当前位置:网站首页>【Mixup】《Mixup:Beyond Empirical Risk Minimization》
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
2022-07-02 07:39:00 【bryant_ meng】

ICLR-2018
List of articles
1 Background and Motivation
Now the model is getting stronger , but memorization( Rote training set , Insufficient generalization ability ) and sensitivity to adversarial examples( Insufficient generalization ability )
The author from Vicinal Risk Minimization (VRM) principle set out , Put forward mixup Data enhancement method (convex combinations of pairs of examples and their labels) To improve existing SOTA The generalization ability of the model
Q:VRM What is it ? First from Empirical Risk Minimization (ERM) principle Start talking about
Simply speaking , When doing machine learning tasks , We cannot know the true distribution of the data (eg Cat and dog classification , Thousands of cat and dog data in the world are inexhaustible ), So we cannot minimize the real risk , Only part of the data can be minimized ( Samples from the real world ) The risk of (minimize their average error over the training data), That is to minimize experience risk
【 Math knowledge 】 Empirical risk minimization and structural risk minimization

the convergence of ERM is guaranteed as long as the size of the learning machine does not increase with the number of training data.
When the data must , The model gets bigger and bigger , be based on ERM The model trained by the principle will have the following problems :
- memorize (instead of generalize from) the training data( Start memorizing , Over fitting )
- trained with ERM change their predictions drastically when evaluated on examples just outside the training distribution,also known as adversarial examples( Sensitive , Generalization performance is not enough )
The model is big , Does not match the amount of data , It is often necessary to sample more data from the real distribution , That is, we have faced the data augmentation method often used in fitting ,formalized by the Vicinal Risk Minimization (VRM) principle
Concrete ,
The author puts forward a new way of data expansion ,mixup
2 Related Work
A little
3 Advantages / Contributions
Put forward mixup Data enhancement method ( The introduction of the story is good ),improves the generalization of state-of-the-art neural network architectures
- reduces the memorization of corrupt labels
- increases the robustness to adversarial examples
- stabilizes the training of generative adversarial networks(GAN)
- improves generalization on speech and tabular data( I haven't learned about this )
4 Method
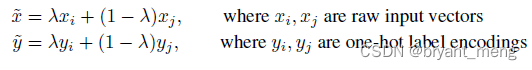
among λ ∼ B e t a ( α , α ) \lambda \sim Beta(\alpha, \alpha) λ∼Beta(α,α)
code
B e t a ( α , β ) Beta(\alpha, \beta) Beta(α,β) The probability density function of the distribution is as follows
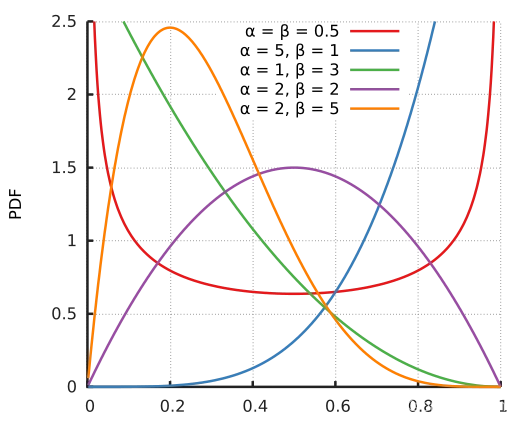
this paper α = β \alpha = \beta α=β
Here are some of the α \alpha α Images
Part of the code
from scipy.stats import beta
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1, 100)
y = beta.pdf(x, 0.1, 0.1)
plt.plot(x, y, label="0.1")
plt.legend()
plt.show()

You can see , The probability density function is symmetric , α = 1 \alpha=1 α=1 when , B e t a ( α , α ) Beta(\alpha, \alpha) Beta(α,α) Become evenly distributed
When α → 0 \alpha \rightarrow 0 α→0,Beta The probability density function of tends to 0, When sampling λ → 0 \lambda \rightarrow 0 λ→0,mixup Integration is gone ,VRM Fallback into ERM
When α → ∞ \alpha \rightarrow \infty α→∞,Beta The probability density function of tends to ∞ \infty ∞
The author found
- mixup More than 2 The effect has not been further improved , But the computational cost increases
- mixup The two pictures of are from the same mini-batch, Economize I/O
- mixup only It works on equal label The effect has not been significantly improved ( Single class mixup The effect is not obvious ?)
What is mixup doing?
encourages the model f f f to behave linearly in-between training examples, Especially different classes , The previous data expansion is basically based on the same kind ,mixup A priori of the relationship between different categories is introduced , Although it is only the simplest linear relationship .
mixup leads to decision boundaries that transition linearly from class to class,providing a smoother estimate of uncertainty

5 Experiments
5.1 Datasets and Metrics
Data sets
- CIFAR-10 / CIFAR-100
- ImageNet
- UCI
- the Google commands dataset
The evaluation index
- top1-error
- top5-error
5.2 Experiments
1)ImageNet Classification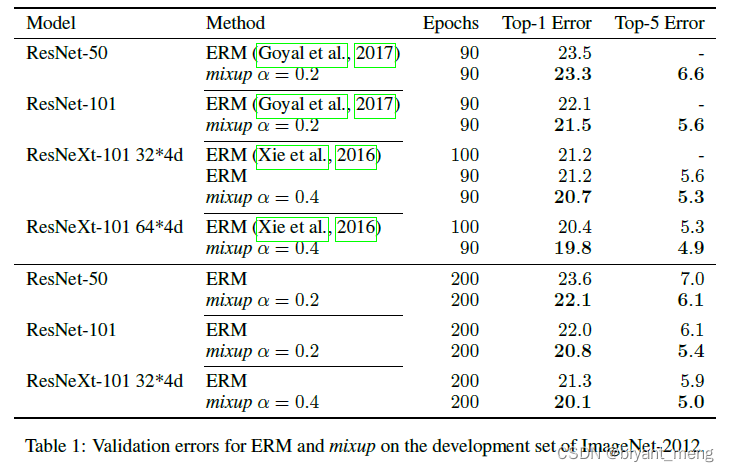
α ∈ \alpha \in α∈[0.1, 0.4] When ,mixup Than ERM good , for large α \alpha α, mixup leads to underfitting( α \alpha α The bigger it is λ \lambda λ The more tend to take 0.5, The two pictures overlap more deeply , The more deviated from the original data , The difficulty of fitting increases )
The bigger the model , Longer training time ,mixup It plays a more obvious role
2)CIFAR-10 and CIFAR-100
α \alpha α Set to 1,beta Distribution is now equal to uniform distribution , That is to say λ \lambda λ Fetch 0~1 The probability of any value of is the same 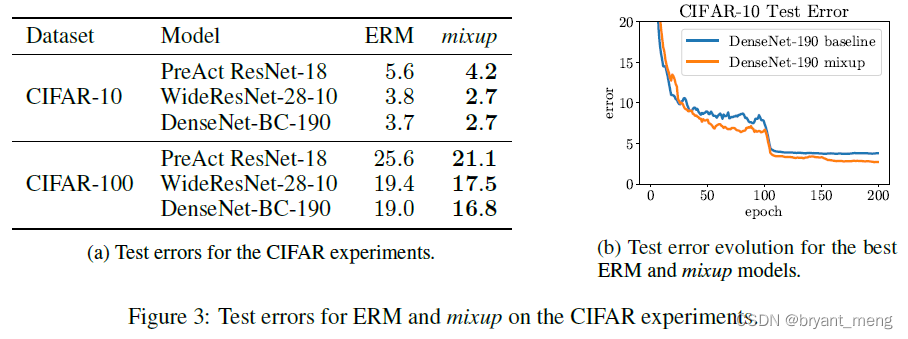
3)Speech data

LeNet Not on ERM good ,VGG Upper ratio ERM good
4)Memorization of corrupted labels
CIFAR-10 Data sets 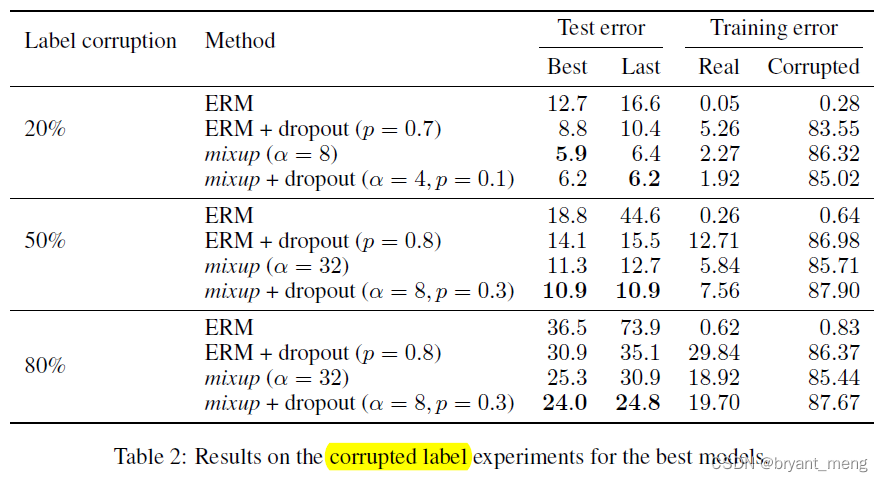
α \alpha α The bigger it is ,mixup The deeper the integration ,making memorization more difficult to achieve
obvious , No, mixup, Over fitting is serious , Learn all the wrong information ( Corrupt data set training error Very low )
How to evaluate mixup: BEYOND EMPIRICAL RISK MINIMIZATION? - Zhang Hongyi's answer
mixup and dropout It can also promote each other
5)Robustness to adversarival examples
ImageNet
penalizing the norm of the gradient of the loss( Reduce bad oscillations in the data set )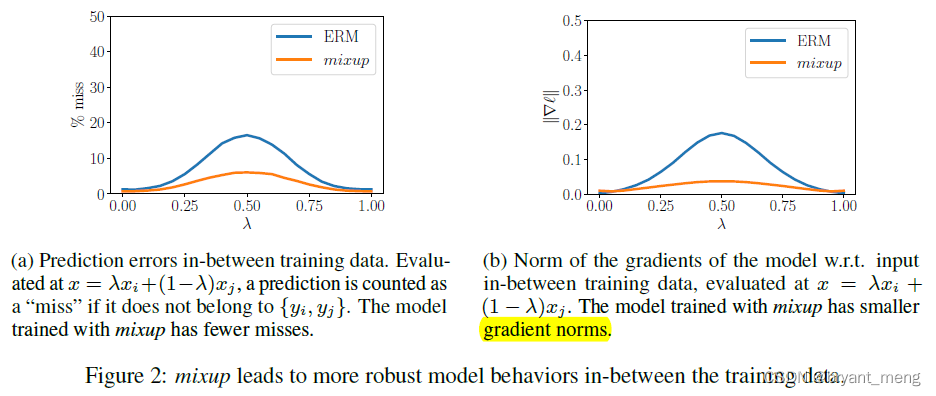
You can see mixup The gradient norm of is smaller
Let's see the effect of facing the confrontation sample 
obvious mixup Much more robust
White box attack (white box) With black box attack (black box):
- White box attack : The model parameters of the attacked model can be obtained ;
- Black box attack : The model parameters of the attacked model cannot be obtained .
fast gradient sign method(FGSM)
Here's about FGSM The introduction and code of comes from : Against the sample FGSM actual combat

# FGSM attack code
def fgsm_attack(image, epsilon, data_grad):
# Use sign( Symbol ) function , Will be right x The gradient of partial derivative is found and symbolized
sign_data_grad = data_grad.sign()
# adopt epsilon Generate countermeasure samples
perturbed_image = image + epsilon*sign_data_grad
# Do a cutting job , take torch.clamp Internal greater than 1 The value of is changed to 1, Less than 0 The value of is equal to 0, prevent image Transboundary
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# Return the confrontation sample
return perturbed_image
def test( model, device, test_loader, epsilon ):
# Accuracy counter
correct = 0
# Counter samples
adv_examples = []
# Cycle through all test sets
for data, target in test_loader:
# Send the data and label to the device
data, target = data.to(device), target.to(device)
# Set requires_grad attribute of tensor. Important for Attack
data.requires_grad = True
# Forward pass the data through the model
output = model(data)
init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
# If the initial prediction is wrong, dont bother attacking, just move on
if init_pred.item() != target.item():
continue
# Calculate the loss
loss = F.nll_loss(output, target)
# Zero all existing gradients
model.zero_grad()
# Calculate gradients of model in backward pass
loss.backward()
# Collect datagrad
data_grad = data.grad.data
# Call FGSM Attack
perturbed_data = fgsm_attack(data, epsilon, data_grad)
# Re-classify the perturbed image
output = model(perturbed_data)
...
6)Tabular data
It's using UCI Machine learning data sets , Form 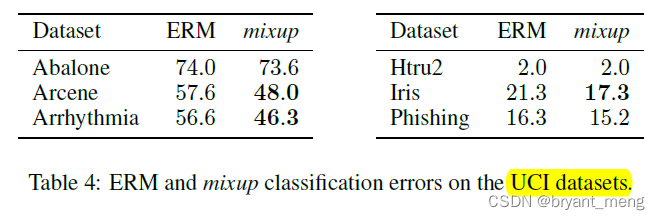
7)Stabilization of GAN
GAN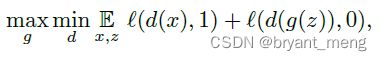
GAN + mixup

the stabilizing effect of mixup the training of GAN (orange samples) when modeling two toy datasets (blue samples).—— Yellow fits blue
You can find mixup + GAN A more stable
8)Ablation studies
Explore mixup Different forms of 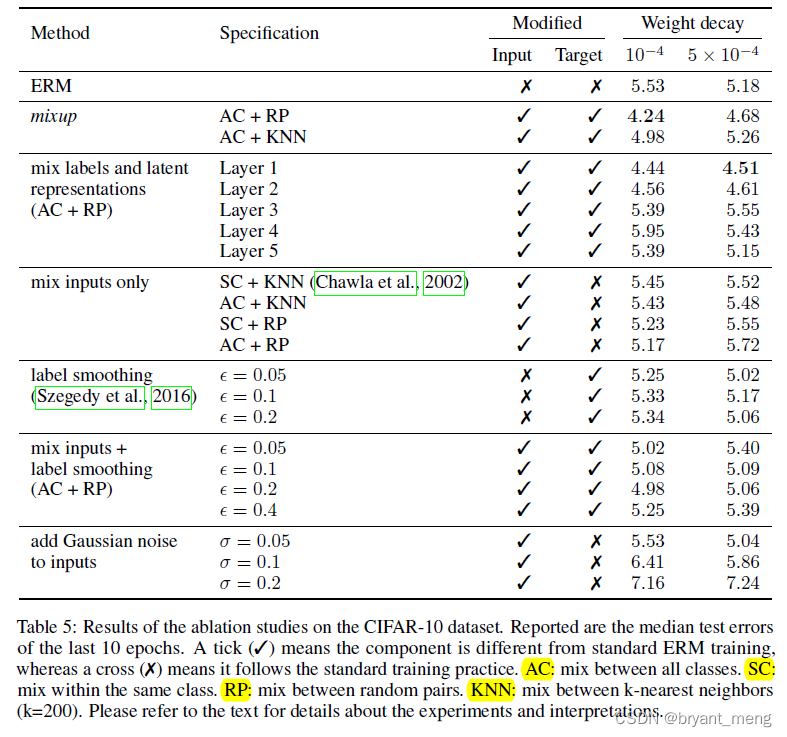
ERM a large weight decay works better, whereas for mixup a small weight decay is preferred
9)Discussion
increasingly large α \alpha α the training error on real data increases, while the generalization gap decreases.
increasing the model capacity would make training error less sensitive to large α \alpha α
6 Conclusion(own) / Future work
1) The future work :
- Use in regression and structure learning On (eg Division )
- Used in semi supervision 、 Unsupervised 、 Deep reinforcement learning
2) Source code
https://github.com/facebookresearch/mixup-cifar10/blob/main/train.py
def mixup_data(x, y, alpha=1.0, use_cuda=True):
'''Returns mixed inputs, pairs of targets, and lambda'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
if use_cuda:
index = torch.randperm(batch_size).cuda()
else:
index = torch.randperm(batch_size)
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
for batch_idx, (inputs, targets) in enumerate(trainloader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets_a, targets_b, lam = mixup_data(inputs, targets,
args.alpha, use_cuda)
inputs, targets_a, targets_b = map(Variable, (inputs,
targets_a, targets_b))
outputs = net(inputs)
loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam)
3) The most complete network : Inventory those image data expansion methods Mosiac,MixUp,CutMix etc. .

So when you have more categories of data sets , In this way, it may be effective to distinguish some difficult cases , But not all cases work MixUp, At least if there is only one category , I don't think the effect will be very effective .
4) What is the essence of the integral result in Mathematics ?
5) How to understand beta Distribution ? - Ma's answer - You know

Beta The distribution has the property of conjugate a priori , That is to say 
And 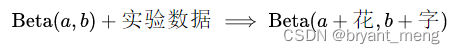

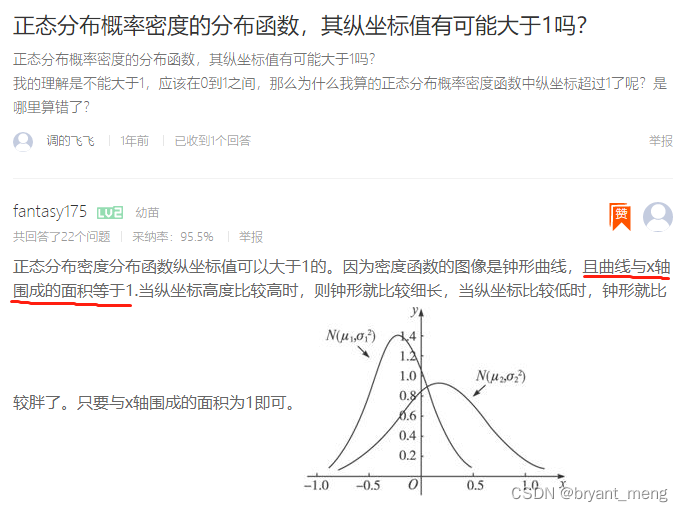
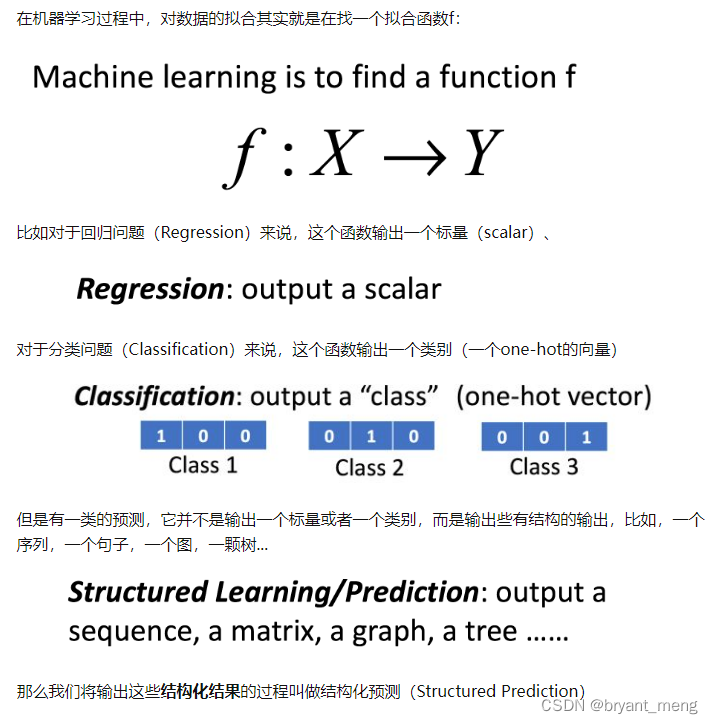
8) How to evaluate mixup: BEYOND EMPIRICAL RISK MINIMIZATION? - Zhang Hongyi's answer
These synthetic training data The role of , The popular explanation is “ Enhance the model's response to certain transformations invariance”. The reverse of this sentence , It is often mentioned in machine learning “ Reduce the estimated variance”, That is to control the complexity of the model .


9) How to evaluate mixup: BEYOND EMPIRICAL RISK MINIMIZATION? - Zhanxing Zhu Answer 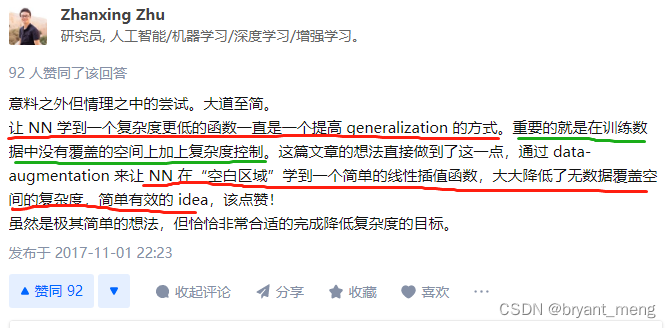
10)label smooth、mixup understand 
11) Why? mixup To use beta Distribution ?
Point of view : Why? mixup To use beta Distribution ? - Sincere Answer
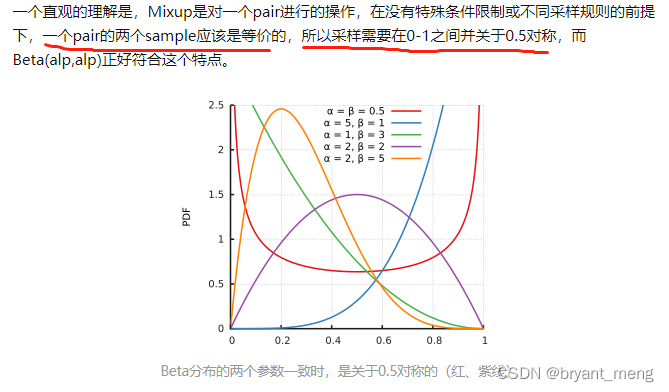
Viewpoint two : Why? mixup To use beta Distribution ? - Zou Yuliang's answer

This answer is refreshing !!!
12)Beta Confusion of distribution sampling
How to evaluate mixup: BEYOND EMPIRICAL RISK MINIMIZATION? - Zhang Hongyi's answer 
13)《Manifold mixup: Better representations by interpolating hidden states》(ICML-2019)

边栏推荐
- Using MATLAB to realize: Jacobi, Gauss Seidel iteration
- [model distillation] tinybert: distilling Bert for natural language understanding
- Implementation of yolov5 single image detection based on pytorch
- [torch] the most concise logging User Guide
- 【Ranking】Pre-trained Language Model based Ranking in Baidu Search
- SSM second hand trading website
- 【Torch】最简洁logging使用指南
- 基于pytorch的YOLOv5单张图片检测实现
- How to efficiently develop a wechat applet
- SSM laboratory equipment management
猜你喜欢

基于pytorch的YOLOv5单张图片检测实现
【Ranking】Pre-trained Language Model based Ranking in Baidu Search
![[model distillation] tinybert: distilling Bert for natural language understanding](/img/c1/e1c1a3cf039c4df1b59ef4b4afbcb2.png)
[model distillation] tinybert: distilling Bert for natural language understanding

How do vision transformer work?【论文解读】
Using MATLAB to realize: Jacobi, Gauss Seidel iteration

iOD及Detectron2搭建过程问题记录

Interpretation of ernie1.0 and ernie2.0 papers
![[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table](/img/3f/09f040baf11ccab82f0fc7cf1e1d20.png)
[introduction to information retrieval] Chapter II vocabulary dictionary and inverted record table
常见CNN网络创新点
Win10+vs2017+denseflow compilation
随机推荐
【Mixup】《Mixup:Beyond Empirical Risk Minimization》
Using MATLAB to realize: Jacobi, Gauss Seidel iteration
Classloader and parental delegation mechanism
ModuleNotFoundError: No module named ‘pytest‘
離線數倉和bi開發的實踐和思考
MoCO ——Momentum Contrast for Unsupervised Visual Representation Learning
Find in laravel8_ in_ Usage of set and upsert
Huawei machine test questions-20190417
PHP uses the method of collecting to insert a value into the specified position in the array
生成模型与判别模型的区别与理解
A summary of a middle-aged programmer's study of modern Chinese history
Win10+vs2017+denseflow compilation
论文tips
yolov3训练自己的数据集(MMDetection)
实现接口 Interface Iterable<T>
Agile development of software development pattern (scrum)
Two table Association of pyspark in idea2020 (field names are the same)
Calculate the total in the tree structure data in PHP
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
ABM论文翻译