Learning rate is a crucial parameter in deep learning training , Most of the time, a proper learning rate can give full play to the great potential of the model . So the learning rate adjustment strategy is also very important , This blog introduces Pytorch Common learning rate adjustment methods in .
import torch
import numpy as np
from torch.optim import SGD
from torch.optim import lr_scheduler
from torch.nn.parameter import Parameter
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, lr=0.1)
The above is a general code , Here, set the basic learning rate to 0.1. Next, just show the code of the learning rate regulator , And the corresponding learning rate curve .
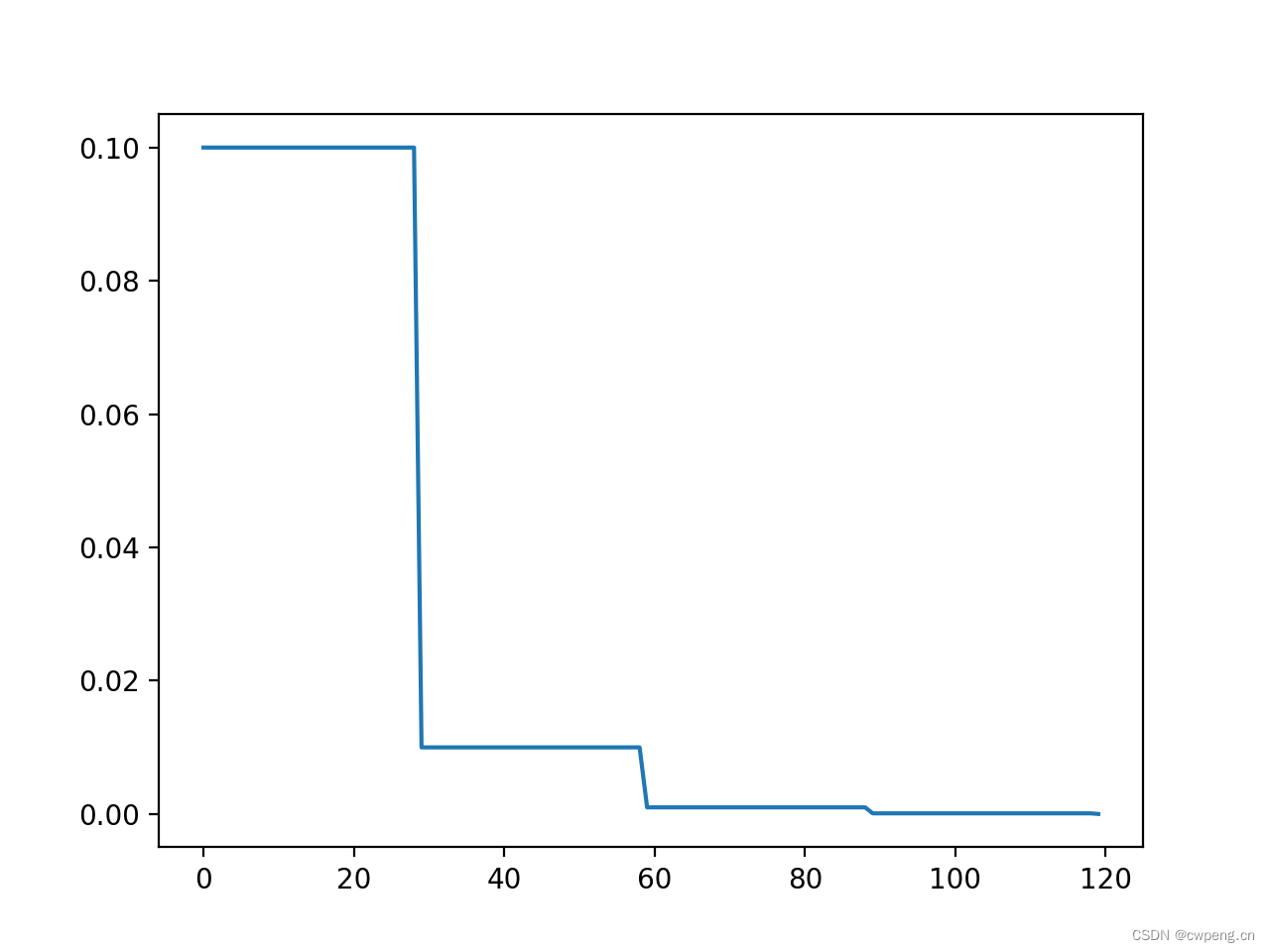
1. StepLR
This is the simplest and most commonly used learning rate adjustment method , every step_size round , Multiply the previous learning rate by gamma.
scheduler=lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
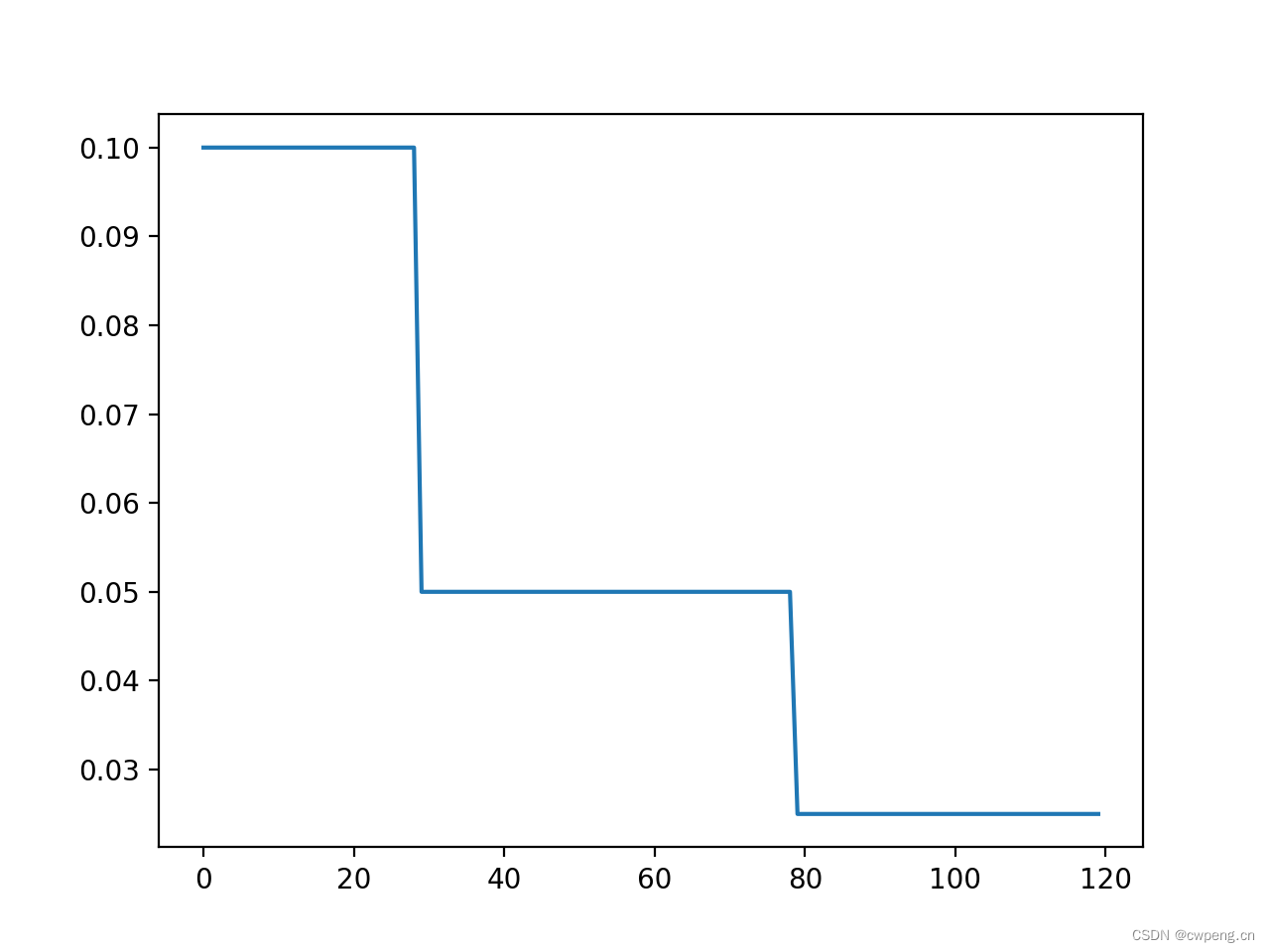
2. MultiStepLR
MultiStepLR It is also a very common learning rate adjustment strategy , It will be in every milestone when , Multiply the previous learning rate by gamma.
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30,80], gamma=0.5)
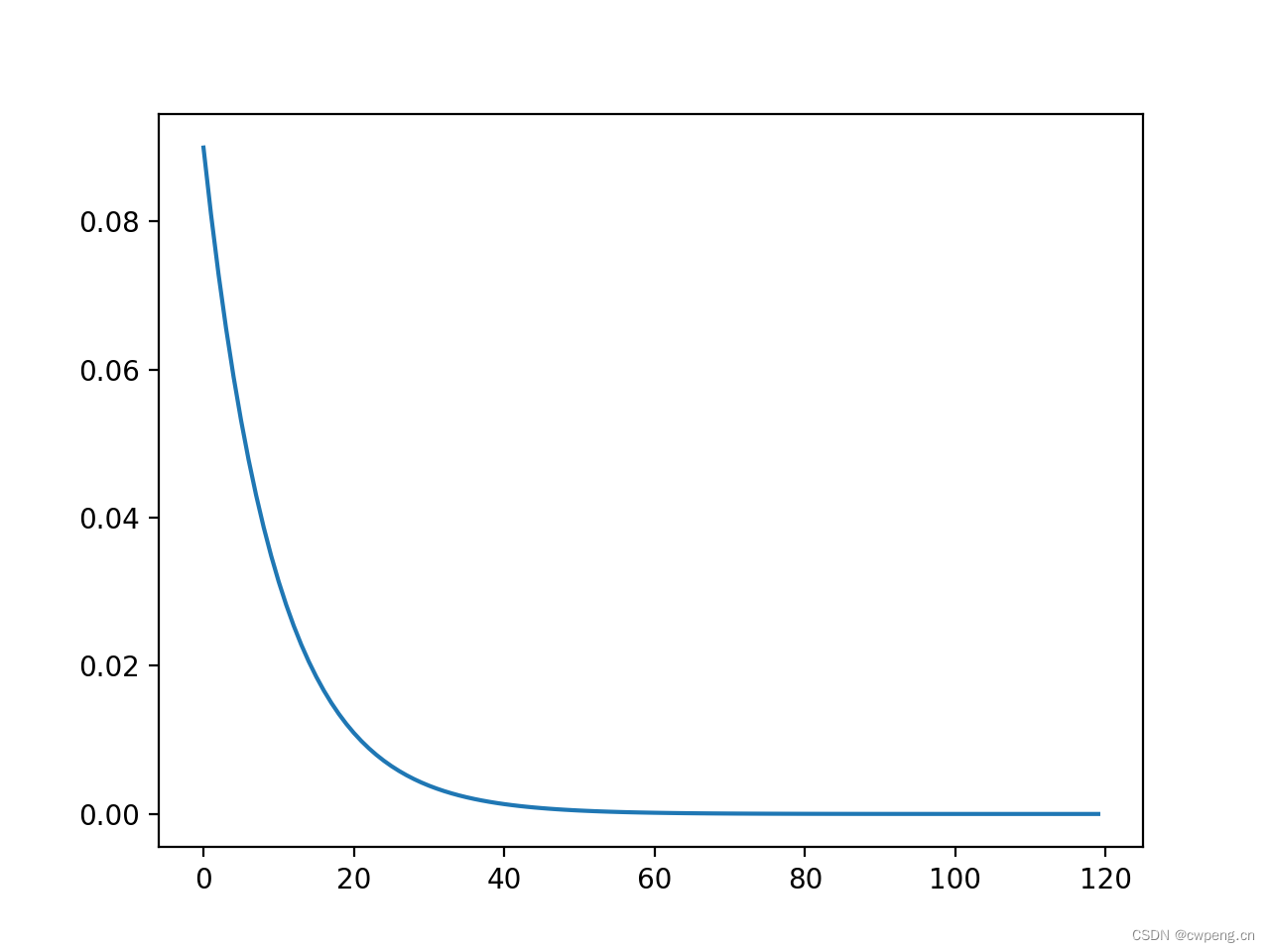
3. ExponentialLR
ExponentialLR It is a learning rate regulator with exponential decline , Each round will multiply the learning rate by gamma, So pay attention here gamma Don't set it too small , Otherwise, the learning rate will drop to 0.
scheduler=lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
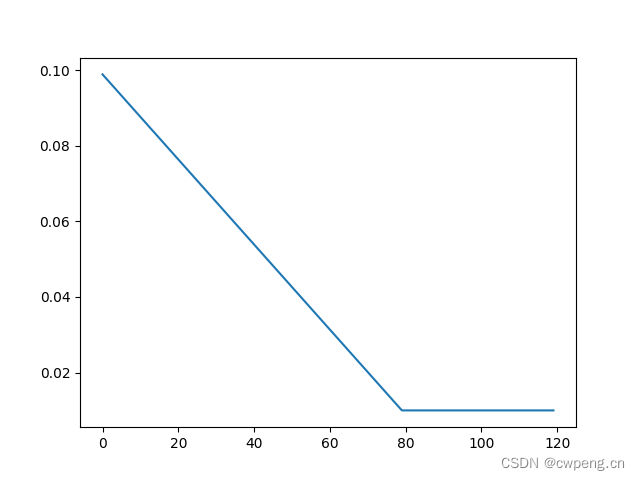
4. LinearLR
LinearLR Is the linear learning rate , Given start factor And finally factor,LinearLR Will do linear interpolation in the intermediate stage , For example, the learning rate is 0.1, start factor by 1, The final factor by 0.1, So the first 0 Sub iteration , The learning rate will be 0.1, The final round learning rate is 0.01. The total number of rounds set below total_iters by 80, So over 80 when , The learning rate is constant 0.01.
scheduler=lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)
5. CyclicLR
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)
CyclicLR There are more parameters for , Its curve looks like continuous uphill and downhill ,base_lr For the learning rate at the bottom ,max_lr For the peak learning rate ,step_size_up It is the number of rounds needed from the bottom to the top ,step_size_down The number of rounds from the peak to the bottom . As for why it is set like this , You can see The paper , In short, the best learning rate will be base_lr and max_lr,CyclicLR Instead of blindly declining, the process of increasing is to avoid falling into the saddle point .
scheduler=lr_scheduler.CyclicLR(optimizer,base_lr=0.1,max_lr=0.2,step_size_up=30,step_size_down=10)
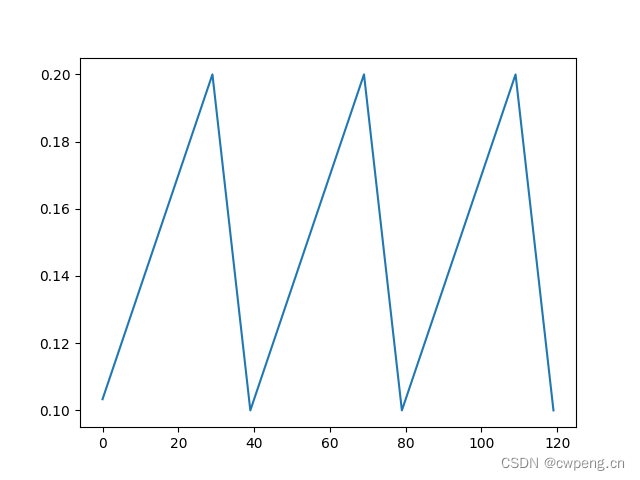
6. OneCycleLR
OneCycleLR As the name suggests, it's like CyclicLR One cycle version of , It also has multiple parameters ,max_lr Is the maximum learning rate ,pct_start Is the proportion of the rising part of the learning rate , The initial learning rate is max_lr/div_factor, The final learning rate is max_lr/final_div_factor, The total number of iterations is total_steps.
scheduler=lr_scheduler.OneCycleLR(optimizer,max_lr=0.1,pct_start=0.5,total_steps=120,div_factor=10,final_div_factor=10)
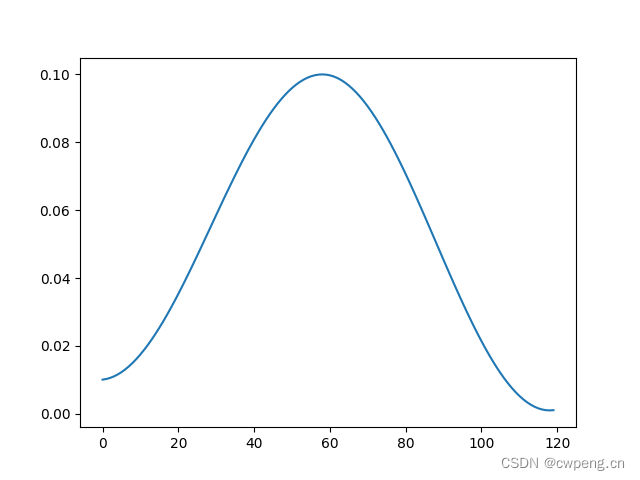
7. CosineAnnealingLR
CosineAnnealingLR Is the cosine annealing learning rate ,T_max It's half the cycle , The maximum learning rate is optimizer It is specified in , The minimum learning rate is eta_min. This can also help escape the saddle point . It is worth noting that the maximum learning rate should not be too large , otherwise loss There may be sharp fluctuations up and down in cycles similar to the learning rate .
scheduler=lr_scheduler.CosineAnnealingLR(optimizer,T_max=20,eta_min=0.05)
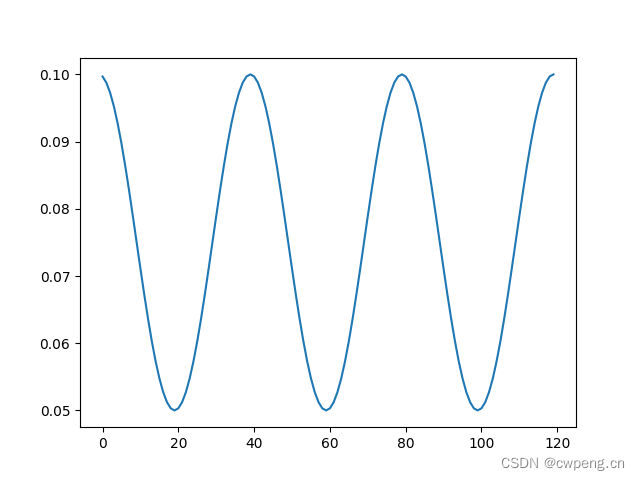
7. CosineAnnealingWarmRestarts
Here is relatively responsible , The formula is as follows , among T_0 It's the first cycle , From optimizer The learning rate in fell to eta_min, Each subsequent cycle becomes the previous cycle multiplied by T_mult.
\(eta_t = \eta_{min} + \frac{1}{2}(\eta_{max} - \eta_{min})\left(1 + \cos\left(\frac{T_{cur}}{T_{i}}\pi\right)\right)\)
scheduler=lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, T_mult=2, eta_min=0.01)
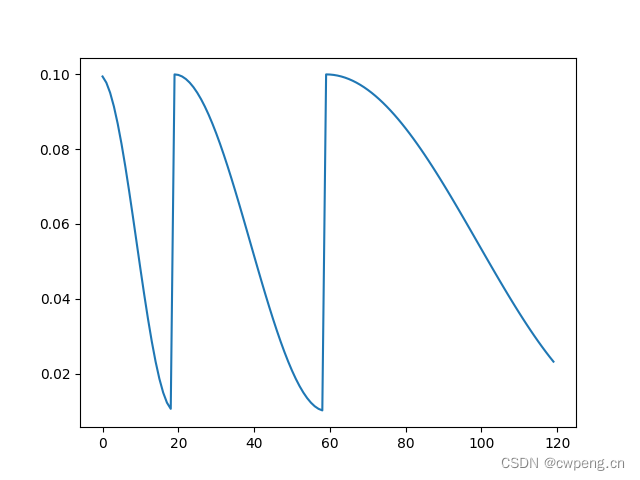
8. LambdaLR
LambdaLR In fact, there is no fixed learning rate curve , In the name lambda It refers to that the learning rate can be customized as a related epoch Of lambda function , For example, we define an exponential function , Realized ExponentialLR The function of .
scheduler=lr_scheduler.LambdaLR(optimizer,lr_lambda=lambda epoch:0.9**epoch)
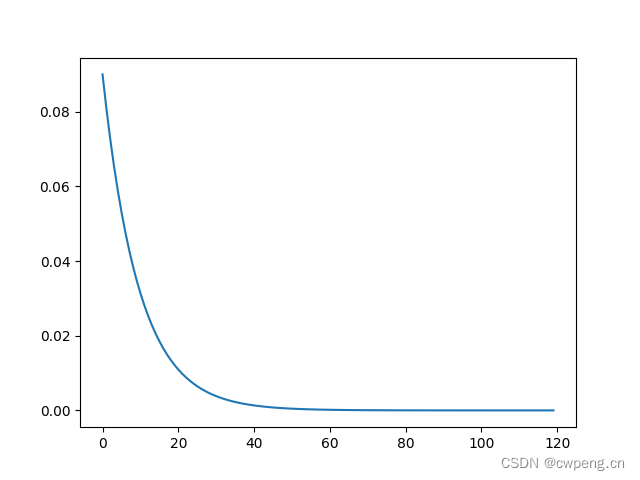
9.SequentialLR
SequentialLR You can connect multiple learning rate adjustment strategies in sequence , stay milestone Switch to the next learning rate adjustment strategy . The following is to combine an exponential decay learning rate with a linear decay learning rate .
scheduler=lr_scheduler.SequentialLR(optimizer,schedulers=[lr_scheduler.ExponentialLR(optimizer, gamma=0.9),lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.1,total_iters=80)],milestones=[50])
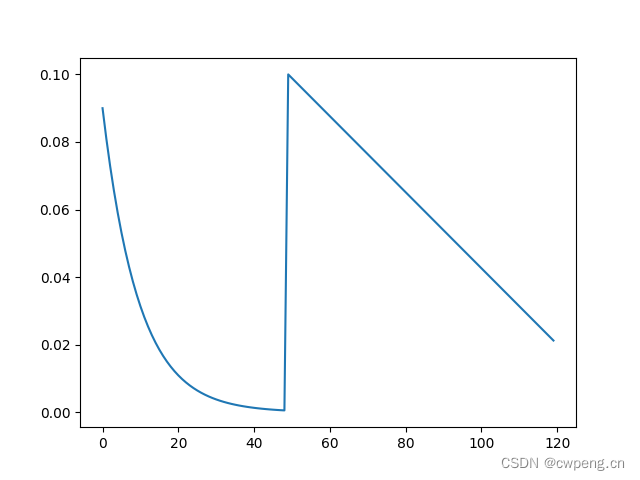
10.ChainedScheduler
ChainedScheduler and SequentialLR similar , It also calls several learning rate adjustment strategies in series in order , The difference is ChainedScheduler The learning rate changes continuously .
scheduler=lr_scheduler.ChainedScheduler([lr_scheduler.LinearLR(optimizer,start_factor=1,end_factor=0.5,total_iters=10),lr_scheduler.ExponentialLR(optimizer, gamma=0.95)])
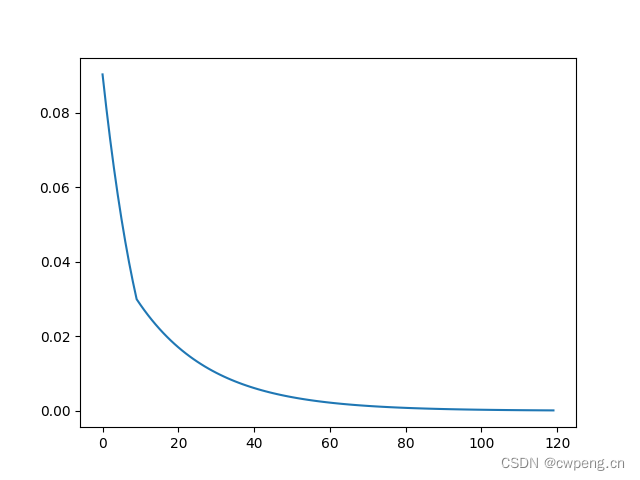
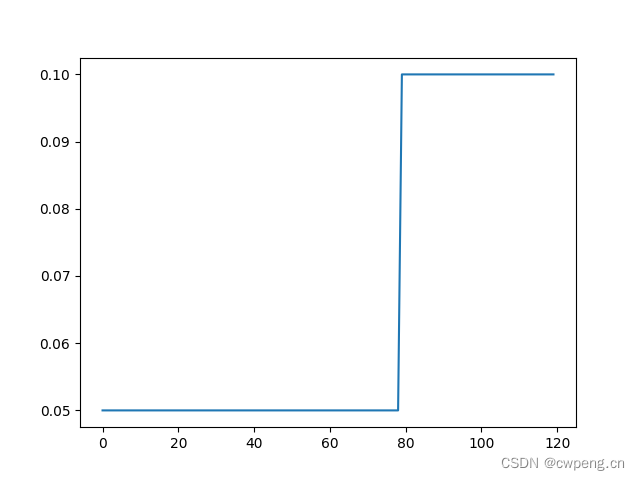
11.ConstantLR
ConstantLRConstantLR It's simple , stay total_iters In wheel general optimizer Multiply the specified learning rate by factor,total_iters The original learning rate is restored outside the round .
scheduler=lr_scheduler.ConstantLRConstantLR(optimizer,factor=0.5,total_iters=80)
12.ReduceLROnPlateau
ReduceLROnPlateau There are so many parameters , Its function is to adaptively adjust the learning rate , It's in step You will observe on the validation set loss Or accuracy ,loss Of course, the lower the better , The higher the accuracy, the better , So use loss As step Parameter time ,mode by min, When using accuracy as a parameter ,mode by max.factor Is the proportion of each decline in learning rate , The new learning rate is equal to the old learning rate multiplied by factor.patience Is the number of times you can tolerate , When patience Next time , Network performance has not improved , Will reduce the learning rate .threshold Is the threshold for measuring the best value , Generally, we only focus on relatively large performance improvements .min_lr Is the minimum learning rate ,eps Refers to the smallest change in learning rate , When the difference between the old and new learning rates is less than eps when , Keep the learning rate unchanged .
Because the parameters are relatively complex , Here you can see a complete code Practice .
scheduler=lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.5,patience=5,threshold=1e-4,threshold_mode='abs',cooldown=0,min_lr=0.001,eps=1e-8)
scheduler.step(val_score)