当前位置:网站首页>GFS分布式文件系统
GFS分布式文件系统
2022-07-07 05:20:00 【Kiro君】
GlusterFS分布式文件系统
一、GlusterFS概述
- GlusterFS是一个开源的分布式文件系统
- 由服务器、客户端以及NFS/Samba 存储网关 存储(可选,根据需要选择使用)组成
- 没有元数据服务器组件,这有助于提升整个系统的性能、可靠性和稳定性
1、文件系统组成
- 文件系统接口(API)
- 对对象管理的软件集合
- 对象及属性
2、文件系统的作用
- 从系统角度来看,文件系统是对文件存储设备的空间进行组织和备份
- 负责文件存储并对存入的文件进行保护和检索的系统
- 具体地说,它负责为用户建立文件、存入、读出、修改、转储文件、控制文件的存储
3、专业术语
- Brick(块存储服务器)实际存储用户数据的服务器
- Volume (逻辑卷):一个逻辑卷就是一组Brick的集合,本地文件系统的"分区"
- FUSE (一个内核模块): 用户空间的文件系统(类别EXT4),”这是一个伪文件系统“ ,用户端的交换模块
- VFS(虚拟端口)内核态的虚拟文件系统,用户是提交请求给VFS 然后VFS交给FUSH,再交给GFS客户端,最后由客户端交给远端的存储
- Glusterd(服务)是运行再存储节点的进程(客户端运行的是gluster client)GFS使用过程中整个GFS之间的交换由Gluster client 和glusterd完成
4、模块化堆栈式架构
GlusterFS采用模块化、堆栈式的架构
通过对模块进行各种组合,即可实现复杂的功能。例如Replicate模块
通过两者的组合可实现RAID10和RAID01,同时获得更高的性及可靠的RAID0
缺少一点
5、服务器详解
- Application :客户端或应用程序通过GlusterFSync的挂载点访问数据
- VFS :linux系统内核通过VFS的API 收到请求并处理
- FUSE :VFS将数据递交给FUSE内核文件系统,fuse文件系统则是将数据通过/dev/fuse设备文件递交给了GlusterFS
- GlusterFS Client :通过网络将数据传递至远端的GlusterFS Server, 并且写入到服务器存储设备上
二、GFS特点
- 扩展性和高性能 (分布式):可扩展性,扩展节点,通过多节点提高性能
- 高可用性 (容灾能力) : 不存在单点故障,有备份机制,类似Raid的容灾机制
- 全局统一命名空间 :类比 API 的性质/概念,系统里根据他命名所定义的隔离区域,是一个独立空间;统一的名称空间,与客户端交互,把请求存放至后端的块数据服务器
- 弹性卷管理 :方便扩容及对后端存储集群的管理与维护,较为复杂
- 基于标准协议 :Gluster 存储服务支持 NFS、CIFS、HTTP、FTP、SMB 及 Gluster原生协议 ,完全与 POSIX 标准(可移植操作系统接口)兼容。
现有应用程序不需要做任何修改就可以对Gluster 中的数据进行访问,也可以使用专用 API 进行访问。
三、GFS工作原理
① 客户端或应用程序通过 GlusterFS 的挂载点访问数据;
② linux系统内核“这是一个伪文件系”通过 VFS API 虚拟接口收到请求并处理;
③ VFS 将数据递交给 FUSE 内核文件系统,这是一个伪文件系统 ,这个伪文件系统主要用来转存,它提供一个虚拟接口,映射出来/dev/fuse这样一个虚拟路径,而 FUSE 文件系统则是将数据通过 /dev/fuse 设备文件递交给了 GlusterFS client 端。可以将 FUSE 文件系统理解为一个代理
④ GlusterFS client 会实时监听/dev/fuse下的数据 ,一旦数据更新,会把数据拿过来,client 根据配置文件的配置对数据进行处理
⑤ 经过 GlusterFS client 处理后,通过网络将数据传递至远端的 GlusterFS Server,server会先转存到本地的vfs虚拟文件系统中 ,然后再通过vfs转存到EXT3上。EXT3指的是各个block块中的EXT3文件系统中。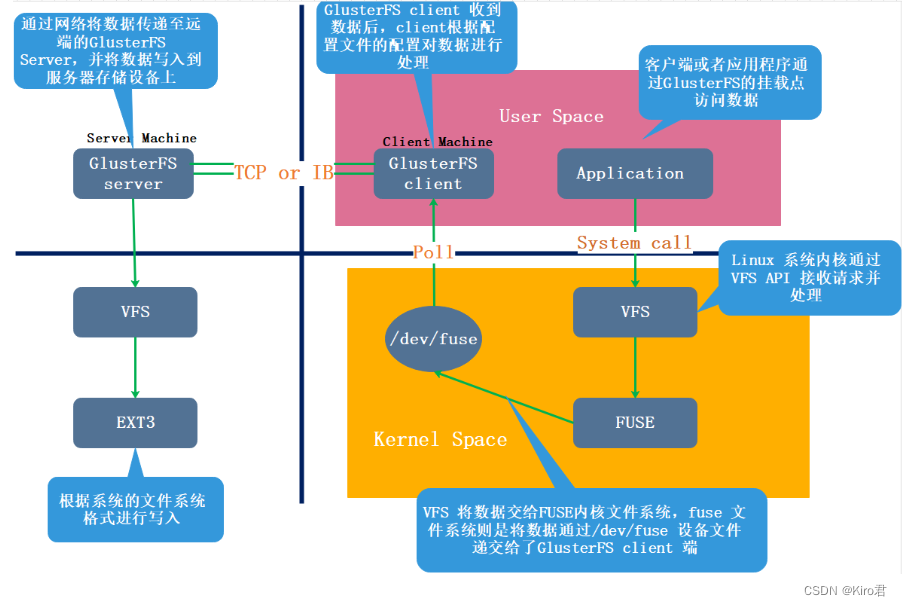
GFS-server 端功能模块的划分: ① 卷的类型(使用分布式、复制、条带) ② 存储管理(卷的创建、启用、关闭) ③
I/O调用(存储后,读取数据,如何读取) ④ 与GFS-client 端对接
GFS-client 端 ① 用户通过用户态模式下,存储数据(写入数据) ②
写入的数据,使用GFS挂载的形式完成(网络挂载samba/NFS)
③数据的写入会由GFS-client转存到GFS-server端(对应的卷中)
四、弹性HASH算法
弹性HASH算法是Davies-Meyer算法的具体实现,通过HASH算法可以得到一个32为的整数范围的hash值,假设逻辑卷中有N哥存储单位Brick,则32为的整数范围将被划分为N哥连续的子空间,每个空间对应一个Brick。
当用户或应用程序访问某一个,命名空间时,通过对该命名空间计算HASH值,根据该HASH值所对应的32为整数空间定位数据所在的Brick。
弹性HASH算法的优点
缺少一点
五、GlusterFS卷
5.1 GlusterFS卷类型
分布式卷
条带卷
复制卷
分布式条带卷
分布式复制卷
条带复制卷
分布式条带数据卷
5.2 三大基本卷的特点
1 、分布式卷(Distribute volume)
①原理
File1 和 File2 存放在 Server1,而 File3 存放在 Server2,文件都是随机存储,一个文件(如 File1)要么在 Server1 上,要么在 Server2 上,不能分块同时存放在 Server1和 Server2 上
② 特点
- 没有对文件进行分块处理
- 通过扩展文件属性保存hash
- 支持的底层文件系统有EXT3、EXT4、ZFX、XFS等
- 文件分布在不同的服务器,不具备冗余性
- 更容易和廉价地扩展卷的大小
- 单点故障会造成数据丢失
- 依赖底层的数据保护
③创建分布式卷
创建一个名为dis-volume的分布式卷,文件将根据HASH分布在server1:/dir1、server2:/dir2和server3:/dir3中gluster volume create dis-volume server1:/dir1 server2:/dir2 server3:/dir3
2、条带卷(Stripe volume)
类似 RAID0,文件被分成数据块并以轮询的方式分布到多个 Brick Server 上 ,文件存储以数据块为单位,支持大文件存储, 文件越大,读取效率越高,但是不具备冗余性
①原理
File 被分割为 6 段,1、3、5 放在 Server1,2、4、6 放在 Server2
② 特点
- 类似RAID0,文件根据偏移量被分成数据块并以轮询的方式分布到多个
- 存储大文件时,性能尤为突出(分布减少了负载且更小的文件加速了存取的速度)
- 没有数据冗余
③ 创建条带卷
创建了一个名为stripe-volume的条带卷,文件将被分块轮询的存储在Server1:/dir1和Server2:/dir2两个Brick中gluster volume create stripe-volume stripe 2 transport tcp server1:/dir1 server2:/dir2
3、 复制卷(Replica volume)
将文件同步到多个 Brick 上,比如说我有五个文件,这5个文件是一个整体,放在服务器A上,复制卷会帮我们复制一份复制在服务器B上。属于文件级 RAID 1,具有容错能力。因为数据分散在多个 Brick 中,所以读性能得到很大提升,但写性能下降。复制卷具备冗余性,即使一个节点损坏,也不影响数据的正常使用。但因为要保存副本,所以磁盘利用率较低
①原理
File1 同时存在 Server1 和 Server2,File2 也是如此,相当于 Server2 中的文件是 Server1 中文件的副本
②特点
- 卷中所有的服务器均保存一个完整的副本
- 卷的副本数量可由客户创建的时候决定
- 至少由两个块服务器或更多服务器
- 具备冗余性
③创建复制卷
创建名为rep-volume的复制卷,文件将同时存储两个副本,分别在Server1:/dir1和Server2:/dir2两个Brick中gluster volume create rep-volume replica 2 transport tcp server1:/dir1 server2:/dir2
4、分布式条带卷(Distribute Stripe volume)
Brick Server 数量是条带数(数据块分布的 Brick 数量)的倍数,兼具分布式卷和条带卷的特点。 主要用于大文件访问处理,创建一个分布式条带卷最少需要 4 台服务器
①原理
File1 和 File2 通过分布式卷的功能分别定位到Server1和 Server2。在 Server1 中,File1 被分割成 4 段,其中 1、3 在 Server1 中的 exp1 目录中,2、4 在 Server1 中的 exp2 目录中。在 Server2 中,File2 也被分割成 4 段,其中 1、3 在 Server2 中的 exp3 目录中,2、4 在 Server2 中的 exp4 目录中
② 创建分布式条带卷
创建一个名为dis-stripe的分布式条带卷,配置分布式的条带卷时,卷中Brick所包含的存储服务器数必须是条带数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),条带数为 2(stripe 2)gluster volume create dis-stripe stripe 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
创建卷时,存储服务器的数量如果等于条带或复制数,那么创建的是条带卷或者复制卷;如果存储服务器的数量是条带或复制数的 2 倍甚至更多,那么将创建的是分布式条带卷或分布式复制卷
5、分布式复制卷(Distribute Replica volume)
分布式复制卷(Distribute Replica volume):Brick Server 数量是镜像数(数据副本数量)的倍数,兼具分布式卷和复制卷的特点,主要用于需要冗余的情况下
①原理
File1 和 File2 通过分布式卷的功能分别定位到 Server1 和 Server2。在存放 File1 时,File1 根据复制卷的特性,将存在两个相同的副本,分别是 Server1 中的exp1 目录和 Server2 中的 exp2 目录。在存放 File2 时,File2 根据复制卷的特性,也将存在两个相同的副本,分别是 Server3 中的 exp3 目录和 Server4 中的 exp4 目录
② 创建分布式复制卷
建一个名为dis-rep的分布式复制卷,配置分布式的复制卷时,卷中Brick所包含的存储服务器数必须是复制数的倍数(>=2倍)。Brick 的数量是 4(Server1:/dir1、Server2:/dir2、Server3:/dir3 和 Server4:/dir4),复制数为 2(replica 2)gluster volume create dis-rep replica 2 transport tcp server1:/dir1 server2:/dir2 server3:/dir3 server4:/dir4
6、条带复制卷(Stripe Replica volume)和分布式条带复制卷(Distribute Stripe Replicavolume)
条带复制卷(Stripe Replica volume)类似 RAID 1 0,同时具有条带卷和复制卷的特点。
分布式条带复制卷(Distribute Stripe Replicavolume)三种基本卷的复合卷,通常用于类 Map Reduce 应用
边栏推荐
- Battery and motor technology have received great attention, but electric control technology is rarely mentioned?
- jeeSite 表单页面的Excel 导入功能
- 通俗易懂单点登录SSO
- What is the function of paralleling a capacitor on the feedback resistance of the operational amplifier circuit
- CTF-WEB shrine模板注入nmap的基本使用
- Leetcode 187 Repeated DNA sequence (2022.07.06)
- 【无标题】
- game攻防世界逆向
- 青龙面板--整理能用脚本
- 发挥创客教育空间的广泛实用性
猜你喜欢
OpenVSCode云端IDE加入Rainbond一体化开发体系
调用 pytorch API完成线性回归

Qinglong panel - today's headlines
Wang Zijian: is the NFT of Tencent magic core worth buying?
饥荒云服管理脚本
buureservewp(2)
使用BiSeNet实现自己的数据集

CCTV is so warm-hearted that it teaches you to write HR's favorite resume hand in hand
![[quick start of Digital IC Verification] 12. Introduction to SystemVerilog testbench (svtb)](/img/dc/a809f2ec5f9e85a02e68c88bdcdb5e.png)
[quick start of Digital IC Verification] 12. Introduction to SystemVerilog testbench (svtb)

探索STEAM艺术设计中的创造力
随机推荐
Introduction à l'objet blob
[quick start of Digital IC Verification] 10. Verilog RTL design must know FIFO
Myabtis_ Plus
Blob 对象介绍
使用 Nocalhost 开发 Rainbond 上的微服务应用
Quick analysis of Intranet penetration helps the foreign trade management industry cope with a variety of challenges
opencv学习笔记三——图像平滑/去噪处理
JS copy picture to clipboard read clipboard
[quick start of Digital IC Verification] 11. Introduction to Verilog testbench (VTB)
Real time monitoring of dog walking and rope pulling AI recognition helps smart city
解读创客思维与数学课程的实际运用
Kotlin combines flatmap for filtering and zip merge operators
Rainbond 5.6 版本发布,增加多种安装方式,优化拓扑图操作体验
Interview questions (CAS)
It took "7" years to build the robot framework into a micro service
eBPF Cilium实战(1) - 基于团队的网络隔离
Lua 编程学习笔记
Notes on PHP penetration test topics
jeeSite 表单页面的Excel 导入功能
Search for an element in a binary search tree (BST)