当前位置:网站首页>Deep understanding of MySQL lock and transaction isolation level
Deep understanding of MySQL lock and transaction isolation level
2022-07-07 23:23:00 【Which floor do you rate, moto】
Catalog
Mysql Business and ACID Feature details
Problems caused by concurrent transaction processing
Mysql Transaction isolation level details
Mysql Transaction isolation level details
Temporary key lock (Next-key Locks)
No index row lock will be upgraded to table lock
see INFORMATION_ SCHEMA Data table related to system library lock
Case study of row lock and transaction isolation level
Mysql Business and ACID Feature details
summary
Our database usually executes multiple transactions concurrently , Multiple transactions may add, delete, modify and query the same batch of data concurrently , It may lead to what we call dirty writing 、 Dirty reading . It can't be read repeatedly 、 Read these questions .
The essence of these problems is the multi transaction concurrency of database , In order to solve the problem of multi transaction concurrency , Transaction isolation mechanism is designed for database 、 Locking mechanism 、MVCC Multi version concurrency control isolation mechanism , Use a set of mechanisms to solve the problem of multi transaction concurrency . Next , We will explain these mechanisms in depth , Let's thoroughly understand the execution principle inside the database .
Affairs and ACID attribute
The business is made up of a group of SQL A logical processing unit made up of statements , The transaction has the following 4 Attributes are usually referred to as transactional ACID attribute .
Atomicity (Atomicity): A transaction is an atom operation unit , Its modifications to the data are either all implemented , Or none of them .
Uniformity (Consistent): At the beginning and end of the transaction , data Must be consistent . This means that all relevant data rules must be applied to the modification of the transaction , To maintain the integrity of the data .
Isolation, (solation) : The database system provides a certain isolation mechanism , Ensure that transactions are not affected by external concurrent operations “ Independent environment execution . This means that the intermediate state in the transaction process is not visible to the outside . vice versa .
persistence (Durable) : After the transaction completes , Its modification of data is permanent . Even if there is a system failure, it can keep .
Problems caused by concurrent transaction processing
Update missing (Lost Update) Or dirty writing
When two or more transactions select the same row , When the row is then updated based on the originally selected value , Because each transaction does not know the existence of other transactions , There will be a problem of missing updates The last update covers the updates made by other firms .
Dirty reading (Dirty Reads)
A transaction is modifying a record , Before this transaction is completed and committed , The data of this record is in an inconsistent state ; At this time , Another transaction also reads the same record , If not controlled , The second transaction reads these “ dirty “ data , And further processing based on it , Uncommitted data dependency will be generated . This phenomenon is called by image “ Dirty reading ".
In a word : Business A Transaction read B Data that has been modified but not yet submitted , On the basis of this data, we have done the operation . here , If B Transaction rollback , A Invalid data read , Does not meet conformance requirements .
It can't be read repeatedly (Non-Repeatable Reads)
A time after a transaction reads some data , Read the previously read data again , But the data they read has changed . Or some records have been deleted ! This phenomenon is called unrepeatable ”.
In a word : Business A The results read by the same internal query statement at different times are inconsistent , Nonconformance isolation
Fantasy reading (Phantom Reads)
A transaction re reads the previously retrieved data according to the same query criteria , However, it is found that other transactions have inserted new data satisfying their query criteria , This phenomenon is called “ Fantasy reading ".
Mysql Transaction isolation level details
Mysql Transaction isolation level details
Dirty reading , No repeated reading or phantom reading , In fact, it's all about database read consistency , A database must provide a certain transaction isolation mechanism to solve
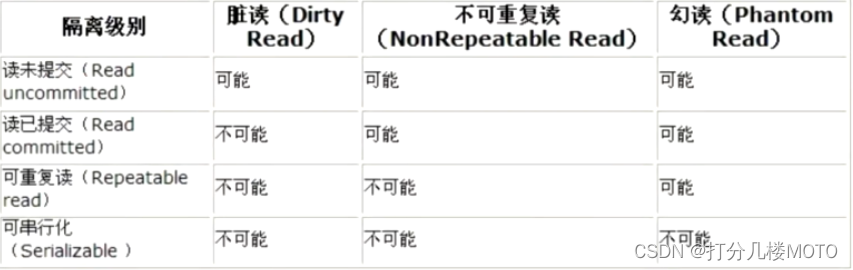
The more strict the transaction isolation of the database , The less side effects , But the more it costs , Because transaction isolation essentially makes transactions to a certain extent “ Serialization “ Conduct , This is obviously related to " Concurrent ” Is contradictory .
meanwhile , Different applications have different requirements for read consistency and transaction isolation Begging is also different , For example, many applications are right for “ It can't be read repeatedly " and “ Unreal reading is not sensitive , Perhaps more concerned about the ability of concurrent data access .
View the transaction isolation level of the current database : show variables like 'tx_ _isolation';
Set the transaction isolation level : set tx_ jisolation="REPEATABLE-READ';
Mysq| The default transaction isolation level is repeatable read , use Spring When developing programs , If you do not set the isolation level, the default is Mysq| Set the isolation level of , If Spring If it is set, the isolation level that has been set will be used
Mysql Lock mechanism details
Lock details
A lock is a mechanism by which a computer coordinates multiple processes or threads to access a resource concurrently . In the database , In addition to traditional computing resources ( Such as CPU. RAM. I/0 etc. ) Beyond contention , Data is also a kind of supply and demand Resources to be shared by users . How to ensure the consistency of data concurrent access 、 Validity is a problem that all databases must solve , Lock conflicts are also an important factor affecting the performance of concurrent database access .
Lock classification
In terms of performance, it can be divided into Optimism lock ( Use version comparison to achieve ) and Pessimistic locking
From the type of database operation , It is divided into Read the lock and Write lock ( All belong to pessimistic lock )
Read the lock ( Shared lock , S lock (Shared)) : For the same data , Multiple read operations can be performed simultaneously without affecting each other
Write lock ( Exclusive lock ,X lock (eXclusive) : Before the current write operation is completed , It blocks other write and read locks
From the granularity of data operations , It is divided into table lock and row lock
Table locks
Lock the whole table with each operation , Small expenses and fast sales ; A deadlock will not occur ; Large locking size , The highest probability of lock collisions , Lowest degree of concurrency , One It is generally used in the scenario of whole table data migration .
# Add meter lock by hand lock table The name of the table read(write),, The name of the table 2 read(write); # View the lock added to the table show open tables; # Delete table lock unlock tables;
case analysis ( Add read lock )
Lock table myLock read;
At present session And others session You can read the watch
At present session Insert or update locked tables in will report errors , other session Insert or update will wait
case analysis ( Add write lock )
Lock table myLock write;
At present session There is no problem with the addition, deletion, modification or search of this table , other session All operations on the table are blocked
Conclusion of the case
Yes MyISAM Read operation of table ( Add read lock ) , It will not block other processes from reading the same table , But it will block the write request for the same table . Only when the read lock is released , To perform other process write operations .
Yes MyISAM Write operation of table ( Add write lock ), Will block other processes to read and write to the same table , Only when the write lock is released , Will perform read and write operations of other processes
Row lock
Lock one row of data per operation . Spending big , Lock the slow ( First, find a table , Then find a line from the table ); A deadlock occurs ; Locking granularity minimum , The lowest probability of lock collisions , Highest concurrency .
InnoDB And MYISAM There are two big differences :
InnoDB Support transactions (TRANSACTION)
InnoDB Row level locking is supported
Row lock Demo
One by one session Enable transaction updates without committing , the other one session Updating the same record will block , Updating different records will not block
summary
MyISAM In the execution of the query statement SELECT front , Will automatically lock all tables involved , In execution update、insert delete The operation will automatically add write locks to the tables involved .
InnoDB In the execution of the query statement SELECT when , Because there is mvcc The mechanism does not lock . however update、 insert. delete The operation will add line lock .
In short , It's just that reading locks block writing , But it doesn't block reading . A write lock blocks both reading and writing .
Clearance lock (Gap Lock)
- Clearance lock , Lock is the gap between two values .Mysql The default level is repeatable-read, Is there a way to solve the unreal reading problem ? Gap lock can solve the unreal reading problem in some cases . hypothesis account The data in the table are as follows :
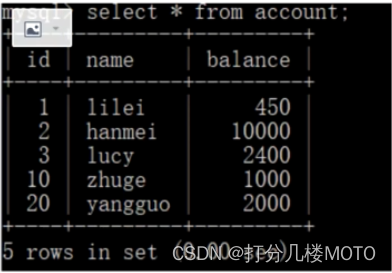
- Missing 3-10,10-20,20- Three intervals of positive infinity , Then the gap is id by (3,10), (10,20), (20, It's just infinite )
- stay Session_ 1 Following execution update account set name = 'zhuge' where id > 8 and id <18;, Other Session Can't be here All line records contained in the range ( Whether this row record exists or not ) And the gap in the range is recorded ( Whether this row record exists or not ) In all the gaps of the original table Insert or modify any data , namely id stay (3,20] Data cannot be modified in any interval , Pay attention to the last one 20 Also included . At this time, if other transactions are inserted id stay (3,20] The data line , It will block uniformly , Solved unreal reading
- The gap lock is only effective at the repeatable read isolation level .
Temporary key lock (Next-key Locks)
- Next-Key Locks It's a combination of row lock and clearance lock . Like this in the above example (3,20] The whole interval of can be called critical lock .
No index row lock will be upgraded to table lock
- The lock is mainly added to the index , If you update a non indexed field , Row locks may become table locks
- session1 perform : update account set balance = 800 where name = lilei; If name Not an index or no index , Then row lock will become table lock
- session2 Any operation on any row of the table will block
- InnoDB The row lock of is the lock added for the index , It's not a lock on records 、 And the index cannot be invalidated , Otherwise, it will be upgraded from row lock to table lock .
- You can also lock a row with lock in share mode( Shared lock ) and for update( Exclusive lock ), for example : select * from test_ innodb_ lock where a = 2 for update; So other session Only this line of data can be read , Modification will be blocked , Until the row is locked session Submit
Conclusion
- Innodb The storage engine implements row level locking , Although the performance loss caused by the implementation of locking mechanism may be higher than that of table level locking , But it's much better than MYISAM The watch level is locked . When the system concurrency is high ,Innodb The overall performance and MYISAM There will be obvious advantages in comparison . however ,Innodb Row level locking also has its vulnerability - Noodles , When we don't use it properly , May let Innodb The overall performance of MYISAM high , Even worse .
Line lock analysis
- clear through InnoDB_ _row_ lock State variables are used to analyze the contention of row locks on the system
show status like 'innodb_row_ 1ock%' ;
The description of each state quantity is as follows :
- Innodb_ row_ lock_ current_ waits: The number of currently waiting locks
- Innodb_ row_ lock_ _time: The total length of time from system startup to lock up
- Innodb_ row_ _lock_ time_ avg: The average time it takes to wait
- Innodb_ row_ lock_ time_ max: The longest waiting time from system startup to now
- Innodb_ row_ _lock_ waits: The total number of times the system has been waiting since it was started
For this 5 Two state variables , The more important thing is :
- Innodb_ row_ lock_ _time_ _avg ( wait for Average duration )
- Innodb_ row_ _lock_ _waits ( Total waiting times )
- Innodb_ row_ _lock_ time ( The total waiting time )
Especially when waiting times are high , And every time the waiting time is not small , We need to analyze why there are so many waits in the system , Then according to the results of the analysis to develop optimization plan .
see INFORMATION_ SCHEMA Data table related to system library lock
-- View transactions
select * from INFORMATION_ SCHEMA. INNODB_ _TRX;
-- Check the lock
select * from INFORMATION_ SCHEMA. INNODB_ LOCKS;
-- View lock wait
select * from INFORMATION_ SCHEMA. INNODB_ _LOCK_ WAITS ;
-- Release the lock ,trx_ mysq1_ _thread_ id It can be downloaded from INNODB_ _TRX See in the table
kill trx_ mysql_ _thread_ _id
Deadlock
- set tx_ isolation='repeatable-read;
- Session_1 perform : select * from account where id=1 for update;
- Session_2 perform : select * from account where id=2 for update;
- Session_1 perform : select * from account where id=2 for update;
- Session_2 perform : select * from account where id=1 for update;
- Check the recent deadlock log information : show engine innodb status\G;
- In most cases mysq Deadlock can be detected automatically and the transaction that generated the deadlock can be rolled back , But in some cases mysq Can't automatically detect deadlocks
Lock optimization suggestions
- As far as possible, all data retrieval should be done through index , Avoid upgrading non indexed row locks to table locks
- Design index reasonably , Try to narrow down the range of locks
- Minimize the range of search conditions , Avoid gap locks
- The gap id by (3,10), (10,20), (20, It's just infinite ) These three intervals , stay Session_ 1 Following execution update account set name = 'zhuge' where id > 8 and id <25, If the search condition range is this , Then the scope of the lock is (3, It's just infinite ); If you are inserting a id by 26 The data of , The gap id by (3,10), (10,20), (20,26),(26, It's just infinite ) Then the scope of the lock is (3,26], Greatly reducing the range of locks
- Try to control the transaction size , Reduce the amount of locked resources and the length of time , Involving transaction locking sq| Try to put it at the end of the transaction
- As low level transaction isolation as possible
Case study of row lock and transaction isolation level
Read uncommitted
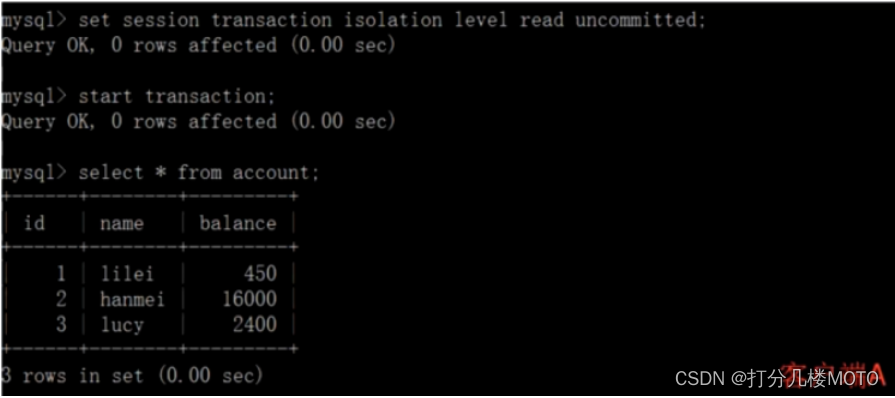
Open a client A, And set the current transaction mode to read uncomlmitted ( Uncommitted read ), Query table account The initial value of the :
set tx_ isolation='read-uncommitted'
On the client side A Before the transaction is committed , Open another client B, Update table account:
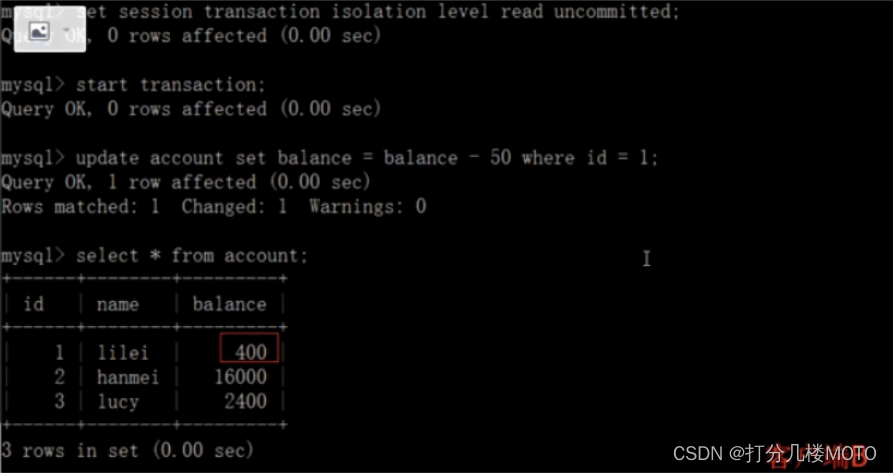
At this time , Although the client B The business of has not been submitted , But the client A You can find B Updated data
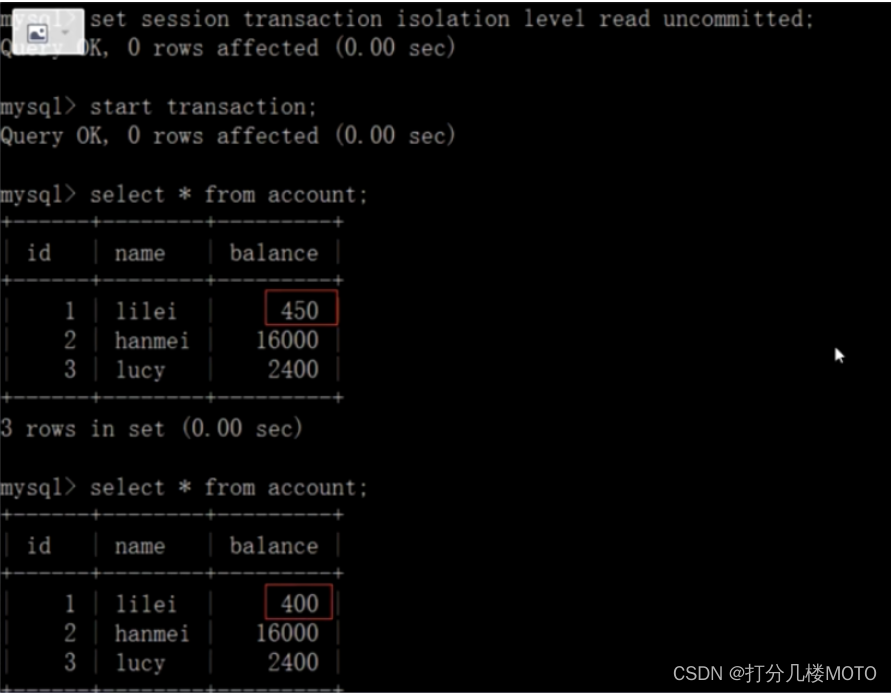
Once the client B The transaction of is rolled back for some reason , All operations will be undone , That client A The data queried is actually dirty data :
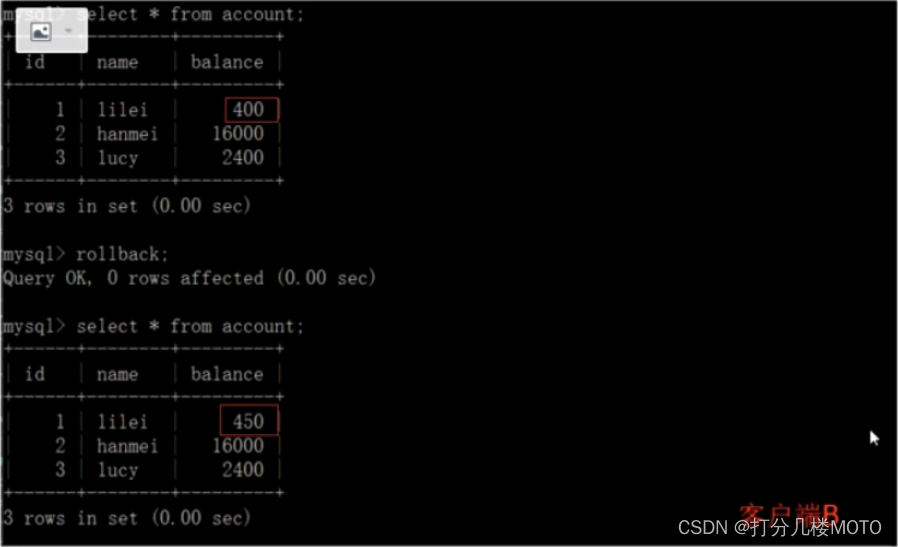
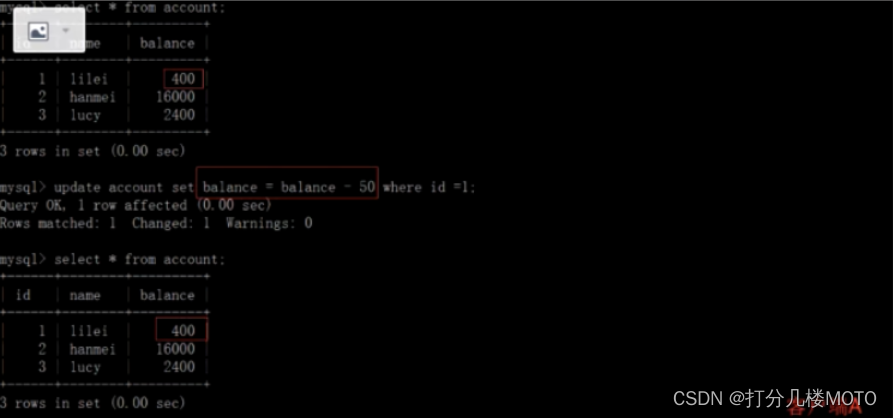
On the client side A Execute UPDATE statement update account set balance = balance - 50 where id =1. lilei Of balance Did not become 350, was 400, Isn't that weird? , The data are inconsistent , It would be naive of you to think so , In the application , We will use 400-50=350, I didn't know that other sessions rolled back , To solve this problem, we can adopt Read the submitted isolation level
As can be seen from the above Business A Transaction read B Data that has been modified but not yet submitted Dirty reading ; The query operation is performed at two time points of transaction execution , Data inconsistency occurs It can't be read repeatedly ; If the transaction B Insert a new data transaction A You can also read Phantom reading
Read submitted
- Open a client A, And set the current transaction mode to read committed ( Uncommitted read ), Query table account All records :set tx_ _isolation='read-committed';
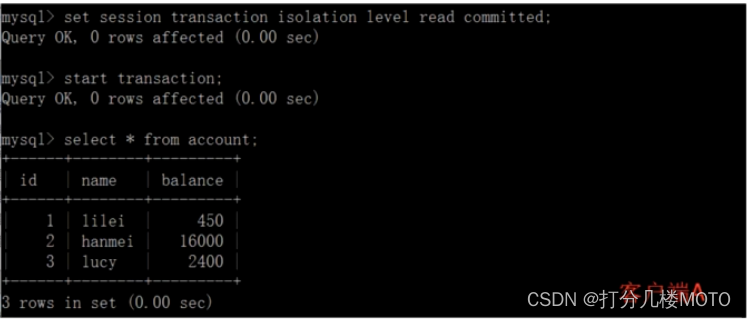
- On the client side A Before the transaction is committed , Open another client B, Update table account:
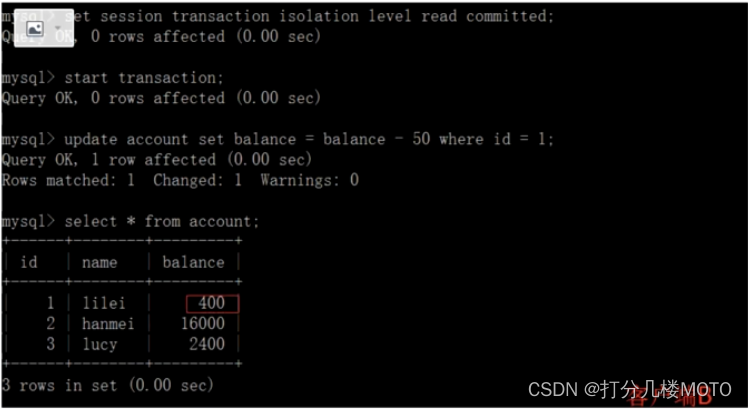
- At this time , client B The business of has not been submitted , client A Can't find B Updated data , Solved the problem of dirty reading :
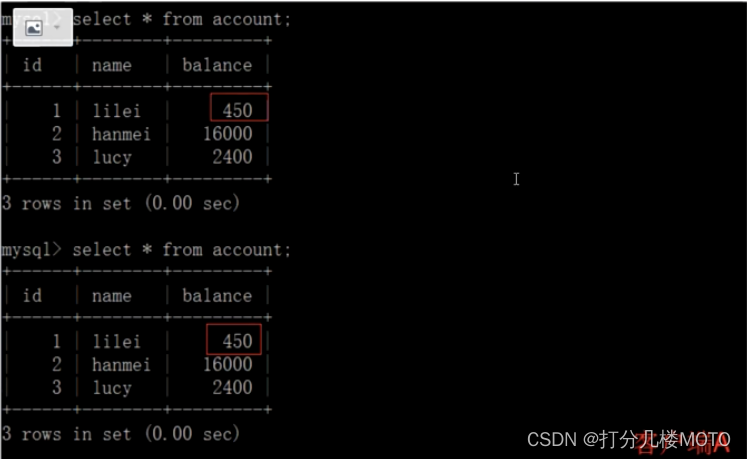
- client B Transaction commit for
- client A Execute the same query as in the previous step , The result is different from the previous step - Cause , That is to say, there is the problem of non repetition
Repeatable
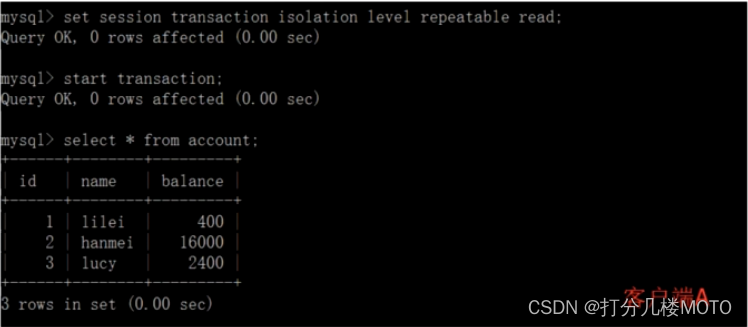
Open a client A, And set the current transaction mode to repeatable read, Query table account All records
set tx_ isolationt'repeatable-read";
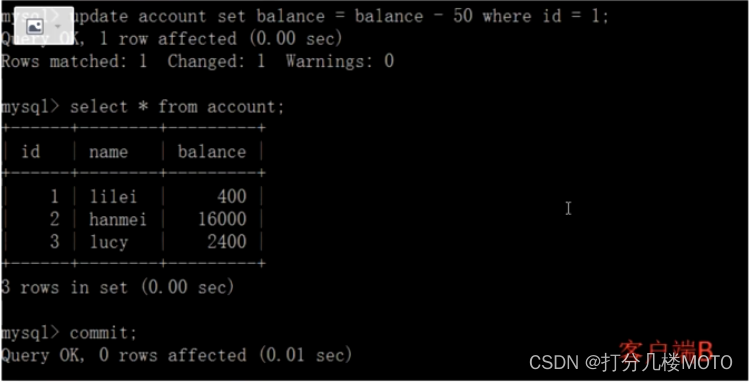
- On the client side A Before the transaction is committed , Open another client B, Update table account And submit
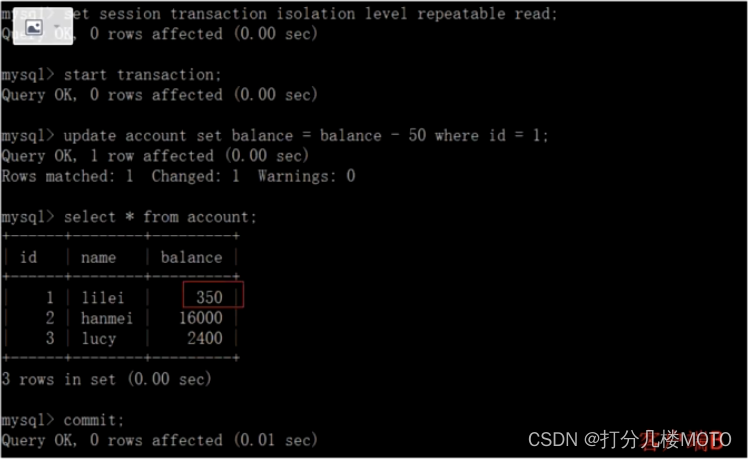
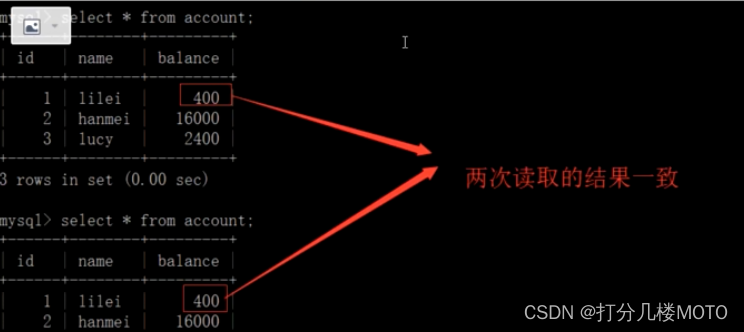
- On the client side A Query table account All records , And steps (1) Query results - Cause , There is no non repeatable reading problem , But the real value in the database is 350, No matter whether other matters have been modified , How much after the transaction starts . How much is it if the value is not modified before the end of the transaction
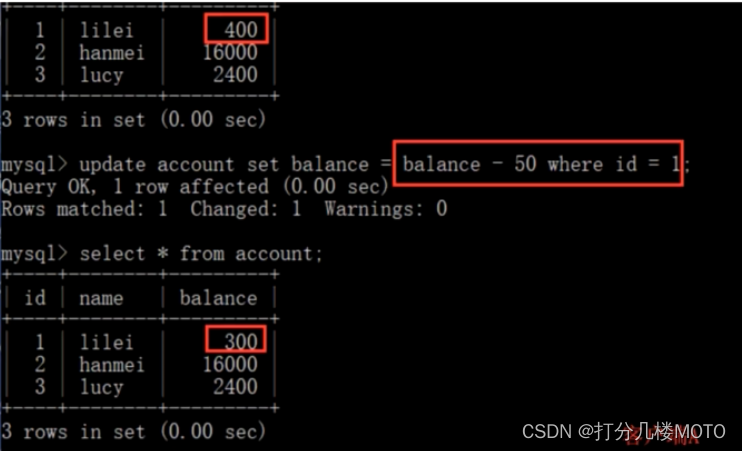
- On the client side A, Then perform update account set balance = balance - 50 where id = 1, balance Did not become 400-50=350, It is 350-50=300. so ilei Of balance It's worth the steps 2 Medium 350 To calculate , So it is 300, The consistency of the data has not been broken . Used under the isolation level of repeatable reading MVCC(multi-version concurrency control) Mechanism ,select Operation will not update version number , It's snapshot reading ( Version history ) ; insert,update and delete Will update version number , It's the current reading ( current version ).
- Reopen the client B, Insert a piece of data and submit ( Note that the client B Not yet submitted , therefore id by 1 The row of data is still unchanged , Although the business A This value has been changed again )
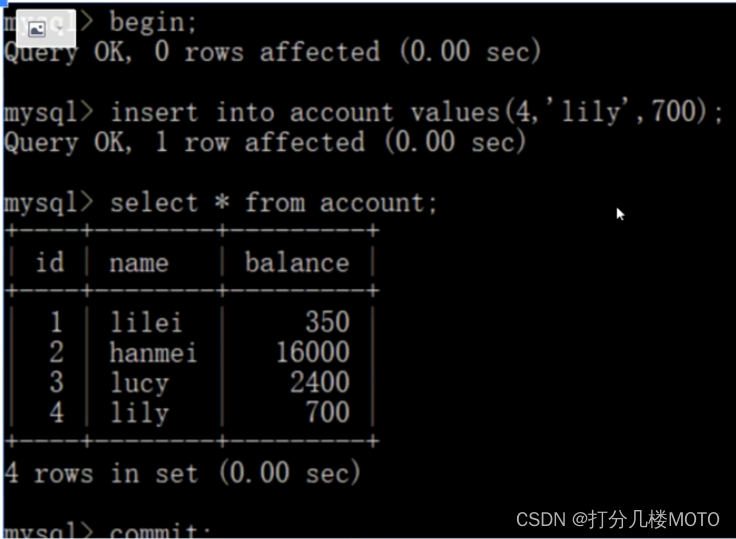
- On the client side A Query table account All records , No new data found , So there is no unreal reading
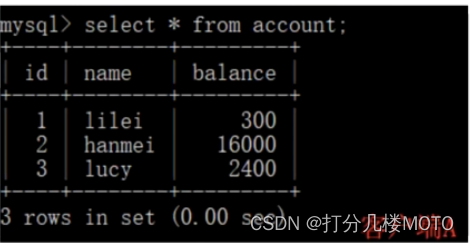
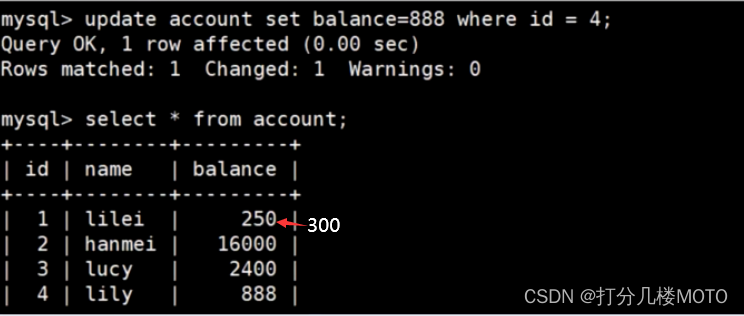
- Verify unreal reading : On the client side A perform update account set balance-888 where id = 4; Can update successfully , You can find the client again B New data ( Repeatable reading can't completely solve phantom reading ,select Statement does not lock )
Serializable
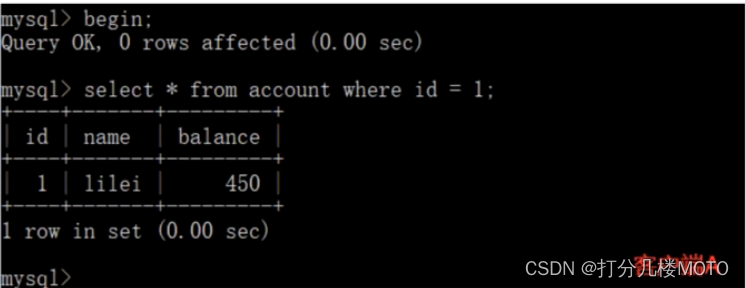
- open - A client A, And set the current transaction mode to serializable, Query table account The initial value of the :
set tx_ isolation='serializable';
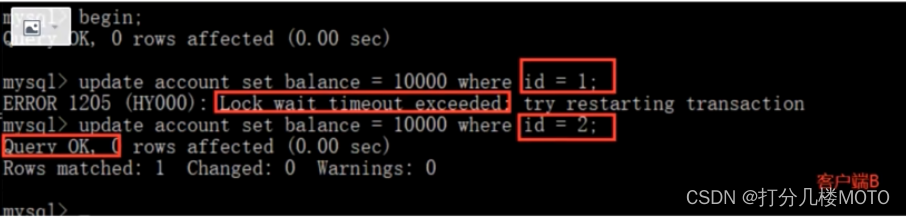
- open - A client B, And set the current transaction mode to serializable, Update the same id by 1 Your records will be blocked waiting , to update id by 2 Your record can be successful , Description in serial mode innodb The query will also be locked ; If the client A Executing a range query , Then all lines within this range include the gap interval range where each line of records is located ( Even if the row data has not been inserted, it will be locked , This is a clearance lock ) Will be locked . At this point, if the client B Inserting data within this range will be blocked , So we avoid unreal reading . This isolation level is extremely low in concurrency , It's rarely used in development .
- Be careful , The guest line is to lock the queried data , If the transaction A Enter query id by 1 The data of , The transaction B You can modify , Add other data rows (id Not for 1), This is equivalent to a transaction B Lock these data rows ; Business A It is impossible to query these data , Modify or delete
边栏推荐
- Inftnews | the wide application of NFT technology and its existing problems
- [microservices SCG] gateway integration Sentinel
- Dynamics 365 find field filtering
- Unity3D学习笔记4——创建Mesh高级接口
- Gee (III): calculate the correlation coefficient between two bands and the corresponding p value
- Unity3D学习笔记6——GPU实例化(1)
- 网络安全-联合查询注入
- USB (十八)2022-04-17
- Matlab 信号处理【问答随笔·2】
- Matlab SEIR infectious disease model prediction
猜你喜欢
2021icpc Shanghai h.life is a game Kruskal reconstruction tree
PCI-Express接口的PCB布线规则
When copying something from the USB flash disk, an error volume error is reported. Please run CHKDSK
十四、数据库的导出和导入的两种方法

Wechat forum exchange applet system graduation design completion (6) opening defense ppt

JMeter interface automated test read case, execute and write back result
聊聊支付流程的设计与实现逻辑

Vulnerability recurrence ----- 49. Apache airflow authentication bypass (cve-2020-17526)
2021ICPC上海 H.Life is a Game Kruskal重构树

Wechat forum exchange applet system graduation design completion (7) Interim inspection report
随机推荐
Advantages and disadvantages of rest ful API
Add data analysis tools in Excel
kubernetes的简单化数据存储StorageClass(建立和删除以及初步使用)
2021icpc Shanghai h.life is a game Kruskal reconstruction tree
十三、系统优化
leetcode-520. Detect capital letters -js
Inftnews | the wide application of NFT technology and its existing problems
Solution: prompt "unsupported video format" when inserting avi format video into the message
FPGA基础篇目录
Vs extension tool notes
1. Sum of two numbers
Network security - information query of operating system
Inftnews | web5 vs Web3: the future is a process, not a destination
Grid
MATLAB signal processing [Q & A essays · 2]
Count the top 10 films at the box office and save them in another file
在软件工程领域,搞科研的这十年!
USB(十六)2022-04-28
2021ICPC上海 H.Life is a Game Kruskal重构树
Ros2 topic (03): the difference between ros1 and ros2 [02]