当前位置:网站首页>A brief history of deep learning (II)
A brief history of deep learning (II)
2022-07-07 00:53:00 【Lao Qi】
A brief history of deep learning ( Two )
This article series 《 A brief history of deep learning 》 The second part
2018 - 2020 years
since 2017 Since then , Deep learning algorithm 、 Applications and technologies are advancing by leaps and bounds . For the sake of clarity , The subsequent development is divided by category . In each category , We will all review major trends and some of the most important breakthroughs .
Applied to images Transformers
since transformers stay NLP After Zhongda shows off , Some pioneers can't wait to put attention Applied to images . Several Google researchers published an article entitled 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》^{[7]} The paper of , According to the article , An ordinary transformer With a little modification , Directly used in an image sequence , You can achieve a good classification . These researchers named their framework Vision Transformer, abbreviation ViT. In many CV under advisement , Will see ViT, As of this writing , It is Cifar-10 The most advanced classification model in .ViT Our researchers are not the first to attention For visual recognition , The paper 《Attention Augmented Convolutional Networks》^{[8]} The example in is earlier , This paper attempts to self-attentions Combined with convolution , So as to solve the problem of inductive deviation in convolution . The other is used earlier attentions The case of appears in 《Visual Transformers: Token-based Image Representation and Processing for Computer Vision》^{[9]} in , It will transformers Used on word filter or image filter . These two papers, together with many papers not listed here, have promoted the development of the basic framework , But not beyond ViT , So references [7] It is one of the important documents in the industry , The greatest innovation is ViT Developers use images directly as input , incorrect transformer Make too many changes .
ViT
The picture above is from reference [7] The paper of , In addition to directly using images as input , Two other tough features are also noticeable : Parallelism and scalability . Of course ,ViT It's not perfect , For example, early performance in target detection and image segmentation is poor , Until later introduced Swin Transformer After that, it got better .Swin Transformer The core highlight of is : It's in a continuous attention Sliding windows are used between layers . The following figure describes Swin Transformer and ViT Differences in the way hierarchical feature mapping is constructed .
Vison Transformers It is one of the most exciting research fields recently , More information can be found in resources [10] View in , There are also frontier studies in this area CrossViT
^{[11]}、ConViT^{[12]} and SepViT^{[13]} .
V-L Model
V-L Model refers to the vision involved at the same time (vision) And language (language) Model of , Also known as multi model (multi-models), for example , Generate a matching image according to the text content 、 Generate a text description of the image 、 Generate relevant answers according to the image content .transformer The success in the field of vision and language has largely contributed to the multi model of a single unified network . in fact , All visual and language tasks use pre training techniques . In computer vision , Pre training is usually done with large data sets ( for example ImageNet) Training ; stay NLP in , Generally, fine tune the network , Usually based on BERT. To learn more about V-L Task pre training , Please read the paper 《A Survey of Vision-Language Pre-Trained Models》^{[14]} . Another paper , It makes a good summary of the development in this regard , Please refer to resources [15] The article 《Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods》.
lately ,V-L A typical representative of the model OpenAI New version released DALL·E 2 , It can generate realistic images from text . Among the competitors ,DALL·E 2 In resolution 、 Image title matching and realism are excellent . The following example uses DALL·E 2 Some pictures generated .
Big language model
Language models that implement natural language processing have many uses , For example, predict the next word or character in the sentence ; Summarize a document ; Translate text content from one language to another ; Speech recognition or converting a piece of text into speech , wait . about transformers , whoever , All pay attention to it in NLP Application in .Transformer yes 21 The first of the century 10 One of the greatest inventions of the year . If there are enough data and calculations , The effect of large models is always shocking and enviable . In the past 5 In the year , The scale of language model has been expanding . The paper 《attention is all you need》^{[6]} A year after its publication , Everything began to change .2018 year ,OpenAI Released GPT (Generative Pre-trained Transformer), This was one of the largest language models at that time . A year later ,OpenAI It's released again GPT-2, This is a possession of 15 A hundred million parameter model . Another year passed , They released the ownership 1750 One hundred million parameters GPT-3, And in 570GB Training on the text of GPT-3. The whole model uses 1750 One hundred million parameters , The size is 700GB. GPT-3 How big is it ?LAMBDA The laboratory made such an estimate ^{[16]} , If you use the lowest price in the current market GPU Cloud services to train it , Need to spend 366 Years and 460 Thousands of dollars . However ,GPT-n The series is just the beginning , There are other big models . Their size is close to GPT-3 Or bigger . for example :NVIDIA Megatron-LM Yes 83 One hundred million parameters . Abreast of the times DeepMind Gopher Yes 2800 One hundred million parameters .2022 year 4 month 12 Japan ,DeepMind Released another one with 700 A language model with hundreds of millions of parameters . This model is called Chinchilla, Even though it's better than Gopher、GPT-3 and Megattron-turing NLG(5300 One hundred million parameters ) smaller , But its performance exceeds many language models .Chinchilla My paper shows that : The existing language model training is insufficient , If you double the size of the model , The data should also be doubled . Equivalent to , Google PaLM(Pathways Language Model) Almost at the same time , It includes 5400 One hundred million parameters .
Chinchilla Model
Here we need to add a model that should lead to Chinese language processing : Wenxin big model , This is Baidu launched .
Code generation model
Code generation model , That is, a programmable artificial intelligence system , It can write a specific piece of code 、 Or generate functions according to the requirements of natural language or text . As you might have guessed , Modern code generators are based on Transformer Of . For a long time , Just as we hope computers can do other things , We are also studying how to make computers write programs by themselves . First of all, this work is due to OpenAI Released Codex After that, it has to be paid attention to .Codex Is based on GitHub Open code base and other source code trained GPT-3.OpenAI Express :“OpenAI Codex Is a general programming model , It can be used for almost any programming task ( Although the results may vary ). We have successfully used it in Translation 、 Interpreting and refactoring code . But we know that , All we can do is the tip of the iceberg .” Codex Now supports GitHub Copilot , This is a paragraph AI Pair programming tools .
OpenAI Release Codex After a few months ,DeepMind Released AlphaCode , It's based on transformer The language model of , It can solve the problems in competitive programming competitions .AlphaCode The blog published said ,“ In the programming game ,AlphaCode Solving requires critical thinking 、 Logic 、 Algorithm 、 New problems of the combination of coding and natural language understanding , Among the participants, about... Were obtained 54% Ranking .” Solving programming problems is very difficult . just as Dzmitry said , Beyond the human level, there are still a few light years away . not long ago ,Meta AI Scientists released InCoder, This is a generation model that can generate and edit programs .
Back to the perceptron
In convolutional neural networks and transformer For a long time before the rise , Deep learning is developed around perceptron . later , Convolutional neural network shows excellent performance in various recognition tasks , Instead of multilayer perceptron . from Vision Transformers According to the current situation , It is still a promising framework . But did the perceptron die out completely ? May not be . It's just 2021 year 7 month , Two papers based on perceptron were published , One is 《MLP-Mixer: An all-MLP Architecture for Vision》^{[17]} , The other is 《Pay Attention to MLPs(gMLP)》^{[18]} .MLP-Mixer claim , Convolution sum attention Are unnecessary , It only uses MLP, It can achieve high accuracy in image classification .MLP-mixer An important feature of is that it contains two main MLP layer : A layer is applied to image data independently , It is called channel mixing ; Another layer is used for each image , Called spatial blending .gMLP It also shows that , Abandoned self-attention After convolution , It can still be used in image recognition and NLP Achieve high accuracy in the task .
MLP-Mizers and g-MLP
obviously , You didn't put MLPs To the extreme , What is fascinating is that they do compete with the most advanced deep Networks .
Let's talk about Convolutional Neural Networks : oriented 21 century 20 Convolutional neural networks of the s
since 2020 Since then , The research of computer vision has been around transformers an . stay NLP in ,transformer It has also become a norm .ViT Excellent performance in image classification , But in object detection and image segmentation, it is disappointing . With Swin Transformers available , It was not long before , These difficulties have also been overcome . Many people like convolutional neural networks , It's really effective , It's hard for us to give them up . With this love , Some scientists continue to promote the development of Convolutional Neural Networks , Then the residual neural network is proposed (ResNet).Saining Xie With him Meta AI My colleagues are working on this research , They elaborated the research results in the paper , And finally got a name ConvNeXt Convolution network framework . According to different test standards ,ConvNeXt Have achieved with Swin Transformer Quite a result . About ConvNeXt Details of , You can read references [19] .
Conclusion
Deep learning is a vast world , And change with each passing day , It is difficult to summarize everything in a short space , This is just a glimpse of the leopard . There are numerous papers in this field , Everyone can only understand a small area . In this paper , We haven't discussed a lot , For example, famous AlphaGo, Deep learning framework 、 Hardware accelerator 、 Graph neural network and so on , There's a lot more .
Reference material
[1]. https://www.getrevue.co/profile/deeprevision/issues/a-revised-history-of-deep-learning-issue-1-1145664?continueFlag=0d4c136e098ffe282d51bc9870b62335
[2]. https://github.com/Nyandwi/ModernConvNets?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[3]. https://www.deeplearningbook.org/contents/generative_models.html?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[4]. https://www.zhihu.com/question/434784733
[5]. https://www.jiqizhixin.com/articles/2018-01-10-20
[6]. https://arxiv.org/pdf/1706.03762.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[7]. https://arxiv.org/abs/2010.11929v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[8]. https://arxiv.org/abs/1904.09925?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[9]j. https://arxiv.org/abs/2006.03677?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[10]. https://arxiv.org/pdf/2101.01169.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[11]. https://arxiv.org/abs/2103.14899v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[12]. https://arxiv.org/abs/2103.10697v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[13]. https://arxiv.org/abs/2203.15380v2?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[14]. https://arxiv.org/abs/2202.10936?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[15]. https://arxiv.org/abs/1907.09358?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[16]. https://lambdalabs.com/blog/demystifying-gpt-3/?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[17]. https://arxiv.org/pdf/2105.01601v4.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[18]. https://arxiv.org/pdf/2105.08050.pdf?utm_campaign=Deep Learning Revision&utm_medium=email&utm_source=Revue newsletter
[19]. https://github.com/Nyandwi/ModernConvNets/blob/main/convnets/13-convnext.ipynb?utm_campaign=Deep%20Learning%20Revision&utm_medium=email&utm_source=Revue%20newsletter
边栏推荐
- 【批處理DOS-CMD命令-匯總和小結】-字符串搜索、查找、篩選命令(find、findstr),Find和findstr的區別和辨析
- How to set encoding in idea
- Data sharing of the 835 postgraduate entrance examination of software engineering in Hainan University in 23
- Distributed cache
- Learn self 3D representation like ray tracing ego3rt
- AI超清修复出黄家驹眼里的光、LeCun大佬《深度学习》课程生还报告、绝美画作只需一行代码、AI最新论文 | ShowMeAI资讯日报 #07.06
- Quaternion attitude calculation of madgwick
- Slow database query optimization
- Deep understanding of distributed cache design
- 城联优品入股浩柏国际进军国际资本市场,已完成第一步
猜你喜欢

stm32F407-------DAC数模转换
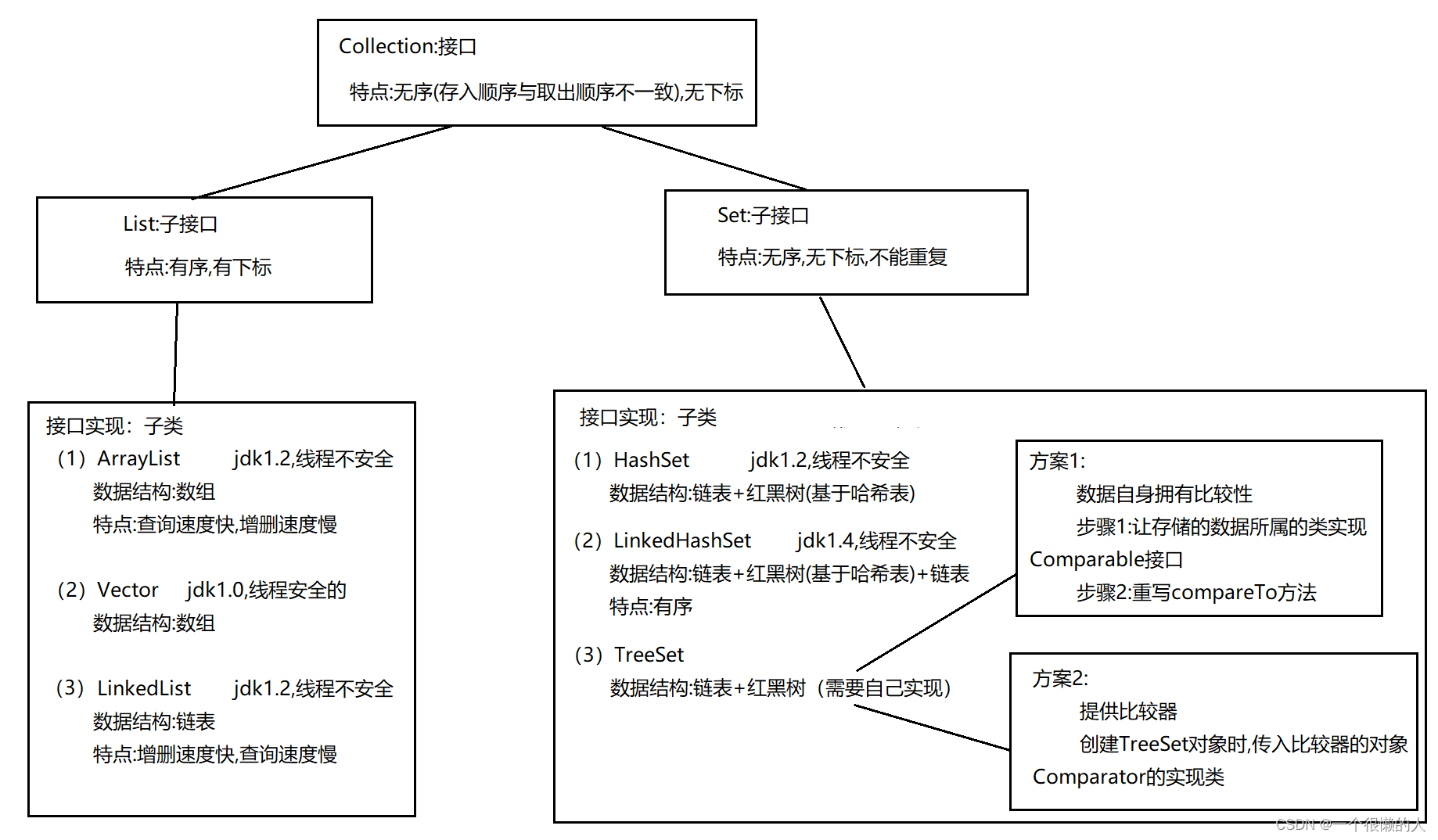
集合(泛型 & List & Set & 自定义排序)
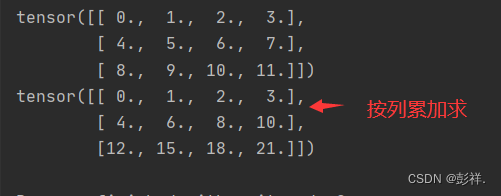
深度学习之线性代数

Data processing of deep learning
深入探索编译插桩技术(四、ASM 探秘)
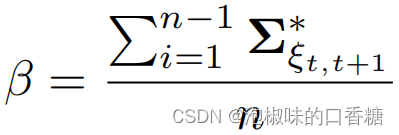
Slam d'attention: un slam visuel monoculaire appris de l'attention humaine
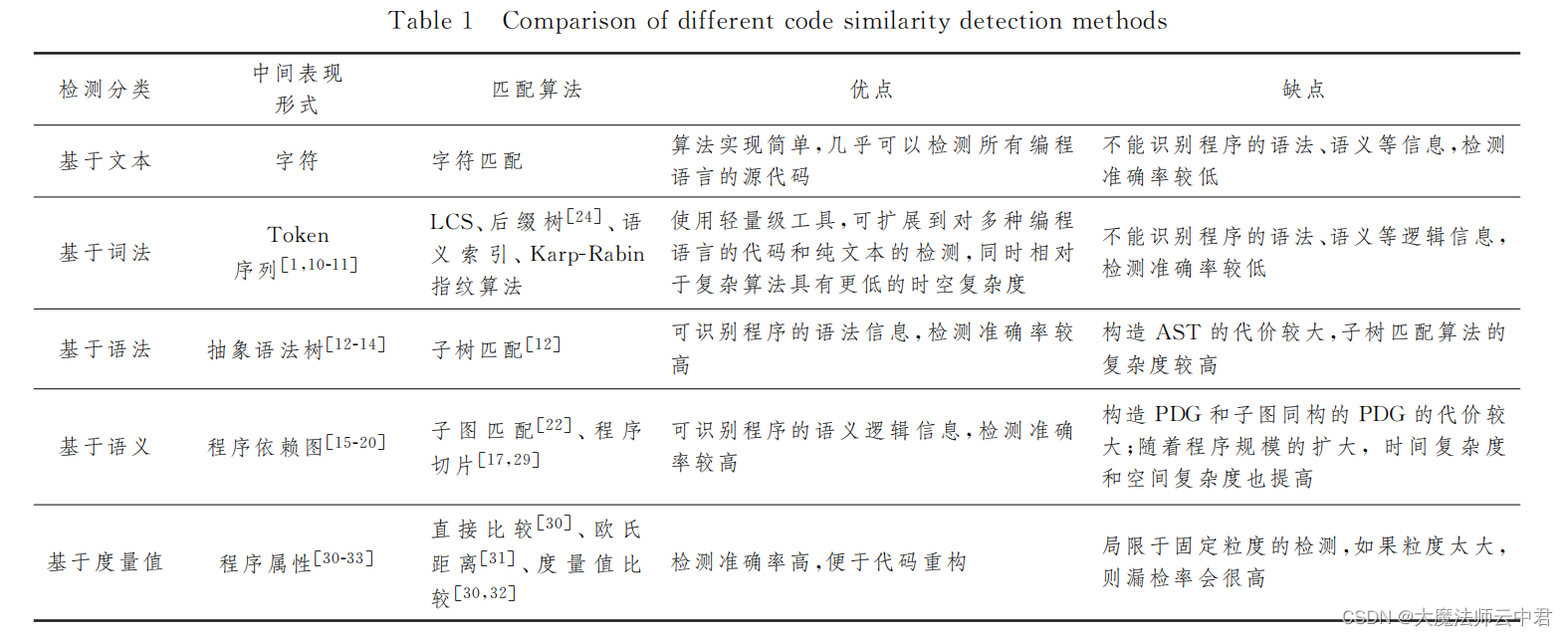
Five different code similarity detection and the development trend of code similarity detection

JWT signature does not match locally computed signature. JWT validity cannot be asserted and should
![[software reverse automation] complete collection of reverse tools](/img/72/d3e46a820796a48b458cd2d0a18f8f.png)
[software reverse automation] complete collection of reverse tools

The difference between redirectto and navigateto in uniapp

随机推荐
第六篇,STM32脉冲宽度调制(PWM)编程
Zabbix 5.0:通过LLD方式自动化监控阿里云RDS
批量获取中国所有行政区域经边界纬度坐标(到县区级别)
Model-Free Control
【vulnhub】presidential1
stm32F407-------DAC数模转换
深度学习简史(二)
Learn to use code to generate beautiful interface documents!!!
以机房B级建设标准满足等保2.0三级要求 | 混合云基础设施
深入探索编译插桩技术(四、ASM 探秘)
Set (generic & list & Set & custom sort)
三维扫描体数据的VTK体绘制程序设计
Are you ready to automate continuous deployment in ci/cd?
腾讯云 WebShell 体验
uniapp实现从本地上传头像并显示,同时将头像转化为base64格式存储在mysql数据库中
Mujoco Jacobi - inverse motion - sensor
AI super clear repair resurfaces the light in Huang Jiaju's eyes, Lecun boss's "deep learning" course survival report, beautiful paintings only need one line of code, AI's latest paper | showmeai info
dynamic programming
Article management system based on SSM framework
【软件逆向-求解flag】内存获取、逆变换操作、线性变换、约束求解