当前位置:网站首页>Robot reinforcement learning synergies between pushing and grassing with self supervised DRL (2018)
Robot reinforcement learning synergies between pushing and grassing with self supervised DRL (2018)
2022-07-04 23:31:00 【Qianyu QY】
Address of thesis :https://ieeexplore.ieee.org/document/8593986
1 brief introduction
model-free Reinforcement learning ,Q-learning
Method : Train two networks , Predict pixel level push Of Q-value and Pixel level grasp Of Q-value;Q-value The highest push or grasp Be performed .
Every pixel point push Is defined as pushing from left to right 10cm;grasp Is defined as centered on this point ,10cm For grab width , Horizontal grab .
At testing time , The image is rotated 16 Time , Sent to the network respectively , Therefore, it can be realized 16 From two angles push and grasp.
In this paper High dimensional action, That is, grasp posture and push ;QT-Opt And so on Lower dimensional action, That is, the end offset .
High dimensional action stay Full drive system It's possible , Full drive means that the motion of an object is completely controlled by a manipulator , Such as the capture of this article ;
Low dimension action More suitable for Underactuated system , It needs to be adjusted in real time according to the system feedback action, Finally reach the goal state . Underdrive means that the motion of an object is determined by the environment and the manipulator at the same time , Such as pre crawl 、 Push objects along the track .
2 Method
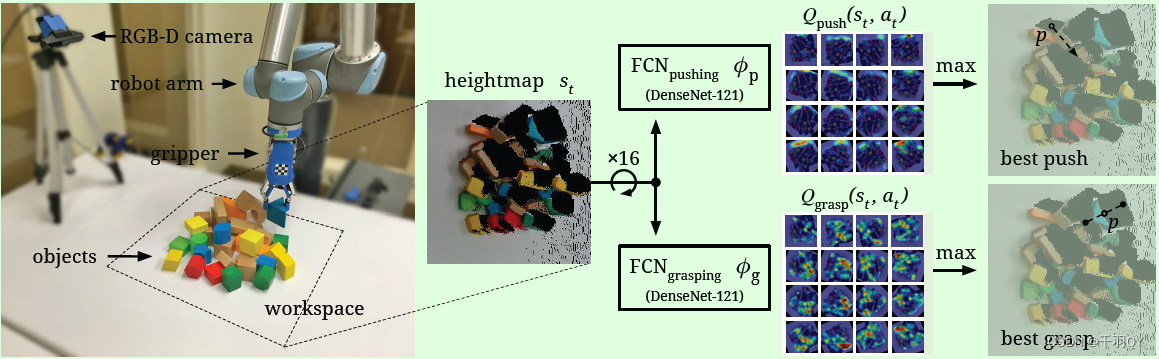
state:RGB-D Images
action: Describe in Section 1
grasp reward: Capture success reward=1. If the opening length of the gripper of the manipulator is greater than the threshold , Then the capture is successful .
push reward: The difference between scene images is greater than the threshold reward=0.5. The reward encourage push Action changes the scene , But it doesn't explicitly make future crawling more convenient .
Q Network structure : The structure of the two networks is the same . First, we will RGB Images and D Images are sent in parallel DenseNet, Then merge features , Output prediction by convolution and difference up sampling Q-value.
1、 How to give push Set up reward
answer : The difference between scene images is greater than the threshold reward=0.5. The reward encourage push Action changes the scene , But it doesn't explicitly make future crawling more convenient .
2、 How to train pixel level prediction network
answer : Execution only action Pixels of p Calculate the gradient , For all other 0
3 idea
1、 In essence, the method of this paper is supervised learning , Just put grasp/push The confidence label of is replaced by reward, It's essentially the same
边栏推荐
- 可观测|时序数据降采样在Prometheus实践复盘
- 如何将自己的代码作品快速存证,已更好的保护自己劳动成果
- Advantages of Alibaba cloud international CDN
- French scholars: the explicability of counter attack under optimal transmission theory
- 用快解析内网穿透实现零成本自建网站
- List related knowledge points to be sorted out
- PMP证书续证流程
- Pict generate orthogonal test cases tutorial
- 电力运维云平台:开启电力系统“无人值班、少人值守”新模式
- CTF競賽題解之stm32逆向入門
猜你喜欢

Hong Kong Jewelry tycoon, 2.2 billion "bargain hunting" Giordano
How to use fast parsing to make IOT cloud platform
The difference between cout/cerr/clog
Stm32 Reverse Introduction to CTF Competition Interpretation
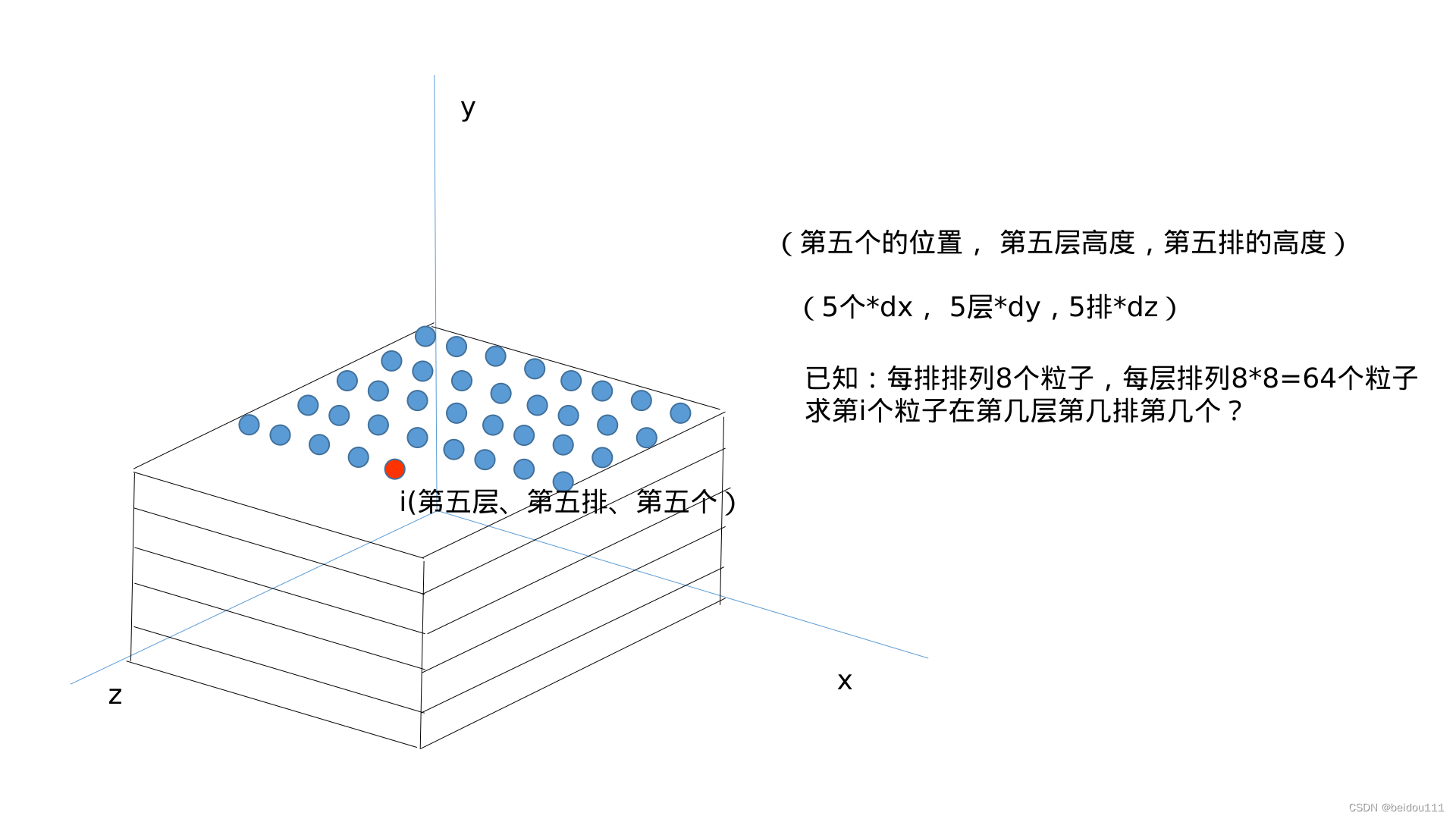
SPH中的粒子初始排列问题(两张图解决)
Jar批量管理小工具
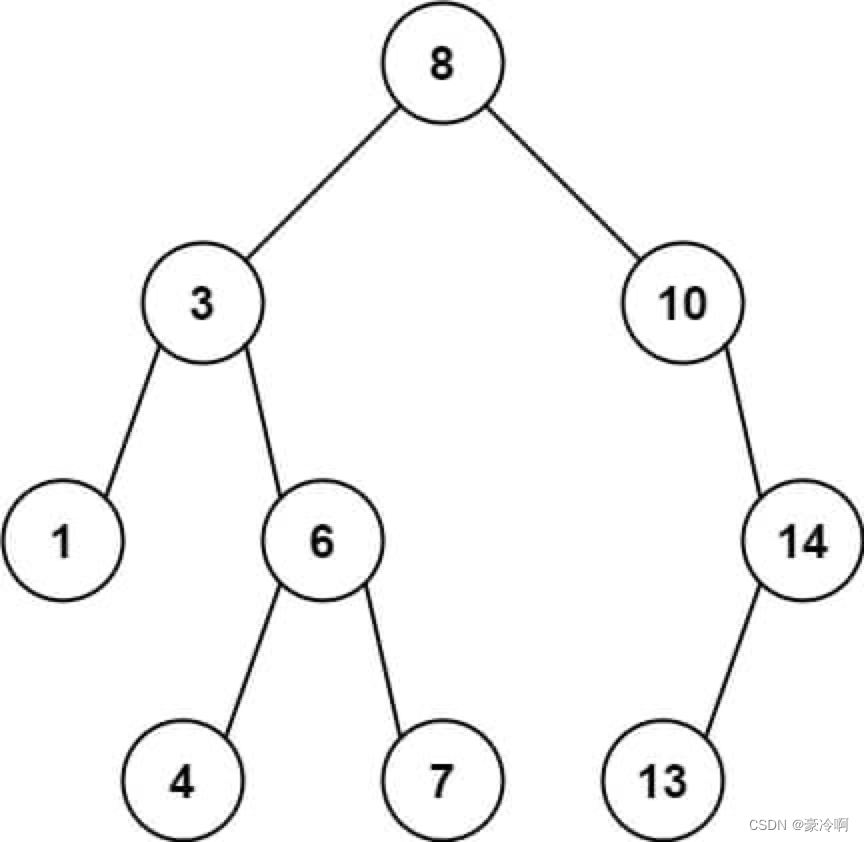
【二叉树】节点与其祖先之间的最大差值

OSEK standard ISO_ 17356 summary introduction
CTF competition problem solution STM32 reverse introduction
![[kotlin] the third day](/img/c4/1bf1b00c4a1dda920ad3bb178ac0f9.png)
[kotlin] the third day
随机推荐
Build your own minecraft server with fast parsing
高通WLAN框架学习(30)-- 支持双STA的组件
debug和release的区别
ICML 2022 || 3DLinker: 用于分子链接设计的E(3)等变变分自编码器
The initial arrangement of particles in SPH (solved by two pictures)
Mysql database backup and recovery -- mysqldump command
CTF競賽題解之stm32逆向入門
Using the uniapp rich text editor
ScriptableObject
colResizable. JS auto adjust table width plug-in
取得PMP證書需要多長時間?
go踩坑——no required module provides package : go.mod file not found in current directory or any parent
Network namespace
端口映射和端口转发区别是什么
The caching feature of docker image and dockerfile
JS 将伪数组转换成数组
如何在外地外网电脑远程公司项目?
Galera cluster of MariaDB - dual active and dual active installation settings
The difference between cout/cerr/clog
heatmap. JS picture hotspot heat map plug-in