当前位置:网站首页>Save the memory of the model! Meta & UC Berkeley proposed memvit. The modeling time support is 30 times longer than the existing model, and the calculation amount is only increased by 4.5%
Save the memory of the model! Meta & UC Berkeley proposed memvit. The modeling time support is 30 times longer than the existing model, and the calculation amount is only increased by 4.5%
2022-07-07 18:34:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
CVPR 2022 The paper 『MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition』,Facebook&UC Berkeley Put forward MeMViT, Modeling time support is longer than existing models 30 times , Calculation amount only increases 4.5%
The details are as follows :

Thesis link :https://arxiv.org/abs/2201.08383
01
Abstract
Although today's video recognition systems accurately parse short clips , But they can't reason in a longer time frame . Most existing video architectures can only handle <5 The second video , Without encountering computing or memory bottlenecks .
In this paper , The author proposes a new strategy to overcome this challenge . The author proposes to process video online , And cache at each iteration “ memory ”, Instead of processing more frames at a time like most existing methods . Through memory , The model can refer to the previous context for long-term modeling , Just marginal cost . Based on this idea , The author constructed MeMViT, A memory enhanced multiscale vision Transformer, Its time support is longer than existing models 30 times , Calculation amount only increases 4.5%; Traditional methods need to exceed 3000% To complete the same operation .
In a wide range of settings ,MeMViT The increase of support time brings a great improvement in consistent recognition accuracy .MeMViT stay AVA、EPIC-Kitchens100 Get the most advanced results on the action classification and action prediction data set .
02
Motivation
as time goes on , Our world is constantly evolving . Events at different points in time interact , Tell the story of the visual world together . Computer vision is expected to understand this story , But today's system is still quite limited . They can be in separate snapshots or short clips ( for example 5 second ) Accurately analyze the visual content , But not beyond this time period . that , How can we achieve accurate long-term visual understanding ? Of course , There are many challenges ahead , But having a model that can run on long videos is an important first step .
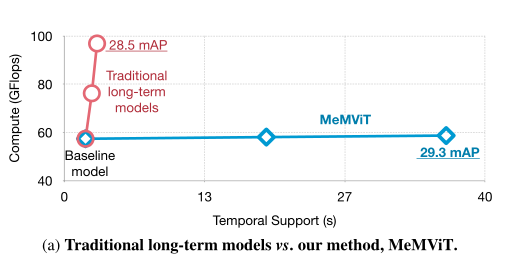
In this paper , The author proposes a memory based method to construct an effective long-term model . The central idea is not to jointly process or train the entire long video , Instead, keep... While processing video online “ memory ”. At any time , Models can access the previous memory of long-term context . Because memory is from the past “ reusing ” Of , So the model is very efficient . In order to realize this idea , The author constructed a system called MeMViT Specific model of ,MeMViT It is a memory enhanced multi-scale vision Transformer.MeMViT Processing input takes longer than existing models 30 times , Calculation amount only increases 4.5%. by comparison , The long-term model established by increasing the number of frames will need to exceed 3000% The calculation of . The figure above shows the calculation / The trade-off comparison of duration .
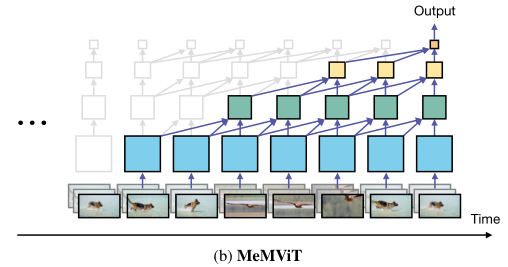
To be specific ,MeMViT Use Transformer Of “ key ” and “ value ” As a memory . When the model runs on a fragment ,“ Inquire about ” Involving a set of extensions “ key ” and “ value ”, They come from the present time and the past . When performing this operation on multiple layers , Each layer will go deep into the past , Thus producing significantly longer receptive fields , As shown in the figure above .
In order to further improve efficiency , The author jointly trained a memory compression module , To reduce memory usage . Intuition , This allows the model to understand which clues are important for future recognition , And keep only these clues .
The design inspiration of this paper comes from how human beings analyze long-term visual signals . Human beings will not process all signals at the same time for a long time . contrary , Humans process signals online , Connect what we see with past memories to understand past memories , And memorize important information for future use .
The results of this paper show that , Using memory to enhance video model and realize remote attention is simple and very beneficial . stay AVA Space time action positioning 、EPIC-Kitchens-1001 Action classification and EPIC-Kitchens-100 On the action prediction data set ,MeMViT Greater performance gains than other models , And achieved the most advanced results .
03
Preliminaries
Vision Transformers (ViT)
Vision Transformer(ViT) First, embed the image into N A non overlapping patch in ( Use step convolution ), And its embed Arrival tensor . then , a pile Transformer These layers... Yes patch Modeling the interaction between .Transformer The central component of the layer is to pay attention to operation , It will first input the tensor X Linear projection is a query Q、 key K And the value V:
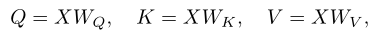
And perform self attention operation , Obtain the output tensor .
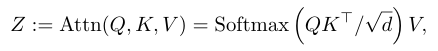
Multiscale Vision Transformers (MViT)
Multiscale vision Transformer(MViT) Improved based on two simple ideas ViT. First ,MViT There is no fixed resolution in the whole network N, Instead, learn multi-scale representation through multiple stages , From smaller patch Fine grained modeling ( Big N And small d) Start , In the later stage, it is larger patch Advanced modeling ( Small N And big d). The transition between phases is accomplished by pooling across phases . secondly ,MViT Use pooled attention (P), Pooling Q、K and V The space-time dimension of , To significantly reduce the computational cost of the attention layer , namely :
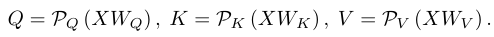
These two changes have significantly improved the performance and efficiency of the model . In this paper , The author based on slightly modified MViT The method of this paper is constructed , Among them, the author exchanged the order of linear layer and pooling :
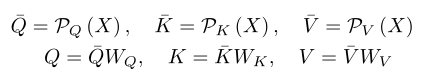
This allows the linear layer to operate on smaller tensors , Reduce computing costs , Without affecting the accuracy .
04
Method
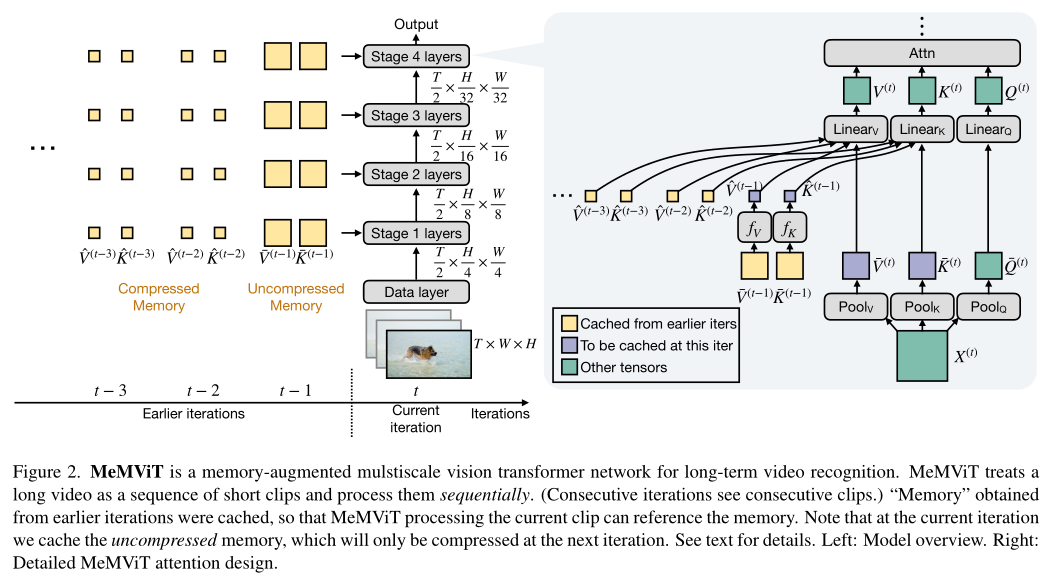
The method in this paper is very simple . The author divides the video into a series of short T×H×W A fragment , And deal with it in sequence ( For training and reasoning ). The author caches at each iteration “ memory ”, That is, some representations of processed fragments . When in the time step t When processing the current clip , Models can access early iterations
For long-term context . The figure above shows the overview.
4.1. Memory Attention and Caching
The Basic MeMViT Attention
A simple way to realize this idea is to transformer The structure of the “ key ” and “ value ” As a form of memory , And in the current iteration t And , To include the sum of early iterations from and :
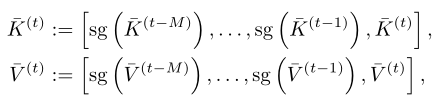
among , Square brackets indicate concat. Use this formula , Inquire about Q Not only the current time step t Information about , And it also involves up to M Step information . here ,“ Stop the gradient ” The operator (sg) In the back-propagation, it further breaks the dependence on the past . Memory is structured hierarchically over time ( See above b), The previous key and value memory holds the information stored in the previous time step .
The additional costs of training and reasoning include only those used for memory caching GPU Extra computation in memory and extended attention layer . All other parts of the network (MLP etc. ) remain unchanged . The cost increases with the support of time , The complexity is . The author caches the complete key and value tensors , These tensors may contain redundant information that is not useful for future identification .
4.2. Memory Compression
Naive Memory Compression
There are many potential ways to compress memory , But an intuitive design attempts to combine training compression modules ( for example , Learnable pooling operators ) and , To reduce K and V The space-time size of tensor :
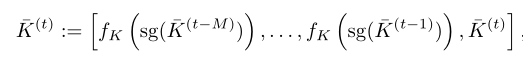
The same is true for . Use this design , When reasoning, you only need to cache and process “ Compress ” Memory and , Thus, memory occupation and calculation cost are reduced . However , During the training , It requires joint training of all “ complete ” Memory tensor of , So this may actually increase the calculation and cost of memory , Make it expensive to obtain such a model . For long-term modeling M Larger models , The cost of higher .
Pipelined Memory Compression
To solve this problem , The author puts forward a kind of pipelined Compression method . Although the compression module and need to run on uncompressed memory and carry out joint optimization , In order to learn the important content that needs to be retained , But learning modules can be shared in all past memories . therefore , The author suggests that training only compresses memory once , namely :
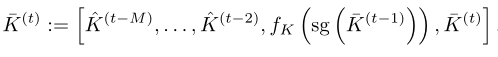
The same is true for . The right side of the figure above shows this design . Note that only the memory from the previous step in the cache is uncompressed , And used to train in the current iteration . From to
402 Payment Required
It has been compressed in the previous iteration . The following figure shows the pseudo code of this step .
such ,MeMViT Only than the foundation MeMViT Added “ Fix ” The compression cost , Because it only runs compression on one step at a time . however , It greatly reduces the cache and attention costs of all other steps . An attractive feature of this design is , The receptive field of the video model not only follows M To increase by , And with the number of layers L To increase by , Because each layer will go further into the past , therefore , The time receptive field will increase in layers with the increase of depth .
4.3. Implementation Details
Data Loading
In the process of training and reasoning , For consecutive frame blocks ( fragment ) Read sequentially , Process videos online . In the implementation of this article , just concat All videos and read them in order . When the cache memory comes from the previous video ( namely , At the video boundary ), The author will remember mask zero .
Compression Module Design
The compression module can be reduced token Quantity but keep dimension d Any function of . In the instantiation of this article , The author chose a learnable pool , Because it is simple and powerful , But there are other options .
Positional Embedding
In primitive MViT in , Absolute location embedding is added to the input of the network , Each segment is embedded in the same position . therefore , Position embedding can only indicate the position within the segment , It cannot indicate the order between multiple fragments . therefore , The author adopts “ The improved MViT” Relative position embedding used in , Therefore, memory and query at different time points have different relative distances .
05
experiment
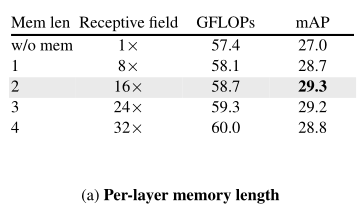
The above table compares the memory lengths with different layers (M) Model of . The author found , And baseline Compared with the short-term model , All models that increase memory have improved significantly (mAP The absolute gain in is 1.7-2.3%). Interestingly , This behavior is not very sensitive to the choice of memory length . The memory length of each layer is 2, Corresponding to 16× Bigger (36 second ) Feeling field of , You can get AVA Best performance of . In the following A V A In the experiments , Author use M=2 As default .
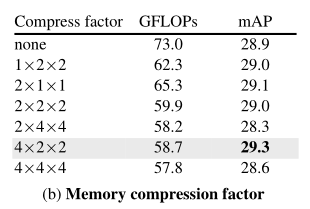
The above table compares the compression modules with different down sampling factors . The author found , While achieving strong performance , Sampling under time (4×) Sampling under specific space (2×) To a greater extent . Interestingly , Compared with the model without compression , The compression method in this paper actually improves the accuracy . This supports the hypothesis of this paper , That is, in learning and memory “ What to keep ” It may suppress irrelevant noise and contribute to learning . Because of its powerful performance , The author defaults to 4×2×2 Downsampling factor ( Respectively for time 、 Height and width ).
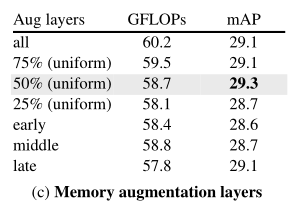
In the above table , The authors explored the need to increase memory at all levels of attention , If you don't need to , Which layer is the most effective to increase memory . Interestingly , The author finds it unnecessary to deal with memory on all levels . Besides , Placing them evenly throughout the network is better than concentrating them early ( Stage 1 and 2) layer 、 Mid - ( Stage 3) Layer or late ( Stage 4) Layer effect is slightly better .
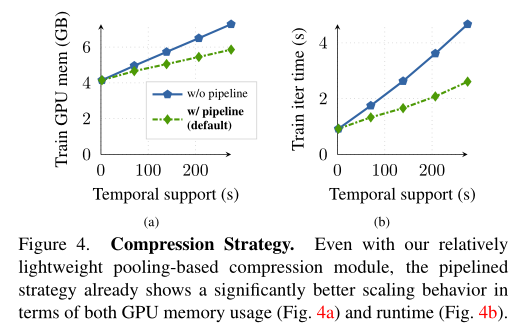
Last , The author compares Pipelined Compression strategy and no Pipelined The basic version of the zoom behavior . You can see , Even with relatively lightweight pooled compression modules ,Pipelined The strategy is GPU Memory usage ( Upper figure a) And run time ( Upper figure b) Aspect has shown significantly better scaling behavior . therefore , The author in MeMViT It is used by default .
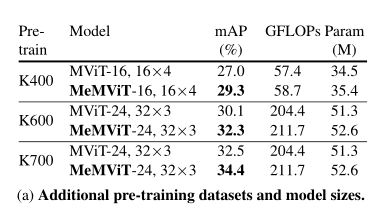
The table above shows , Although the pre training data set and model size settings are different ,MeMViT Provides a shorter term model than the original (MViT) Consistent performance gains , This shows that the method in this paper has good versatility .
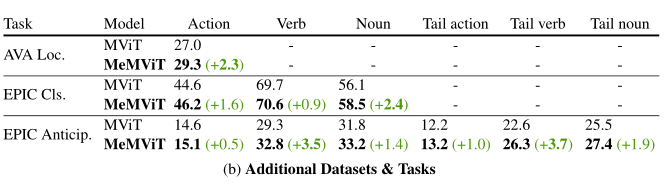
The table above shows EPIC-Kitchens-100 Action classification and EPIC-Kitchens-100 The result of action prediction . The model used here is similar to AVA The default model used “MeMViT-16,16×4” identical , Is only for EPIC Kitchens, The author found that using M=4(32× long-term , or 70.4 Second feeling field ) The effect of long-term model is the best .
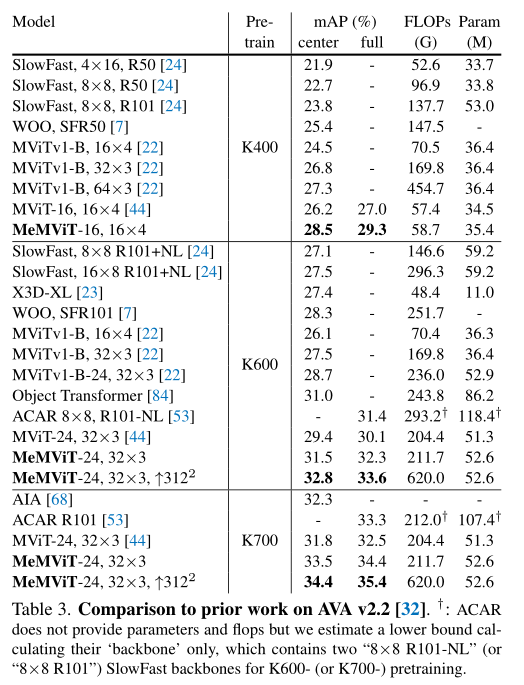
The above table compares MeMViT And AVA v2.2 Previous work on the dataset . You can find , Under all pre training settings ,MeMViT Higher accuracy than previous work , At the same time, it has comparable or even less FLOPs And parameter quantities .
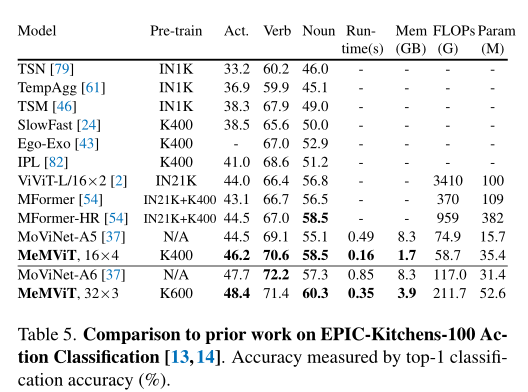
The table above shows EPIC-Kitchens-100 The result of the action classification task , It can be seen that ,MeMViT Once again, it is superior to all previous work , Including based on CNN Based on ViT Methods .
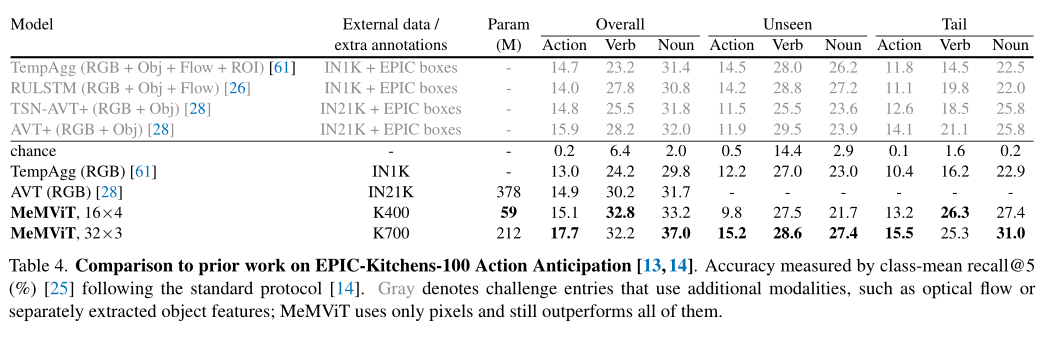
The table above shows EPIC-Kitchens-100 Result of action prediction task , It can be seen that ,MeMViT Better than all previous work , Including work using multiple modes , Such as optical flow 、 Separately trained object feature extractor and large-scale pre training .
06
summary
Long term video understanding is an important goal of computer vision . Do that , Having a practical model for long-term visual modeling is a basic premise . In this paper , The author shows , Extending existing state-of-the-art models to include more input frames does not extend well . The memory based method proposed in this paper MeMViT Can be expanded more efficiently , And get better accuracy . The technology proposed in this paper is universal , Applicable to others based on Transformer Video model .
Reference material
[1]https://arxiv.org/abs/2201.08383

END
Join in 「Transformer」 Exchange group notes :TFM

边栏推荐
- Mobile pixel bird game JS play code
- 静态路由配置
- Performance test process and plan
- How to open an account for wealth securities? Is it safe to open a stock account through the link
- Introduction to OTA technology of Internet of things
- Skills of embedded C language program debugging and macro use
- [paddleseg source code reading] add boundary IOU calculation in paddleseg validation (1) -- val.py file details tips
- Tips for short-term operation of spot silver that cannot be ignored
- Chapter 2 building CRM project development environment (building development environment)
- Interviewer: why is the page too laggy and how to solve it? [test interview question sharing]
猜你喜欢

【Unity Shader】插入Pass实现模型遮挡X光透视效果
Click on the top of today's headline app to navigate in the middle

RIP和OSPF的区别和配置命令
SD_DATA_RECEIVE_SHIFT_REGISTER

性能测试过程和计划

讨论 | AR 应用落地前,要做好哪些准备?
The highest level of anonymity in C language

Pro2: modify the color of div block
How to clean when win11 C disk is full? Win11 method of cleaning C disk
![[C language] string function](/img/6c/c77e8ed5bf383b7c656f45b361940f.png)
[C language] string function
随机推荐
小试牛刀之NunJucks模板引擎
Tips for short-term operation of spot silver that cannot be ignored
【Unity Shader】插入Pass实现模型遮挡X光透视效果
The report of the state of world food security and nutrition was released: the number of hungry people in the world increased to 828million in 2021
What is the general yield of financial products in 2022?
性能测试过程和计划
PHP面试题 foreach($arr as &$value)与foreach($arr as $value)的用法
Main work of digital transformation
Test for 3 months, successful entry "byte", my interview experience summary
The highest level of anonymity in C language
讨论| 坦白局,工业 AR 应用为什么难落地?
zdog. JS rocket turn animation JS special effects
Live broadcast software construction, canvas Text Bold
debian10编译安装mysql
“解密”华为机器视觉军团:华为向上,产业向前
Hash, bitmap and bloom filter for mass data De duplication
Personal best practice demo sharing of enum + validation
回归问题的评价指标和重要知识点总结
[trusted computing] Lesson 13: TPM extended authorization and key management
磁盘存储链式的B树与B+树