当前位置:网站首页>Some principles of mongodb optimization
Some principles of mongodb optimization
2022-07-07 13:12:00 【cui_ yonghua】
The basic chapter ( Can solve the problem of 80% The problem of ):
MongoDB data type 、 Key concepts and shell Commonly used instructions
MongoDB Various additions to documents 、 to update 、 Delete operation summary
Advanced :
Other :
1. Query optimization
Make sure your query takes full advantage of the index , use explain Command to check the execution of the query , Add the necessary indexes , Avoid table scanning .
2. Figure out the size of the hot data
Maybe your data set is very large , But it's not that important , What matters is how big your thermal data set is , How big is the data you often visit ( Including frequently accessed data and all index data ).
Use MongoDB, You'd better make sure your hot data is below the memory size of your machine , Make sure the memory can hold all the hot data .
3. Choose the right file system
MongoDB The data file is pre allocated , And in Replication Inside ,Master and Replica Sets Non - Arbiter Nodes will create enough empty files in advance to store operation logs .
These file allocation operations can be very slow on some file systems , Cause the process to be Block. So we should choose those file systems with fast space allocation . The conclusion here is to try not to use ext3, use ext4 perhaps xfs.
4. Choose the right hard disk
The choices here include the disk RAID The choice of , It also includes disks and SSD Comparative selection of .
5. Use less as far as possible in How to query
Especially in shard On , He will let your inquiry go by a shand Last run , If you have to use it as a last resort shard Index up .
Optimize in The way is to in Decompose into single queries one by one . The speed will increase 40-50 times
6. Reasonable design sharding key
The incremental sharding-key: Suitable for fields that can be delimited , such as integer、float、date Type of , The query time is relatively fast
Random sharding-key: It is suitable for the scenario of frequent write operations , And in this case, if it's in a shard It's going to make this shard The load is higher than the others , It's not balanced , So I hope to hash Inquire about key, Distribute writes across multiple locations shard on , Consider compounding key As sharding key, The general principle is fast query , Try to reduce the number of spans shard Inquire about ,balance Less equalization .
mongodb The default is a single record 16M, Especially in the use of GFS When , Be sure to pay attention to shrading-key The design of the .
Unjustified sharding-key There will be , Multiple documents , In a chunks On , meanwhile , because GFS Large files are often stored in , Lead to mongodb Doing it balance You can't get through sharding-key To separate these documents into different shard On , Now mongodb Will constantly report errors [conn27669] Uncaught std::exception: St9bad_alloc, terminating. Finally lead to mongodb Fall down .
terms of settlement : enlarge chunks size ( Cure the symptoms ), Well designed sharding-key( Permanent cure ).
7.mongodb Can pass profile To monitor data , To optimize .
See if it's on profile function Command db.getProfilingLevel() return level Grade , The value is 0|1|2,
Respectively means :0 On behalf of closed ,1 For recording slow orders ,2 Represent all
Turn on profile The function command is db.setProfilingLevel(level); #level Grade , The value is the same as above. level by 1 When , The default value of slow command is 100ms, Change to db.setProfilingLevel(level,slowms) Such as db.setProfilingLevel(1,50) This changes to 50 millisecond
adopt db.system.profile.find() View the current monitoring log .
边栏推荐
- Milkdown 控件图标
- .Net下极限生产力之efcore分表分库全自动化迁移CodeFirst
- 初学XML
- HZOJ #235. Recursive implementation of exponential enumeration
- Japanese government and enterprise employees got drunk and lost 460000 information USB flash drives. They publicly apologized and disclosed password rules
- How to continue after handling chain interruption / sub chain error removed from scheduling
- Realbasicvsr test pictures and videos
- DHCP 动态主机设置协议 分析
- 《ASP.NET Core 6框架揭秘》样章[200页/5章]
- 滑轨步进电机调试(全国海洋航行器大赛)(STM32主控)
猜你喜欢
![《ASP.NET Core 6框架揭秘》样章[200页/5章]](/img/4f/5688c391dd19129d912a3557732047.jpg)
《ASP.NET Core 6框架揭秘》样章[200页/5章]

Coscon'22 community convening order is coming! Open the world, invite all communities to embrace open source and open a new world~
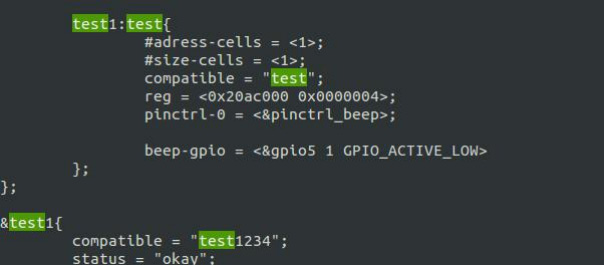
迅为iTOP-IMX6ULL开发板Pinctrl和GPIO子系统实验-修改设备树文件
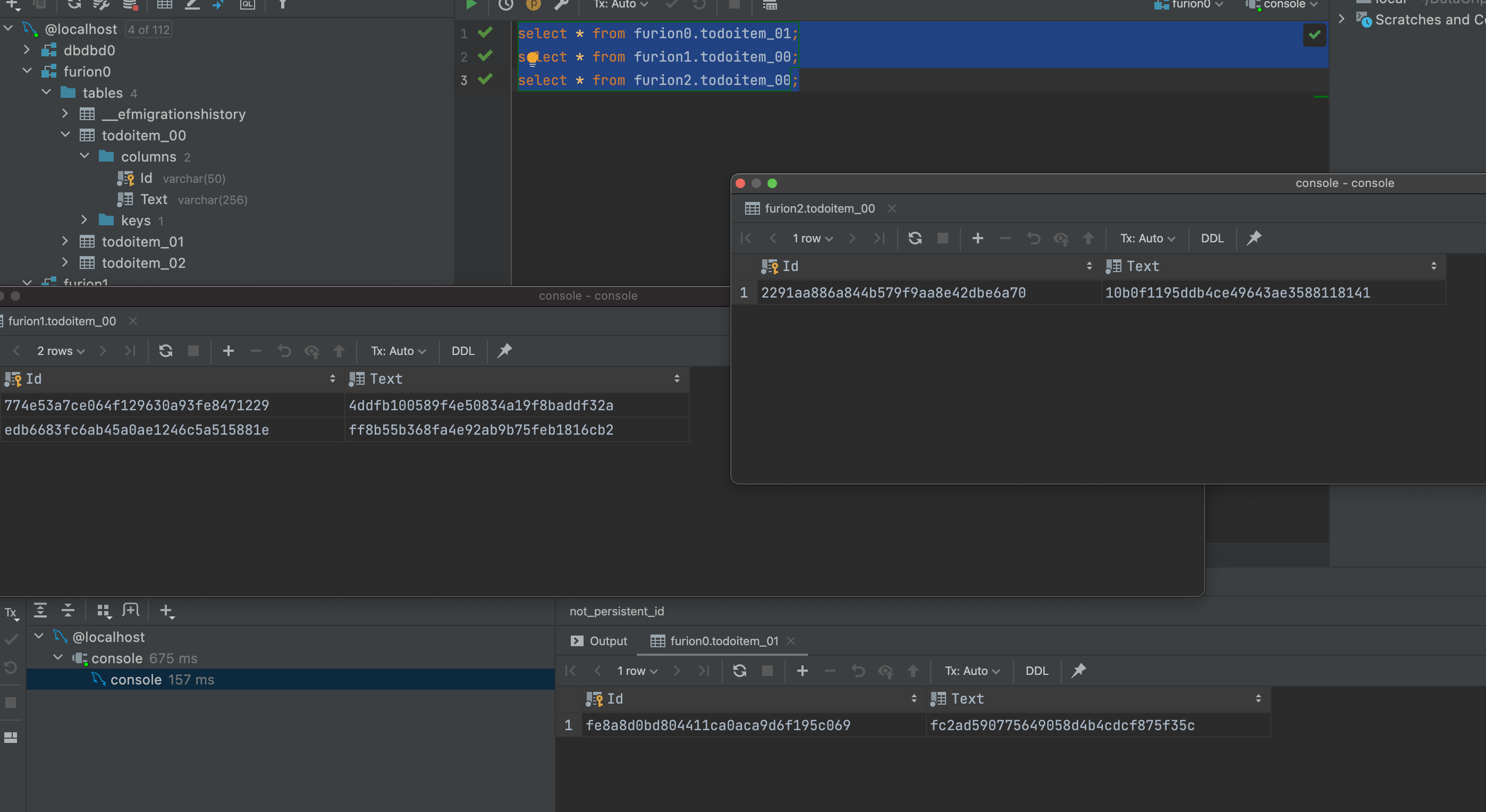
.Net下極限生產力之efcore分錶分庫全自動化遷移CodeFirst

Practical example of propeller easydl: automatic scratch recognition of industrial parts
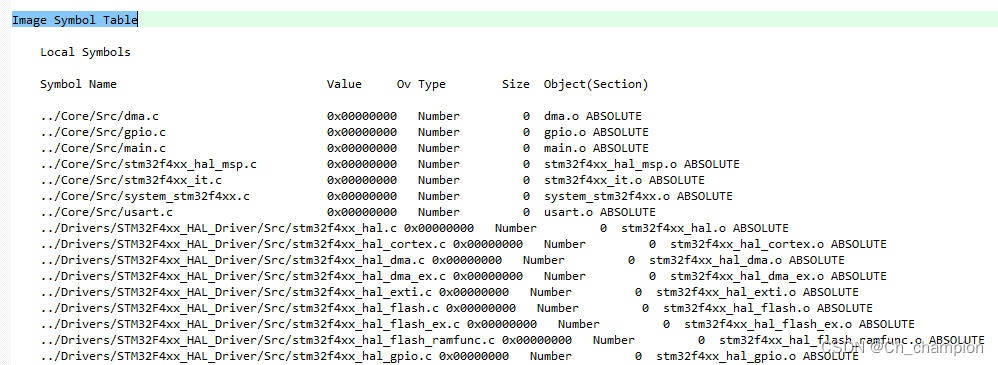
通过Keil如何查看MCU的RAM与ROM使用情况

Per capita Swiss number series, Swiss number 4 generation JS reverse analysis

飞桨EasyDL实操范例:工业零件划痕自动识别
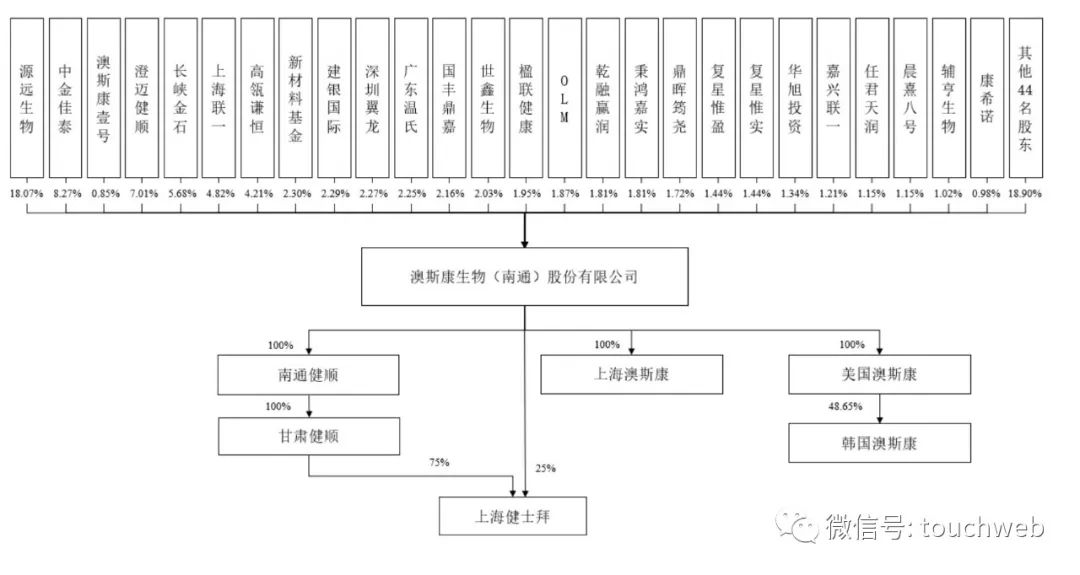
高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作

为租客提供帮助
随机推荐
详细介绍六种开源协议(程序员须知)
JS determines whether an object is empty
【无标题】
DrawerLayout禁止侧滑显示
Query whether a field has an index with MySQL
Grep of three swordsmen in text processing
Vscode编辑器ESP32头文件波浪线不跳转彻底解决
How to reset Google browser? Google Chrome restore default settings?
error LNK2019: 无法解析的外部符号
Why can basic data types call methods in JS
为租客提供帮助
JS中为什么基础数据类型可以调用方法
Cinnamon 任务栏网速
高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作
ESP32构解工程添加组件
Practical example of propeller easydl: automatic scratch recognition of industrial parts
How did Guotai Junan Securities open an account? Is it safe to open an account?
[learning notes] segment tree selection
Realbasicvsr test pictures and videos
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf