当前位置:网站首页>Implementation principle of waitgroup in golang
Implementation principle of waitgroup in golang
2022-07-07 01:08:00 【raoxiaoya】
Principle analysis
type WaitGroup struct {
noCopy noCopy
// 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
// 64-bit atomic operations require 64-bit alignment, but 32-bit
// compilers only guarantee that 64-bit fields are 32-bit aligned.
// For this reason on 32 bit architectures we need to check in state()
// if state1 is aligned or not, and dynamically "swap" the field order if
// needed.
state1 uint64
state2 uint32
}
among noCopy yes golang Source code to detect the prohibition of copying technology . If there is WaitGroup The assignment behavior of , Use go vet When checking the program , You'll find that there's a mistake . But it should be noted that ,noCopy Will not affect the normal compilation and operation of the program .
state1 Field
- high 32 Position as counter, Represents the number of collaborative processes that have not yet been completed .
- low 32 Position as waiter, Represents that
WaitOf goroutine The number of , becausewaitIt can be called by multiple coroutines .
state2 For a semaphore .
WaitGroup The whole calling process of can be described as follows :
- When calling
WaitGroup.Add(n)when ,counter It's going to grow :counter + n - When calling
WaitGroup.Wait()when , Willwaiter++. At the same time callruntime_Semacquire(semap), Increase the semaphore , And suspend the current goroutine. - When calling
WaitGroup.Done()when , willcounter--. If the self subtracting counter be equal to 0, explain WaitGroup The waiting process is over , You need to callruntime_SemreleaseRelease semaphore , Wake up isWaitGroup.WaitOf goroutine.
About memory for it
func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
if unsafe.Alignof(wg.state1) == 8 || uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
// state1 is 64-bit aligned: nothing to do.
return &wg.state1, &wg.state2
} else {
// state1 is 32-bit aligned but not 64-bit aligned: this means that
// (&state1)+4 is 64-bit aligned.
state := (*[3]uint32)(unsafe.Pointer(&wg.state1))
return (*uint64)(unsafe.Pointer(&state[1])), &state[0]
}
}
If the variable is 64 Bit alignment (8 byte), Then the starting address of the variable is 8 Multiple . If the variable is 32 Bit alignment (4 byte), Then the starting address of the variable is 4 Multiple .
When state1 yes 32 When a , that state1 It is treated as an array [3]uint32, The first bit of the array is semap, The second and third bits store counter, waiter Is precisely 64 position .
Why is there such a strange setting ? There are two premises involved here :
Premise 1: stay WaitGroup In the real logic of , counter and waiter It's been put together , Think of it as a 64 Bit integers are used externally . When change is needed counter and waiter When , through atomic To operate this atom 64 An integer .
Premise 2: stay 32 A system. , If you use atomic Yes 64 Bit variables perform atomic operations , The caller needs to guarantee the correctness of the variable 64 Bit alignment , Otherwise, there will be an exception .golang Official documents of sync/atomic/#pkg-note-BUG This is what the original text says :
On ARM, x86-32, and 32-bit MIPS, it is the caller’s responsibility to arrange for 64-bit alignment of 64-bit words accessed atomically. The first word in a variable or in an allocated struct, array, or slice can be relied upon to be 64-bit aligned.
therefore , On the premise 1 Under the circumstances ,WaitGroup Need to be right 64 Bit for atomic operation . According to the premise 2,WaitGroup You need to guarantee that count+waiter Of 64 Bit alignment .
This method is very ingenious , It's just a change semap The order of the positions , You can guarantee that counter+waiter Definitely, I will 64 Bit alignment , It can also ensure the efficient use of memory .
notes : Some articles will talk about ,WaitGroup Two different memory layouts are 32 Bit system and 64 The difference between bit systems , It's not very rigorous . The exact answer is 32 Bit alignment and 64 The difference between bit alignment . Because in 32 A system. ,state1 It's also possible for variables to fit exactly 64 Bit alignment .
stay sync.mutex There is no memory operation on it in the source code of , Although it also has a large number of atomic operation , That's because state int32.
stay sync.mutex The four states are also stored in a variable address , In fact, the purpose of doing this is to realize atomic operation , Because there is no way to modify multiple variables at the same time and ensure atomicity .
WaitGroup Put... Directly counter and waiter As a unified 64 Bit variable . among counter It's the high of this variable 32 position ,waiter It's the low of this variable 32 position . In need of change counter when , By shifting the accumulated value to the left 32 The way of bit .
Atomic operations here do not use Mutex perhaps RWMutex Such a lock , The main reason is that the lock will bring a lot of performance loss , Context switch exists , The best way to perform atomic operations on a single memory address is atomic, Because this is supported by the underlying hardware (CPU Instructions ), Smaller particle size , Higher performance .
The source code section
func (wg *WaitGroup) Add(delta int) {
// wg.state() It's the address
statep, semap := wg.state()
// Atomic manipulation , modify statep high 32 The value of a , namely counter Value
state := atomic.AddUint64(statep, uint64(delta)<<32)
// Move right 32 position , Make high 32 Bit becomes low 32, obtain counter Value
v := int32(state >> 32)
// Direct lower 32 position , obtain waiter Value
w := uint32(state)
// Nonstandard operation
if v < 0 {
panic("sync: negative WaitGroup counter")
}
// Nonstandard operation
if w != 0 && delta > 0 && v == int32(delta) {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// It's normal
if v > 0 || w == 0 {
return
}
// The rest is counter == 0 And waiter != 0 The situation of
// In this case ,*statep The value is waiter Value , Otherwise there will be problems
// In this case , All the tasks have been completed , Can be *statep Whole set 0
// At the same time to all Waiter Release semaphore
// This goroutine has set counter to 0 when waiters > 0.
// Now there can't be concurrent mutations of state:
// - Adds must not happen concurrently with Wait,
// - Wait does not increment waiters if it sees counter == 0.
// Still do a cheap sanity check to detect WaitGroup misuse.
if *statep != state {
panic("sync: WaitGroup misuse: Add called concurrently with Wait")
}
// Reset waiters count to 0.
*statep = 0
for ; w != 0; w-- {
runtime_Semrelease(semap, false, 0)
}
}
func (wg *WaitGroup) Done() {
wg.Add(-1)
}
func (wg *WaitGroup) Wait() {
// wg.state() It's the address
statep, semap := wg.state()
// for Circulation is coordination CAS operation
for {
state := atomic.LoadUint64(statep)
v := int32(state >> 32) // counter
w := uint32(state) // waiter
// If counter by 0, Explain that all tasks are calling Wait By the time of , immediate withdrawal
// This requires that , Must be called in synchronization Add(), otherwise Wait Maybe I quit first
if v == 0 {
return
}
// waiter++, Atomic manipulation
if atomic.CompareAndSwapUint64(statep, state, state+1) {
// If autoincrement succeeds , Then obtain the semaphore , Here the semaphore plays the role of synchronization
runtime_Semacquire(semap)
return
}
}
}
To sum up ,WaitGroup The principle of is just five points : Memory alignment , Atomic manipulation ,counter,waiter, Semaphore .
Memory alignment is used for atomic operations .
counter The increase or decrease of uses atomic operation ,counter The function of is once for 0 Release all semaphores .
waiter The autoincrement of uses atomic operation ,waiter The function of is to indicate how much semaphore to release .
边栏推荐
- Informatics Orsay Ibn YBT 1172: find the factorial of n within 10000 | 1.6 14: find the factorial of n within 10000
- 第五篇,STM32系统定时器和通用定时器编程
- SuperSocket 1.6 创建一个简易的报文长度在头部的Socket服务器
- There is an error in the paddehub application
- 腾讯云 WebShell 体验
- Build your own website (17)
- Deep learning environment configuration jupyter notebook
- pyflink的安装和测试
- 「精致店主理人」青年创业孵化营·首期顺德场圆满结束!
- 第七篇,STM32串口通信编程
猜你喜欢
![[牛客] B-完全平方数](/img/bd/0812b4fb1c4f6217ad5a0f3f3b8d5e.png)
[牛客] B-完全平方数

重上吹麻滩——段芝堂创始人翟立冬游记
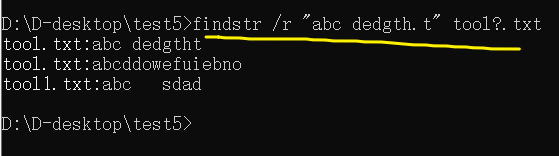
【批處理DOS-CMD命令-匯總和小結】-字符串搜索、查找、篩選命令(find、findstr),Find和findstr的區別和辨析

UI控件Telerik UI for WinForms新主题——VS2022启发式主题
[Niuke] b-complete square
【JVM调优实战100例】04——方法区调优实战(上)

Chenglian premium products has completed the first step to enter the international capital market by taking shares in halber international

迈动互联中标北京人寿保险,助推客户提升品牌价值

Js+svg love diffusion animation JS special effects
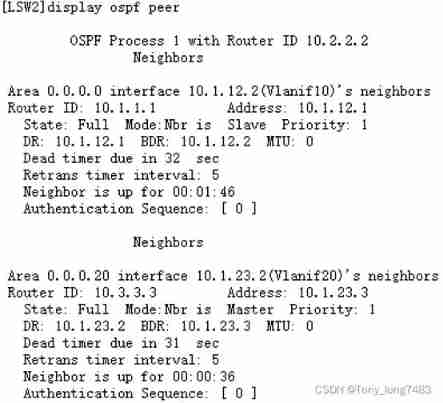
Configuring OSPF basic functions for Huawei devices
随机推荐
Link sharing of STM32 development materials
Oracle:CDB限制PDB资源实战
Data type of pytorch tensor
MySQL中回表的代价
线段树(SegmentTree)
Js+svg love diffusion animation JS special effects
Part 7: STM32 serial communication programming
【批处理DOS-CMD命令-汇总和小结】-跳转、循环、条件命令(goto、errorlevel、if、for[读取、切分、提取字符串]、)cmd命令错误汇总,cmd错误
再聊聊我常用的15个数据源网站
力扣1037. 有效的回旋镖
Informatics Olympiad YBT 1171: factors of large integers | 1.6 13: factors of large integers
资产安全问题或制约加密行业发展 风控+合规成为平台破局关键
How do novices get started and learn PostgreSQL?
golang中的atomic,以及CAS操作
Installation of torch and torch vision in pytorch
Deep learning environment configuration jupyter notebook
[100 cases of JVM tuning practice] 04 - Method area tuning practice (Part 1)
Make a simple graphical interface with Tkinter
用tkinter做一个简单图形界面
Fastdfs data migration operation record