当前位置:网站首页>JSON data flattening pd json_ normalize
JSON data flattening pd json_ normalize
2022-07-07 07:57:00 【Ouchen Eli】
pandas There's a built-in feature called .json_normalize.
pandas It is mentioned in the document of : Will be semi-structured JSON The data is normalized to a flat table .
def _json_normalize(
data: Union[Dict, List[Dict]],
record_path: Optional[Union[str, List]] = None,
meta: Optional[Union[str, List[Union[str, List[str]]]]] = None,
meta_prefix: Optional[str] = None,
record_prefix: Optional[str] = None,
errors: str = "raise",
sep: str = ".",
max_level: Optional[int] = None,
) -> "DataFrame":
"""
Normalize semi-structured JSON data into a flat table.
Parameters
----------
data : dict or list of dicts
Unserialized JSON objects.
record_path : str or list of str, default None
Path in each object to list of records. If not passed, data will be
assumed to be an array of records.
meta : list of paths (str or list of str), default None
Fields to use as metadata for each record in resulting table.
meta_prefix : str, default None
If True, prefix records with dotted (?) path, e.g. foo.bar.field if
meta is ['foo', 'bar'].
record_prefix : str, default None
If True, prefix records with dotted (?) path, e.g. foo.bar.field if
path to records is ['foo', 'bar'].
errors : {'raise', 'ignore'}, default 'raise'
Configures error handling.
* 'ignore' : will ignore KeyError if keys listed in meta are not
always present.
* 'raise' : will raise KeyError if keys listed in meta are not
always present.
sep : str, default '.'
Nested records will generate names separated by sep.
e.g., for sep='.', {'foo': {'bar': 0}} -> foo.bar.
max_level : int, default None
Max number of levels(depth of dict) to normalize.
if None, normalizes all levels.
.. versionadded:: 0.25.0
Returns
-------
frame : DataFrame
Normalize semi-structured JSON data into a flat table.
Examples
--------
>>> data = [{'id': 1, 'name': {'first': 'Coleen', 'last': 'Volk'}},
... {'name': {'given': 'Mose', 'family': 'Regner'}},
... {'id': 2, 'name': 'Faye Raker'}]
>>> pd.json_normalize(data)
id name.first name.last name.given name.family name
0 1.0 Coleen Volk NaN NaN NaN
1 NaN NaN NaN Mose Regner NaN
2 2.0 NaN NaN NaN NaN Faye Raker
>>> data = [{'id': 1,
... 'name': "Cole Volk",
... 'fitness': {'height': 130, 'weight': 60}},
... {'name': "Mose Reg",
... 'fitness': {'height': 130, 'weight': 60}},
... {'id': 2, 'name': 'Faye Raker',
... 'fitness': {'height': 130, 'weight': 60}}]
>>> pd.json_normalize(data, max_level=0)
id name fitness
0 1.0 Cole Volk {'height': 130, 'weight': 60}
1 NaN Mose Reg {'height': 130, 'weight': 60}
2 2.0 Faye Raker {'height': 130, 'weight': 60}
Normalizes nested data up to level 1.
>>> data = [{'id': 1,
... 'name': "Cole Volk",
... 'fitness': {'height': 130, 'weight': 60}},
... {'name': "Mose Reg",
... 'fitness': {'height': 130, 'weight': 60}},
... {'id': 2, 'name': 'Faye Raker',
... 'fitness': {'height': 130, 'weight': 60}}]
>>> pd.json_normalize(data, max_level=1)
id name fitness.height fitness.weight
0 1.0 Cole Volk 130 60
1 NaN Mose Reg 130 60
2 2.0 Faye Raker 130 60
>>> data = [{'state': 'Florida',
... 'shortname': 'FL',
... 'info': {'governor': 'Rick Scott'},
... 'counties': [{'name': 'Dade', 'population': 12345},
... {'name': 'Broward', 'population': 40000},
... {'name': 'Palm Beach', 'population': 60000}]},
... {'state': 'Ohio',
... 'shortname': 'OH',
... 'info': {'governor': 'John Kasich'},
... 'counties': [{'name': 'Summit', 'population': 1234},
... {'name': 'Cuyahoga', 'population': 1337}]}]
>>> result = pd.json_normalize(data, 'counties', ['state', 'shortname',
... ['info', 'governor']])
>>> result
name population state shortname info.governor
0 Dade 12345 Florida FL Rick Scott
1 Broward 40000 Florida FL Rick Scott
2 Palm Beach 60000 Florida FL Rick Scott
3 Summit 1234 Ohio OH John Kasich
4 Cuyahoga 1337 Ohio OH John Kasich
>>> data = {'A': [1, 2]}
>>> pd.json_normalize(data, 'A', record_prefix='Prefix.')
Prefix.0
0 1
1 2
Returns normalized data with columns prefixed with the given string.
"""
def _pull_field(
js: Dict[str, Any], spec: Union[List, str]
) -> Union[Scalar, Iterable]:
"""Internal function to pull field"""
result = js
if isinstance(spec, list):
for field in spec:
result = result[field]
else:
result = result[spec]
return result
def _pull_records(js: Dict[str, Any], spec: Union[List, str]) -> List:
"""
Internal function to pull field for records, and similar to
_pull_field, but require to return list. And will raise error
if has non iterable value.
"""
result = _pull_field(js, spec)
# GH 31507 GH 30145, GH 26284 if result is not list, raise TypeError if not
# null, otherwise return an empty list
if not isinstance(result, list):
if pd.isnull(result):
result = []
else:
raise TypeError(
f"{js} has non list value {result} for path {spec}. "
"Must be list or null."
)
return result
if isinstance(data, list) and not data:
return DataFrame()
# A bit of a hackjob
if isinstance(data, dict):
data = [data]
if record_path is None:
if any([isinstance(x, dict) for x in y.values()] for y in data):
# naive normalization, this is idempotent for flat records
# and potentially will inflate the data considerably for
# deeply nested structures:
# {VeryLong: { b: 1,c:2}} -> {VeryLong.b:1 ,VeryLong.c:@}
#
# TODO: handle record value which are lists, at least error
# reasonably
data = nested_to_record(data, sep=sep, max_level=max_level)
return DataFrame(data)
elif not isinstance(record_path, list):
record_path = [record_path]
if meta is None:
meta = []
elif not isinstance(meta, list):
meta = [meta]
_meta = [m if isinstance(m, list) else [m] for m in meta]
# Disastrously inefficient for now
records: List = []
lengths = []
meta_vals: DefaultDict = defaultdict(list)
meta_keys = [sep.join(val) for val in _meta]
def _recursive_extract(data, path, seen_meta, level=0):
if isinstance(data, dict):
data = [data]
if len(path) > 1:
for obj in data:
for val, key in zip(_meta, meta_keys):
if level + 1 == len(val):
seen_meta[key] = _pull_field(obj, val[-1])
_recursive_extract(obj[path[0]], path[1:], seen_meta, level=level + 1)
else:
for obj in data:
recs = _pull_records(obj, path[0])
recs = [
nested_to_record(r, sep=sep, max_level=max_level)
if isinstance(r, dict)
else r
for r in recs
]
# For repeating the metadata later
lengths.append(len(recs))
for val, key in zip(_meta, meta_keys):
if level + 1 > len(val):
meta_val = seen_meta[key]
else:
try:
meta_val = _pull_field(obj, val[level:])
except KeyError as e:
if errors == "ignore":
meta_val = np.nan
else:
raise KeyError(
"Try running with errors='ignore' as key "
f"{e} is not always present"
) from e
meta_vals[key].append(meta_val)
records.extend(recs)
_recursive_extract(data, record_path, {}, level=0)
result = DataFrame(records)
if record_prefix is not None:
result = result.rename(columns=lambda x: f"{record_prefix}{x}")
# Data types, a problem
for k, v in meta_vals.items():
if meta_prefix is not None:
k = meta_prefix + k
if k in result:
raise ValueError(
f"Conflicting metadata name {k}, need distinguishing prefix "
)
result[k] = np.array(v, dtype=object).repeat(lengths)
return result
json_normalize() Function parameters
| Parameter name | explain |
|---|---|
| data | Unresolved Json object , It can also be Json List objects |
| record_path | List or string , If Json Nested lists in objects are not set here , After parsing, the whole list will be directly stored in one column for display |
| meta | Json Object key , Nested tags can also be used when there are multiple layers of data |
| meta_prefix | The prefix of the key |
| record_prefix | Prefix of nested list |
| errors | error message , Can be set to ignore, Said if key If not, ignore the error , It can also be set to raise, Said if key If it does not exist, an error will be reported to prompt . The default value is raise |
| sep | Multi-storey key Separator between , The default value is .( One point ) |
| max_level | analysis Json The maximum number of layers of the object , It is suitable for multi-layer nested Json object |
Before the code demonstration, import the corresponding dependent Libraries , Not installed pandas Please install the library by yourself ( This code is in Jupyter Notebook Running in the environment ).
from pandas import json_normalize
import pandas as pd
1. Analyze the most basic Json
a. Parsing general Json object
a_dict = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2
}
pd.json_normalize(a_dict)
The output is :

b. Analyze a Json The object list
json_list = [
{'class': 'Year 1', 'student number': 20, 'room': 'Yellow'},
{'class': 'Year 2', 'student number': 25, 'room': 'Blue'}
]
pd.json_normalize(json_list)
The output is :

2. Parse a with multiple layers of data Json
a. Parse a with multiple layers of data Json object
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj)
The output is :
Multi-storey key Use points to separate , Shows all the data , This has been resolved 3 layer , The above writing is similar to pd.json_normalize(json_obj, max_level=3) Equivalent .
If you set max_level=1, The output result is as shown in the figure below ,contacts Part of the data collection is integrated into a column 
If you set max_level=2, The output result is as shown in the figure below ,contacts Under the email Part of the data collection is integrated into a column 
b. Parse a with multiple layers of data Json The object list
json_list = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask'
}
}
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
'math': 'Alan Turing',
'physics': 'Albert Einstein'
}
}
}
]
pd.json_normalize(json_list)
The output is :

If you separate max_level Set to 2 and 3, What should the output results be ? Please try it yourself ~
3. Resolve a with nested lists Json
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj)
In this case students The value corresponding to the key is a list , Use [] Cover up . The above method is directly used for analysis , The results are as follows :

students Part of the data was not successfully parsed , It can be record_path Set the value , The call mode is pd.json_normalize(json_obj, record_path='students'), In this calling mode , The results obtained only include name Part of the data .

To add information for other fields , It needs to be meta parameter assignment , For example, under the following call mode , The result is as follows :
pd.json_normalize(json_obj, record_path='students', meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']])

4. When Key How to ignore the system error when it does not exist
data = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask',
}
},
'students': [
{ 'name': 'Tom', 'sex': 'M' },
{ 'name': 'James', 'sex': 'M' },
]
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
# no math teacher
'physics': 'Albert Einstein'
}
},
'students': [
{ 'name': 'Tony', 'sex': 'M' },
{ 'name': 'Jacqueline', 'sex': 'F' },
]
},
]
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']]
)
stay class be equal to Year 2 Of Json In the object ,teachers Under the math The key doesn't exist , Running the above code directly will report the following error , Tips math Keys don't always exist , And the corresponding suggestions are given :Try running with errors='ignore'.

add to errors After the condition , The results of re running are shown in the figure below , No, math The part of the key uses NaN Filled .
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']],
errors='ignore'
)

5. Use sep Parameters are nested Json Of Key Set separator
stay 2.a Case study , It can be noted that the output result has multiple layers key The header of the data column is . To multilayer key Separating , It can be for sep Assign a value to change the separator .
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj, sep='->')
The output is :

6. Prefix nested list data and metadata
stay 3 In the output of example , Each column name has no prefix , for example name I don't know if this column is the data obtained by metadata parsing , Or through student Data from nested lists , Therefore record_prefix and meta_prefix The parameters are assigned respectively , You can add the corresponding prefix to the output result .
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj, record_path='students',
meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
In this case , Add... To nested list data students-> Prefix , Add... For metadata meta-> Prefix , Will be nested key Change the separator between to ->, The output is :

7. adopt URL obtain Json And analyze the data
adopt URL Getting data requires requests library , Please install the corresponding library by yourself .
import requests
from pandas import json_normalize
# Through the weather API, Get Shenzhen near 7 Days of the weather
url = 'https://tianqiapi.com/free/week'
# Pass in url, And set the corresponding params
r = requests.get(url, params={"appid":"59257444", "appsecret":"uULlTGV9 ", 'city':' Shenzhen '})
# Convert the obtained value to json object
result = r.json()
df = json_normalize(result, meta=['city', 'cityid', 'update_time'], record_path=['data'])
df
result The results are as follows , among data For a nested list :
{'cityid': '101280601',
'city': ' Shenzhen ',
'update_time': '2021-08-09 06:39:49',
'data': [{'date': '2021-08-09',
'wea': ' Moderate rain to thunderstorm ',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '26',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-10',
'wea': ' thunder shower ',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-11',
'wea': ' thunder shower ',
'wea_img': 'yu',
'tem_day': '31',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-12',
'wea': ' cloudy ',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-13',
'wea': ' cloudy ',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-14',
'wea': ' cloudy ',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '},
{'date': '2021-08-15',
'wea': ' cloudy ',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': ' No sustained wind direction ',
'win_speed': '<3 level '}]}
The output result after parsing is :

8. To explore the : Resolution with Multiple nested lists Of Json
When one Json When there is more than one nested list in an object or object list ,record_path Cannot include all nested lists , Because it can only receive one key value . here , We need to start with... Based on multiple nested lists key take Json It's resolved into multiple DataFrame, And I'll put these DataFrame Spliced according to the actual correlation conditions , And remove duplicates .
json_obj = {
'school': 'ABC primary school',
'location': 'shenzhen',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
# add to university Nested list , add students, The JSON There are... In the object 2 A nested list
'university': [
{'university_name': 'HongKong university shenzhen'},
{'university_name': 'zhongshan university shenzhen'},
{'university_name': 'shenzhen university'}
],
}
# Try to record_path Write the names of two nested lists in , namely record_path = ['students', 'university], The result is of no avail
# So I decided to analyze it twice , Separately record_path Set to university and students, In the end 2 Results combined
df1 = pd.json_normalize(json_obj, record_path=['university'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='university->',
meta_prefix='meta->',
sep='->')
df2 = pd.json_normalize(json_obj, record_path=['students'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
# According to index Associate and remove duplicate Columns
df1.merge(df2, how='left', left_index=True, right_index=True, suffixes=['->', '->']).T.drop_duplicates().T
The output is :

The part marked in the red box on the way is Json Object .
summary
json_normalize() Method is extremely powerful , It covers almost all parsing JSON Scene , When it comes to more complex scenes , Can give the existing functions for divergent Integration , for example 8. To explore the The same thing happened in .
With this powerful Json Parsing library , I'll never be afraid to encounter complex Json Data. !
Reference resources :
边栏推荐
猜你喜欢
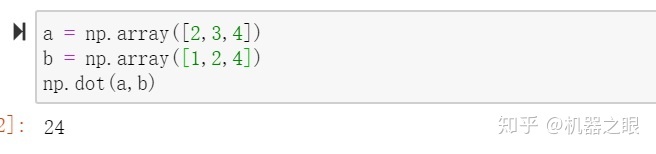
Use and analysis of dot function in numpy
Resource create package method
知识点滴 - 关于苹果认证MFI

2022 recurrent training question bank and answers of refrigeration and air conditioning equipment operation

Few shot Learning & meta learning: small sample learning principle and Siamese network structure (I)
![[Stanford Jiwang cs144 project] lab3: tcpsender](/img/82/5f99296764937e7d119b8ab22828fd.png)
[Stanford Jiwang cs144 project] lab3: tcpsender
![[SUCTF 2019]Game](/img/9c/362117a4bf3a1435ececa288112dfc.png)
[SUCTF 2019]Game
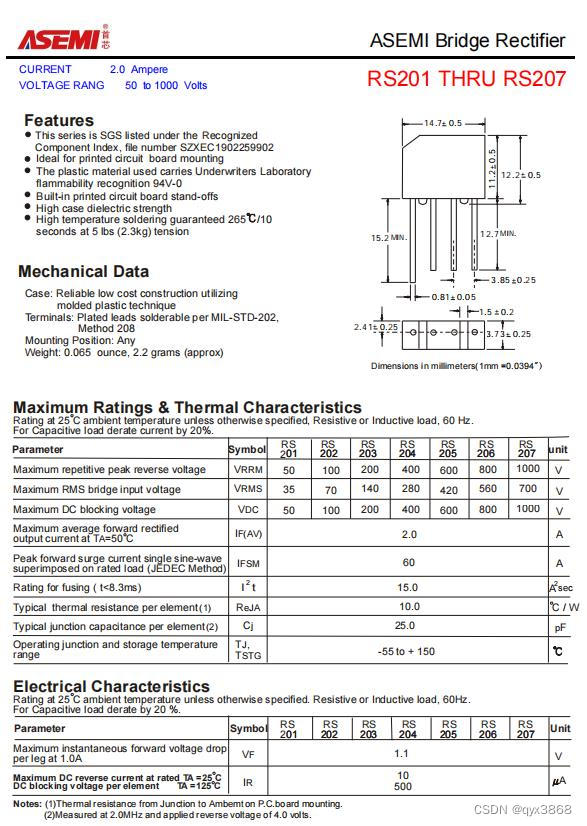
Asemi rectifier bridge rs210 parameters, rs210 specifications, rs210 package

Ansible
![[Stanford Jiwang cs144 project] lab4: tcpconnection](/img/fd/704d19287a12290f779cfc223c71c8.png)
[Stanford Jiwang cs144 project] lab4: tcpconnection
随机推荐
《动手学深度学习》(四) -- 卷积神经网络 CNN
Button wizard collection learning - mineral medicine collection and running map
dash plotly
Gslx680 touch screen driver source code analysis (gslx680. C)
Figure out the working principle of gpt3
[mathematical notes] radian
buuctf misc USB
Force buckle 145 Binary Tree Postorder Traversal
Six methods of flattening arrays with JS
Is the test cycle compressed? Teach you 9 ways to deal with it
[UTCTF2020]file header
C language communication travel card background system
Qt学习26 布局管理综合实例
MySQL multi column index (composite index) features and usage scenarios
[SUCTF 2019]Game
Tianqing sends instructions to bypass the secondary verification
Idea add class annotation template and method template
自定义类加载器加载网络Class
Leanote private cloud note building
[UVM practice] Chapter 2: a simple UVM verification platform (2) only driver verification platform