当前位置:网站首页>服务熔断 Hystrix
服务熔断 Hystrix
2022-07-05 05:14:00 【喵先森爱吃鱼】
一、概述
1.1 分布式面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免的失败、
服务雪崩
多个微服务之间调用的时候,假设微服务 A 调用微服务 B 和微服务 C,微服务 B 和微服务 C 又调用其他的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务 A 的调用就会占用越来越多的系统资源,进而引起系统崩溃,这就叫做“雪崩效应”。
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不会影响整个应用程序或系统。所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫做雪崩。
1.2 Hystrix
Hystrix 是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统中,许多依赖不可避免的会调用失败,比如超时、异常等。Hystrix 能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似于熔断保险丝),向调用方返回一个复核预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
1.3 Hystrix 作用
- 包裹请求:使用 HystrixCommand 包裹队以来的调用逻辑,每个命令在独立线程中执行。者使用了设计模式中的“命令模式”。
- 跳闸机制:当某服务的错误率超过一定的阈值时,Hystrix 可以自动或手动跳闸,停止请求该服务一段时间。
- 资源隔离:Hystrix 为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程池已满,发往该依赖的请求就会被立即拒绝,而不是排队等待,从而加速失败判定。
- 监控:Hystrix 可以近乎实时的监控运行指标和配置的变化,例如成功、失败、超时,以及被拒绝的请求等。
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑。回退逻辑由开发人员自行提供,例如返回一个缺省值。
- 自我修复:断路器打开一段时间后,会自动进入“半开”状态。
1.4 Hystrix 重要概念
1.4.1 服务隔离
是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相对独立,无强依赖。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不波及其他模块,不影响整体的系统服务。
1.4.2 服务熔断
熔断这一概念来源与电子工程中的断路器(Circuit Breaker)。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。
1.4.3 服务降级
所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的 fallback 回调,返回一个缺省值。也可以理解为兜底。
哪些情况会触发降级?
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
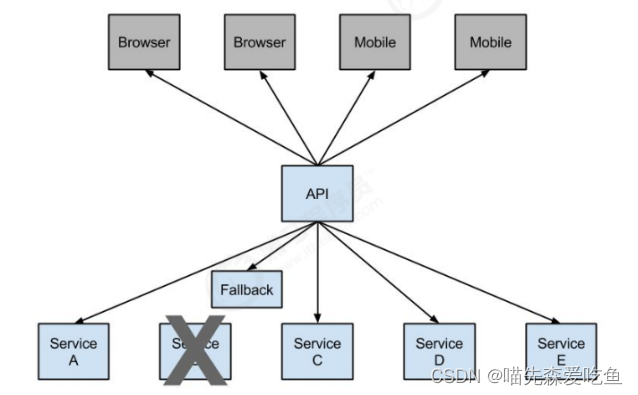
1.4.4 服务限流
限流可以认为服务降级的一种,限流就是限制系统的输入和输出流量,以达到保护系统的目的。一般来说,系统的吞吐量是可以被测算的,为了保证系统的稳固运行,一旦达到需要限制的阈值,就需要限制流量并采取少量措施以完成限制流量的目的。比方:推迟解决、拒绝解决,或者部分拒绝解决等等。
边栏推荐
- Simple HelloWorld color change
- C # perspective following
- Magnifying glass effect
- Merge sort
- mysql审计日志归档
- UE fantasy engine, project structure
- Lua GBK and UTF8 turn to each other
- [paper notes] multi goal reinforcement learning: challenging robotics environments and request for research
- 669. Prune binary search tree ●●
- [转]: OSGI规范 深入浅出
猜你喜欢
Grail layout and double wing layout
C语言杂谈1
Panel panel of UI
Chinese notes of unit particle system particle effect

Page countdown

Data is stored in the form of table
AutoCAD - full screen display

Research on the value of background repeat of background tiling

小程序直播+電商,想做新零售電商就用它吧!
Unity find the coordinates of a point on the circle
随机推荐
C # perspective following
Data is stored in the form of table
How to choose a panoramic camera that suits you?
room数据库的使用
Unity shot tracking object
stm32Cubemx(8):RTC和RTC唤醒中断
Create a pyGame window with a blue background
[turn]: OSGi specification in simple terms
Basic knowledge points
Panel panel of UI
54. Spiral matrix & 59 Spiral matrix II ●●
Applet live + e-commerce, if you want to be a new retail e-commerce, use it!
2022上半年全国教师资格证下
《动手学深度学习》学习笔记
Unity check whether the two objects have obstacles by ray
支持多模多态 GBase 8c数据库持续创新重磅升级
Research and investment forecast report of adamantane industry in China (2022 Edition)
小程序直播+电商,想做新零售电商就用它吧!
Solon 框架如何方便获取每个请求的响应时间?
2022/7/1學習總結