当前位置:网站首页>Reppoints: advanced order of deformable convolution
Reppoints: advanced order of deformable convolution
2022-07-06 17:42:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery I have always appreciated Microsoft's research , Especially deformable convolution , In my opinion, this job is very creative ( I like the idea of deformable convolution ), This time RepPoints This latest paper , Review deformable convolution .
This paper mainly deals with DCNv1、DCNv2、RepPoints Three articles , among RepPoints Think of it as DCNv3. These three articles continue to improve deformable convolution , Improve the geometric deformation modeling ability of the model .
Review of DCNv1 and DCNv2
By scale 、 Posture 、 Geometric changes caused by visual angle and partial deformation are the main challenges of target recognition and detection . In convolution /RoI In the pool module ,DCN The ability of geometric deformation modeling can be obtained by learning the location of sampling points .
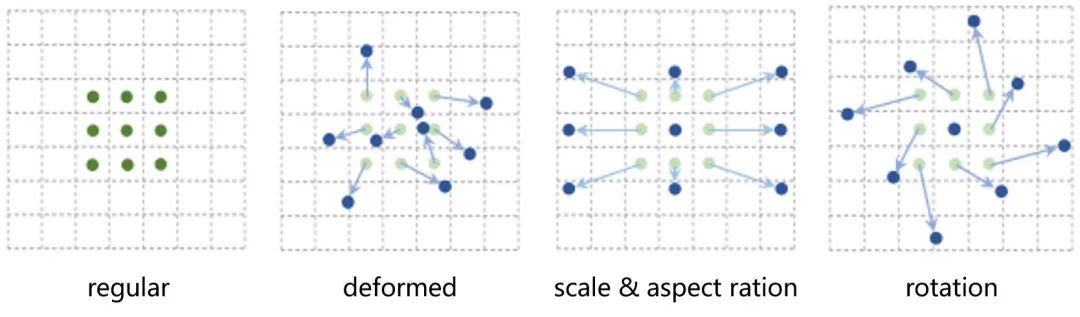
Deformable Convolution
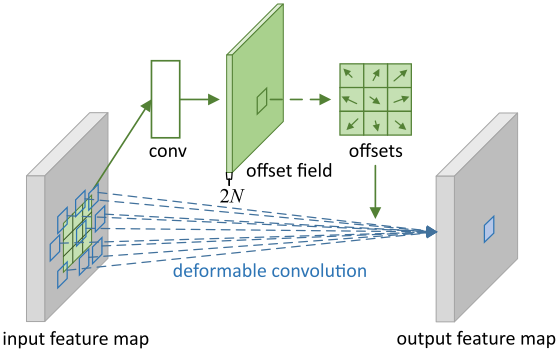
The sampling position of the standard convolution is changed by the offset obtained from the input feature learning .
Deformable convolution can be expressed as :

Given a Convolution kernel of sampling points , Expressed as No Weights of sampling points , Expressed as No Predefined offset of sampling points ( for example , and Defined a 3x3 Convolution kernel ). Defined as the input feature location Characteristics of , Defined as the output feature location Characteristics of . For convolution learning, the second Position offset of sampling points . because Is the decimal , therefore By bilinear interpolation .
PS: The resolution of the offset feature is the same as that of the input feature , And the number of channels is twice the number of sampling points ( That is, every position has x and y Offset in both directions ).
Modulated Deformable Convolution
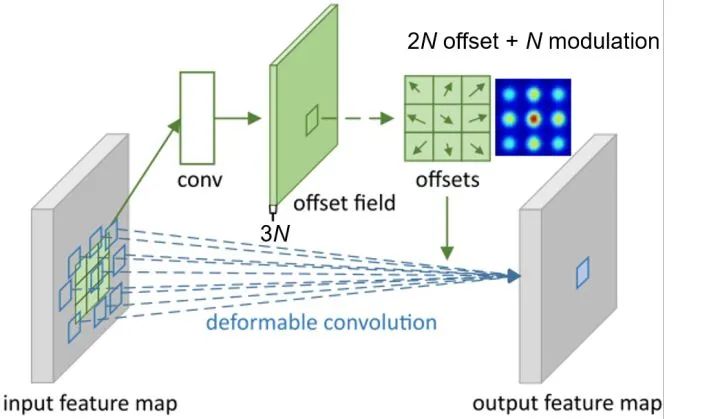
Compared with deformable convolution, it has one more modulation factor .
Modulation deformable convolution can be expressed as :
Expressed as No Modulation factor of sampling points ( The scope is Between ).
PS: The resolution of the modulation factor feature is the same as that of the input feature , And the number of channels is the number of sampling points , The number of channels after adding the offset feature is three times the number of sampling points ( That is, every position has x and y Offset in both directions , There is also a modulation factor ).
Deformable RoI Pooling
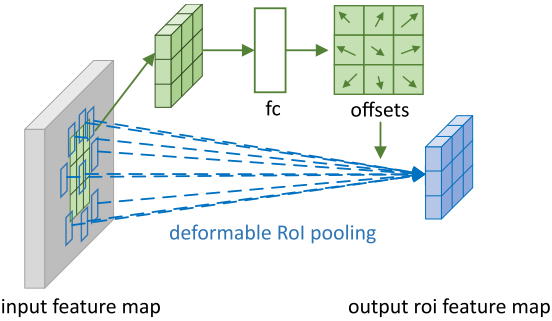
Given an input RoI,RoI pooling Divide it into individual bins. First, through RoI pooling Get the pooled feature maps, And then through a fc The layer produces a normalized offset ( This offset can be converted into ).
Single bin The output characteristics of can be expressed as :
Expressed as No individual bin Of the Location of two sampling points , Expressed as No individual bin The number of sampling points of . By bilinear interpolation . For the first time individual bin The offset .
PS:fc The output of the layer is bin Twice as many ( each bin There are x and y Offset in both directions ).
Modulated Deformable RoI Pooling
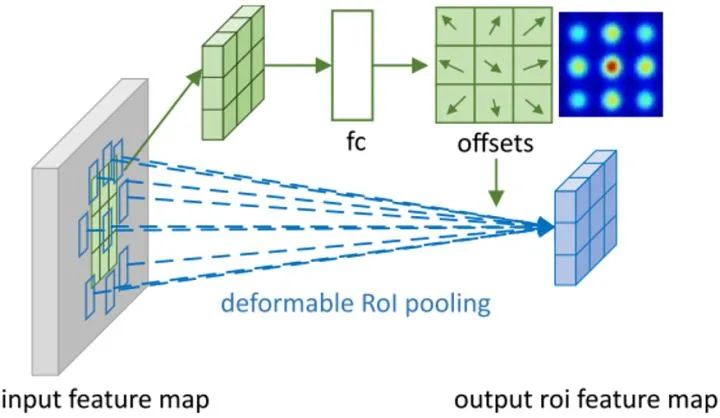
Single with modulation factor bin The output characteristics of can be expressed as :
For the first time individual bin Modulation factor ( The scope is Between ).
PS: There are two fc layer , the second fc The output of the layer is bin Three times the number ( each bin There are x and y Offset in both directions , There is also a modulation factor ).
RepPoints
Motivation
In the target detection task , The bounding box describes the target position of each stage of the target detector .
Although the bounding box is easy to calculate , But they only provide a rough location of the target , It does not completely fit the shape and posture of the target . therefore , The features extracted from the regular cells of the bounding box may be seriously affected by the invalid information of the background content or the foreground area . This may lead to a reduction in feature quality , Thus, the classification performance of target detection is reduced .
In this paper, a new representation method is proposed , be called RepPoints, It provides finer grained positioning and more convenient classification .
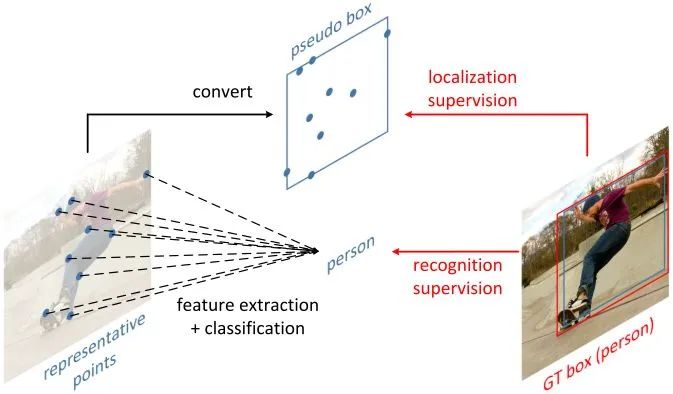
As shown in the figure ,RepPoints It's a set of points , By learning to put yourself adaptively above your goals , This method limits the spatial range of the target , It also represents local areas with important semantic information .
RepPoints The training of is driven by target location and recognition , therefore ,RepPoints And ground-truth The bounding box of is closely related , And guide the detector to correctly classify the target .
Bounding Box Representation
The bounding box is a 4 Wei said , The spatial location of the coding target , namely , Represents the center point , Indicates width and height .
Because of its simple and convenient use , Modern target detectors rely heavily on bounding boxes to represent detection pipeline The objects of each stage in .
The target detector with the best performance usually follows a multi-stage Recognition paradigm of , Among them, the target positioning is gradually refined . among , The roles represented by the goal are as follows :
RepPoints
As mentioned earlier ,4 The dimension bounding box is a rough representation of the target location . The bounding box indicates that only the rectangular space range of the target is considered , Don't think about shape 、 The position of local areas that are important in posture and semantics , These can be used for better positioning and better target feature extraction .
To overcome these limitations ,RepPoints Instead, model a group of adaptive sample points :
among Is the total number of sample points used in the representation . In this work , The default setting is 9.
Learning RepPoints
RepPoints Learning is driven by the loss of target location and target recognition . In order to calculate the target location loss , We first use a conversion function take RepPoints Convert to pseudo frame (pseudo box). then , Calculate the converted pseudo box and ground truth Differences between bounding boxes .
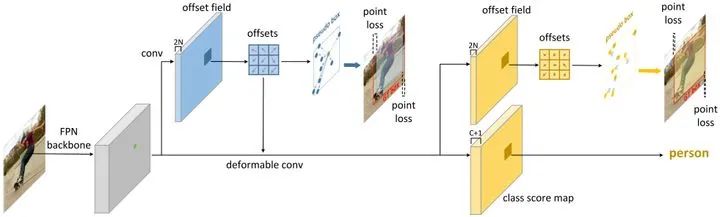
RPDet
The author designed a kind of non use anchor Object detector for , It USES RepPoints Replace the bounding box as the basic representation of the target .
The evolution process of target representation is as follows :
RepPoints Detector (RPDet) It consists of two recognition stages based on deformable convolution , As shown in the figure .
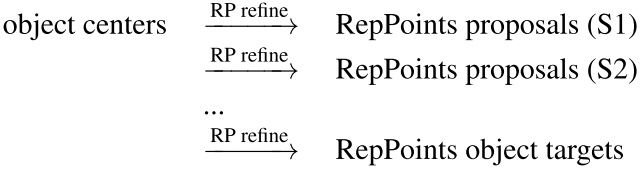
Deformable convolution and RepPoints Well combined , Because its convolution is calculated on a group of irregularly distributed sampling points , in addition , Its classification can guide the positioning of these points in training .
The first offset in the above figure is obtained through diagonal point supervised learning , The second offset is obtained by classification supervision learning on the basis of the previous offset .
To understand from another angle RepPoints:
Deformable convolution is supervised by the final classification branch and regression Branch , Adaptive attention to the appropriate feature location , Extract better features , But what I haven't figured out is whether deformable convolution can really pay attention to the appropriate feature location , The offset learning of deformable convolution is very free , May run away from the target , So are these features really helpful , These problems have been bothering me , I think the intermediate process of deformable convolution is too vague , Too indirect , It's hard to explain . and RepPoints The learning of offset is directly supervised by the supervision signals of positioning and classification , In this way, the offset can be explained , The offset position makes the positioning and classification more accurate ( That is, the offset position can locate the target and the semantic information can identify the target ), In this way, the offset will not run around , And it's explicable .
Think of it in this way ,RepPoints In fact, it is a further improvement of deformable convolution , Compared with deformable convolution, it has two advantages :
1. Learn the offset of deformable convolution through direct supervision of location and classification , Make the offset interpretable .
2. You can directly generate pseudo frames by sampling points (pseudo box), There is no need to learn the bounding box , And classification and positioning are related .
The good news !
Xiaobai learns visual knowledge about the planet
Open to the outside world

download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , Cover expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing and other more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download, including image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 Face recognition, etc 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 A real project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Please do not send ads in the group , Or you'll be invited out , Thanks for your understanding ~边栏推荐
- DataGridView scroll bar positioning in C WinForm
- How to submit data through post
- JUnit unit test
- Based on infragistics Document. Excel export table class
- PySpark算子处理空间数据全解析(4): 先说说空间运算
- The art of Engineering (2): the transformation from general type to specific type needs to be tested for legitimacy
- Single responsibility principle
- 中移动、蚂蚁、顺丰、兴盛优选技术专家,带你了解架构稳定性保障
- 轻量级计划服务工具研发与实践
- The NTFS format converter (convert.exe) is missing from the current system
猜你喜欢
C#版Selenium操作Chrome全屏模式显示(F11)
Application service configurator (regular, database backup, file backup, remote backup)
Flink parsing (VII): time window
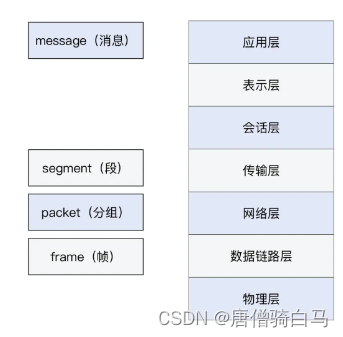
Concept and basic knowledge of network layering

Vscode replaces commas, or specific characters with newlines
FlutterWeb浏览器刷新后无法回退的解决方案
自动答题 之 Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
04个人研发的产品及推广-数据推送工具
![Case: check the empty field [annotation + reflection + custom exception]](/img/50/47cb40e6236a0ba34362cdbf883205.png)
Case: check the empty field [annotation + reflection + custom exception]
Huawei certified cloud computing hica
随机推荐
C#WinForm中的dataGridView滚动条定位
基于Infragistics.Document.Excel导出表格的类
【MySQL入门】第四话 · 和kiko一起探索MySQL中的运算符
The NTFS format converter (convert.exe) is missing from the current system
Xin'an Second Edition: Chapter 25 mobile application security requirements analysis and security protection engineering learning notes
Vscode matches and replaces the brackets
C # nanoframework lighting and key esp32
Error: Publish of Process project to Orchestrator failed. The operation has timed out.
connection reset by peer
Kali2021 installation and basic configuration
Debug xv6
EasyCVR平台通过接口编辑通道出现报错“ID不能为空”,是什么原因?
MySQL报错解决
05个人研发的产品及推广-数据同步工具
RepPoints:可形变卷积的进阶
03个人研发的产品及推广-计划服务配置器V3.0
Xin'an Second Edition: Chapter 23 cloud computing security requirements analysis and security protection engineering learning notes
pip install pyodbc : ERROR: Command errored out with exit status 1
灵活报表v1.0(简单版)
【MySQL入门】第一话 · 初入“数据库”大陆