当前位置:网站首页>神经网络入门(下)
神经网络入门(下)
2022-07-04 07:27:00 【Uncertainty!!】
神经网络入门(下)
笔记来源:Neural Networks Demystified
声明:本人为小白,第一次学习有关知识,本篇为学习笔记,如有错误,请各位大佬匹配指正!
Observation = Signal + Noise
模型应该适应信号,而不是适应噪音
What is Noise in Machine Learning?
Humans are prone to making mistakes when collecting data, and data collection instruments may be unreliable, resulting in dataset errors. The errors are referred to as noise. Data noise in machine learning can cause problems since the algorithm interprets the noise as a pattern and can start generalizing from it. --摘自:What is Noise in Machine Learning
Machine learning noise detection and removal
PCA attempts to eliminate corrupted data from a signal or picture using preservative noise while maintaining the critical features–摘自:What is Noise in Machine Learning
关于PCA我之前写过一篇笔记,传送门:主成分分析(Principal Component Analysis,PCA)
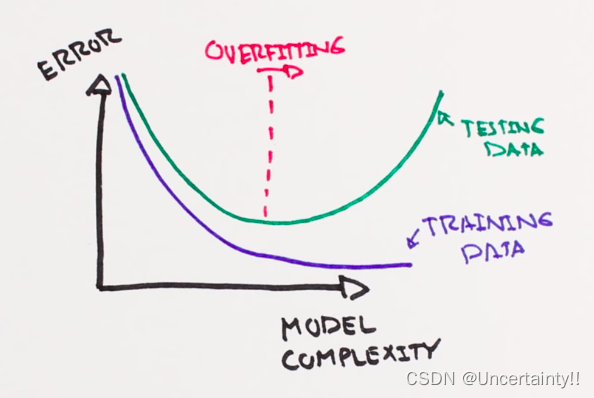
1.1 过拟合(Overfitting)
过拟合现象(Overfitting)
In mathematical modeling, overfitting is “the production of an analysis that corresponds too closely or exactly to a particular set of data, and may therefore fail to fit to additional data or predict future observations reliably” --摘自:Overfitting
绿线代表过拟合模型(也就是一个函数),能够很好符合训练数据,但对训练数据依赖性太高,一旦对不在训练数据中的未知数据进行预测时就会有较大偏差,过拟合模型缺乏泛化能力
黑线代表正则化模型(对过拟合模型的改进,提高泛化能力)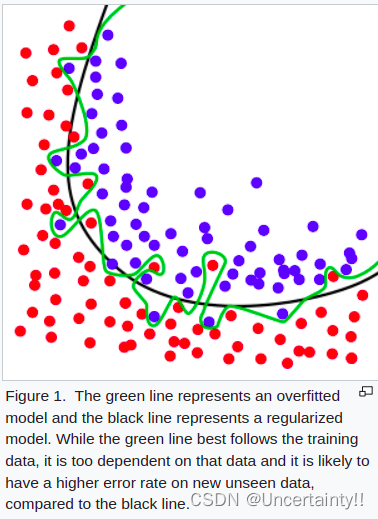
增加一组数据,使得过拟合更加明显
增加数据后,我们重新训练
绘制添加新数据后的图
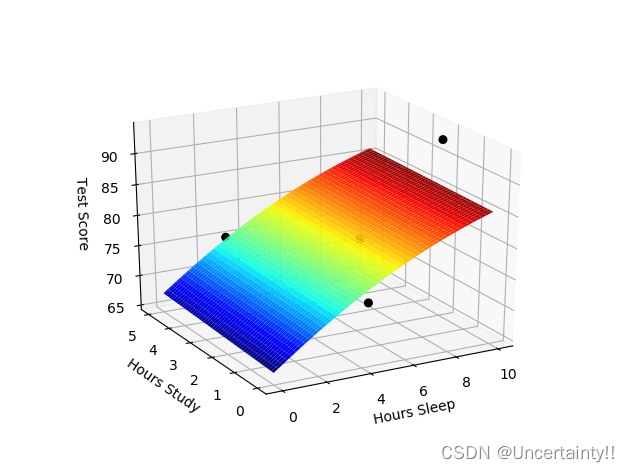
新训练模型(曲面)如下
黑色点为训练集数据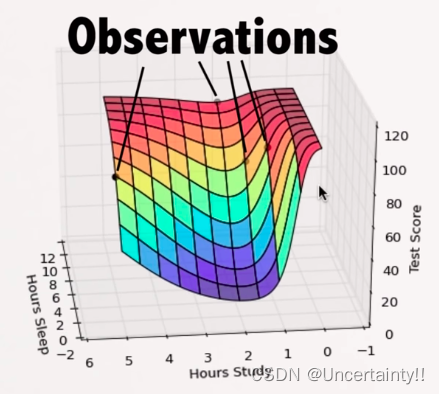
我们发现有些数据已经不符合事实,这是模型过拟合导致的
如下图所示,当Hours Sleep固定在一个值时,随着Hours Study的增加,TestScore会先减小后增加,这显然不符合现实
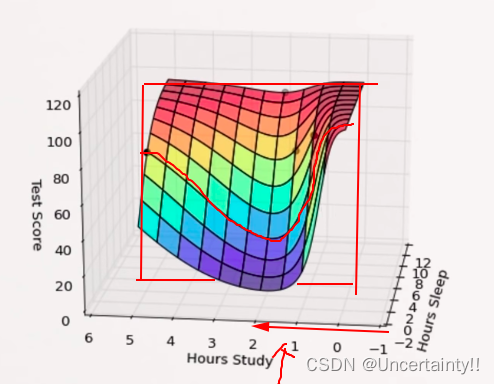
1.2 检测过拟合
如何检测模型是否过拟合?
首先我们将数据集分为:训练集和测试集
1.训练集
Your training data is a subset of your dataset that you use to teach a machine learning model to recognize patterns or perform your criteria. --摘自:What is Training Data?
2.测试集
Once your machine learning model is built (with your training data), you need unseen data to test your model. This data is called testing data, and you can use it to evaluate the performance and progress of your algorithms’ training and adjust or optimize it for improved results. --摘自:What is Testing Data?
Testing data has two main criteria. It should:
1.Represent the actual dataset
2.Be large enough to generate meaningful predictions
内容延展:对比数据集(Contrastive dataset)
Assume you need to clean a noisy dataset that includes big background patterns as noise that a data scientist isn’t interested in. Then, using an adaptive noise cancellation approach, this method offers a solution by eliminating the noisy signal. This technique employs two signals: one is the target signal, and the other is a noise-free background signal.–摘自:What is Noise in Machine Learning
傅里叶变换
Researches have already shown that our signal or data has a structure, we can remove noise from it directly. The Fourier Transform of the signal is used to translate the signal into the frequency domain in this process.–摘自:What is Noise in Machine Learning
信号的傅里叶变换常常将信号转到频域,从而去除对应的某个噪音
关于傅里叶变换我之前写过一篇笔记,传送门:傅里叶级数、傅里叶变换、频谱
下图来自LaTeX工作室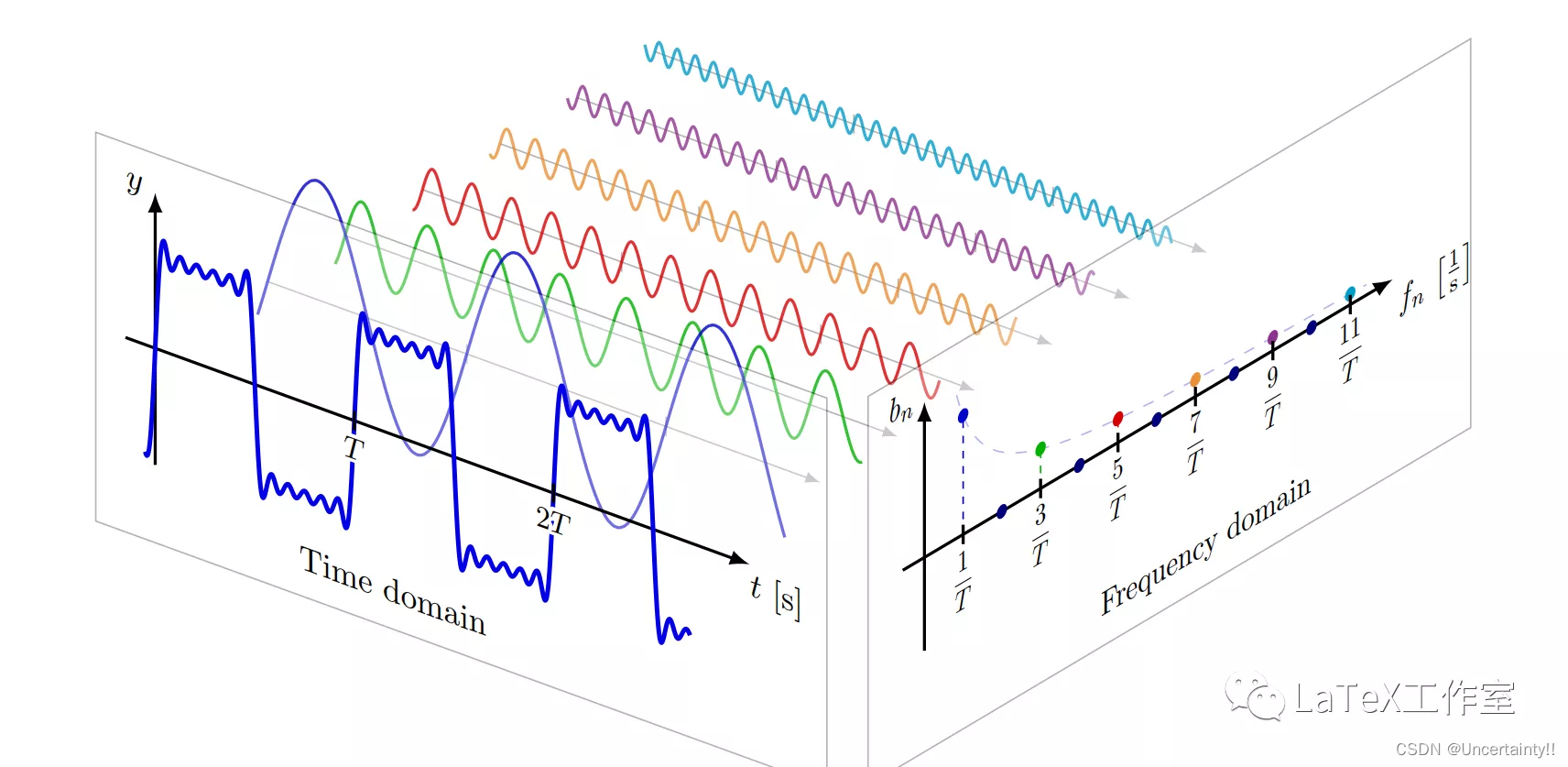
原数据集
训练集和测试集
我们通过测试集来检测过拟合
1.3 正则化(Regularization)
What is regularization?
Regularization is a process that changes the result answer to be “simpler”.–摘自:Regularization
Regularization is to add a term to our cost function that penalizes overly complex models
通过正则化来修复过拟合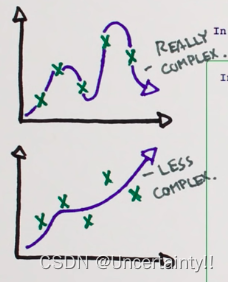
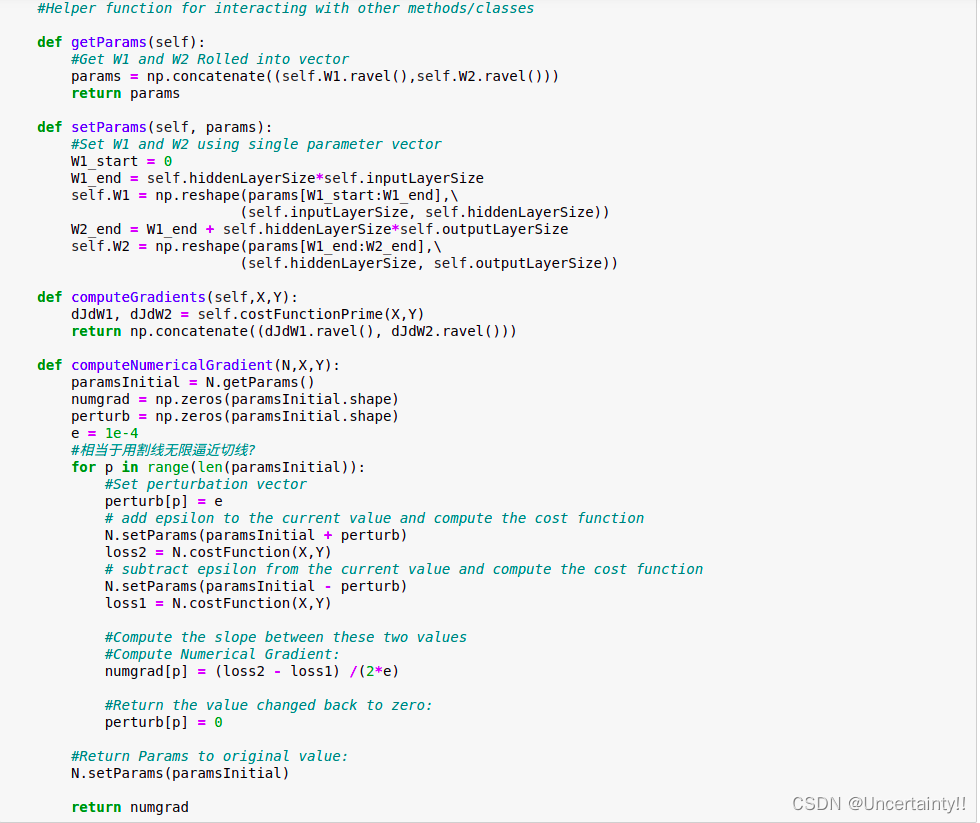
修改初始化函数,添加lambda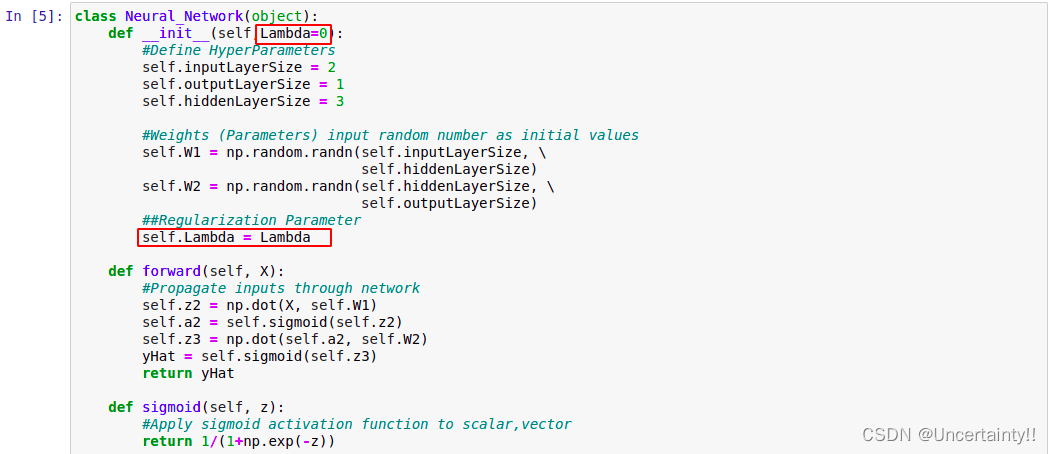 在代价函数J以及dJdW1和dJdW2中添加正则项
在代价函数J以及dJdW1和dJdW2中添加正则项
其余函数未进行改动
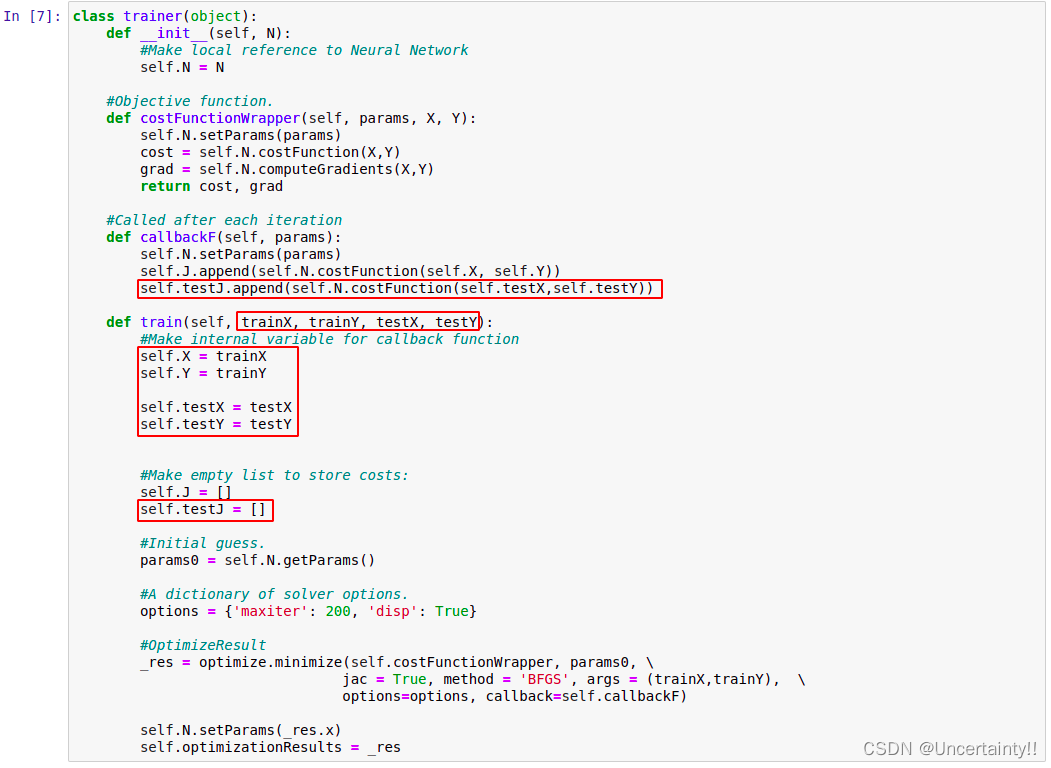
在trainer中新添加如下内容
所有修改均完成,接下来我们重新训练
下图为模型在测试集和训练集上的误差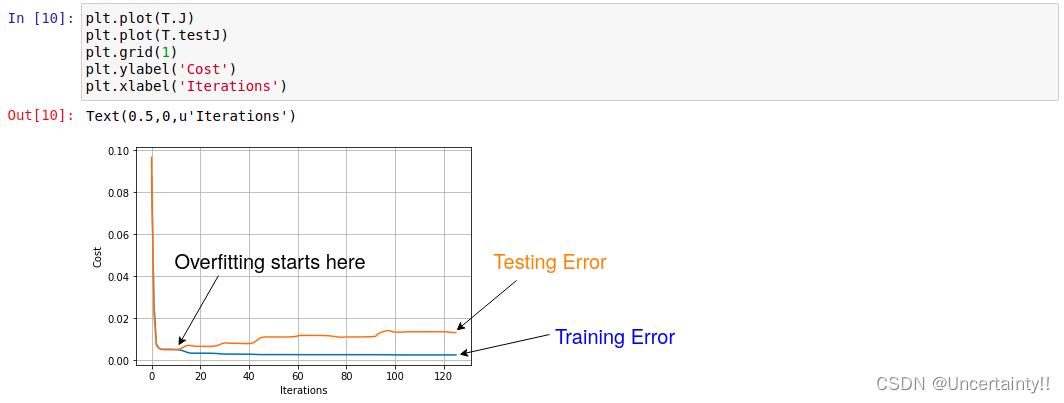 我们的目的是通过不断调整lambda使得Testing Error逐渐贴近Training Error,以提高模型的泛化能力
我们的目的是通过不断调整lambda使得Testing Error逐渐贴近Training Error,以提高模型的泛化能力
训练误差就是模型在训练集上的误差平均值,度量了模型对训练集拟合的情况。训练误差大说明对训练集特性学习得不够,训练误差太小说明过度学习了训练集特性,容易发生过拟合。–摘自模型评价——训练误差与测试误差、过拟合与欠拟合、混淆矩阵
测试误差是模型在测试集上的误差平均值,度量了模型的泛化能力。在实践中,希望测试误差越小越好。–摘自模型评价——训练误差与测试误差、过拟合与欠拟合、混淆矩阵
模型不再完美符合所有数据,也就完成了修复过拟合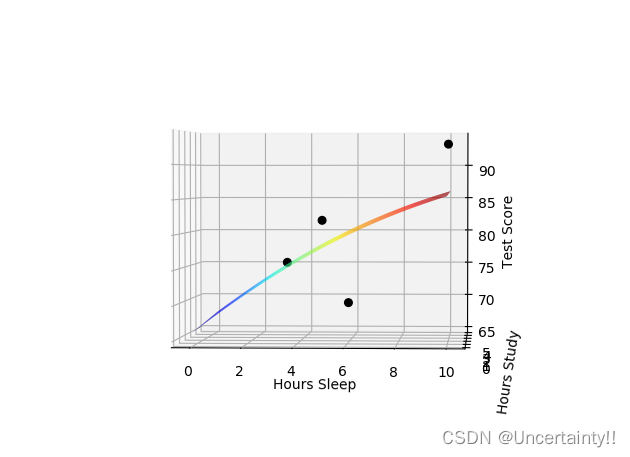
对应的contour图
边栏推荐
- How to buy financial products in 2022?
- Electronic Association C language level 1 34, piecewise function
- flask-sqlalchemy 循环引用
- Boast about Devops
- [C language] open the door of C
- Boosting the Performance of Video Compression Artifact Reduction with Reference Frame Proposals and
- Handwritten easy version flexible JS and source code analysis
- Zabbix agent主动模式的实现
- The cloud native programming challenge ended, and Alibaba cloud launched the first white paper on application liveliness technology in the field of cloud native
- Rhcsa the next day
猜你喜欢

The cloud native programming challenge ended, and Alibaba cloud launched the first white paper on application liveliness technology in the field of cloud native
Zephyr 学习笔记1,threads

Routing decorator of tornado project

大学阶段总结
The important role of host reinforcement concept in medical industry
Blog stop statement
Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool
Selenium driver ie common problem solving message: currently focused window has been closed
Zhanrui tankbang | jointly build, cooperate and win-win zhanrui core ecology
Zephyr Learning note 2, Scheduling
随机推荐
rapidjson读写json文件
Deep profile data leakage prevention scheme
[Chongqing Guangdong education] National Open University spring 2019 770 real estate appraisal reference questions
BibTex中参考文献种类
Blog stop statement
Rapidjson reading and writing JSON files
Cell reports: Wei Fuwen group of the Institute of zoology, Chinese Academy of Sciences analyzes the function of seasonal changes in the intestinal flora of giant pandas
云Redis 有什么用? 云redis怎么用?
Solution of running crash caused by node error
Rhcsa the next day
Valentine's Day is coming! Without 50W bride price, my girlfriend was forcibly dragged away...
电子协会 C语言 1级 34 、分段函数
Directory of tornado
Node connection MySQL access denied for user 'root' @ 'localhost' (using password: yes
BasicVSR++: Improving Video Super-Resolutionwith Enhanced Propagation and Alignment
jdbc连接es查询的时候,有遇到下面这种情况的大神嘛?
2022-021ARTS:下半年開始
"Sword finger offer" 2nd Edition - force button brush question
【森城市】GIS数据漫谈(一)
Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool