当前位置:网站首页>How to deploy pytorch lightning model to production
How to deploy pytorch lightning model to production
2020-11-08 21:03:00 【Computer and AI】

Mass service PyTorch Lightning A complete guide to the model .

Looking at the field of machine learning , One of the main trends is the proliferation of projects focused on applying software engineering principles to machine learning . for example ,Cortex It reproduces the experience of deploying server free but reasoning pipelines . Similarly ,DVC Modern version control and CI / CD The Conduit , But only for ML.
PyTorch Lightning With similar ideas , Only for training . The framework is PyTorch Provides Python Wrappers , It allows data scientists and engineers to write clean , Manageable and high performance training code .
As a build The whole person who deployed the platform , Part of the reason is that we hate to write templates , So we are PyTorch Lightning A loyal supporter of . In this spirit , I've sorted it out PyTorch Lightning Guidelines for model deployment to production environments . In the process , We are going to look at several derivations PyTorch Lightning Model to include options in the inference pipeline .
Deploy PyTorch Lightning Every method of reasoning by model
There are three ways to derive PyTorch Lightning Model launch :
-
Save the model as PyTorch checkpoint
-
Convert the model to ONNX
-
Export the model to Torchscript
We can go through Cortex For these three .
1. Package and deploy directly PyTorch Lightning modular
Start with the simplest way , Let's deploy a... Without any transformation steps PyTorch Lightning Model .
PyTorch Lightning Trainer Is an abstract template training code ( Think about training and validation steps ) Class , It has built-in save_checkpoint() function , This function will save your model as .ckpt file . To save the model as a checkpoint , Just add the following code to the training script :

Now? , Before we start serving this checkpoint , It should be noted that , Although I always say “ PyTorch Lightning Model ”, but PyTorch Lightning yes PyTorch The wrapper - Project README Literally means “ PyTorch Lightning It's just organized PyTorch.” therefore , The derived model is generic PyTorch Model , You can use... Accordingly .
With preserved checkpoints , We can do it in Cortex Easily serve the model in . If you are not familiar with it Cortex, Sure Get familiar with it quickly here , however Cortex A brief overview of the deployment process is :
-
We use Python We wrote a prediction for our model API
-
We are YAML What defines us in API Infrastructure and behavior
-
We use CLI Command deployment in API
Our prediction API Will use Cortex Of Python Predictor Class defines a init() Function to initialize our API And load the model , And use a define() Function to provide predictions at query time :

It's simple We've adapted some of the code from the training code , Added some reasoning logic , That's it . One thing to pay attention to is , If you upload the model to S3( recommend ), You need to add some logic to access it .
Next , We are YAML Configure infrastructure in :

Again , Simple . We gave it to us API Name it , tell Cortex Our prediction API Where is the , And allocate some CPU.
Next , We deploy it :
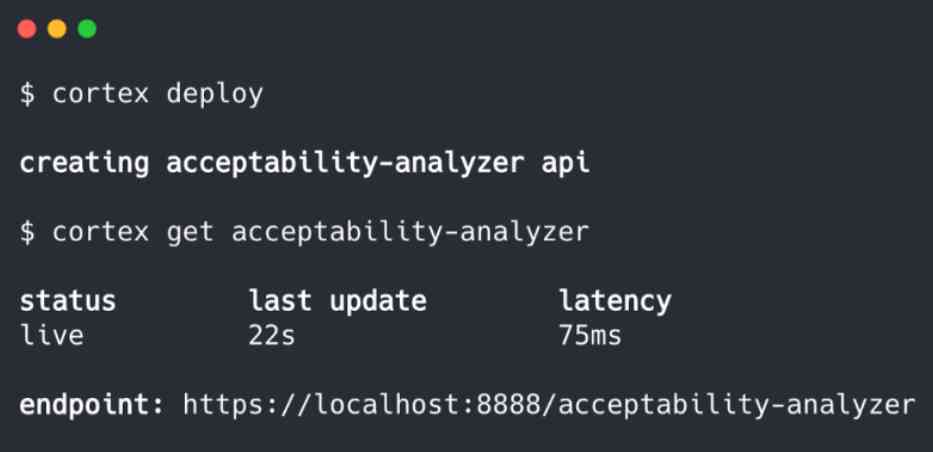
Please note that , We can also deploy to clusters , from Cortex Speed up and manage :
In all deployments ,Cortex Will container our API And make it public as Web service . Through cloud deployment ,Cortex Load balancing can be configured , Automatic extension , monitor , Updates and many other infrastructure features .
this is it ! Now? , We have a real-time Web API, Model predictions are available on request .
2. Export to ONNX And pass ONNX Launch at runtime
Now? , We've deployed a normal PyTorch checkpoint , Make things more complicated .
PyTorch Lightning Recently added a convenient abstraction , Used to export models to ONNX( before , You can use PyTorch The built-in conversion function of , Although they need more templates ). To export the model to ONNX, Just add the following code to your training script :

Please note that , Your input sample should mimic the shape of the actual model input .
export ONNX After the model , You can use Cortex Of ONNX Predictor To serve them . The code basically looks the same , And the process is the same . for example , This is a ONNX forecast API:
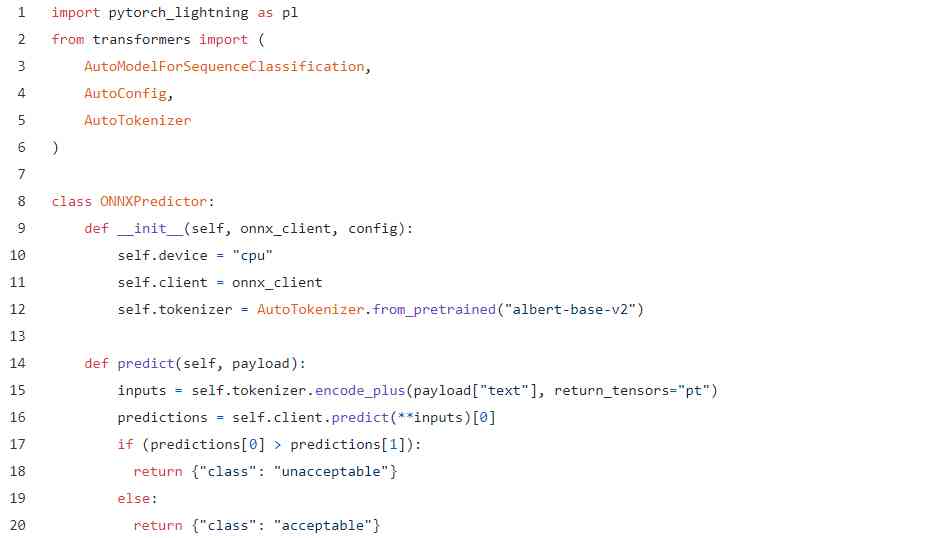
Basically the same . The only difference is , We don't initialize the model directly , But through onnx_client Access the data , This is a Cortex Launched to serve our model ONNX Runtime container .
our YAML It looks very similar :
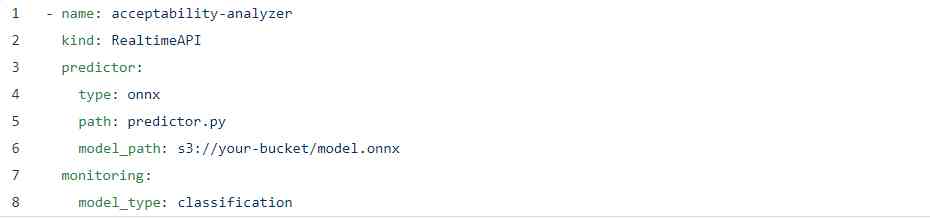
I've added a watch sign here , The purpose is just to show how easy the configuration is , And there are some ONNX Specific fields , But everything else is the same YAML.
Last , We use the same as before $ cortex deploy Command to deploy , And our ONNX API Enabled .
3. Use Torchscript Of JIT The compiler serializes
For the final deployment , We will PyTorch Lightning The model is exported to Torchscript And use PyTorch Of JIT The compiler provides services . To export the model , Just add it to your training script :

For this purpose Python API With primordial PyTorch The examples are almost the same :
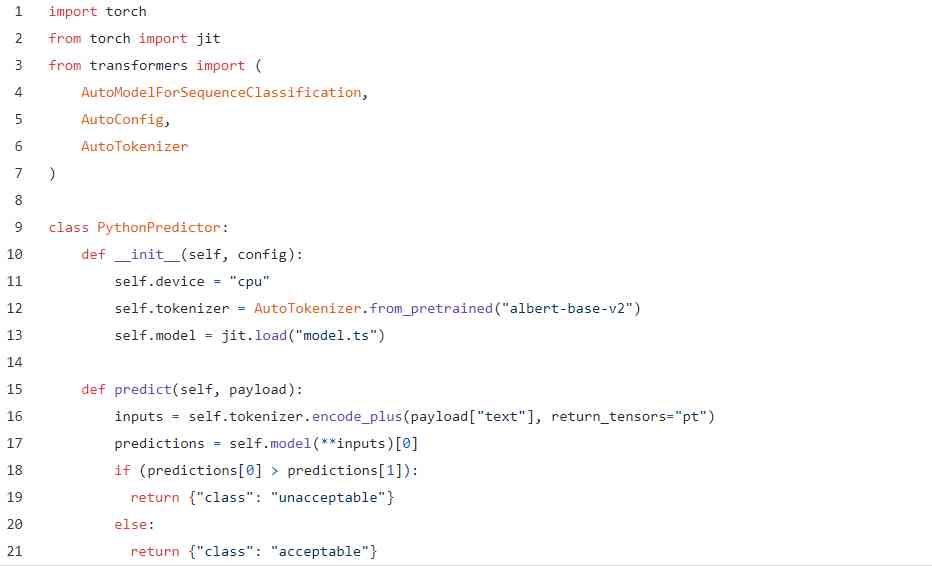
YAML Keep the same as before , also CLI The orders are, of course, consistent . If necessary , We can actually update our previous PyTorch API To use the new model , Just put the new and the old dictor.py The script is replaced by a new script , Then run... Again $ cortex Deploy :
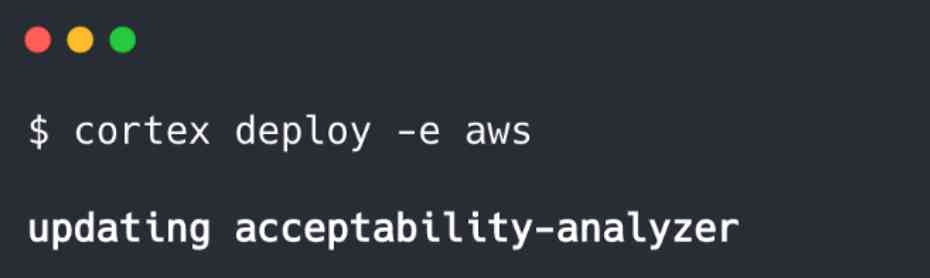
Cortex Automatically perform rollover here , In this update , new API Will be activated , And then with the old API In exchange for , This avoids any downtime between model updates .
That's all . Now? , You already have fully operational predictions for real-time reasoning API, According to the Torchscript Models provide predictions .
that , Which method should you use ?
The obvious question is which method works best . The fact is that , There is no simple answer here , Because it depends on your model .
about BERT and GPT-2 etc. Transformer Model ,ONNX Can provide incredible optimization ( We measured CPU Throughput improvement 了 40 times ). For other models ,Torchscript May be better than vanilla PyTorch Better - Although there are some caveats , Because not all models are exported cleanly to Torchscript.
Fortunately, , Deployment with any option is easy , You can test all three options in parallel , And see which way works best for your particular API.
If you like this article , Welcome to like forwarding ! thank you .
Don't go after watching, and there's a surprise !
I carefully organized the computer /Python/ machine learning / Deep learning is related to 2TB Video lessons and books , value 1W element . Pay attention to WeChat public number “ Computers and AI”, Click the menu below to get the online disk link .

版权声明
本文为[Computer and AI]所创,转载请带上原文链接,感谢
边栏推荐
- Looking for better dynamic getter and setter solutions
- Using annotation + interceptor to implement asynchronous execution
- Introduction and application of swagger
- Deep copy
- 选择排序
- Introduction and application of swagger
- 信息安全课程设计第一周任务(7条指令的分析)
- 实验一作业
- MYCAT build
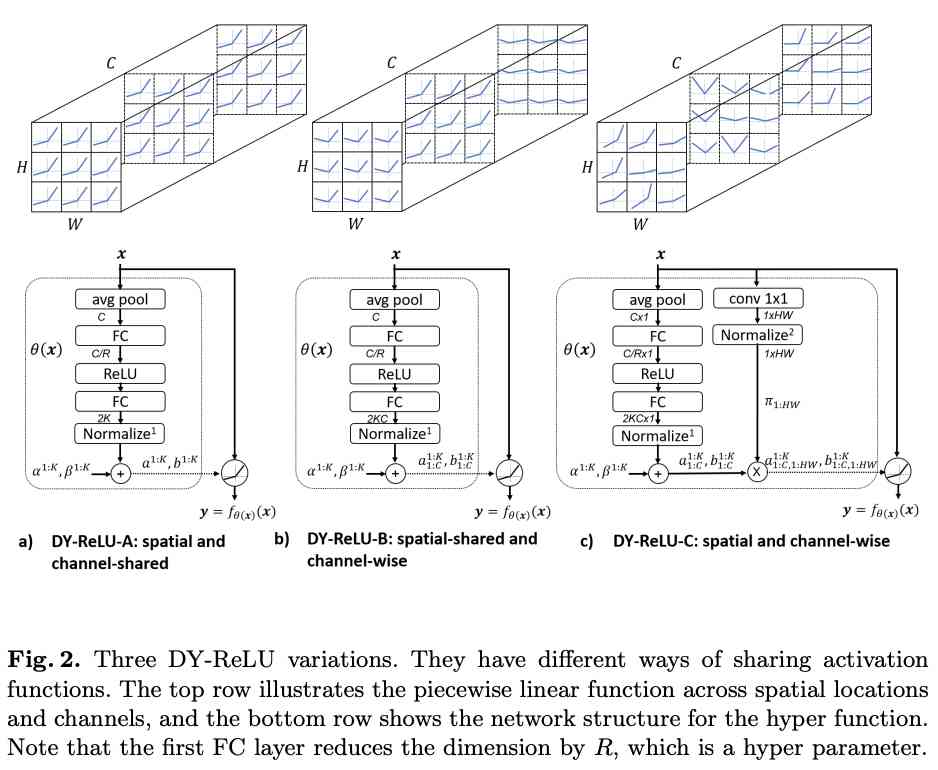
- Dynamic relu: Microsoft's refreshing device may be the best relu improvement | ECCV 2020
猜你喜欢


随机推荐
Suffix expression to infix expression
Swagger介绍和应用
接口测试用例思路总结
为什么需要使用API管理平台
Countdownlatch explodes instantly! Based on AQS, why can cyclicbarrier be so popular?
接口测试工具Eolinker进行post请求
Chapter five
简明 VIM 练级攻略
200 programmers interview experience, all here
Dynamic ReLU:微软推出提点神器,可能是最好的ReLU改进 | ECCV 2020
选择排序
【杂谈】JS相关的线程模型整理
进程 线程 协程
Wechat applet related
寻找性能更优秀的动态 Getter 和 Setter 方案
Using annotation + interceptor to implement asynchronous execution
Case analysis of entitycore framework
给大家介绍下,这是我的流程图软件 —— draw.io
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
JVM真香系列:轻松理解class文件到虚拟机(下)