当前位置:网站首页>ICML 2022 | explore the best architecture and training method of language model
ICML 2022 | explore the best architecture and training method of language model
2022-07-07 06:22:00 【PaperWeekly】

author | Zhuyaoming
Company | Byte beat Artificial Intelligence Lab
Research direction | Machine translation
This article introduces two articles published in ICML 2022 The paper of , Researchers are mainly from Google. Both papers are very practical analytical papers . It's different from the common papers' innovation in the model , Both papers are aimed at existing NLP The structure and training method of language model 、 Explore its advantages and disadvantages in different scenarios and summarize empirical rules .
Here, the author first collates the main experimental conclusions of the two papers :
1. The first paper found that although encoder-decoder It has occupied the absolute mainstream of machine translation , But when the model parameters are large , Design language model reasonably LM It can be compared with the traditional encoder-decoder The performance of architecture for machine translation tasks is comparable ; And LM stay zero-shot scenario 、 Better performance in small language machine translation 、 In large language machine translation, it also has off-target Fewer benefits .
2. The second paper found that I was not doing finetuning Under the circumstances ,Causal decoder LM framework +full language modeling Training in zero-shot The best performance in the task ; And there are multitasking prompt finetuning when , It is encoder-decoder framework +masked language modeling Training has the best zero-shot performance .

Paper 1
The first part mainly explores the traditional language model of language model in machine translation task (language model) How good it can be , Whether it can be compared with mainstream encoder-decoder rival .

Paper title :
Examining Scaling and Transfer of Language Model Architectures for Machine Translation
Thesis link :
https://arxiv.org/abs/2202.00528
The conference :
ICML 2022
Author organization :
University of Edinburgh 、Google
1.1 introduction
The author believes that at present encoder-decoder Architecture is the absolute mainstream in machine translation , However, people are not satisfied with the more pure language model (Language Model) There is not much research on Machine Translation , Its performance and advantages and disadvantages are rarely analyzed . The author explores various language model configurations for machine translation , And do a systematic performance analysis .
1.2 Method introduction
The author used for machine translation LM See the picture below ,X and Y Represents source language input and target language input respectively , The two make splicing input LM. In order to prevent information leakage during translation , The author will LM The original attention mask of is adjusted to prefix-LM Mask or casual-LM Mask , The black part is a mask mask( top left corner ). The lower right corner is and mainstream encoder-decoder Mask comparison .
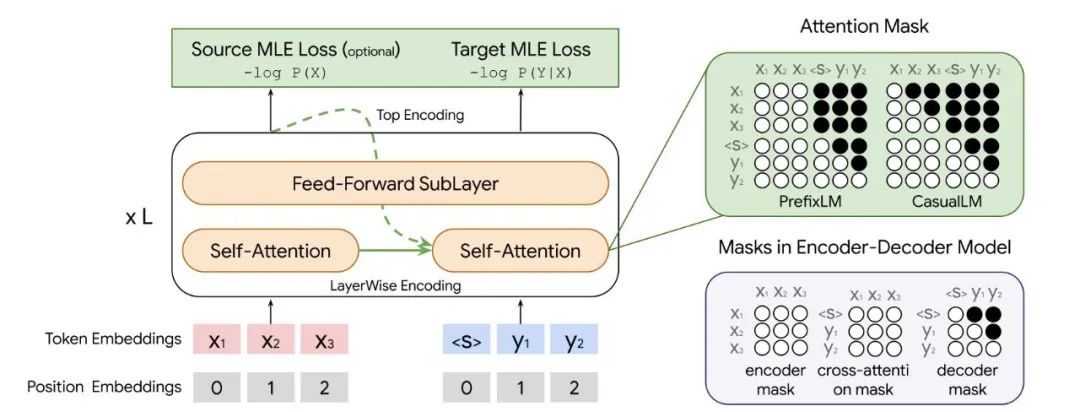
▲ The author used for translation LM. The main method is source language + Splice the target language , And in Attention Do on mask Masks prevent information disclosure .
In addition to two masking mechanisms , The author also compares TopOnly and layer-wise [1] Two representations , The former is the most common one, which only uses the top-level representation of neural network as the input of the output layer , The latter will coordinate the representation of each layer [1].
The author also compares TrgOnly Formal LM, such LM The loss function of only models the generation of target languages , Instead of modeling source side language generation .
1.3 Experimental exploration
The author's baseline model uses a similar Transformer-base The architecture of , stay WMT14 Britain and France 、 England and Germany ,WMT19 English/Chinese , And the main experiment on its own Yingde data set . The author also explored the effect of increasing the parameter quantity on LM Influence on Machine Translation .
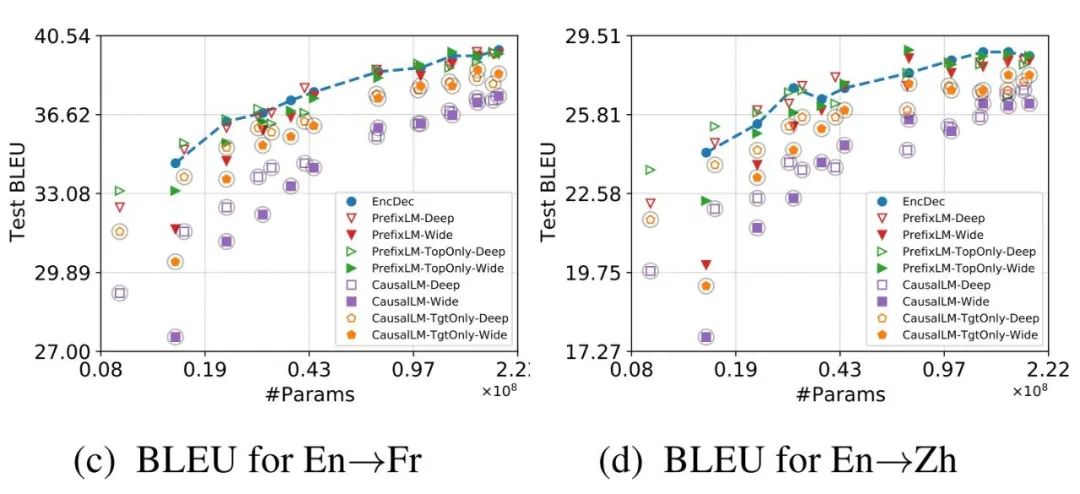
▲ Here are the most important experimental figures in this paper : On two datasets , Various LM Variants and encoder-decoder Of BLEU fraction - Parameter curve .
The author's main conclusions are listed below :
1. When the model parameters are small , Architecture has the greatest impact on Performance . here , have inductive biases The translation quality of the model is the best . What the author said inductive biases There are four main categories :1) similar prefix-LM Mask this source language side information is completely visible ;2) Use TopOnly Do output layer characterization instead of layer-wise;3) priority of use Deep LM instead of Wide LM;4)Loss Refers to modeling target language generation , Instead of modeling source side language generation .
2. Different models show different parameter characteristics , But this gap is narrowed when large-scale parameters are used .
3. Sentence sequence length is right LM The influence of parameter quantity characteristics is small .
4. Encoder-decoder The architecture is in computing efficiency ( With FLOPs To measure ) Better than all LM framework ( This also explains why the former is the absolute mainstream of machine translation ).
The author is still there zero-shot The scenario tested LM Performance in machine translation , The author found :
1. PrefixLM The mask is zero-shot The scene has a good performance .CausalLM Mask is not suitable zero-shot scene .
2. In low resource languages ,LM The performance of machine translation language migration is better than encoder-decoder framework .
3. In the performance of big language translation ,LM and decoder-encoder Each architecture has its merits . In general ,LM There are better zero-shot performance , When translating off-target( That is, the wrong language ) Even less .

Thesis 2
The second chapter explores large-scale pre training LM stay Zero-shot Performance of the scene , And discuss what architecture to use 、 What is the most effective pre training goal .
Paper title :
What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Thesis link :
https://arxiv.org/abs/2204.05832
Code link :
https://github.com/bigscience-workshop/architecture-objective
The conference :
ICML 2022
Author organization :
Google Brain, HuggingFace, LightOn, Allen NLP, LPENS
2.1 research objective
The author compares three architectures (causal decoder-only, non-causal decoder-only, encoder-decoder)、 Two pre training goals (autoregressive、masked language modeling) The trained language model is zero-shot stay zero-shot NLP Mission performance . The author also according to whether multitask prompted finetuning Step also divides the test into two scenarios .
2.2 Method introduction
The research method of this paper is very simple , Is to put causal decoder LM, non-causal decoder LM, encoder-decoder Three basic architectures and full language modeling( The most common LM Training ),masked language modeling( Instant belt mask The mechanism LM Training ) Two training methods do permutation and combination test performance .
meanwhile , In the evaluation phase , In addition to direct testing zero-shot Beyond performance , The author also tested the addition of multitask prompted finetuning after , Each model + The performance of training methods on new tasks . multitasking tune You can refer to this paper (T0) [2].
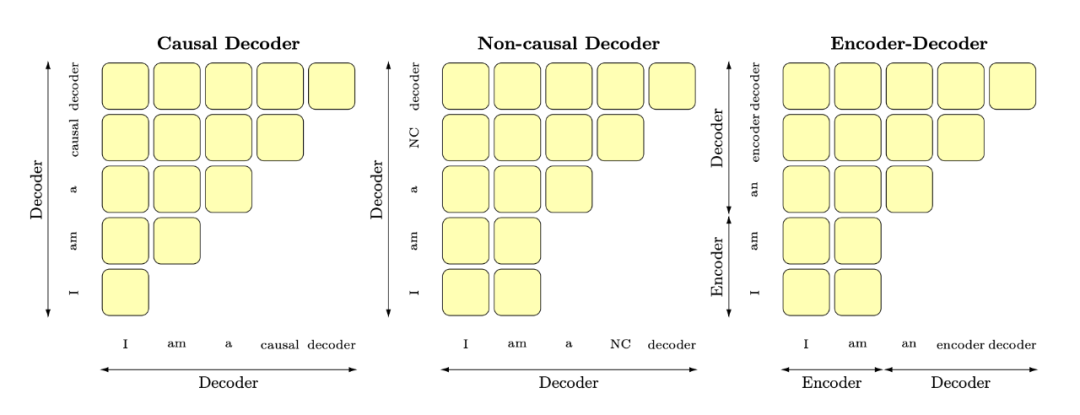
▲ The author's attention mechanism diagram of three basic architectures (attention map). in short ,causal decoder LM Only source sentence Each of them token To the front token do attention, The latter two are bidirectional attention Of .
2.3 Experimental exploration
The author's evaluation task is also a reference T0 The paper [2] and EleutherAI LM Evaluation Harness [3].( The authors note : these two items. benchmark A total of similar T5 and GPT-3 Such a large language model provides hundreds of evaluation tasks ).
There are many evaluation tasks , Here is just the conclusion of the author :
1. I'm not doing finetuning Under the circumstances ,Causal decoder LM framework +full language modeling Training can make the model have the best zero-shot Generalization performance . This conclusion is also consistent with the present GPT-3 This kind of model is in zero-shot NLG The amazing performance is consistent .
2. There is multitask finetuning Under the circumstances ,encoder-decoder framework +masked language modeling Training is the best zero-shot Generalization performance . The author also found that in a single task finetune Well behaved architectures tend to be multitask It's better to generalize in the scene .
3. Use only decoder Of LM Doing it adaptation perhaps task transfer when , Than encoder-decoder Less overhead 、 That is, it is easier to migrate tasks .

The author makes a brief comment on
Both papers are practical emprical study. Comprehensive speaking , The author believes that the previous article is more enlightening , The author explains that when the model is large enough , have only decorder Structural LM It can also complete machine translation tasks well . In addition to zero-shot Machine translation of ,LM Very good performance —— Consider that there has been a lot of work to prove LM It has extremely high generalization , Maybe LM Have become a very low resource language or minority language translation ( For example, classical Chinese Translation ) The potential of mainstream models . All in all ,LM The upper limit in the field of machine translation remains to be tapped .
The last one is Google A typical example of working miracles vigorously , The tone of the writing is more inclined to “ Plug and play ”, It can be used as a guide for relevant researchers or engineers to select models on demand . Actually, I'm a little curious Google Why choose in ICML’22 Publish this paper on , The author foolishly believes that this paper seems to be more consistent TACL or JAIR A kind of periodical .

reference
[1] https://proceedings.neurips.cc/paper/2018/hash/4fb8a7a22a82c80f2c26fe6c1e0dcbb3-Abstract.html
[2] https://arxiv.org/abs/2110.08207
[3] https://github.com/EleutherAI/lm-evaluation-harness
Read more




# cast draft through Avenue #
Let your words be seen by more people
How to make more high-quality content reach the reader group in a shorter path , How about reducing the cost of finding quality content for readers ? The answer is : People you don't know .
There are always people you don't know , Know what you want to know .PaperWeekly Maybe it could be a bridge , Push different backgrounds 、 Scholars and academic inspiration in different directions collide with each other , There are more possibilities .
PaperWeekly Encourage university laboratories or individuals to , Share all kinds of quality content on our platform , It can be Interpretation of the latest paper , It can also be Analysis of academic hot spots 、 Scientific research experience or Competition experience explanation etc. . We have only one purpose , Let knowledge really flow .
The basic requirements of the manuscript :
• The article is really personal Original works , Not published in public channels , For example, articles published or to be published on other platforms , Please clearly mark
• It is suggested that markdown Format writing , The pictures are sent as attachments , The picture should be clear , No copyright issues
• PaperWeekly Respect the right of authorship , And will be adopted for each original first manuscript , Provide Competitive remuneration in the industry , Specifically, according to the amount of reading and the quality of the article, the ladder system is used for settlement
Contribution channel :
• Send email :[email protected]
• Please note your immediate contact information ( WeChat ), So that we can contact the author as soon as we choose the manuscript
• You can also directly add Xiaobian wechat (pwbot02) Quick contribution , remarks : full name - contribute

△ Long press add PaperWeekly Small make up
Now? , stay 「 You know 」 We can also be found
Go to Zhihu home page and search 「PaperWeekly」
Click on 「 Focus on 」 Subscribe to our column
·

边栏推荐
- Rk3399 platform development series explanation (WiFi) 5.52. Introduction to WiFi framework composition
- c语言面试写一个函数在字符串N中查找第一次出现子串M的位置。
- Shared memory for interprocess communication
- Open the blue screen after VMware installation
- 那些自损八百的甲方要求
- 微信小程序隐藏video标签的进度条组件
- 字符串常量与字符串对象分配内存时的区别
- 屏幕程序用串口无法调试情况
- 改变ui组件原有样式
- JVM command - jmap: export memory image file & memory usage
猜你喜欢

Experience sharing of contribution of "management world"
![[SOC FPGA] peripheral PIO button lights up](/img/34/58728bddbf91eb69e9c0062dbfd531.jpg)
[SOC FPGA] peripheral PIO button lights up
Ctfshow-- common posture
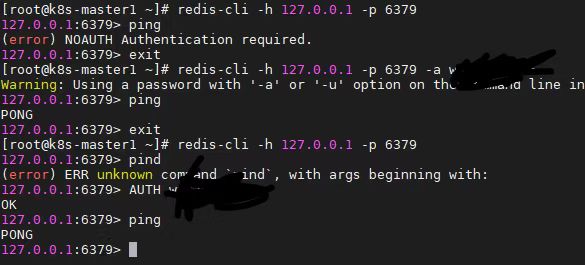
Redis(一)——初识Redis
Handling hardfault in RT thread

哈趣投影黑馬之姿,僅用半年强勢突圍千元投影儀市場!
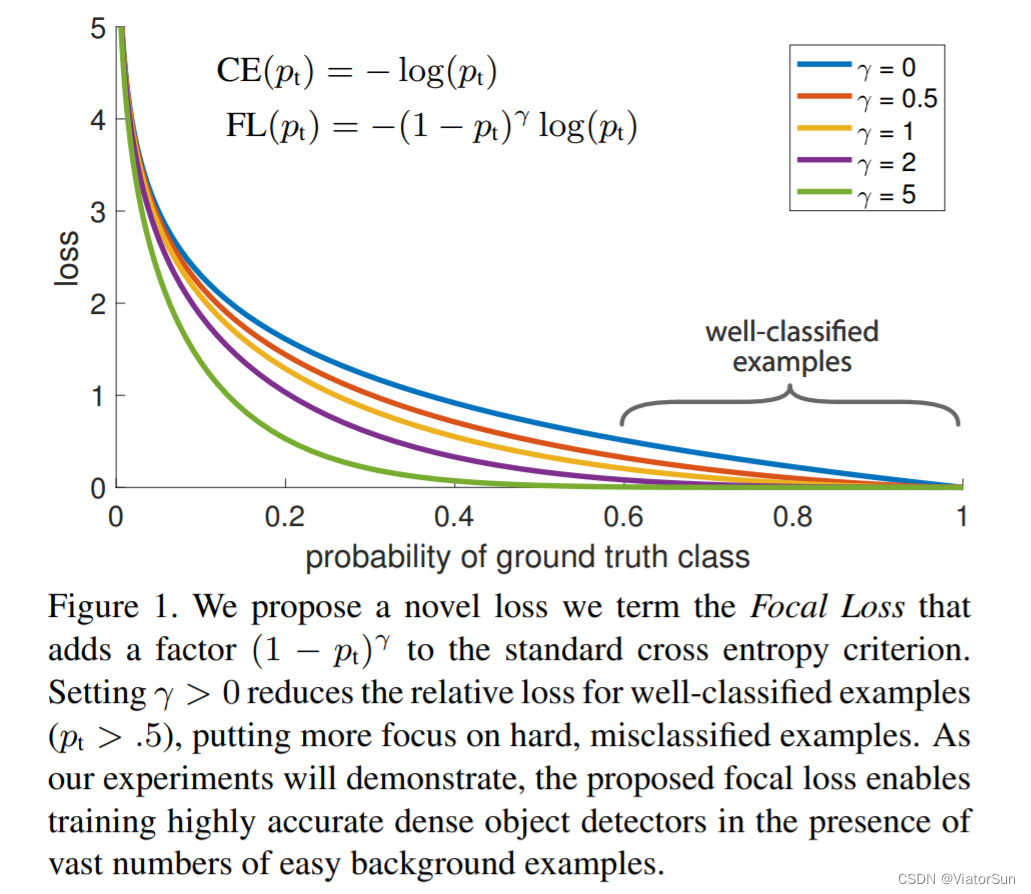
"Parse" focalloss to solve the problem of data imbalance

postgresql 数据库 timescaledb 函数time_bucket_gapfill()报错解决及更换 license
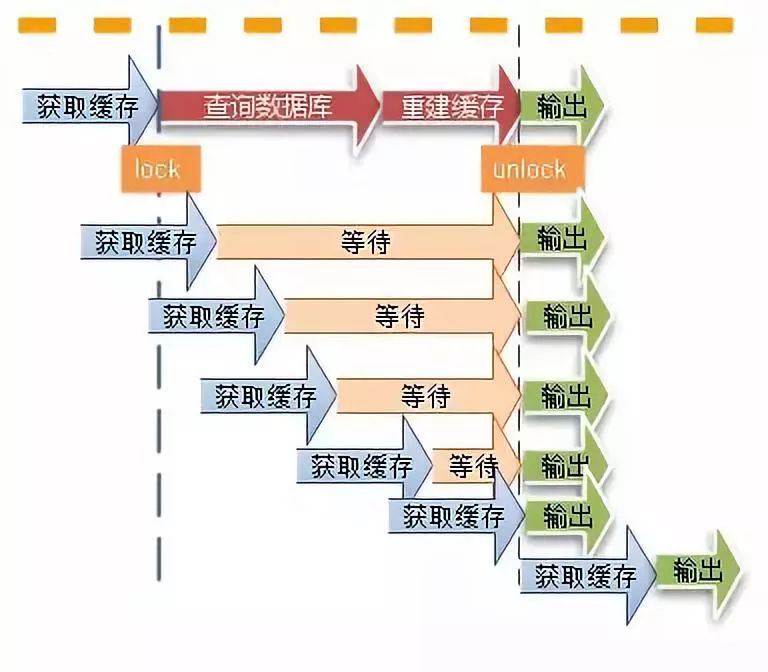
缓存在高并发场景下的常见问题
外设驱动库开发笔记43:GPIO模拟SPI驱动
随机推荐
ETCD数据库源码分析——从raftNode的start函数说起
Chain storage of stack
QT console output in GUI applications- Console output in a Qt GUI app?
Experience sharing of contribution of "management world"
【GNN】图解GNN: A gentle introduction(含视频)
Say sqlyog deceived me!
Symmetric binary tree [tree traversal]
外设驱动库开发笔记43:GPIO模拟SPI驱动
Jinfo of JVM command: view and modify JVM configuration parameters in real time
tkinter窗口选择pcd文件并显示点云(open3d)
Developers don't miss it! Oar hacker marathon phase III chain oar track registration opens
Rk3399 platform development series explanation (interruption) 13.10, workqueue work queue
k8s运行oracle
Party A's requirements for those who have lost 800 yuan
雷特智能家居龙海祁:从专业调光到全宅智能,20年专注成就专业
Understand the deserialization principle of fastjson for generics
Peripheral driver library development notes 43: GPIO simulation SPI driver
vim映射大K
基于ADAU1452的DSP及DAC音频失真分析
Three updates to build applications for different types of devices | 2022 i/o key review