当前位置:网站首页>轻松上手Fluentd,结合 Rainbond 插件市场,日志收集更快捷
轻松上手Fluentd,结合 Rainbond 插件市场,日志收集更快捷
2022-07-07 05:08:00 【Rainbond】

以往有篇文章介绍 EFK(Kibana + ElasticSearch + Filebeat)的插件日志收集。Filebeat 插件用于转发和集中日志数据,并将它们转发到 Elasticsearch 或 Logstash 以进行索引,但 Filebeat 作为 Elastic 的一员,只能在 Elastic 整个体系中使用。
Fluentd
Fluentd是一个开源的,分布式日志采集系统,可以从不同的服务,数据源采集日志,对日志进行过滤加工,分发给多种存储和处理系统。支持各种插件,数据缓存机制,且本身所需的资源很少,内置可靠性,结合其他服务,可以形成高效直观的日志收集平台。
本文介绍在 Rainbond 中使用 Fluentd 插件,收集业务日志,输出到多个不同的服务。
一、整合架构
在收集组件日志时,只需在组件中开通 Fluentd 插件,本文将演示以下两种方式:
- Kibana + ElasticSearch + Fluentd
- Minio + Fluentd
我们将 Fluentd 制作成 Rainbond 的 一般类型插件 ,在应用启动之后,插件也随之启动并自动收集日志输出到多个服务源,整个过程对应用容器无侵入,且拓展性强。
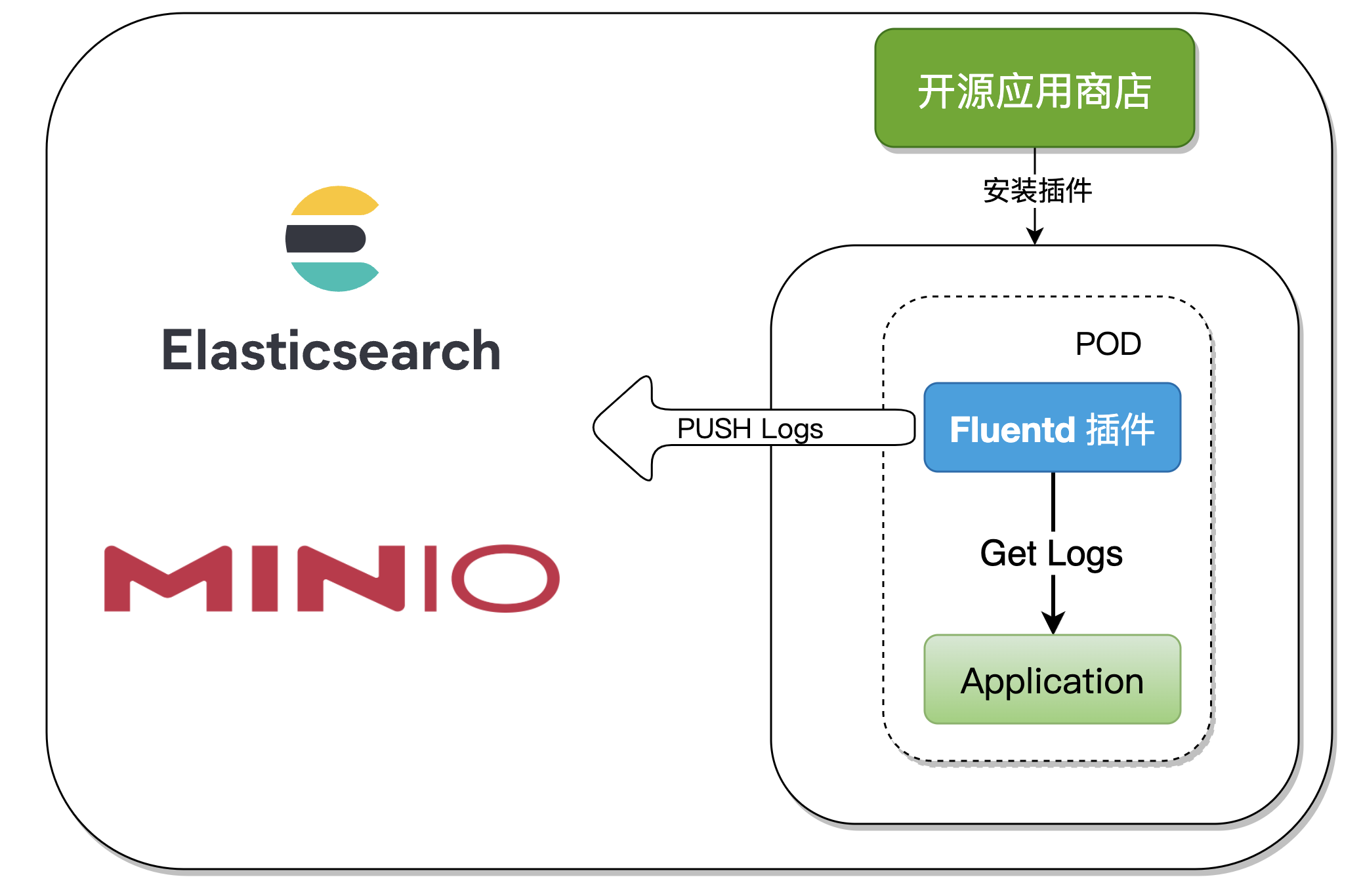
二、插件原理分析
Rainbond V5.7.0 版本中新增了:从开源应用商店安装插件,本文中的插件已发布到开源应用商店,当我们使用时一键安装即可,根据需求修改配置文件。
Rainbond 插件体系是相对于 Rainbond 应用模型的一部分,插件主要用来实现应用容器扩展运维能力。由于运维工具的实现有较大的共性,因此插件本身可以被复用。插件必须绑定到应用容器时才具有运行时状态,用以实现一种运维能力,比如性能分析插件、网络治理插件、初始化类型插件。
在制作 Fluentd 插件的过程中,使用到了 一般类型插件,可以理解为一个POD启动两个 Container,Kubernetes原生支持一个POD中启动多个 Container,但配置起来相对复杂,在 Rainbond 中通过插件实现使用户操作更加简单。
三、EFK 日志收集实践
Fluentd-ElasticSearch7 输出插件将日志记录写入 Elasticsearch。默认情况下,它使用批量 API创建记录,该 API 在单个 API 调用中执行多个索引操作。这减少了开销并可以大大提高索引速度。
3.1 操作步骤
应用 (Kibana + ElasticSearch)和插件(Fluentd)都可以通过开源应用商店一键部署。
- 对接开源应用商店
- 在应用商店中搜索
elasticsearch并安装7.15.2版本。 - 团队视图 -> 插件 -> 从应用商店安装
Fluentd-ElasticSearch7插件 - 基于镜像创建组件,镜像使用
nginx:latest,并且挂载存储var/log/nginx。这里使用Nginx:latest作为演示- 在组件内挂载存储后,插件也会自定挂载该存储,并可访问 Nginx 产生的日志文件。
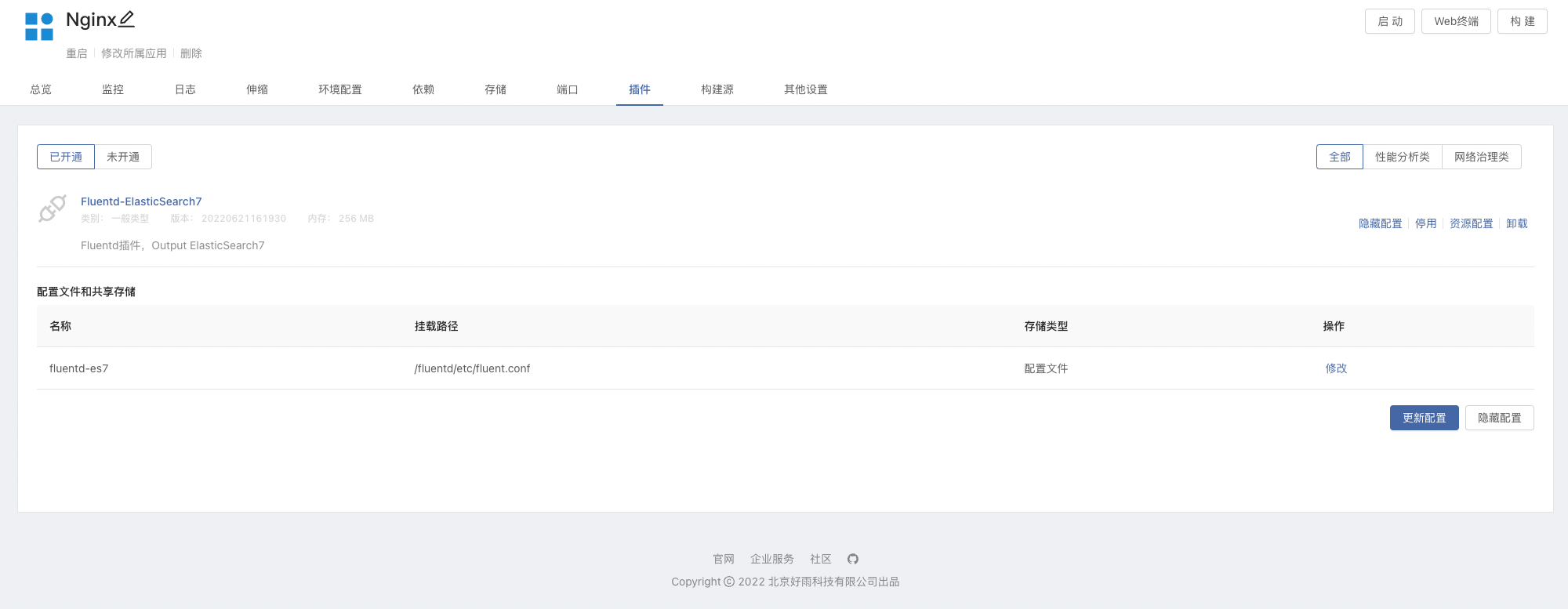
- 在 Nginx 组件内开通插件,可以根据所需进行修改
Fluentd配置文件,可参考下方配置文件简介部分。
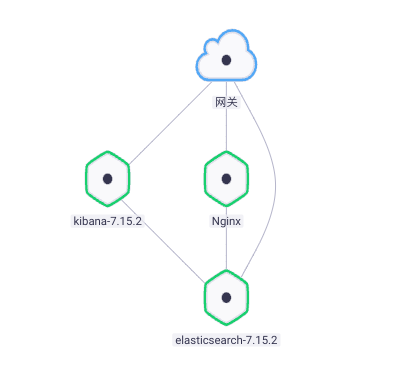
- 添加 ElasticSearch 依赖,将 Nginx 连接到 ElasticSearch,如下图:
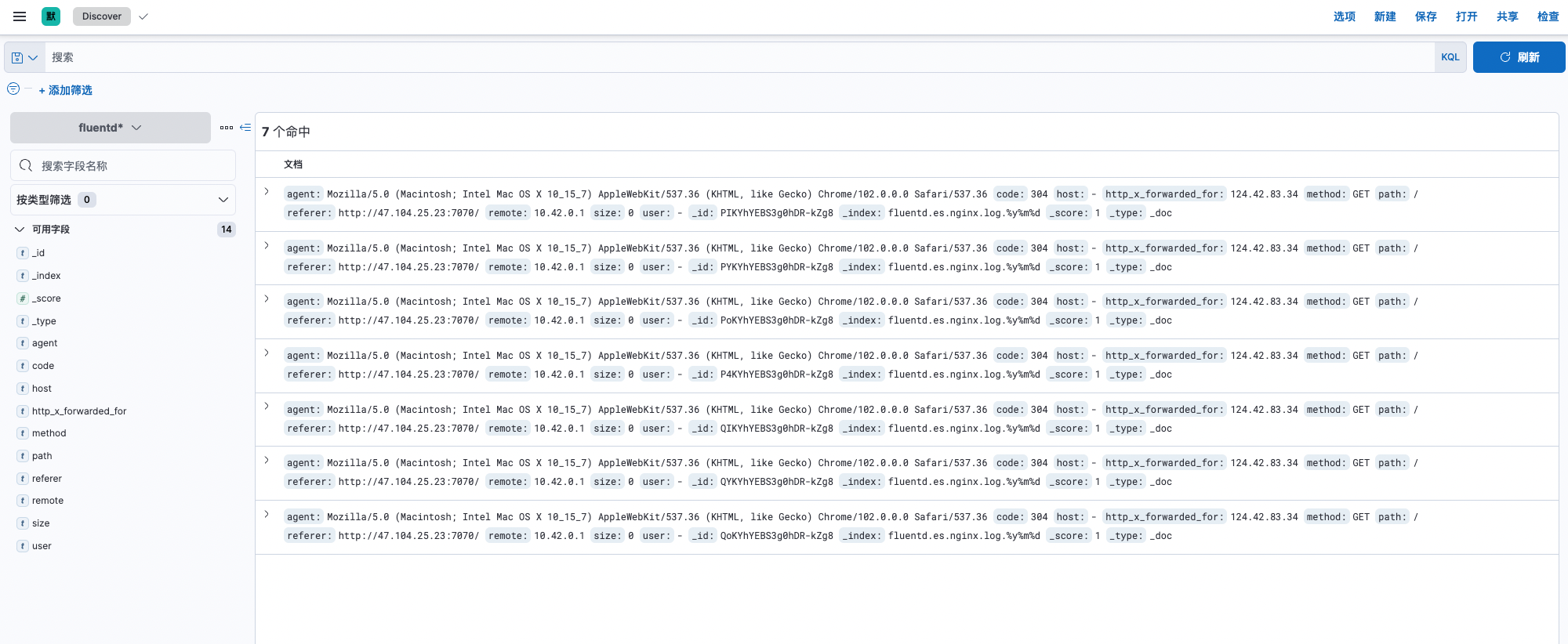
访问
Kibana面板,进入到 Stack Management -> 数据 -> 索引管理,可以看到已存在的索引名称为fluentd.es.nginx.log,访问
Kibana面板,进入到 Stack Management -> Kibana -> 索引模式,创建索引模式。进入到 Discover,日志正常展示。
3.2 配置文件介绍
配置文件参考 Fluentd 文档 output_elasticsearch。
<source> @type tail path /var/log/nginx/access.log,/var/log/nginx/error.log pos_file /var/log/nginx/nginx.access.log.pos <parse> @type nginx </parse> tag es.nginx.log</source><match es.nginx.**> @type elasticsearch log_level info hosts 127.0.0.1 port 9200 user elastic password elastic index_name fluentd.${tag} <buffer> chunk_limit_size 2M queue_limit_length 32 flush_interval 5s retry_max_times 30 </buffer></match>配置项解释:
<source></source> 日志的输入源:
| 配置项 | 解释说明 |
|---|---|
| @type | 采集日志类型,tail表示增量读取日志内容 |
| path | 日志路径,多个路径可以使用逗号分隔 |
| pos_file | 用于标记已经读取到位置的文件(position file)所在的路径 |
| <parse></parse> | 日志格式解析,根据你自己的日志格式,编写对应的解析规则。 |
<match></match>日志的输出端:
| 配置项 | 解释说明 |
|---|---|
| @type | 输出到的服务类型 |
| log_level | 设置输出日志的级别为info;支持的日志级别有:fatal, error, warn, info, debug, trace. |
| hosts | elasticsearch的地址 |
| port | elasticsearch的端口 |
| user/password | elasticsearch用到的用户名/密码 |
| index_name | index定义的名称 |
| <buffer></buffer> | 日志的缓冲区,用于缓存日志事件,提高系统性能。默认使用内存,也可以使用file文件 |
| chunk_limit_size | 每个块的最大大小:事件将被写入块,直到块的大小变成这个大小,内存默认为8M,文件256M |
| queue_limit_length | 此缓冲插件实例的队列长度限制 |
| flush_interval | 缓冲区日志刷新事件,默认60s刷新输出一次 |
| retry_max_times | 重试失败块输出的最大次数 |
以上只是部分配置参数,其他配置可以跟官网文档自定义。
四、Fluentd + Minio 日志收集实践
Fluentd S3 输出插件将日志记录写入到标准的 S3 对象存储服务,例如 Amazon、Minio。
4.1 操作步骤
应用(Minio)和插件(Fluentd S3)都可以通过开源应用商店进行一键部署。
对接开源应用商店。在开源应用商店中搜索
minio,并安装22.06.17版本。团队视图 -> 插件 -> 从应用商店安装
Fluentd-S3插件。访问 Minio 9090 端口,用户密码在 Minio 组件 -> 依赖中获取。
创建 Bucket,自定义名称。
进入 Configurations -> Region,设置 Service Location
- Fluentd 插件的配置文件中
s3_region默认为en-west-test2。
- Fluentd 插件的配置文件中
基于镜像创建组件,镜像使用
nginx:latest,并且挂载存储var/log/nginx。这里使用Nginx:latest作为演示- 在组件内挂载存储后,插件也会自定挂载该存储,并可访问 Nginx 产生的日志文件。
进入到 Nginx 组件内,开通 Fluentd S3 插件,修改配置文件中的
s3_buckets3_region
- 建立依赖关系,Nginx 组件依赖 Minio,更新组件使其生效。
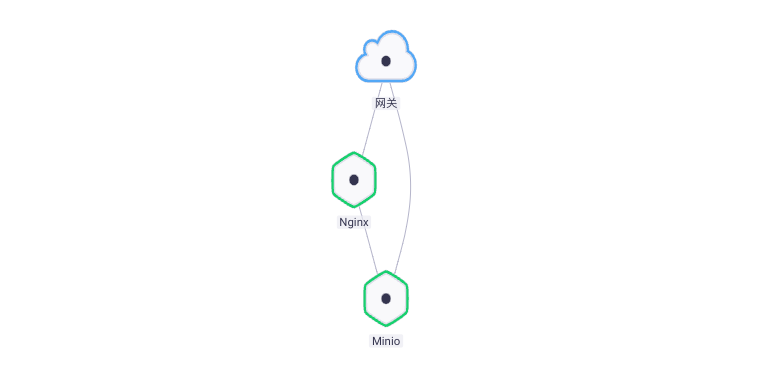
- 访问 Nginx 服务,让其产生日志,片刻后就可以在 Minio 的 Bucket 中看到。

4.2 配置文件介绍
配置文件参考 Fluentd 文档 Apache to Minio。
<source> @type tail path /var/log/nginx/access.log pos_file /var/log/nginx/nginx.access.log.pos tag minio.nginx.access <parse> @type nginx </parse></source><match minio.nginx.**> @type s3 aws_key_id "#{ENV['MINIO_ROOT_USER']}" aws_sec_key "#{ENV['MINIO_ROOT_PASSWORD']}" s3_endpoint http://127.0.0.1:9000/ s3_bucket test s3_region en-west-test2 time_slice_format %Y%m%d%H%M force_path_style true path logs/ <buffer time> @type file path /var/log/nginx/s3 timekey 1m timekey_wait 10s chunk_limit_size 256m </buffer></match>配置项解释:
<source></source> 日志的输入源:
| 配置项 | 解释说明 |
|---|---|
| @type | 采集日志类型,tail表示增量读取日志内容 |
| path | 日志路径,多个路径可以使用逗号分隔 |
| pos_file | 用于标记已经读取到位置的文件(position file)所在的路径 |
| <parse></parse> | 日志格式解析,根据你自己的日志格式,编写对应的解析规则。 |
<match></match>日志的输出端:
| 配置项 | 解释说明 |
|---|---|
| @type | 输出到的服务类型 |
| aws_key_id | Minio 用户名 |
| aws_sec_key | Minio 密码 |
| s3_endpoint | Minio 访问地址 |
| s3_bucket | Minio 桶名称 |
| force_path_style | 防止 AWS SDK 破坏端点 URL |
| time_slice_format | 每个文件名都加上这个时间戳 |
| <buffer></buffer> | 日志的缓冲区,用于缓存日志事件,提高系统性能。默认使用内存,也可以使用file文件 |
| timekey | 每 60 秒刷新一次累积的chunk |
| timekey_wait | 等待 10 秒再刷新 |
| chunk_limit_size | 每个块的最大大小 |
最后
Fluentd 插件可以很灵活的收集业务日志并输出至多个服务,并结合 Rainbond 插件市场的一键安装,让我们的使用变得更加简单、快捷。
目前 Rainbond 开源插件应用市场的 Flunetd 插件只有 Flunetd-S3Flunetd-ElasticSearch7,欢迎小伙伴们贡献插件哦!
边栏推荐
- Introduction to basic components of wechat applet
- 基于Pytorch 框架手动完成线性回归
- Dedecms collects content without writing rules
- Bugku CTF daily one question chessboard with only black chess
- 【數字IC驗證快速入門】15、SystemVerilog學習之基本語法2(操作符、類型轉換、循環、Task/Function...內含實踐練習)
- [Matlab] Simulink 自定义函数中的矩阵乘法工作不正常时可以使用模块库中的矩阵乘法模块代替
- 2022 welder (elementary) judgment questions and online simulation examination
- Complete linear regression manually based on pytoch framework
- Relevant data of current limiting
- JS cross browser parsing XML application
猜你喜欢
Call pytorch API to complete linear regression
电池、电机技术受到很大关注,反而电控技术却很少被提及?
padavan手动安装php
![[quick start of Digital IC Verification] 15. Basic syntax of SystemVerilog learning 2 (operators, type conversion, loops, task/function... Including practical exercises)](/img/e1/9a047ef13299b94b5314ee6865ba26.png)
[quick start of Digital IC Verification] 15. Basic syntax of SystemVerilog learning 2 (operators, type conversion, loops, task/function... Including practical exercises)
【数字IC验证快速入门】15、SystemVerilog学习之基本语法2(操作符、类型转换、循环、Task/Function...内含实践练习)

Linux server development, redis protocol and asynchronous mode
The charm of SQL optimization! From 30248s to 0.001s
Quickly use Jacobo code coverage statistics

Qinglong panel - today's headlines

LeetCode简单题之判断一个数的数字计数是否等于数位的值
随机推荐
Avatary's livedriver trial experience
[step on the pit series] H5 cross domain problem of uniapp
DNS server configuration
Niu Mei's mathematical problem --- combinatorial number
Who has docker to install MySQL locally?
C language queue
B. Value sequence thinking
Uniapp mobile terminal forced update function
芯片 设计资料下载
Linux server development, MySQL transaction principle analysis
Chip information website Yite Chuangxin
Linux server development, detailed explanation of redis related commands and their principles
Main window in QT learning 27 application
json 数据展平pd.json_normalize
2022年全国最新消防设施操作员(初级消防设施操作员)模拟题及答案
padavan手动安装php
QT learning 28 toolbar in the main window
【数字IC验证快速入门】15、SystemVerilog学习之基本语法2(操作符、类型转换、循环、Task/Function...内含实践练习)
通俗易懂单点登录SSO
【数字IC验证快速入门】13、SystemVerilog interface 和 program 学习