当前位置:网站首页>Hidden Markov model (HMM) learning notes
Hidden Markov model (HMM) learning notes
2022-07-07 07:12:00 【Wsyoneself】
- Markov chain : At any moment t, The value of the observation variable depends only on the current state variable , It has nothing to do with the state variables at other times, that is, the observed variables ; meanwhile , The current state value only depends on the state of the previous moment , It has nothing to do with anything else .
- Obtained by Markov HMM The joint probability distribution of
- A model must contain parameters , The essence of machine learning is to find a set of optimal parameters , Make the fitting effect of the model the best .
- HMM Parameters of : State transition probability ( Infer the probability of the next state from the current state ), Output observation probability ( The probability of inferring the observed value from the current state )
- Three basic questions :
- The problem of probability calculation : Given the model and observation sequence , Calculate the probability of occurrence of the observation sequence
- Learning problems : Known observation sequence , Estimate model parameters , Maximize the output probability of the observation sequence
- Prediction problem : Given the model and observation sequence , Find the conditional probability of a given observation sequence P(I|O) The largest hidden state I
- Algorithm :
- Forward algorithm : Given hidden Markov model , And to the moment t The sequence of observations , And the state is qi The forward probability of : It's actually from t=1 Start calculating , According to the implicit Markov hypothesis , Iterative calculation can get ( I understand : Forward probability is the moment t Transfer to time t+1 Probability , Multiply each state by the state transition probability of the current state , Because the final result is the observed value , We also need to multiply the observation probability at the last moment )
- Backward algorithm : Given hidden Markov model , And from t+1 Moment to T The sequence of observations , And the state is qi Backward probability : Suppose the probability of the last moment is 1, Then the inverse calculation of the conditional probability of reason is pushed forward
- Baum-welch Algorithm : If the sample data has no label , Then the training data only contains the observation sequence O, But the corresponding state I Unknown , Then the hidden Markov model at this time is a probability model with hidden variables .
The essence of parameter learning is still EM,EM The basic idea of is to first add the initial estimate of the parameter to the likelihood function , Then maximize the likelihood function ( It's usually derivative , Make it equal to 0), Get new parameter estimates , repeated , Until it converges .
Viterbi (Viterbi) Algorithm : It's a dynamic programming algorithm , Used to find the most likely sequence of observed events - Viterbi path - Implicit state sequence .
Generalization :
Given models and observations ,Forward The algorithm can calculate the probability of observing a specific sequence from the model ;Viterbi The algorithm can calculate the most likely internal state ;Baum-Welch The algorithm can be used for training HMM. When there is enough training data , use Baum-Welch Work out HMM State transition probability and observation probability function , And then you can use it Viterbi The algorithm calculates the most likely phoneme sequence behind each input speech . But if the amount of data is limited , Often first train some smaller HMM Used to identify each monosyllabic (monophone), Or triphones (triphone), Then put these small HMM String together to recognize continuous speech
For speech synthesis , Given a string of phonemes , Go to the database to find a bunch of small ones that best match this crosstalk HMM, String them into a long HMM, Stands for the whole sentence . Then according to this combination HMM, Calculate the sequence of speech parameters that are most likely to be observed , The rest is to generate speech from the parameter sequence . This is a simplification of the whole process , The main problem is , The speech parameters thus generated are discontinuous , because HMM The state of is discrete . To solve this problem ,Keiichi Tokuda Learn from the dynamic parameters widely used in speech recognition ( The first and second derivatives of parameters ), It is introduced into the parameter generation of speech synthesis , The coherence of generated speech has been greatly improved . The key is to use the recessive state , Such as grammar , The habit of using words, etc , Infer the output with higher probability .
- When the model parameters are known , The observation sequence is O when , The state can be any state , Then the observation sequence in each state is O The probability accumulation of is the probability of the observation sequence .
- For supervised learning , The state transition probability and output observation probability can be calculated directly from the data ( For participles , The observation sequence corresponds to the text sentence , The hidden state corresponds to the label of each word in the sentence )
- The observation sequence in speech recognition is language , The hidden state is text , The function of speech recognition is to convert speech into corresponding words .
Reference resources :
「 hidden Markov model 」(HMM-Based) How is it applied in speech synthesis ? - You know (zhihu.com)
边栏推荐
- How can gyms improve their competitiveness?
- Anr principle and Practice
- 工具类:对象转map 驼峰转下划线 下划线转驼峰
- Complete process of MySQL SQL
- 什么情况下考虑分库分表
- Leetcode t1165: log analysis
- Abnova membrane protein lipoprotein technology and category display
- Answer to the second stage of the assignment of "information security management and evaluation" of the higher vocational group of the 2018 Jiangsu Vocational College skills competition
- Tumor immunotherapy research prosci Lag3 antibody solution
- Esxi attaching mobile (Mechanical) hard disk detailed tutorial
猜你喜欢
freeswitch拨打分机号源代码跟踪
Prime partner of Huawei machine test questions
The latest trends of data asset management and data security at home and abroad
IP address

Brand · consultation standardization

Paranoid unqualified company
At the age of 20, I got the ByteDance offer on four sides, and I still can't believe it
Bus消息总线
How can gyms improve their competitiveness?
异步组件和Suspense(真实开发中)
随机推荐
Four goals for the construction of intelligent safety risk management and control platform for hazardous chemical enterprises in Chemical Industry Park
Matlab tips (29) polynomial fitting plotfit
How does an enterprise manage data? Share the experience summary of four aspects of data governance
2022年全国所有A级景区数据(13604条)
Circulating tumor cells - here comes abnova's solution
Answer to the second stage of the assignment of "information security management and evaluation" of the higher vocational group of the 2018 Jiangsu Vocational College skills competition
js小练习
Fast quantitative, abbkine protein quantitative kit BCA method is coming!
Abnova immunohistochemical service solution
Mysql---- import and export & View & Index & execution plan
After the promotion, sales volume and flow are both. Is it really easy to relax?
Get the city according to IP
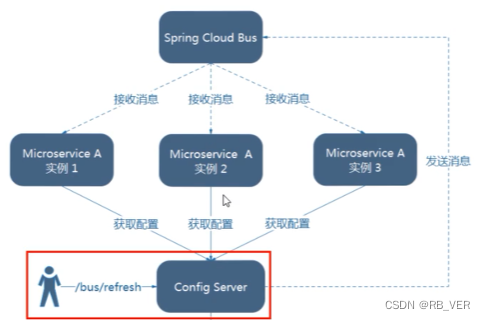
Bus消息总线
readonly 只读
Master-slave replication principle of MySQL
$refs:组件中获取元素对象或者子组件实例:
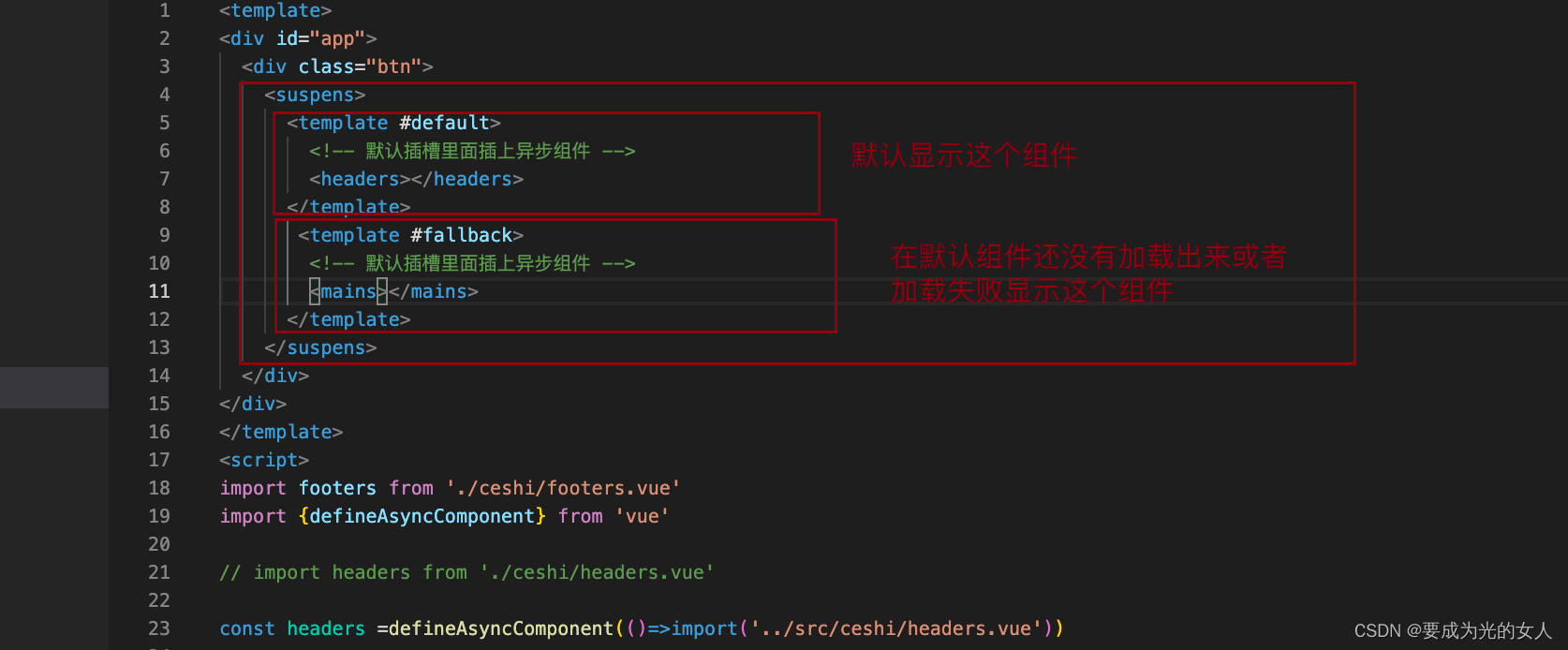
Asynchronous components and suspend (in real development)
Abnova circulating tumor DNA whole blood isolation, genomic DNA extraction and analysis
Config分布式配置中心
组件的通信