当前位置:网站首页>Is AI more fair than people in the distribution of wealth? Research on multiplayer game from deepmind
Is AI more fair than people in the distribution of wealth? Research on multiplayer game from deepmind
2022-07-07 19:07:00 【qubit 】
Yi Pavilion From the Aofei temple qubits | official account QbitAI
DeepMind No chess this time , And don't play video games , Instead, I studied a multiplayer game .
The latest development of “Democratic AI”—— Learn human values through training , Then we can allocate resources fairly according to everyone's contribution .
To demonstrate this concept ,DeepMind Designed a simple investment game , from AI And human beings serve as referees respectively , Let players choose the preferred allocation rules ,Democratic AI Even got a higher support rate than human referees .
AI Referees are more popular than humans
When a group of people decide to concentrate their money on investment , How to distribute the income is a big problem that we must face .
A simple strategy is to distribute returns equally among investors , But this is likely to be unfair , Because some people contribute more than others .
The second option is , We can allocate according to the initial investment of each person , That sounds fair , But what if people start with different asset levels ?
If two people contribute the same amount , But one is a small part of their available funds , The other contributed all his assets , Should they get the same share of income ?
To meet this challenge ,DeepMind Created a simple multiplayer investment game .
Game involves 4 Players , Share in 10 round .
Each player will be allocated initial funds , In each round , Players can make choices according to their own wishes : keep , Or invest it in a common pool .
The investment will definitely pay off , But there is a risk —— Players don't know how the final revenue will be distributed .
besides , They were told , front 10 There is a referee in the round (A) Make allocation decisions , Then 10 round , By different judges (B) To take over .
At the end of the game , They will vote for A or B, To decide which referee you want to play with again .
And the revenue of this last game can be retained by the players themselves , This will enable players to choose the most impartial referee in their hearts more actively .
in fact , One of the judges performs according to the preset allocation rules , On the other side is by Democratic AI make designs of one's own .
When we study the voting of these players , We found that AI Designed rules are more popular than standard allocation rules .
meanwhile ,DeepMind Also invited a human referee , And introduce him to the rules 、 Let him try to achieve fair distribution to win votes , But the final vote showed , He still lost to Democratic AI.
Democratic AI Why can we win ?
stay DeepMind The latest is published in Nature Sub issue Nature Human Behaviour Papers , It records the researchers' understanding of Democratic AI Training process of .
First , They let 4000 Many human players participate in the game many times under different allocation rules , And vote to choose which distribution method you prefer .
These data are used for training AI To imitate human behavior in the game , Including the way players vote .
secondly , The researchers made these AI Players compete with each other in thousands of games , And another one. AI System basis AI Players' voting methods continue to adjust the redistribution rules .
therefore , At the end of the process ,AI Redistribution rules that are very close to fairness have been established :
First ,AI Choose to allocate according to the proportion of relative contribution rather than absolute contribution . It means , When reallocating funds ,AI We will consider the initial amount of each player and their willingness to invest .
secondly ,AI The system specially rewards players who contribute more generously , To encourage others to do the same . It is important to , AI can only discover these rules by maximizing human voting rate .
Can this method be extended to reality ?
although DeepMind The game test of has achieved brilliant results , But to transform this approach from a simple four person game to a large-scale economy , It is still a huge challenge , At present, it is uncertain how it will develop in the real world .
secondly , The researchers themselves found several potential problems .
Democratic One problem is that it may develop into “ Tyranny of the majority ”, This will lead to the persistence of existing discrimination or unfair patterns against minorities .
AI More work needs to be done to understand how design allows everyone's voice to be heard .
in addition , The researchers also raised people's concerns about AI The question of trust :
Whether people will trust by AI Designed mechanisms to replace humans ? If people know the identity of the referee , Will it affect the final voting result ?
If you want to Democratic AI Designed solutions are used to solve real-world dilemmas , This is crucial .
Reference link : [1]https://www.deepmind.com/publications/human-centred-mechanism-design-with-democratic-ai [2]https://www.nature.com/articles/s41562-022-01383-x [3]https://singularityhub.com/2022/07/04/deepminds-new-ai-may-be-better-at-distributing-societys-resources-than-humans-are/
— End —
「 Artificial intelligence 」、「 Smart car 」 Wechat community invites you to join !
Welcome to AI 、 Smart car partners join us , And AI Practitioners exchange 、 Compare notes , Don't miss the latest industry development & Technological progress .
ps. Please note your name when adding friends - company - Position oh ~
Focus on me here , Remember to mark the star ~
One key, three links 「 Share 」、「 give the thumbs-up 」 and 「 Looking at 」
The frontier of science and technology meets day by day ~
边栏推荐
猜你喜欢

DeSci:去中心化科学是Web3.0的新趋势?
Continuous test (CT) practical experience sharing

Will low code help enterprises' digital transformation make programmers unemployed?

ES6笔记一

gsap动画库
![Learn open62541 -- [67] add custom enum and display name](/img/98/e5e25af90b3f98c2be11d7d21e5ea6.png)
Learn open62541 -- [67] add custom enum and display name
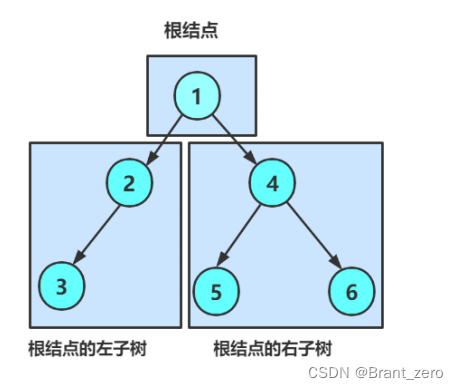
Basic operation of chain binary tree (implemented in C language)

The live broadcast reservation channel is open! Unlock the secret of fast launching of audio and video applications
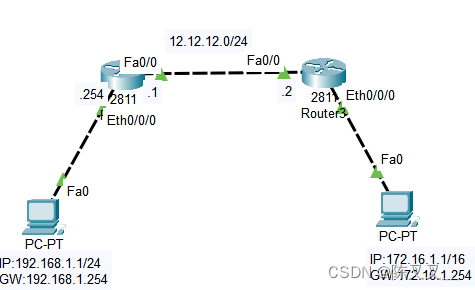
静态路由配置

Industry case | digital operation base helps the transformation of life insurance industry
随机推荐
RIP和OSPF的区别和配置命令
6.关于jwt
Antisamy: a solution against XSS attack tutorial
Calculation of torque target value (ftorque) in servo torque control mode
Will low code help enterprises' digital transformation make programmers unemployed?
初识缓存以及ehcache初体验「建议收藏」
手把手教姐姐写消息队列
Sports Federation: resume offline sports events in a safe and orderly manner, and strive to do everything possible for domestic events
Thread factory in thread pool
The live broadcast reservation channel is open! Unlock the secret of fast launching of audio and video applications
Comparison and selection of kubernetes Devops CD Tools
SD_ DATA_ SEND_ SHIFT_ REGISTER
ip netns 命令(备忘)
Do you know all four common cache modes?
Will domestic software testing be biased
PTA 1102 教超冠军卷
Kubernetes DevOps CD工具对比选型
国内的软件测试会受到偏见吗
微信网页调试8.0.19换掉X5内核,改用xweb,所以x5调试方式已经不能用了,现在有了解决方案
Rules for filling in volunteers for college entrance examination