Preface
In recent days, , Top level conference on computer vision and pattern recognition CVPR Held in New Orleans, USA , At the same time, it is the most influential global top event in the field of computer image restoration NTIRE Award at the meeting , Netease Yunxin audio and video laboratory obtained NTIRE High efficiency super-resolution challenge overall performance track champion , And the running time is the third place of the track . This article will focus on AI The landing problem of super separation technology from research to deployment , Introduce the current situation of super-resolution Technology , And the opportunities and challenges faced by the application of video hyperscore on the mobile terminal .


Overview of super-resolution Technology
In recent years , Internet video data is growing explosively . meanwhile , The resolution of video is getting higher and higher , To meet people's quality of video experience (Quality of Experience, QoE) Growing demand . however , Due to the limitation of bandwidth , Video transmitted over the network is usually downsampled and compressed , This will inevitably lead to the decline of video quality , And then affect the user's experience and appearance . Hyperspectral technology aims to recover high-resolution output with better visual quality from low-resolution input , It can effectively solve the problem of poor video quality , So as to meet the needs of users at the playback end for extreme HD image quality . Live on demand 、 Monitoring equipment 、 Video codec 、 Cell phone shooting 、 Medical imaging 、 Digital HD and video restoration have very important application value .

Classification and development direction of super-resolution Technology
In a broad sense, super-resolution technology includes 3 In this case :
Single image super-resolution
、
Super resolution reconstruction of single frame image from multi frame continuous image
、
Super resolution reconstruction of video sequence
.
Single image amplification mainly uses the prior knowledge of high-resolution images and high-frequency information in the form of aliasing to restore . In the latter two cases, in addition to using prior knowledge and single image information , The complementary information between adjacent images can also be used for super-resolution reconstruction , Get a high-resolution image with higher resolution than any low resolution image , However, these two situations often bring unacceptable computational costs and the risk of discontinuous reconstruction of adjacent frames . therefore , On actual landing , Prefer single image super-resolution Technology .
Classify according to time and effect , Single image super-resolution algorithms can be divided into
Traditional algorithms
and
Deep learning algorithm
Two types of .
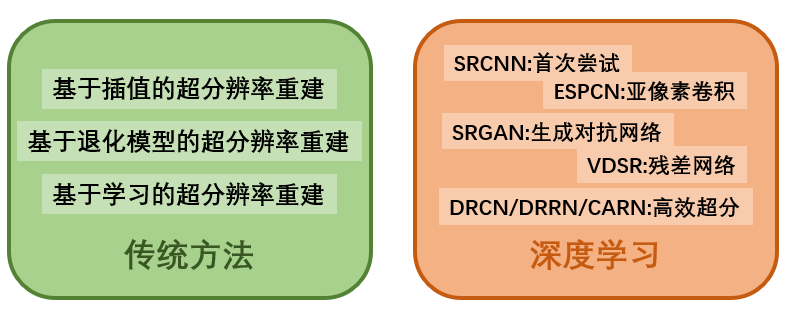
Traditional super-resolution reconstruction algorithm
Traditional super-resolution reconstruction algorithms mainly rely on basic digital image processing technology for reconstruction , The common ones are as follows :
Super resolution reconstruction based on interpolation :
Based on interpolation, each pixel in the image is regarded as a point on the image plane , Then the estimation of super-resolution image can be seen as the process of fitting the known pixel information to the unknown pixel information on the plane , This is usually done by a predefined transform function or interpolation kernel . The method based on interpolation is simple 、 Easy to understand , But there are obvious defects . The restored image is often blurred 、 Sawtooth, etc . Common interpolation based methods include nearest neighbor interpolation 、 Bilinear interpolation and bicube interpolation .
Super resolution reconstruction based on degenerate model :
This kind of method starts from the degradation model of image , It is assumed that the high-resolution image has undergone appropriate motion transformation 、 Blur and noise to get a low resolution image . This method extracts key information from low resolution images , Combined with the prior knowledge of unknown super-resolution image, the generation of super-resolution image is constrained . Common methods include iterative back projection 、 Convex set projection method and maximum a posteriori probability method .
Super resolution reconstruction based on learning :
The learning based method is to use a large amount of training data , Learn some correspondence between low resolution images and high resolution images , Then the high-resolution image corresponding to the low-resolution image is predicted according to the learned mapping relationship , So as to realize the super-resolution reconstruction process of the image . Common learning based methods include manifold learning 、 Sparse coding method .
Super resolution reconstruction algorithm based on deep learning
SRCNN It is the first attempt of deep learning method in super-resolution problem , It's a simple convolution network , from 3 It's made up of two convolution layers , Each convolution layer is responsible for different functions . The first convolution layer is mainly responsible for extracting high-frequency features , The second convolution layer is responsible for nonlinear mapping from low definition features to high definition features , Finally, the role of the convolution layer is to reconstruct high-resolution images .SRCNN Our network structure is relatively simple , The super-resolution effect also needs to be improved , However, it establishes the basic idea of deep learning method in dealing with super-resolution problems . The later deep learning method , Basically follow this idea to carry out super-resolution reconstruction .
Later, ESPCN be based on SRCNN Some improvements have been made , However, due to the limited capacity of network reconstruction , The super-resolution effect is not particularly ideal . Because at that time , There are some problems in the training of deep convolution network . In general, for convolutional neural networks , As the number of network layers increases , Performance will also increase , But in practice , People find that when the number of network layers increases to a certain extent , Because of the back propagation principle , There will be the problem of gradients disappearing , The convergence of the network becomes worse , Reduced model performance . This question goes on until ResNet After putting forward the residual network structure , To get a better solution . But it is worth noting that ,ESPCN The sub-pixel convolution layer is proposed for the first time in the network , It eliminates the pre acquisition operation before the low resolution image is sent to the neural network , Greatly reduced SRCNN Amount of computation , Improved reconstruction efficiency .
VDSR It is the first application of residual network and residual learning in super-resolution problem , Increase the number of super-resolution layers to the first time 20 layer . Using residual learning , Residual characteristics of network learning , The network converges fast , Be more sensitive to details . Later, some convolutional neural networks proposed more complex structures , such as RGAN This paper proposes to use generative countermeasure network to generate high resolution image ,SRGAN from 2 Part of it is made up of , One is generating networks , The other is the discriminant network . The function of generating network is to generate a high resolution image based on a low resolution image , The function of discriminant network is to judge the high resolution image generated by the generated network as false , So when the network is training , There is a constant game between the generation network and the decision network , And finally to balance , So as to generate a high resolution image with realistic detail texture , It has better subjective visual effect . Other deep convolution network methods, such as SRDenseNet、EDSR、RDN, Using a more complex network structure , The convolution layer of the network is getting deeper and deeper , The super-resolution effect on single image is also getting better and better .
However , Due to high computing costs and memory consumption , Many jobs are difficult to deploy on equipment with limited resources . So , Super-resolution and efficient model design has also attracted widespread attention .FSRCNN Adopt a compact hourglass architecture to accelerate for the first time SR The Internet ;DRCN and DRRN The recursive layer is used to build a deep network with fewer parameters .CARN By combining effective residual blocks with group convolution , Less SR Network computing . Attention mechanism is also introduced to find the area with the largest amount of information , To better reconstruct high-resolution images . in addition , Knowledge distillation has also been cited in lightweight super-resolution networks , To improve their performance .
The challenge of real-time video super-resolution
In the era of mobile Internet , As the most important platform for video content, mobile terminal , Responsible for a large number of PGC and UGC Playback of video content , But limited by the insufficient generalization ability of the model , The computing power of the mobile terminal is limited , The algorithm has high computational complexity , be based on AI The following characteristics of super-resolution algorithm make it face great challenges in real-time deployment on mobile terminals :
The subjective effect is poor , Directly use the above-mentioned super-resolution algorithm based on deep learning , You will find its subjective effect and Bicubic Such as traditional algorithms , The effect of improving video quality is very limited .
educational circles SOTA Method the network model parameters are too large , Even many networks that are lightweight , Parameter quantities are also greater than 500K, This leads to excessive computation of the model , Reasoning is slow , It cannot meet the requirements of real-time video processing on mobile terminals .
Yunxin AI Over score
Training data based on real down sampling
The existing training data of super-resolution algorithm based on deep learning , Often through Bicubic Or other known down sampling methods . However, the real scene is often not , As a result, there is a large gap between the model training data and the actual prediction data , So the effect of the super score algorithm is not ideal .
We adopt a real down sampling generation method which is also based on the confrontation generation network . As shown in the figure below , For a high resolution image , Let's train the sampling generator G Discriminator D, bring G The generated low resolution image is close to the real low resolution image , So as to get the real down sampling G. Got it G Later, we can use high-resolution images to generate a large number of training data pairs that meet the degradation of real down sampling .
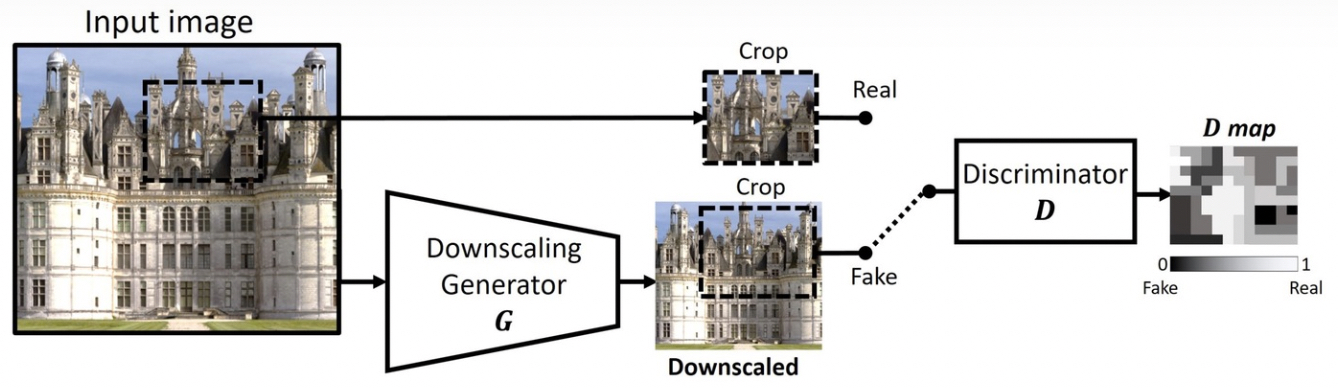
Yunxin super resolution algorithm
Netease Yunxin video lab proposes an edge oriented and efficient feature distillation network (EFDN), stay 2022 year CVPR NTIRE High efficiency super-resolution challenge ,
Overall Performance Racetrack Yunxin won the first place with obvious advantages ,Runtime The track finished third .
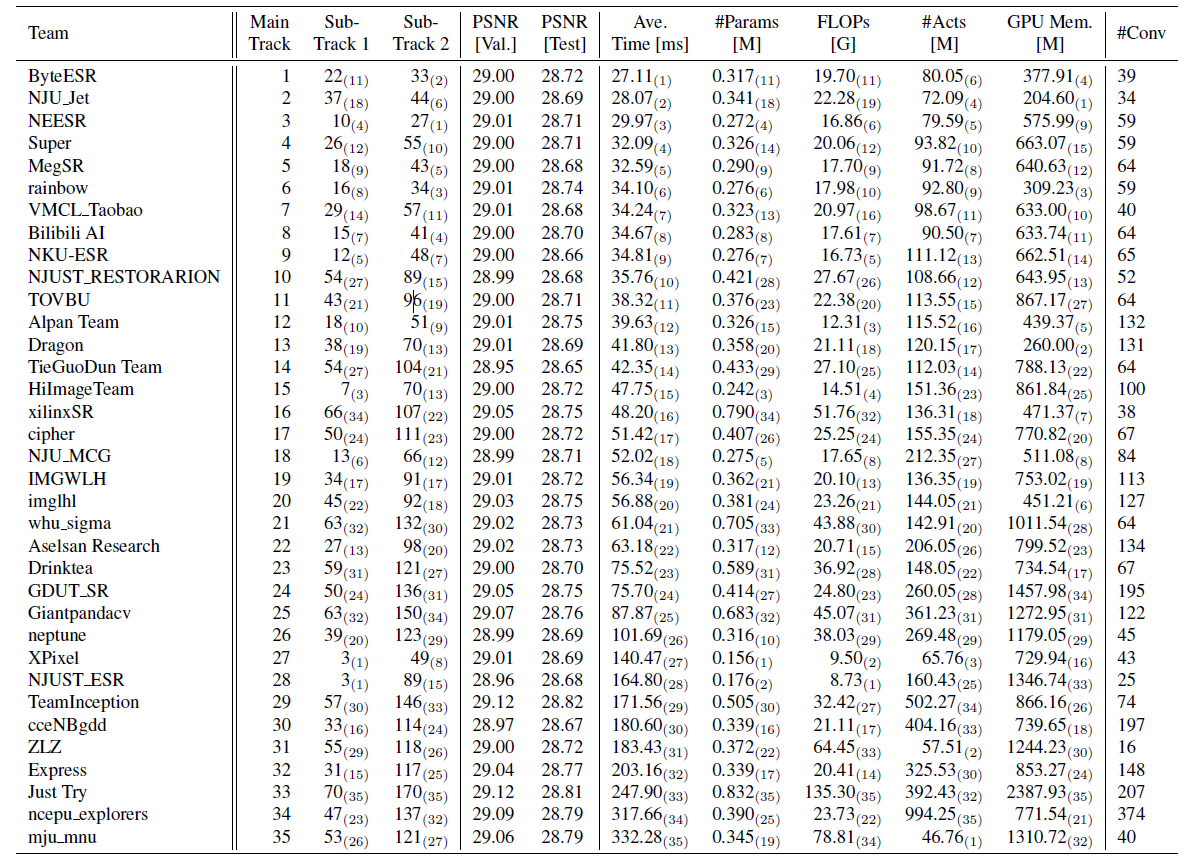
Complete report of the competition :
https://arxiv.org/abs/2205.05675
This method is to improve the accuracy of the model and reduce the cost of the model , Based on the idea of structural heavy parameters , In the training phase, the edge oriented convolution block is used (ECB) Instead of residual characteristic distillation module (RFDB) Medium SRB Shallow residual block , In the reasoning stage, the edge oriented convolution block (ECB) Convert to normal 3x3 Convolution layer , This method can extract texture information and edge information of image more efficiently , Improve network performance while reducing overhead ; At the same time, it can enhance spatial attention (ESA) Module for tailoring , Reduce the number of parameters and increase the step size of the pool layer , The algorithm overhead is further reduced .
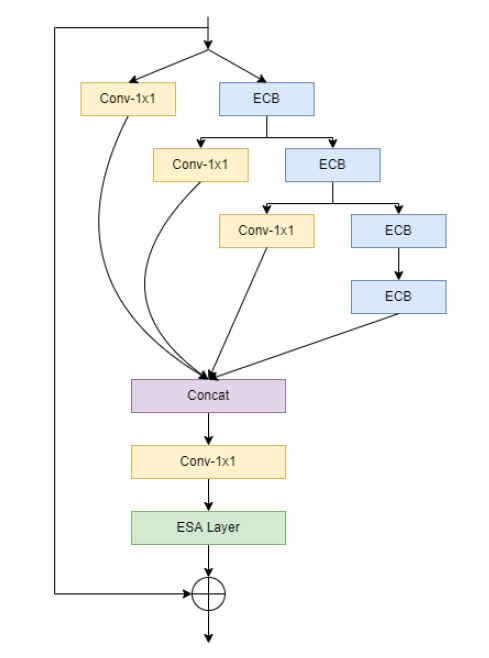
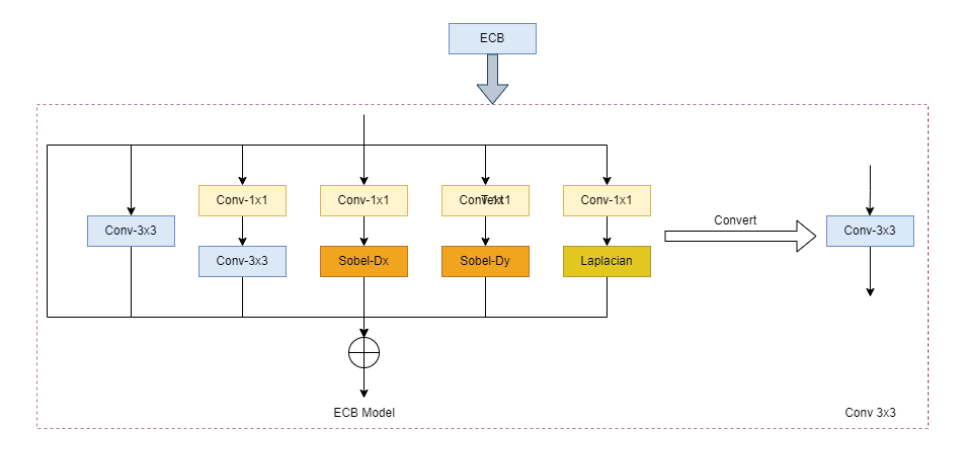
In order to further implement the project , Get a model that can run in real time on mobile devices , Comprehensive efficiency and effect , Yunxin team adopts the following optimization methods :
The model of compression :
In the actual landing process , In order to meet the requirements of real-time processing , We are CVPR NTIRE 2022 High efficiency super score challenge competition model - An edge oriented efficient feature distillation module (EFDN) On the basis of , Use the passage to prune , Knowledge distillation and other model compression technologies further reduce the redundant parameters in the optimized model architecture , Remove channels that contribute little to model performance , To reduce the complexity of the model . At the same time, quantization technology is used to store the weight in low bits , So as to reduce the model volume , Accelerate Computing .
Engineering optimization :
Calculate power on mobile devices 、 With limited memory bandwidth , It should not only meet the requirements of real-time video processing with super division algorithm , It can't increase too much power consumption , The requirements for engineering deployment are very high . Our optimization on the engineering side is mainly through SIMD, Model memory optimization , Optimization methods such as data layout optimization save memory overhead and reasoning time , At the same time, the algorithm realizes zero copy of memory between rendering pipeline and device by deeply combining business scenarios , Complete the high-performance landing of the algorithm .
The following table shows yunxinchao on different platforms / A single frame on the device takes time .

Effect display and future outlook
The video super division of mobile terminal can break through the limitation of codec and the efficiency bottleneck of video transmission , Optimize video transmission speed 、 User experience such as playback fluency , And bring many practical effects :
Improve video clarity
, Take advantage of the high resolution of the high-end computer screen , Low definition video HD playback , HD video provides Ultra HD image quality , Improve users' video consumption experience .
Reduce bandwidth
, Through the sender / The server reduces the resolution of transcoding and distributing video , Combined with the super-resolution processing at the receiving end, it presents a high-resolution effect , Lower the threshold of HD playback , Improve fluency , Reduce user network pressure .
future , We will continue to optimize video enhancement algorithms, including hyperfractional algorithms , Create the industry's top image restoration and image enhancement technology , Help customers improve video quality , Reduce video playback costs , Provide lower consumption of time , Lower power consumption , Better subjective quality , Algorithms that cover more models and save more bit rates , Let users on different mobile phones 、 Enjoy Ultra HD video experience in different network environments .

Zuo Wei Bicubic Upsampling result , On the right is the result of super fractional optimization
Reference material
[1] Yawei Li, Kai Zhang, Luc Van Gool, Radu Timofte, et al. Ntire 2022 challenge on efficient super-resolution: Methods and results. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2022.
[2] Zheng Hui, Xinbo Gao, Yunchu Yang, and Xiumei Wang. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the ACM International Conference on Multimedia, pages 2024–2032, 2019.
[3] Jie Liu, Jie Tang, and Gangshan Wu. Residual feature distillation network for lightweight image super-resolution. In European Conference on Computer Vision Workshops, pages41–55. Springer, 2020.
[4] Zhang, Xindong and Zeng, Hui and Zhang, Lei. Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices. In Proceedings of the 29th ACM International Conference on Multimedia, pages4034--4043. 2021.
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/186/202207051526166921.html