当前位置:网站首页>The latest progress and development trend of 2022 intelligent voice technology
The latest progress and development trend of 2022 intelligent voice technology
2022-07-02 09:45:00 【kaiyuan_ sjtu】
Learn in depth 、 Driven by big data and big computing power , Speech enhancement 、 Intelligent speech technology represented by recognition and synthesis has been applied in many applications . I've compiled some cutting-edge reports for you , Wen Wuke Free access .
No.1
New progress and development trend of intelligent voice technology
Speaker : Xie Lei
Professor of Northwestern Polytechnic University , With concurrent
Head of the audio speech and Language Processing Laboratory of West University of Technology
Abstract :
This report will combine the recent research results of the audio speech and language processing research group of Western Polytechnic University with the development status of intelligent speech technology , Focus on speech enhancement 、 Recent advances in recognition and synthesis . At the same time, with the continuous expansion of scenarios and Applications , Challenges of intelligent voice technology and prospects for future development .
No.2
Research progress of end-to-end sound source separation
Speaker : Luo Yi
PhD student at Neural acoustic processing lab (Naplab),Columbia University.
Abstract :
Recent progress in deep learning methods for the task of source separation have significantly advanced the state-of-the-art.
Among all the recent proposals, end-to-end systems that take waveform as input and directly generate waveforms have shown their advantage on both the system performance and the flexibility. In this talk, I will briefly go through some of the recent advances in the problem of end-to-end neural source separation. I will start with the general problem definition of source separation, then introduce several single-channel and multi-channel approaches, and conclude with the challenges and future works in this area.
Scan the code to get all the reports for free
↓↓↓

No.3
Multi speaker segmentation and clustering based on deep learning
Speaker : juck
University of Cambridge Research Associate
JD technical advisor
Abstract :
This open class first introduces the traditional multi speaker segmentation and clustering system of Cambridge University , The system has obtained ASRU 2015 MGB The champion of the speaker segmentation clustering task in the challenge , Then it introduces some work of the team recently using deep neural network to segment different parts of the clustering system . Finally, it also includes the discussion of some hot issues in the research of multi speaker segmentation and clustering , Including how to achieve a complete end-to-end neural network ( Trainable ) System and how to integrate segmentation and clustering with speech separation and recognition .
No.4
Sound event detection under weak tagging
Speaker : Wang Yun
Facebook The artificial intelligence application research group studies scientists
Carnegie Mellon University (CMU) Institute of computer technology (LTI) Doctor
Abstract :
Sound event detection (sound event detection), It refers to the detection of gunfire in the audio 、 Dog barking and other events , And mark their start and end time . Because it is troublesome to manually standard the start and end time for training data , Therefore, the actual training data is often only weakly labeled —— Only the event type contained in each sound is marked , But the starting and ending time is not marked . This lecture discusses how to use 「 Learn from various examples 」(multiple instance learning) Method , Using weak labeled data to train sound event detection system , The key is how to select the aggregate function , Maintain the balance between false detection and missed detection . The experience gained from this lecture , It can also be used for reference 「 Learn from various examples 」 In the task of .
No.5
Intelligent voice development status and data set introduction
Speaker : Chen Guoguo
SEASALT.AI cofounder
Dr. Johns Hopkins University
Abstract :
Share and discuss the current problems in the voice field , example : When intelligent voice is landing on the embedded device , Compared with the server side, what factors need to be considered ; At the same time, combine their own scientific research and entrepreneurial experience to scientific research colleagues 、 Students in school 、 Some practical suggestions , Let's avoid detours !
No.6
Research progress of accent and dialect speech recognition
Speaker : Tangzhiyuan
Dr. Lian Pei, Chinese Academy of Sciences and Tsinghua University
Tsinghua postdoctoral
Abstract :
Speech recognition technology has been widely used in daily life , However, its performance or experience in accent or dialect is still not satisfactory . This report gives a quick review of the research progress of accent and dialect speech recognition in recent years , And further introduces the data related to accent or dialect speech recognition 、 Benchmarks and competitions , And some feasible research directions .
Scan the code to get all the reports for free
↓↓↓
边栏推荐
- C语言之判断直角三角形
- C语言之数据插入
- Error reporting on the first day of work (incomplete awvs unloading)
- Junit5 支持suite的方法
- C语言之分草莓
- How to choose between efficiency and correctness of these three implementation methods of distributed locks?
- ZK configuration center -- configuration and use of config Toolkit
- 攻防世界-Web进阶区-unserialize3
- 分享一篇博客(水一篇博客)
- c语言编程题
猜你喜欢
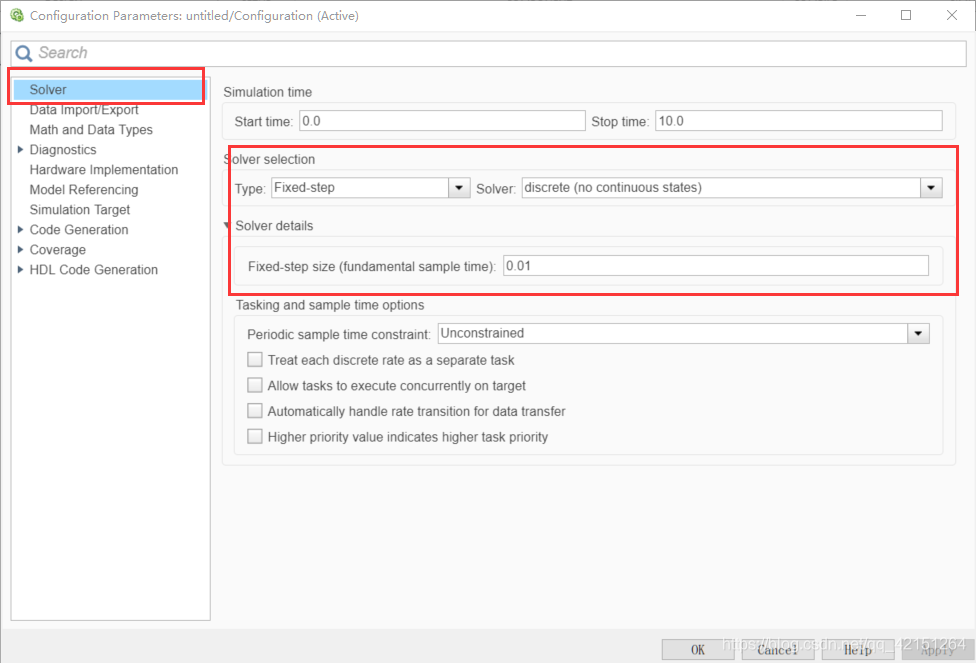
2837xd 代碼生成——補充(1)

2837xd 代码生成——补充(2)
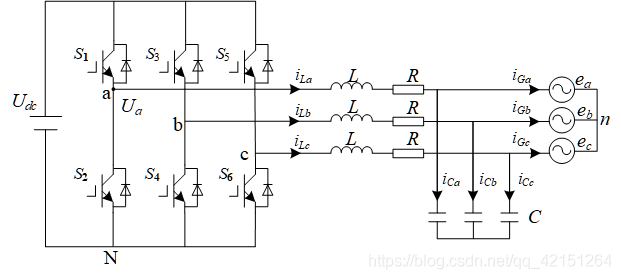
PI control of grid connected inverter (grid connected mode)
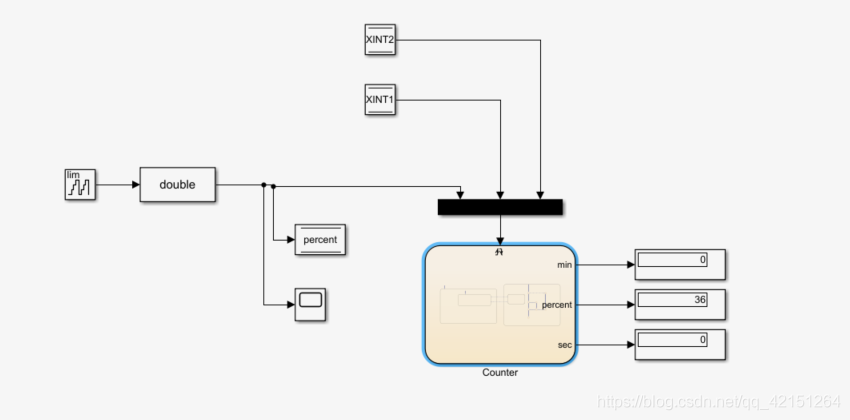
2837xd 代码生成——StateFlow(4)

分享一篇博客(水一篇博客)

Inverter Simulink model -- processor in the loop test (PIL)

Off grid control of three-phase inverter - PR control

Read Day6 30 minutes before going to bed every day_ Day6_ Date_ Calendar_ LocalDate_ TimeStamp_ LocalTime

2837xd 代码生成——补充(3)

ESLint 报错
随机推荐
What are the differences between TP5 and laravel
Alibaba /热门json解析开源项目 fastjson2
QT信号槽总结-connect函数错误用法
web安全与防御
2837xd code generation - stateflow (4)
Typora安装包分享
Enterprise level SaaS CRM implementation
Activity的创建和跳转
上班第一天的报错(AWVS卸载不彻底)
2837xd代码生成模块学习(3)——IIC、eCAN、SCI、Watchdog、eCAP模块
Who is better for Beijing software development? How to find someone to develop system software
2837xd 代码生成——总结篇
Inverter Simulink model -- processor in the loop test (PIL)
2837xd 代码生成——补充(1)
BugkuCTF-web24(解题思路及步骤)
Bugkuctf-web16 (backup is a good habit)
Image recognition - Data Acquisition
MySql报错:unblock with mysqladmin flush-hosts
2837xd 代码生成——补充(2)
图像识别-数据标注