当前位置:网站首页>【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
【MnasNet】《MnasNet:Platform-Aware Neural Architecture Search for Mobile》
2022-07-02 07:48:00 【bryant_ meng】


CVPR-2019
List of articles
1 Background and Motivation
The author aims to design a new resource-constrained mobile model Let it be in resource-constrained platforms Run faster
2 Related Work
Compress the existing network : quantitative ,pruning ,NetAdapt etc. ,do not focus on learning novel compositions of CNN operations
hand-crafted Design ,usually take significant human efforts
NAS, Based on a variety of learning algorithms, for example reinforcement learning / evolutionary search / differentiable search
3 Advantages / Contributions
NAS Out MnasNet, Two main innovations
incorporate model latency into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency( Not just ACC)
a novel factorized hierarchical search space that encourages layer diversity throughout the network.( Unlike NasNet That is cell Grade , It is block Grade )
achieve new state-of-the-art results on both ImageNet classification and COCO object detection under typical mobile inference latency constraints
4 Method
4.1 Problem Formulation
Previous methods objective function
m m m yes model, A C C ACC ACC yes accuracy, L A T LAT LAT yes inference latency, T T T yes target latency
above objective Only accuracy is considered , Speed is not considered
author more interested in finding multiple Pareto-optimal solutions in a single architecture search( Speed and accuracy trade-off)
Designed the following objective function

according to α \alpha α and β \beta β Different values , There are the following soft and hard edition
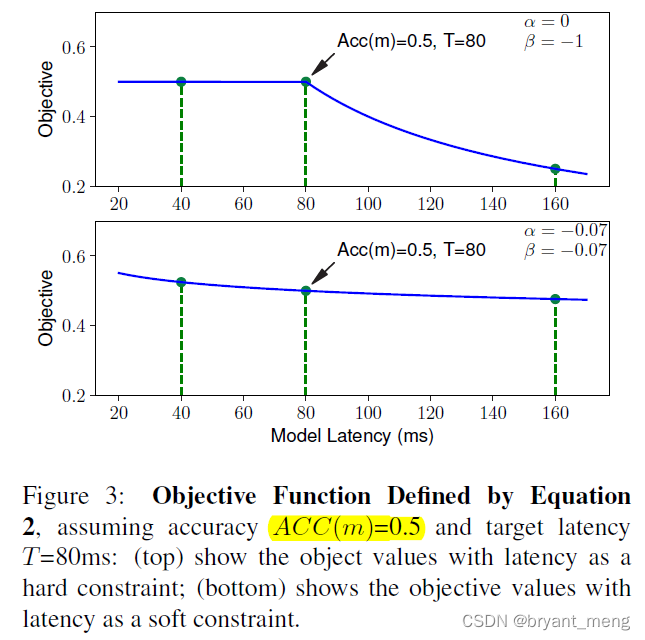
Abscissa is latency, Ordinate for objective
soft edition − 0.07 -0.07 −0.07 Its origin is as follows :
we empirically observed doubling the latency usually brings about 5% relative accuracy gain
R e w a r d ( M 2 ) = a ⋅ ( 1 + % 5 ) ⋅ ( 2 l / T ) β ≈ R e w a r d ( M 1 ) = a ⋅ ( l / T ) β Reward(M2) = a \cdot (1 + %5 ) \cdot (2l/T )^{\beta}\approx Reward(M1) = a \cdot (l/T )^{\beta} Reward(M2)=a⋅(1+%5)⋅(2l/T)β≈Reward(M1)=a⋅(l/T)β
Calculate according to the above formula β ≈ − 0.07 \beta \approx -0.07 β≈−0.07
4.2 Factorized Hierarchical Search Space
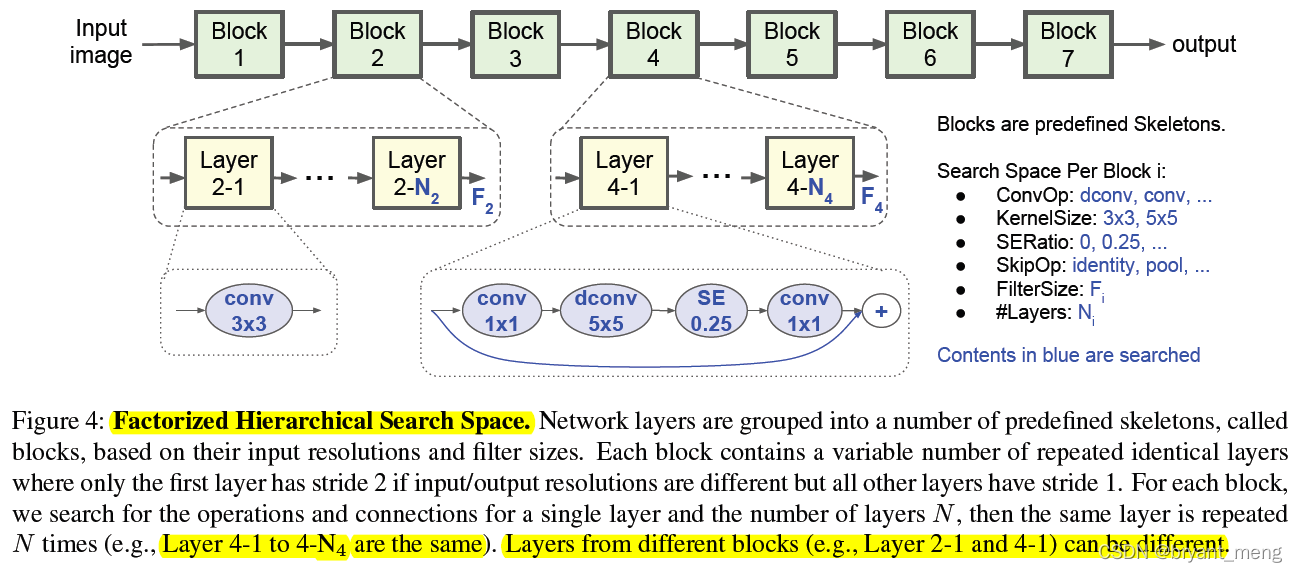
allowing different layer architectures in different blocks
The same block Medium N individual layer It's the same ,layer The operation inside is as follows

When searching using MobileNetV2 as a reference
Every layers Number {0, +1, -1} based on MobileNetV2
filter size per layer {0.75, 1.0, 1.25} to MobileNetV2
One of the finished structures


The size of the search space is as follows :
hypothesis B B B blocks,and each block has a sub search space of size S S S with average N N N layers per block
The search space is S B S^B SB
Every layer If it's all different , Then for S B ∗ N S^{B*N} SB∗N
4.3 Search Algorithm

sample-eval-update loop,maximize the expected reward: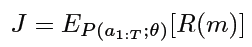
reward value R(m) It's using objective function
5 Experiments
5.1 Datasets
directly perform our architecture search on the ImageNet training set but with fewer training steps (5 epochs)
The difference in NasNet Of Cifar10
5.2 Results
1)ImageNet Classification Performance
T = 75 ms, One search , Multiple model A1 / A2 / A3
comparison mobileNet v2, Introduced SE modular , Discuss SE The impact of modules 
2)Model Scaling Performance
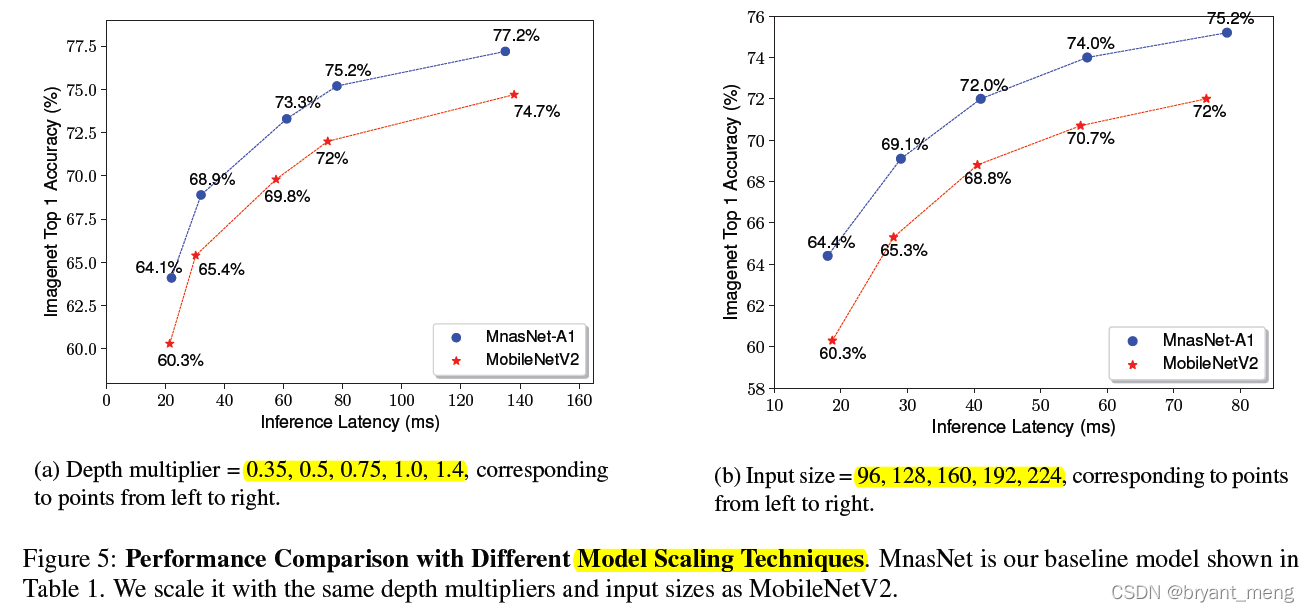
there depth multiplier refer to channels, It can be seen that it is leading in all directions mobilenet v2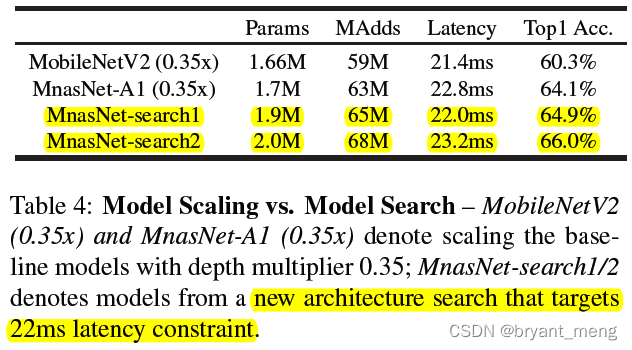
The author can also flexibly change NAS when T To control the size of the model , As can be seen from the table above , It is more powerful than cutting the number of channels on a large model
3)COCO Object Detection Performance
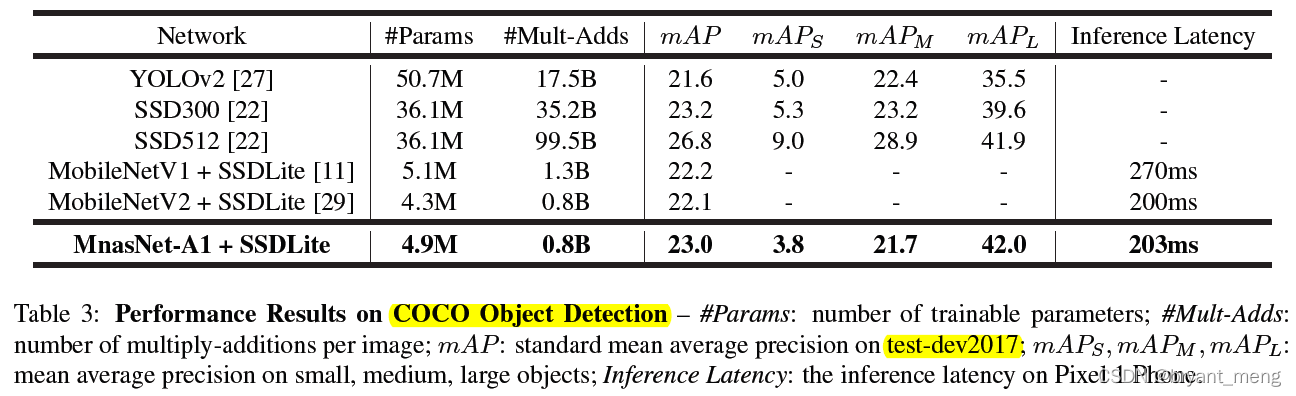
There is nothing to comment on , All vegetables and chickens peck each other , ha-ha , Just kidding , There is a certain improvement
5.3 Ablation Study and Discussion
1)Soft vs. Hard Latency Constraint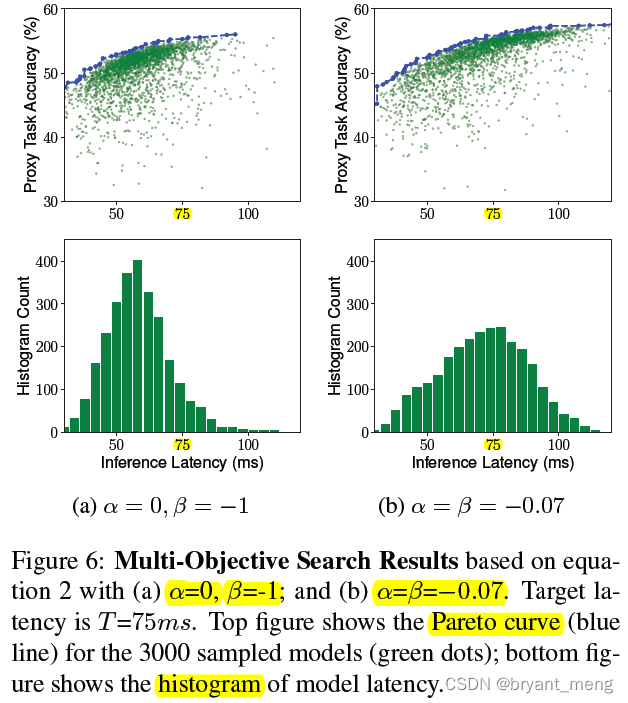
hard edition focus more on faster models to avoid the latency penalty(objective function It can also be seen that )
soft edition tries to search for models across a wider latency range
2)Disentangling Search Space and Reward

Decoupling discusses the role of the next two innovations
3)Layer Diversity

6 Conclusion(own)
stay mobilenet v2 Search based on
Pareto-optimal, Pareto is the best ( From Baidu Encyclopedia )
Pareto is the best (Pareto Optimality), Also known as Pareto efficiency (Pareto efficiency), It refers to an ideal state of resource allocation , Suppose there is an inherent group of people and distributable resources , The change from one allocation state to another , Without making anyone worse , Make at least one person better , This is Pareto improvement or Pareto optimization .
Pareto optimal state It is impossible to have more room for Pareto improvement ; let me put it another way , Pareto improvement is the path and method to achieve Pareto optimality . Pareto optimality is fair and efficient “ Ideal kingdom ”. It was proposed by Pareto .
边栏推荐
- Drawing mechanism of view (II)
- 【DIoU】《Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression》
- 论文写作tip2
- Faster-ILOD、maskrcnn_benchmark安装过程及遇到问题
- 半监督之mixmatch
- 《Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer》论文翻译
- Determine whether the version number is continuous in PHP
- [in depth learning series (8)]: principles of transform and actual combat
- 【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
- 【Hide-and-Seek】《Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization xxx》
猜你喜欢
程序的内存模型

Open3D学习笔记一【初窥门径,文件读取】

生成模型与判别模型的区别与理解

Drawing mechanism of view (I)

Regular expressions in MySQL

Mmdetection trains its own data set -- export coco format of cvat annotation file and related operations

【Paper Reading】
mmdetection训练自己的数据集--CVAT标注文件导出coco格式及相关操作

【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
论文写作tip2
随机推荐
Using compose to realize visible scrollbar
Latex formula normal and italic
程序的内存模型
MMDetection安装问题
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
Yolov3 trains its own data set (mmdetection)
What if a new window always pops up when opening a folder on a laptop
【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
【Paper Reading】
jetson nano安装tensorflow踩坑记录(scipy1.4.1)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
(15) Flick custom source
Sorting out dialectics of nature
[multimodal] clip model
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Use matlab to realize: chord cut method, dichotomy, CG method, find zero point and solve equation
ABM thesis translation
open3d环境错误汇总
【MagNet】《Progressive Semantic Segmentation》
Conversion of numerical amount into capital figures in PHP