当前位置:网站首页>【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
【Sparse-to-Dense】《Sparse-to-Dense:Depth Prediction from Sparse Depth Samples and a Single Image》
2022-07-02 07:44:00 【bryant_ meng】

ICRA-2018
List of articles
1 Background and Motivation
Depth perception and depth estimation in robotics, autonomous driving, augmented reality (AR) and 3D mapping And other engineering applications !
However, the existing depth estimation methods have more or less its limitations when landing :
1)3D LiDARs are cost-prohibitive
2)Structured-light-based depth sensors (e.g. Kinect) are sunlight-sensitive and power-consuming
3)stereo cameras require a large baseline and careful calibration for accurate triangulation, and usually fails at featureless regions
Monocular camera due to its small size , The cost is low , Energy saving , It is ubiquitous in consumer electronic products , Monocular depth estimation method has also become a point of interest for people to explore !
However ,the accuracy and reliability of such methods is still far from being practical( Although there has been a significant improvement over the years )
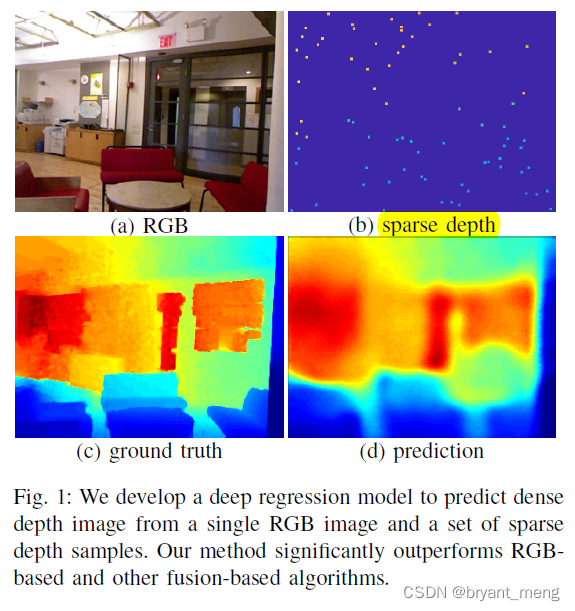
The author in rgb Based on the image , coordination sparse depth measurements, To estimate the depth ,a few sparse depth samples drastically improves depth reconstruction performance
2 Related Work
- RGB-based depth prediction
- hand-crafted features
- probabilistic graphical models
- Non-parametric approaches
- Semi-supervised learning
- unsupervised learning
- Depth reconstruction from sparse samples
- Sensor fusion
3 Advantages / Contributions
rgb + sparse depth Perform monocular depth prediction
ps: There is no innovation in the network structure ,sparse depth This kind of multimodality also draws lessons from others' ideas ( Of course , Sampling methods are different )
4 Method
The overall structure
It's using encoder and decoder In the form of 
UpProj In the form of :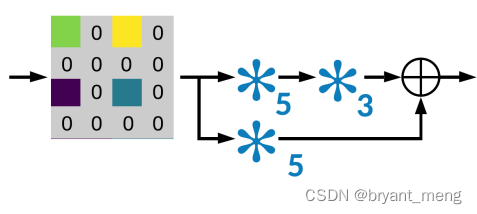
2)Depth Sampling
according to Bernoulli probability sampling (eg: Flip a coin , Each result is irrelevant ), p = m n p = \frac{m}{n} p=nm
Bernoulli's test (Bernoulli experiment) Is repeated under the same conditions 、 A randomized trial conducted independently of each other , It is characterized by the fact that there are only two possible results of the randomized trial : Happen or not . We assumed that the experiment was repeated independently n Time , So we call this series of repeated independent randomized trials n The heavy Bernoulli experiment , Or Bernoulli type .

D ∗ D* D∗ Complete depth map ,dense depth map
D D D sparse depth map
3)Data Augmentation
Scale / Rotation / Color Jitter / Color Normalization / Flips
scale and rotation When it comes to Nearest neighbor interpolation To avoid creating spurious sparse depth points
4)loss function
- l1
- l2:sensitive to outliers,over-smooth boundaries instead of sharp transitions
- berHu
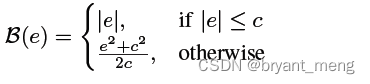
berHu A combination of l1 and l2
author ” Facts speak ” It's using l1
5 Experiments
5.1 Datasets
NYU-Depth-v2
464 different indoor scenes,249 Train + 215 test
the small labeled test dataset with 654 images is used for evaluating the final performance
KITTI Odometry Dataset
The KITTI dataset is more challenging for depth prediction, since the maximum distance is 100 meters as opposed to only 10 meters in the NYU-Depth-v2 dataset.
The evaluation index
RMSE: root mean squared error

REL: mean absolute relative error

δ i \delta_i δi:
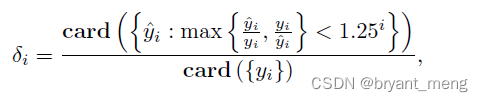
among
- card:is the cardinality of a set( It can be simply understood as counting the number of elements )
- y ^ \hat{y} y^:prediction
- y y y:GT
More relevant evaluation index references Monocular depth estimation index :SILog, SqRel, AbsRel, RMSE, RMSE(log)
5.2 RESULTS
1)Architecture Evaluation
DeConv3 Than DeConv2 good ,
UpProj Than DeConv3 good (even larger receptive field of 4x4, the UpProj module outperforms the others)
2)Comparison with the State-of-the-Art
NYU-Depth-v2 Dataset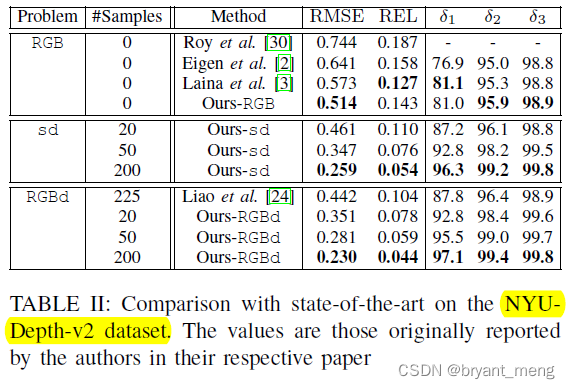
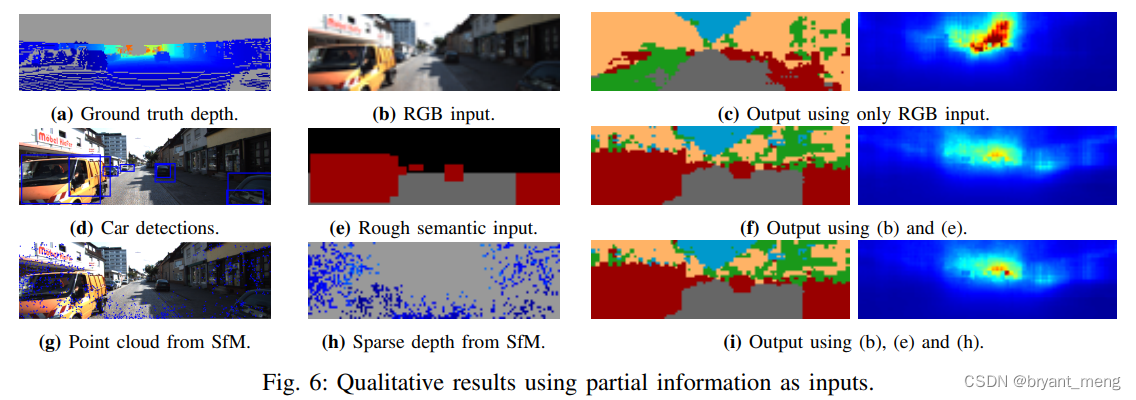
sd yes sparse-depth Abbreviation , That is, enter no rgb
See the visual effect 
KITTI Dataset
3)On Number of Depth Samples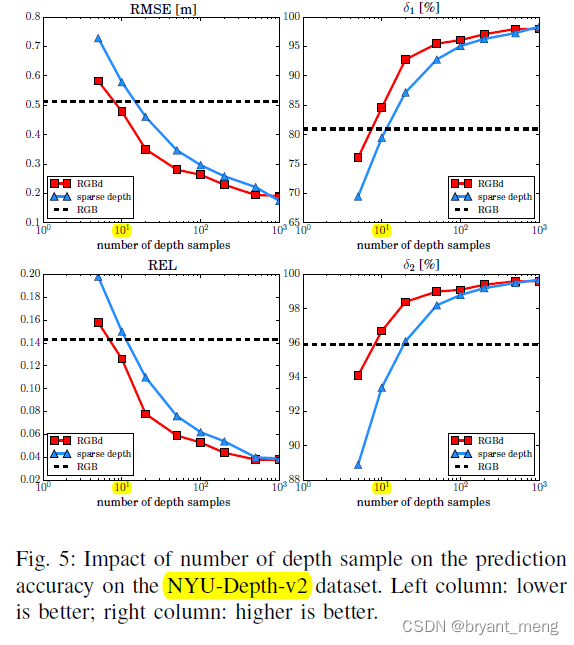
sparse 1 0 1 10^1 101 This order of magnitude can be compared with rgb comparable , 1 0 2 10^2 102 leap ,
The more samples , and rgb It doesn't matter much (performance gap between RGBd and sd shrinks as the sample size increases), Ha ha ha
This observation indicates that the information extracted from the sparse sample set dominates the prediction when the sample size is sufficiently large, and in this case the color cue becomes almost irrelevant. ( Full sampling , I will output it to you as I input it , Don't talk about it rgb Not much to do with , It has little to do with Neural Networks , Ha ha ha )
I want to see others KITTI The impact on 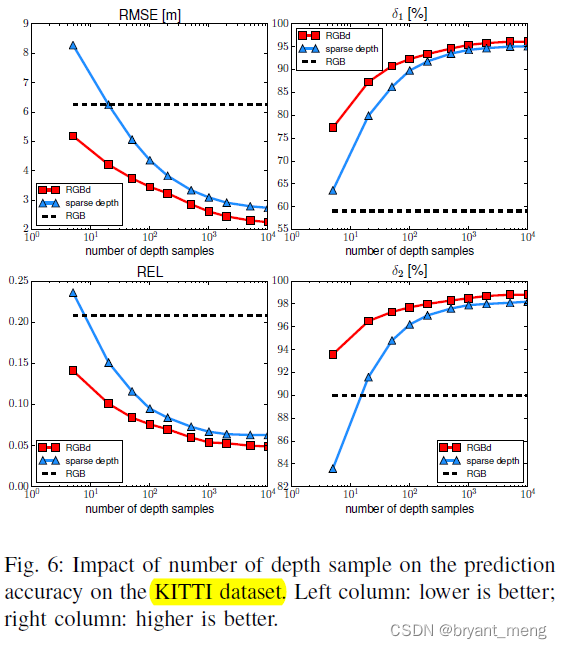
Be the same in essentials while differing in minor points
4)Application: Dense Map from Visual Odometry Features

5)Application: LiDAR Super-Resolution
6 Conclusion(own) / Future work
presentation
https://www.bilibili.com/video/av66343637/
Let's take a look at some other multimodal monocular depth prediction methods
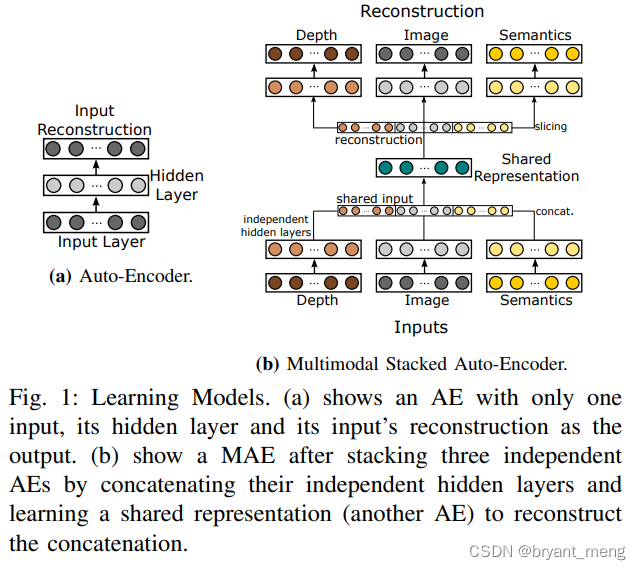
《Multi-modal Auto-Encoders as Joint Estimators for Robotics Scene Understanding》
Robotics: Science and Systems-2016
《Parse Geometry from a Line: Monocular Depth Estimation with Partial Laser Observation》
ICRA-2017

I feel that the landing cost is smaller than that of the author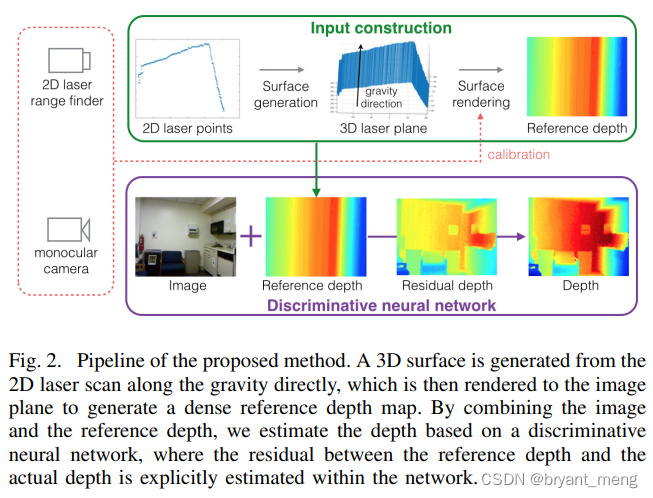

边栏推荐
- 【Cutout】《Improved Regularization of Convolutional Neural Networks with Cutout》
- ModuleNotFoundError: No module named ‘pytest‘
- SSM personnel management system
- 基于onnxruntime的YOLOv5单张图片检测实现
- Translation of the paper "written mathematical expression recognition with bidirectionally trained transformer"
- Alpha Beta Pruning in Adversarial Search
- [Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
- 【AutoAugment】《AutoAugment:Learning Augmentation Policies from Data》
- Ding Dong, here comes the redis om object mapping framework
- MMDetection安装问题
猜你喜欢

【Paper Reading】
![[multimodal] clip model](/img/45/8501269190d922056ea0aad2e69fb7.png)
[multimodal] clip model
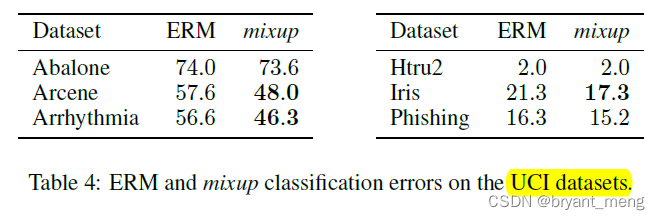
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
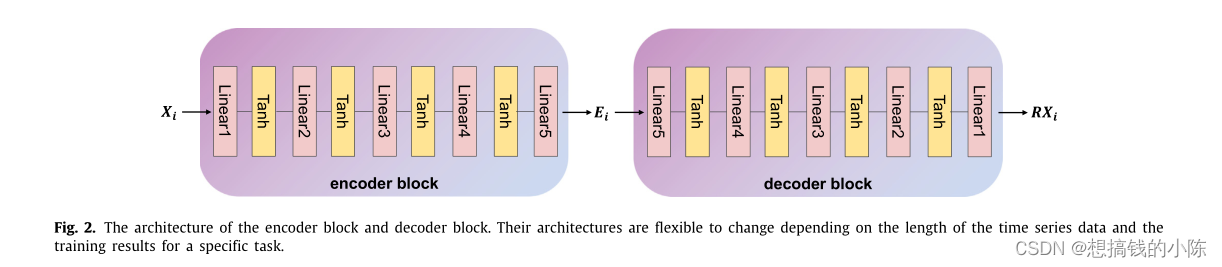
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
Pointnet understanding (step 4 of pointnet Implementation)
Point cloud data understanding (step 3 of pointnet Implementation)
Spark SQL task performance optimization (basic)

SSM supermarket order management system
![[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video](/img/bc/c54f1f12867dc22592cadd5a43df60.png)
[CVPR‘22 Oral2] TAN: Temporal Alignment Networks for Long-term Video
TimeCLR: A self-supervised contrastive learning framework for univariate time series representation
随机推荐
PHP returns the corresponding key value according to the value in the two-dimensional array
一份Slide两张表格带你快速了解目标检测
CONDA creates, replicates, and shares virtual environments
A slide with two tables will help you quickly understand the target detection
iOD及Detectron2搭建过程问题记录
[Bert, gpt+kg research] collection of papers on the integration of Pretrain model with knowledge
Sorting out dialectics of nature
latex公式正体和斜体
parser. parse_ Args boolean type resolves false to true
【Wing Loss】《Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks》
PPT的技巧
Calculate the total in the tree structure data in PHP
[introduction to information retrieval] Chapter 6 term weight and vector space model
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
[torch] the most concise logging User Guide
SSM student achievement information management system
深度学习分类优化实战
Faster-ILOD、maskrcnn_ Benchmark trains its own VOC data set and problem summary
【Random Erasing】《Random Erasing Data Augmentation》
Execution of procedures