The tutorial is in notebook Running on , Not scripts , download notebook file .
PyTorch Provides modules and classes with elegant design :torch.nn, torch.optim, Dataset, DataLoader, To create and train nerves . In order to make full use of its function , And customize it according to the problem , We need to fully understand what they do . In order to improve cognition , We started with MNIST Train a basic neural network , Without using any of the features of these modules ; Use only the most basic PyTorch tensor Function initialization . then , Add one at a time from torch.nn, torch.optim, Dataset, DataLoader Characteristics of , Accurately show the function of each part , And how to make the code simpler and more flexible .
This tutorial assumes that you have installed PyTorch, And right tensor Familiar with the basic knowledge of operation .
MNIST Data settings
We're going to use the classic MNIST Data sets , It is composed of handwritten digits (0-9) Black and white pictures of .
We will use pathlib(Python3 Part of the standard library ) Solve the problem of path , And use requests. We only import when we use them , In this way, you can accurately see what is used in each part .
from pathlib import Path
import requests
DATA_PATH = Path('data')
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "https://github.com/pytorch/tutorials/raw/master/_static/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exits():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open('wb').write(content)
The dataset is Numpy The array format , Use pickle(python The specific format used to serialize data in ) preservation .
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), 'rb') as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding='latin-1')
The size of each picture is 28*28, Saved as flattened rows , The length is 784. Check out one of them , First of all, it needs to be reshape To 2D .
from matplotlib import pyplot
import numpy as np
pyplot.imshow(x_train[0].reshape((28, 28)), cmap = 'gray')
print(x_train.shape)
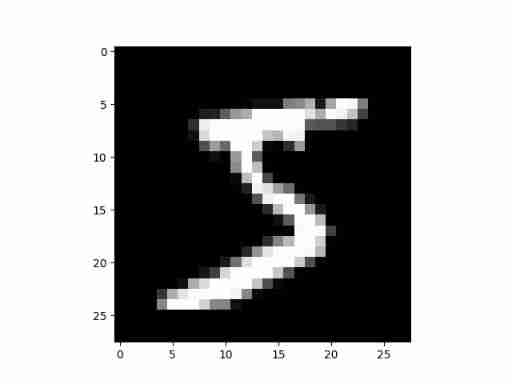
Output :
(50000, 784)
PyTorch Use torch.tensor, instead of numpy Array , So we do data conversion .
import torch
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
Output :
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]) tensor([5, 0, 4, ..., 8, 4, 8])
torch.Size([50000, 784])
tensor(0) tensor(9)
Neural networks from scratch ( Don't use torch.nn)
First use only PyTorch tensor Operation create model . Suppose you are familiar with the basic knowledge of neural network .
PyTorch Provides the ability to create random values or 0 value tensors Methods , It can be used to build weights and offsets for simple linear models . These are just routine tensors, There is also a very special addition : tell PyTorch They need gradients . bring PyTorch The record occurred in tensor All operations on , Thus, the gradient can be calculated in automatic back propagation .
For weights , We set after initialization requires_grad, Because we don't want this step to be included in the gradient update .( Be careful ,PyTorch in , suffix _ representative in-place operation ).
Be careful : This article USES the Xavier initialisation( multiply 1/sqrt(n) ) Initialization weight .
import math
weights = torch.randn(784, 10) / math.sqrt(784)
weights.requires_grad_()
bias = torch.zeros(10, requires_grad=True)
Thanks to the PyTorch The ability to automatically calculate gradients , We can use any standard Python function ( Or call the object ) Build the model . So here is a simple linear model created by pure matrix multiplication and broadcast addition . You also need an activation function , So we will write and use log_softmax. remember : Even though PyTorch Provides a large number of written loss functions , Activation functions, etc , You still use pure python Write them .PyTorch It will even automatically create a quick for your function GPU Or vectorization CPU Code .
def log_softmax(X):
return x - x.enp().sum(-1).log.unsqueeze(-1)
def model(xb):
return log_softmax(xb @ weights + bias)
among ,@ For matrix multiplication . Every batch( This case 64 A picture ) Will call our function . This is a forward pass . Be careful , At this stage, our prediction will not be better than random , Because we use random initialization weights .
bs = 64 # batch size
xb = x_train[0:bs] # a mini-batch from x
preds = model(xb) # predictions
print(preds[0], preds.shape)
Output :
tensor([-1.8235, -2.3674, -2.6933, -2.0418, -2.2708, -2.3946, -2.1448, -2.5031,
-2.7917, -2.3786], grad_fn=<SelectBackward0>) torch.Size([64, 10])
As you can see ,predstensor It's not just about tensor The number , There is also a gradient function . Next we will use this for back propagation .
Now let's implement the negative log likelihood function as the loss function ( Once again, , Use standards Python)
def nll(input, target):
return -input[range(target.shape[0]), target].mean()
loss_func = nll
Calculate the loss , In this way, we will see whether there is any improvement after back propagation .
yb = y_train[0:bs]
print(loss_func(preds, yb))
Output :
tensor(2.2979, grad_fn=<NegBackward0>)
Use a function to calculate the accuracy of the model . For each prediction , If the index of the maximum value is consistent with the target value , The prediction is correct .
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
Check the accuracy of the model , So you can see when loss In ascension , Whether the accuracy will be improved
print(accuracy(preds, yb))
Output :
tensor(0.1094)
We can now run a training cycle , For each cycle , Include :
- Select a mini-batch of data (of size
bs) - Use model forecast
- Calculate the loss
loss.backward()Update model gradient , In this case, it'sweightsandbias
Now use gradient update weights and bias. adopt torch.no_grad() Context manager , Because we don't want these behaviors to be recorded in the next gradient calculation . You can here Read more about PyTorch Of Autograd Record operation .
Next, set the gradient 0, Get ready for the next cycle . otherwise , Our gradient will record the operation records of all operations that have occurred ( namely loss.backward() Add gradients to anything stored , Instead of replacing them ).
TIP: You can use the standard python Debugger step-by-step debugging in PyTroch Code , Allows you to check the values of various variables at each step . Cancel the following set_trace() Note try .
from IPython.core.debugger import set_trace
lr = 0.5 # learning rate
epochs = 2 # how many epochs to train for
for epoch in range(epochs):
for i in range((n - 1) // bs + 1)):
# set_trace()
start_i = i * bs
end_i = start_i + bs
xb = x_train[start_i:end_i]
yb = y_train[start_i:end_i]
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
with torch.no_grad():
weights -= weights.grad * lr
bias -= bias.grad * lr
weights.grad.zero_()
bias.grad.zero_()
above , We from 0 A small neural network is constructed and trained ( In this case , One logistic Return to , Because there is no hidden layer ).
Check loss And accuracy compared to before ,loss Reduce , Accuracy increases , This is the fact. .
print(loss_func(model(xb), yb), accuracy(model(xb), yb))
Output :
tensor(0.0803, grad_fn=<NegBackward0>) tensor(1.)
Use torch.nn.functional
We will use PyTorch Of nn Class reconfiguration network , Make it consistent with what you have done before , But more concise and flexible . Every step from here , We may make the code shorter 、 Easy to understand 、 flexible .
The first and simplest step is to make the code shorter , utilize torch.nn.functional( It is usually named F) Instead of handwriting activation and loss functions . This module contains torch.nn All functions of the Library ( Other parts are classes ). In addition to a lot of losses 、 Activate the function , You can also find some functions for creating neural networks here , Such as pooling function .( There are also some convolutions 、 Functions of linear layers, etc , But we will see , It is usually better to use other parts of the library to solve these things )
If you use the negative log likelihood loss function and log softmax Activation function , that Pytorch Provide a single function F.cross_entropy Combine these two . So we can even remove the activation function from our model .
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb @ weights + bias
Be careful , We are no longer model Call in function log_softmax, confirm loss and accuracy Is it the same as before .
print(loss_func(model(xb), yb), accuracy(model(xb), yb))
Output :
tensor(0.0803, grad_fn=<NllLossBackward0>) tensor(1.)
Use nn.Module restructure
next step , For a clearer and simpler training cycle , We will use nn.Module and nn.Parameter. We inherit nn.Module( It is a class in itself and can track state ). In this case , We want to create a class to hold our weights 、 bias , And the method of forward transmission .nn.Module There are a lot of properties and methods ( for example .parameters() and .zero_grad()).
Be careful :nn.Module( Capitalization M) yes PyTorch A specific concept , It is a class that we need to use a lot . Don't put nn.Module And Python Write small and medium m Of module The concept of confusion , The latter can be imported Python file .
from torch import nn
class Mnist_Logistic(nn.Module):
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(784, 10) / math.sqrt(784))
self.bias = nn.Parameter(torch.zerors(10))
def forward(self, xb):
return xb @ self.weights + self.bias
Because we use an object instead of a function , We need to instantiate the model first .
model = Mnist_Logistic()
Now it can be calculated as above loss. Be careful nn.Module Object is used as a function ( That is, they are callable ), But at the bottom ,Pytorch Will automatically call forward Method .
print(loss_func(model(xb), yb))
Output :
tensor(2.2899, grad_fn=<NllLossBackward0>)
For the training cycle , We need to update each parameter value according to the name , And manually set the gradient of each parameter 0:
with torch.no_grad():
weights -= weights.grad * lr
bias -= bias.grad * lr
weights.grad.zero_()
bias.grad.zero_()
Now? , We can use model.parameters() and model.zero_grad()( It's all by Pytorch by nn.Module Defined ) Make these steps easier , And it is not easy to forget some parameters , Especially some complex models with home :
with torch.no_grad():
for p in model.parameters(): p -= p.grad * lr
model.zero_grad()
Surround the training cycle with fit Function , In order to run again later
def fit():
for epoch in range(epochs):
for i in range((n - 1) // bs + 1):
start_i = i * bs
end_i = start_i + bs
xb = x_train[start_i:end_i]
yb = y_train[start_i:end_i]
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
with torch.no_grad():
for p in model.parameters():
p -= p.grad * lr
model.zero_grad()
fit()
go over loss Whether it has dropped :
print(loss_func(model(xb), yb))
Output :
tensor(0.0835, grad_fn=<NllLossBackward0>)
Use nn.Linear restructure
Let's continue refactoring the code . Replace manual definition and initialization self.weights and self.bias, And calculation xb @ self.weights + self.bias, For a linear layer , We will use Pytorch class nn.Linear, It can realize all the above functions .Pytorch By many predefined layers, It can greatly simplify and speed up our code .
class Mnist_Logistic(nn.Module):
def __init__(self):
super().__init__()
self.lin = nn.Linear(784, 10)
def forward():
return self.lin(xb)
Instantiate the model and calculate loss
model = Mnist_Logistc()
print(loss_func(model(xb), yb))
Output :
tensor(2.3694, grad_fn=<NllLossBackward0>)
Use fit Method training :
fit()
print(loss_func(model(xb), yb))
Output :
tensor(0.0820, grad_fn=<NllLossBackward0>)
Use optim restructure
Pytorch There are also libraries containing various optimization algorithms :torch.optim. We can use step Method instead of manually updating parameters .
This can replace the current manual optimization steps :
with torch.no_grad():
for p in model.parameters(): p -= p.grad * lr
model.zero_grad()
But only with :
opt.step()
opt.zero_grad()
(optim.zero_grad() Reset the gradient to 0, Need to calculate the next minibatch Call before gradient of )
for torch import optim
Define a small function to create the model and optimizer , For later use :
def get_model():
model = Mnist_Logistic()
return model, optim.SGD(model.parameters(), lr=lr)
model, opt = get_modle()
print(loss_func(model(xb), yb))
for epoch in range(epochs):
for i in range((n - 1) // bs + 1):
start_i = i * bs
end_i = start_i + bs
xb = x_train[start_i:end_i]
yb = y_train[start_i:end_i]
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
print(loss_func(model(xb), yb))
Output :
tensor(2.3185, grad_fn=<NllLossBackward0>)
tensor(0.0827, grad_fn=<NllLossBackward0>)
Use Dataset restructure
PyTorch There is an abstract Dataset class . One Dataset It can be owned by any one __len__ function ( Can be Python Standards for len Function call ), And a __getitem__() function , Used to index .This tutorial Complete description of creating custom Dataset Example , take FacialLandmarkDataset Class as Dataset Subclasses of .
Pytorch Of TensorDataset It's a package tensor Of Dataset. By defining length And indexing , It also provides iterations 、 Index and follow tensor The way of slicing in the first dimension . This will make it easier for us to access independent variables and dependent variables in the same line during training .
from torch.utils.data import TensorDataset
x_train and y_train It can be put into a single TensorDataset, For iteration and slicing .
train_ds = TensorDataset(x_train, y_train)
Before , We need to iterate separately x and y Of minibatches:
xb = x_train[start_i:end_i]
yb = y_train[start_i:end_i]
Now? , These two steps can be combined into one step :
xb, yb = train_ds[i*bs : i*bs+bs]
model, opt = get_model()
for epcoh in range(epochs):
for i in range((n - 1) // bs + 1):
xb, yb = train_ds[i * bs: i * bs + bs]
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
print(loss_func(model(xb), yb))
Output :
tensor(0.0812, grad_fn=<NllLossBackward0>)
Use DataLoader restructure
Pytorch Of DataLoader Responsible for managing the batches. You can get it from any Dataset establish DataLoader.DataLoader Make iteration batch It is more convenient , Compared with train_ds[i * bs: i * bs + bs],DataLoader Automatically provide each minibatch.
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs)
previously , Loop iteration batches (xb, yb) That's true :
for i in range((n-1)//bs + 1):
xb,yb = train_ds[i*bs : i*bs+bs]
pred = model(xb)
Now? ,(xb, yb) Automatically from dataloader load , The cycle is more concise :
for xb, yb in train_dl:
pred = model(xb)
model, opt = get_model()
for epoch in range(epochs):
for xb, yb in train_dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
print(loss_func(model(xb), yb))
Output :
tensor(0.0824, grad_fn=<NllLossBackward0>)
Thanks to the Pytorch Of nn.Module,nn.Parameter,Dataset, and DataLoader, Our training cycle is now greatly reduced , And easier to understand . Now try to add the basic functions necessary for an effective model in practice .
Add validation
In the first section , We are just trying to establish a reasonable training cycle for training data . actually , You need one more validation set, To verify whether it is over fitted .
Disrupting training data is important to prevent batch The connection between and over fitting is very important . But on the other hand , Whether or not shuffle Verification set , Verification set of loss It's all certain , therefore shuffle Validation sets are meaningless .
We use 2 Times the training set batch As a validation set batch. This is because the validation set does not need to be back propagated , There is no need to save the gradient , Only a small amount of memory . Take advantage of this , We use bigger batch size And calculate losses faster .
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs*2)
We will be in each epoch End the calculation and print the validation set loss
( Be careful , Call before training model.train(), Call before reasoning model.eval(), This is because layers It uses such as nn.BatchNorm2d、nn.Dropout, These are not required for verification )
model, opt = get_model()
for epoch in range(epochs):
model.train()
for xb, yb in train_dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()
model.eval()
with torch.no_grad():
valid_loss = sum(loss_func(model(xb), yb) for xb, yb in valid_dl)
print(epoch, valid_loss / len(valid_dl))
Output :
0 tensor(0.3260)
1 tensor(0.2793)
structure fit() and get_data()
Now do some custom refactoring . Because there are two similar processes of calculating losses during training and verification , We now put it in function,loss_batch, It can be for each batch Calculate the loss .
We pass in for the training set optimizer, And used for back propagation , For the validation set , Unwanted optimizer, So this function will not carry out back propagation .
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
fit Run the necessary operations to train our model , And calculate each epoch Training and verification loss
import numpy as np
def fit(epochs, model, loss_func, opt, train_dl, valid_dl):
for epoch in range(epochs):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print(epoch, val_loss)
get_data Returns the number of training sets and validation sets dataloaders
def get_data(train_ds, valid_ds, bs):
return(
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
Now? , All the processes , Including data loading 、 Fitting model can be used 3 Line of code runs
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(epochs, model, loss_func, opt, train_dl, valid_dl)
Output :
0 0.37930963896512987
1 0.28746109589338303
You can use this 3 Line based code trains various models . Let's see if we can train with these three lines of code CNN.
Switch to CNN
We are now going to build with 3 Layer by layer neural network . Because the previous section did not assume functions about the model form , So you can use the above 3 Line code direct training CNN, No changes needed .
We will use Pytorch The predefined Conv2d Class as our convolution layer . Define a with 3 Laminated CNN. Each convolution layer is followed by a ReLU. Last , Use an average pooling layer ( Be careful ,view when numpy Medium reshape Corresponding pytorch edition )
class Mnist_CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1)
def forward(self, xb):
xb = xb.view(-1, 1, 28, 28)
xb = F.relu(self.conv1(xb))
xb = F.relu(self.conv2(xb))
xb = F.relu(self.conv2(xb))
xb = F.avg_pool2d(xb, 4)
return xb.view(-1, xb.size(1))
lr = 0.1
Momentum Is a variant of random gradient descent , It is considered and falls behind the previous update , It usually makes training faster .
model = Mnist_CNN()
opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
fit(epochs, model, loss_func, opt, train_dl, valid_dl)
Output :
0 0.36561058859825135
1 0.2279014788389206
nn.Sequential
torch.nn There is another convenient class that can be used to simplify our code :Sequential . One Sequential Object runs each module contained in it in sequence . This is a simpler way to write Neural Networks .
To take advantage of this , We need to define a from a given function custom layer. for example ,PyTorch No, view layer , We need to create one ,Lambda A layer will be created , When using Sequential When defining neural networks, you can use .
class Lambda(nn.Module):
def __init__(self, func):
super().__init__()
self.func = func
def forward(self, x):
return self.func(x)
def preprocess(x):
return x.view(-1, 1, 28, 28)
Use Sequential establish model It's simpler :
model = nn.Sequential(
Lambda(preprocess),
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.AvgPool2d(4),
Lambda(lambda x: x.view(x.size(0), -1)),
)
opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
fit(epochs, model, loss_func, opt, train_dl, valid_dl)
Output :
0 0.3266831987142563
1 0.24143515722751618
Wrapping DataLoader
our CNN It's quite simple , But it can only be used in MNIST Upper use , because :
- It assumes that the input is 28*28 The long vector of
- It assumes the last CNN The grid size is 4*4( This is the average pooled core size we use )
Let's jump out of the above two assumptions , So that our model can be used for any 2 Dimensional single channel pictures . First , We can remove the initial by moving the data preprocessing to the generator Lambda layer .
def preprocess(x, y):
return x.view(-1, 1, 28, 28), y
class WrapperDataLoader:
def __init__(self, dl, func):
self.dl = dl
self.func = func
def __len__(self):
return len(self.dl)
def __iter__(self):
for b in batches:
yield (self.func(*b))
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
train_dl = WrapperDataLoader(train_dl, preprocess)
valid_dl = WrapperDataLoader(valid_dl, preprocess)
Next , Use nn.AdaptiveAvgPool2d Instead of nn.AvgPool2d, It allows us to define what we need output tensor size , Instead of what we already have input tensor. such , The model can be applied to any input size .
model = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 16, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1),
Lambda(lambda x: x.view(x.size(0), -1)),
)
opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
Have a try :
fit(epochs, model, loss_func, opt, train_dl, valid_dl)
Output :
0 0.3653434091329575
1 0.31836258018016816
Use GPU
If you can use support CUDA Of GPU( You can choose from most cloud providers in 0.5 dollar / Rent one per hour ) Speed up your code . First check your GPU Can it be in Pytorch Run in :
print(torch.cuda.is_available())
Output :
True
And then create a device object
dev = torch.device(
"cuda") if torch.cuda.is_available() else torch.device("cpu")
to update preprocess, take batches Move to GPU On :
def preprocess(x, y):
return x.view(-1, 1, 28, 28).to(dev), y.to(dev)
train_dl, valid_dl = get_data(train_ds, valid_ds, bs)
train_dl = WrappedDataLoader(train_dl, preprocess)
valid_dl = WrappedDataLoader(valid_dl, preprocess)
Last , take model Move to GPU:
model.to(dev)
opt = optim.SGD(model.parameters(), lr=lr, momentum=0.9)
You will find that it runs faster now :
fit(epochs, model, loss_func, opt, train_dl, valid_dl)
Output :
0 0.22935870126485824
1 0.21556809792518616
Closing thougths
Now we have a general data pipeline And the training cycle , utilize Pytorch, You can train many types of models. To understand how simple the current training model is , You can see mnist_sample Examples notebook.
Of course , There are many more you want to add , Such as data enhancement 、 Super parameter adjustment 、 Monitor training 、 Transfer learning and so on . These functions are fastai In the library , It was developed using the same design methodology shown in this tutorial , It provides convenience for practitioners who want to further develop the model .
We promise at the beginning , It will be explained by examples torch.nn、'torch.optim'、'Dataset'、'DataLoader'. So let's summarize the above :
torch.nn
Module: Create a callable object similar to a function , But it can also include some states ( Such as the weight of neural network layer ). It knows what it containsParameter(s), And can reduce their gradient to 0, Loop through them for weight updates, etc .Parameter:a wrapper for a tensor. It tellsModuleThe weight that needs to be updated during back propagation . Only with requires_grad Attribute tensor Will be updated .functional: An activation function 、 Loss function and other modules ( Usually imported asF), It also includes non-stateful Version layer , For example, convolution layer and linear layer .
torch.optim: Include optimizer , for exampleSGDetc. , In back propagation step In the updateParamterThe weight of .Dataset: One has__len__and__getitem__The abstract interface of the object , Include Pytorch Class provided , Such asTensorDataset.DataLoader: Receive anyDataset, And create an iterator , The iterator returns batches.