当前位置:网站首页>Implement your own dataset using bisenet
Implement your own dataset using bisenet
2022-07-07 08:23:00 【I am a little rice】
Data set preparation
Data sets : Remote sensing house image segmentation , There are two times , It is mainly to realize the area change of building area with time .
Baidu cloud :https://pan.baidu.com/s/1HlnKWToc00986jiTxhq_CA
Extraction code :RSAI
Data processing
1. Data sets
The data set is stored in the root directory datasets Under the folder , And coco and city Data set juxtaposition , If the label of your dataset is already 0,1, Then don't worry label_255, If the label has not passed 255-->1 The transformation of , You can put the label file in label_255 Next .
—BiSeNet
---------datasets
-----------------coco
-----------------cityscapes
-----------------time
-----------------------train
------------------------------image
------------------------------label_255
------------------------------label
-----------------------val
------------------------------image
------------------------------label_255
------------------------------label
2. stay datasets/times/ Create under folder one.py
The aim is to 0,255 The label of is converted to 0,1, If it's multi class , Then the label is 0,1,2,3,...n
In the code, only train Documents in , To transform val Documents in , modify train by val that will do
import os
import cv2 as cv
labels_path = './train/label_255'
labels_save_path = './train/label'
lab_names = os.listdir(labels_path)
for s in lab_names:
label_path = os.path.join(labels_path, s)
label_save_path = os.path.join(labels_save_path, s)
label = cv.imread(label_path, 0)
label[label!=0]=1
cv.imwrite(label_save_path, label)
2. stay datasets/times/ Create under folder util.py file
The goal is to generate train.txt Document and val.txt file , To transform val.txt file , Just add all of the following code train Switch to val that will do ( There are three )
import os
image_path = './train/image'
label_path = './train/label'
image_names = os.listdir(image_path)
for s in image_names:
image = os.path.join(image_path, s)
label = os.path.join(label_path, s)
with open('train.txt', 'a') as fin:
fin.write(image[2:] +","+ label[2:] +"\n")
fin.close()
Network model address
Model modification
1. modify configs/bisenet_customer.py file
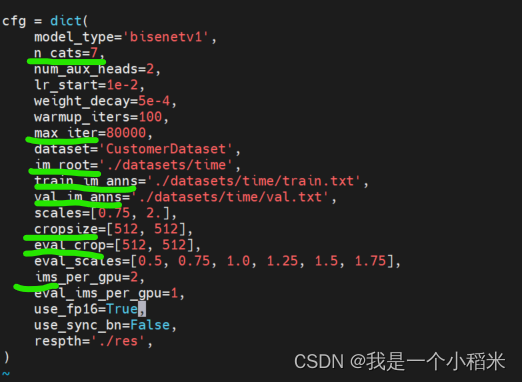
n_cats: Number of categories including background , The category here is 2max_iter: Training times im_root: Data path train_im_anns: Just generated train.txt route val_im_anns: Just generated val.txt route cropsize: Change to image size eval_crop: Change to image size ( I don't know the effect )ims_per_gpu:gpu Number
2. Modify category
This dataset category is 2
If configs/bisenet_customer.py Medium model_type='bisenetv2' modify lib/models/bisenetv2.py In the document n_classes=2

If configs/bisenet_customer.py Medium model_type='bisenetv1' modify lib/models/bisenetv1.py In the document BiSeNetV1(2)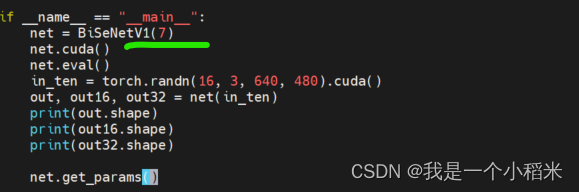
Run the command
--nproc_per_node Do not know what that mean? , there 2 yes gpu The number of
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node=2 tools/train_amp.py --config configs/bisenet_customer.py
And it's going to work !!
边栏推荐
- Obsidan之数学公式的输入
- Bayes' law
- Practice of combining rook CEPH and rainbow, a cloud native storage solution
- opencv学习笔记二——图像基本操作
- Application of slip ring of shipborne radar antenna
- XCiT学习笔记
- Easy to understand SSO
- Improve the delivery efficiency of enterprise products (1) -- one click installation and upgrade of enterprise applications
- Myabtis_ Plus
- ROS bridge notes (05) - Carla_ ackermann_ Control function package (convert Ackermann messages into carlaegovehiclecontrol messages)
猜你喜欢

CCTV is so warm-hearted that it teaches you to write HR's favorite resume hand in hand
GFS分布式文件系统

机器人教育在动手实践中的真理
buureservewp(2)

Leetcode simple question: find the K beauty value of a number

【雅思口语】安娜口语学习记录 Part2

opencv学习笔记三——图像平滑/去噪处理

Give full play to the wide practicality of maker education space
Rsync remote synchronization
Réplication de vulnérabilité - désrialisation fastjson
随机推荐
Using nocalhost to develop microservice application on rainbow
机器人教育在动手实践中的真理
Uniapp mobile terminal forced update function
[step on the pit series] H5 cross domain problem of uniapp
Make LIVELINK's initial pose consistent with that of the mobile capture actor
Blob 對象介紹
[untitled]
柯基数据通过Rainbond完成云原生改造,实现离线持续交付客户
Caractéristiques de bisenet
Easy to understand SSO
通俗易懂单点登录SSO
接口作为参数(接口回调)
Qinglong panel -- finishing usable scripts
Coquette data completes the cloud native transformation through rainbow to realize offline continuous delivery to customers
Zcmu--1492: problem d (C language)
Application of slip ring of shipborne radar antenna
【无标题】
Vulnerability recurrence easy_ tornado
MES system is a necessary choice for enterprise production
Use of any superclass and generic extension function in kotlin