当前位置:网站首页>flink+sklearn——使用jpmml实现flink上的机器学习模型部署
flink+sklearn——使用jpmml实现flink上的机器学习模型部署
2022-08-02 14:09:00 【虹夭】
目录
前言
flink1.12以后感觉真的香的一批,实时计算个人的使用感觉是比spark 的structured streaming要舒服的多。但是奈何还没有spark完善,尤其是在1.8以后,flinkML基本就处于不可用的状态(不知道是不是我没有找对文档,怎么最新的版本只有框架,没有模型啊喂)。
不过最后终于找到了jpmml的这个解决方案。简单来讲,pmml就是一个机器学习模型的中间格式,文件里面是用xml描述的。然后我们可以使用官方提供的sklearn2pmml库,在python中使用skearn训练好模型保存成.pmml文件,然后再java中使用jpmml读取文件来进行预测。
PMML概念
预言模型标记语言(Predictive Model Markup Language,PMML)是一种利用XML描述和存储数据挖掘模型的标准语言,它依托XML本身特有的数据分层思想和应用模式,实现了数据挖掘中模型的可移植性。
使用JPMML的操作步骤
训练模型——jpmml-sklearn
相关项目仓库
里面也有官方的使用案例,内容还挺丰富。
安装Python库
作者提供的对依赖包的要求,pip嗯安装就行了。
自己使用的时候sklearn是用conda安装过了,另外两个好像只有pip安装,这里设置了清华镜像源,速度提升很客观。
好像安装sklearn2pmml时会自动安装sklearn-pandas?应该是有依赖关系吧。
- Python 2.7, 3.4 or newer.
scikit-learn0.16.0 or newer.sklearn-pandas0.0.10 or newer.sklearn2pmml0.14.0 or newer.
pip install sklearn-pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install sklearn2pmml -i https://pypi.tuna.tsinghua.edu.cn/simple/
生成pmml模型三步曲
第一步——创建模型
创建模型不是乱创建
创建模型要使用sklearn2pmml为我们提供的工作流(pipeline)
工作流内需要存入二元组,(名称,模型对象)
二元组的名称也不是乱指定的,每个名称都是对应特定功能的transformer的,像"selector"对应特征选择,“mapper”对应特征预处理,”pca“对应pca,”classifier“对应分类器,”regressor“对应回归器。
乱创建虽然在python可能可以运行,但是生成pmml文件时可能会出错。
吐槽:能设置的名称其实不少,但是关于怎么设置这些二元组,作者都是在github上使用示例代码给出的,挺多使用方法分散在项目的不同角落(主要是README),找起来还挺费劲(估计都是用到了才会仔细一点一点搜,要不就在issue直接问作者了),而且也没统一的文档什么的。(可能作者觉得自己写的那些使用说明很详细,大家都能在各种链接之间跳来跳去找到问题的答案)
使用方法大多在项目的README里面可以找到,下面只演示我之前做过的内容。
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml.decoration import ContinuousDomain
from sklearn2pmml import sklearn2pmml,SelectorProxy
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.feature_selection import VarianceThreshold
mapper = mapper = DataFrameMapper([
(X.columns.to_list(), [ContinuousDomain(with_data = False),StandardScaler()]),
])
params = {
"n_estimators":88,"random_state":420}
classifier = RandomForestClassifier(**params)
pipeline = PMMLPipeline([
("mapper",mapper),
("selector", SelectorProxy(VarianceThreshold())),
("classifier", classifier),
])
要对指定特征就行预处理需要用到mapper
DataFrameMapper中传入二元组列表,前面是指定的列名,可以是多个,后面是处理方式。上面演示的是标准缩放,也可以进行行独热编码。
ContinuousDomain是这个库特色的特征装饰器,这个是对连续型特征进行装饰
- 装饰器主要作用就是能进行一些错误值、空值和离群点的处理。
- 还有其他像是”顺序特征“,”分类特征“,”时间特征“的装饰器,具体可以看官方说明
- 比较坑的一点是,连续型特征的装饰器会学习训练数据,分析离群点,然后在预测的时候会强制将离群点判定为非法值,从而导致预测的时候可能会发生拒绝接受特征的报错。这里再里设置
with_data = False可以避免这个问题。- with_data是设置是否要再训练时对数据进行分析(分析离群点)
- 作者这样设计好像是因为,他认为模型不应该预测不在接受范围内的值,所以强迫你对离群点啊什么的进行处理。
使用selector需要使用SelectorProxy对feature_selection下的对象进行包裹。
第二步——训练模型
训练模型主要需要进行两个操作,一个是fit训练,另一个是verify验证
- 如果在创建pipeline时加入训练好的模型而不进行fit,pipeline也能工作,但是PMMLPipline的
active_fields这个字段无法被激活,进行verify会不通过。然后就是之前提到的,这个库对每个特征进行自动的分析的功能无法进行。- 总之一定要使用这个库提供的PMMLPipeline创建模型进行训练。
- verify是对模型进行验证。这一步非常重要,需要注意以下两点:
- 验证实际上不单单是验证,在把模型部署到java上以后,模型会用你提供的验证数据进行预热,从而提高实际运行时的预测速度。
- **进行验证的的数据不要太多,放15条训练数据差不多。**之前不知道这一步是干什么,傻傻的把整个训练集放进去验证,然后java上模型加载半天加载不出来,原来是一直在用训练集数据预热啊。
pipeline.fit(X,y)
pipeline.verify(X.sample(15))
第三步——保存模型
from sklearn2pmml import sklearn2pmml
sklearn2pmml(pipeline, "StayAlertRFC.pmml", with_repr = True)
回归任务演示代码
部署模型——jpmml-evaluator
maven依赖
这里推荐使用maven项目,里面pmml的相关依赖有这些。
<pmml.version>1.5.15</pmml.version>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>${pmml.version}</version>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator-extension</artifactId>
<version>${pmml.version}</version>
</dependency>
读取模型
生成的模型可以放在项目的资源路径下,方便之后打包。
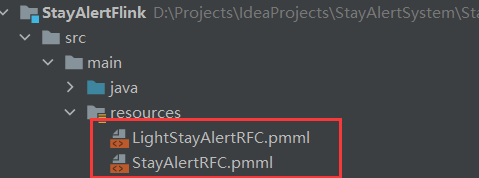
package xyz.hyhy.stayalert.flink.utils;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.jpmml.evaluator.Evaluator;
import org.jpmml.evaluator.InputField;
import org.jpmml.evaluator.LoadingModelEvaluatorBuilder;
import org.xml.sax.SAXException;
import javax.xml.bind.JAXBException;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@Slf4j
public class PMMLUtils {
public static void main(String[] args) throws IOException, JAXBException, SAXException {
Evaluator evaluator = loadEvaluator("/StayAlertRFC.pmml");
// Printing input (x1, x2, .., xn) fields
List<? extends InputField> inputFields = evaluator.getInputFields();
Map<String, Object> obj2 = JSONObject.parseObject("{\"V11\":33.7824}");
Double d = (Double) obj2.get("V11");
inputFields.get(3).prepare(d);
}
/** * 载入PMML模型的方法 * * @param pmmlFileName * @return * @throws JAXBException * @throws SAXException * @throws IOException */
public static Evaluator loadEvaluator(String pmmlFileName) throws JAXBException, SAXException, IOException {
Evaluator evaluator = new LoadingModelEvaluatorBuilder()
.load(PMMLUtils.class.getResourceAsStream(pmmlFileName))
.build();
evaluator.verify(); //自校验——预热模型
log.info("StayAlert分类评估器自校验&预热完成");
return evaluator;
}
}
这里使用LoadingModelEvaluatorBuilder载入模型,注意load()方法可以传入File类型也可以传入InputStream类型,这里一定要使用PMMLUtils.class.getResourceAsStream(pmmlFileName)来获取文件流传入参数,使用getResource在idea上可能可以用,但是打包部署到linux上就不行啦。
读取文件Evaluator evaluator = loadEvaluator("/StayAlertRFC.pmml");
- 路径前面要加斜杠
/
进行预测
package xyz.hyhy.stayalert.flink.prediction;
import org.dmg.pmml.FieldName;
import org.jpmml.evaluator.Evaluator;
import org.jpmml.evaluator.EvaluatorUtil;
import org.jpmml.evaluator.FieldValue;
import org.jpmml.evaluator.InputField;
import org.xml.sax.SAXException;
import xyz.hyhy.stayalert.flink.utils.PMMLUtils;
import javax.xml.bind.JAXBException;
import java.io.IOException;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class StayAlertPredictor {
private Evaluator evaluator;
private List<InputField> inputFields;
public StayAlertPredictor() throws IOException, JAXBException, SAXException {
evaluator = PMMLUtils.loadEvaluator("/LightStayAlertRFC.pmml");
inputFields = evaluator.getInputFields();
}
public Boolean predict(Map<String, ?> inputRecord) {
if (inputRecord == null) {
throw new NullPointerException("预测程序不能输入空的记录");
}
Map<FieldName, FieldValue> arguments = new LinkedHashMap<>();
// 从数据源模式到PMML模式逐字段映射记录
for (InputField inputField : inputFields) {
FieldName inputName = inputField.getName();
Object rawValue = inputRecord.get(inputName.getValue());
Double doubleValue = Double.parseDouble(rawValue.toString());
// 将任意用户提供的值转换为已知的PMML值
FieldValue inputValue = inputField.prepare(doubleValue);
arguments.put(inputName, inputValue);
}
// 用已知的特征来评估模型
Map<FieldName, ?> results = evaluator.evaluate(arguments);
// 解耦结果来自jpmml-evaluator运行时环境
Map<String, ?> resultRecord = EvaluatorUtil.decodeAll(results);
//获取并返回预测结果
Integer isAlert = (Integer) resultRecord.get("IsAlert");
return isAlert == 1;
}
}
在Flink中使用
package xyz.hyhy.stayalert.flink.task;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.util.Collector;
import org.xml.sax.SAXException;
import xyz.hyhy.stayalert.flink.pojo.UserDataPOJO;
import xyz.hyhy.stayalert.flink.prediction.StayAlertPredictor;
import javax.xml.bind.JAXBException;
import java.io.IOException;
public class StayAlertPredictTask {
private static StayAlertPredictor predictor;
static {
try {
predictor = new StayAlertPredictor();
} catch (IOException e) {
e.printStackTrace();
} catch (JAXBException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
}
}
private StayAlertPredictTask() {
}
public static SingleOutputStreamOperator<UserDataPOJO> predict(DataStream<UserDataPOJO> ds) {
return ds.flatMap(new FlatMapFunction<UserDataPOJO, UserDataPOJO>() {
@Override
public void flatMap(UserDataPOJO userDataPOJO,
Collector<UserDataPOJO> collector) throws Exception {
try {
//判断是否分心
boolean isAlert = predictor.predict(userDataPOJO.getDeviceFeature());
userDataPOJO.setIsAlert(isAlert);
collector.collect(userDataPOJO);
userDataPOJO.setIsAlert(null);
} catch (Exception e) {
e.printStackTrace();
}
}
});
}
}
这里封装了一个创建计算流的方法,把预测模型弄成静态类,直接在算子里面使用就是了。
总结
个人感想
这次用下来,个人就有一些小小的感受(无关紧要哈,主要是使用前有疑惑所以想到的一些事项):
- java中载入的预测模型是一次预测一条数据的,就很适合flink的流计算。
- 生成的.pmml模型很大,像生成的88个评估器的随机森林模型就有二百多M,不过打包成jar包后经过压缩,实际只有13M左右了
- 感觉使用pmml后比之前使用sparkml还爽,首先就是在python上训练,然后就是支持的模型更多了,像sparkML之前用的时候好像不支持随机森林的说。
- 然后就是使用sklearn2pmml在整合数据预处理流程的工作上还是挺灵活的,能做的事情比较多。
其他说明
这个项目是之前做的一个flink大作业,博客里主要是和pmml使用相关的代码,完整代码有兴趣的可以到这里下载。
边栏推荐
- Do Windows 10 computers need antivirus software installed?
- 【我的电赛日记(一)】HMI USART串口屏
- 发布模块到npm应该怎么操作?及错误问题解决方案
- Win10电脑不能读取U盘怎么办?不识别U盘怎么解决?
- win10怎么设置不睡眠熄屏?win10设置永不睡眠的方法
- [论文阅读] ACT: An Attentive Convolutional Transformer for Efficient Text Classification
- 机器学习和深度学习中的梯度下降及其类型
- DP4344兼容CS4344-DA转换器
- ARMv8虚拟化
- 系统线性、时不变、因果判断
猜你喜欢
语言模型(NNLM)
PyTorch④---DataLoader的使用

Win11 computer off for a period of time without operating network how to solve
Win10 Settings screen out from lack of sleep?Win10 set the method that never sleep

循环神经网络RNN 之 LSTM
PyTorch⑦---卷积神经网络_非线性激活

为android系统添加产品的过程
PyTorch①---加载数据、tensorboard的使用
Win11声卡驱动如何更新?Win11声卡驱动更新方法
将SSE指令转换为ARM NEON指令
随机推荐
FP7126降压恒流65536级高辉无频闪调光共阳极舞台灯RGB驱动方案
使用预训练语言模型进行文本生成的常用微调策略
日常-笔记
TypeScript 快速进阶
【使用Pytorch实现ResNet网络模型:ResNet50、ResNet101和ResNet152】
Win7 encounters an error and cannot boot into the desktop normally, how to solve it?
Win10上帝模式干嘛的?Win10怎么开启上帝模式?
图像配置分类及名词解释
Win7怎么干净启动?如何只加载基本服务启动Win7系统
PyTorch(12)---损失函数和反向传播
source /build/envsetup.sh和lunch)
机器学习和深度学习中的梯度下降及其类型
神经网络可以解决一切问题吗:一场知乎辩论的整理
基于GPT的隐变量表征解码结构
Win10 can't start WampServer icon is orange solution
【我的电赛日记(完结)---2021全国大学生电子设计竞赛全国一等奖】A题:信号失真度测量装置
ASR6601牛羊定位器芯片GPS国内首颗支持LoRa的LPWAN SoC
Fast advanced TypeScript
什么是外生变量和内生变量
How to add a one-key shutdown option to the right-click menu in Windows 11