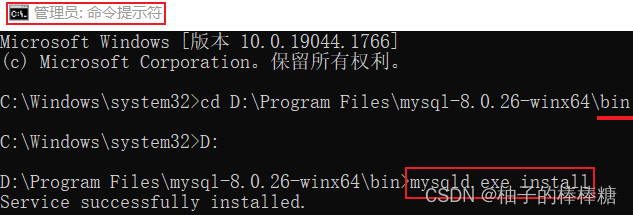
计算机服务中缺失MySQL服务
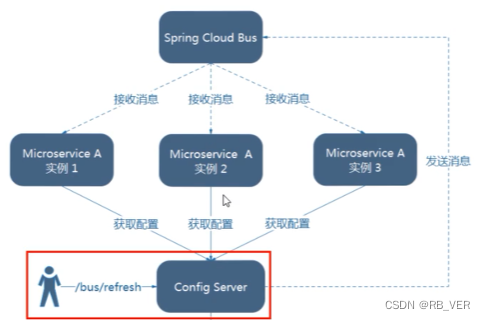
Bus message bus
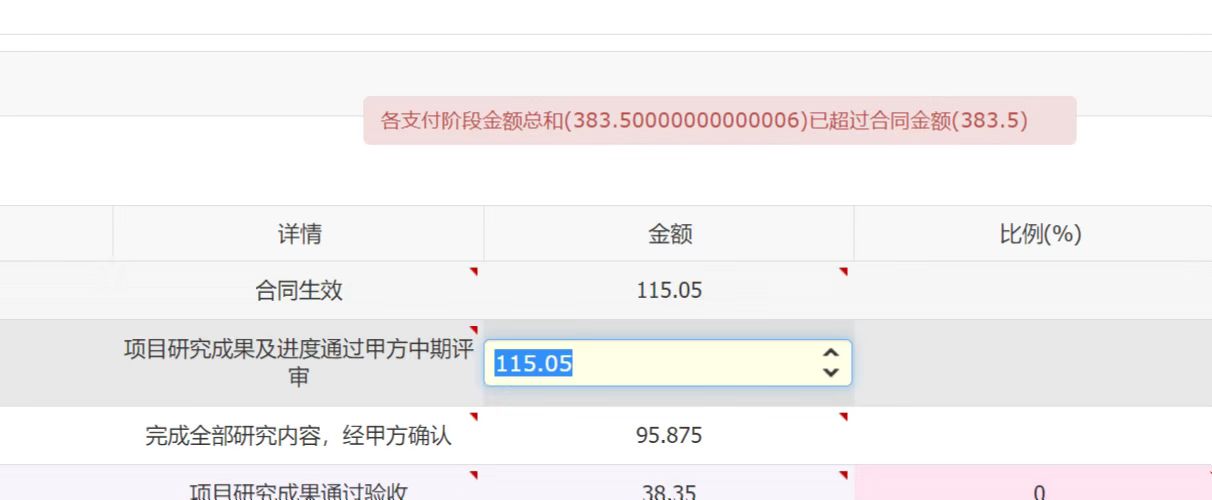
About binary cannot express decimals accurately
Basic process of network transmission using tcp/ip four layer model
Detailed explanation of transform origin attribute
CompletableFuture使用详解
随机推荐
Test of transform parameters of impdp
JS small exercise
Special behavior of main function in import statement
A slow SQL drags the whole system down
Multithreading and high concurrency (9) -- other synchronization components of AQS (semaphore, reentrantreadwritelock, exchanger)
Flexible layout (I)
How Oracle backs up indexes
$refs: get the element object or sub component instance in the component:
Explain Bleu in machine translation task in detail
. Net 5 fluentftp connection FTP failure problem: this operation is only allowed using a successfully authenticated context
Esxi attaching mobile (Mechanical) hard disk detailed tutorial
Software acceptance test
软件验收测试
PostgreSQL source code (59) analysis of transaction ID allocation and overflow judgment methods
Sqlmap tutorial (IV) practical skills three: bypass the firewall
Bus message bus
MIPS uclibc cross compile ffmpeg, support g711a encoding and decoding
Docker compose start redis cluster
How DHCP router works
Communication of components