当前位置:网站首页>ES底层原理之倒排索引
ES底层原理之倒排索引
2022-07-07 10:22:00 【話吥哆先森丶】
目录
一、ElasticSearch架构原理
1、ElasticSearch集群的节点类型
Elasticsearch的一个实例是一个节点,一组节点形成一个集群。Elasticsearch集群中的节点可以通过三种不同的方式进行配置:
(1)Master节点
Master节点控制Elasticsearch集群,并负责在集群范围内创建/删除索引,跟踪哪些节点是集群的一部分,并将分片分配给这些节点。
(2)Data节点
数据节点用来保存数据和倒排索引。
(3)Client节点
如果将node.master和node.data设置为false,则将节点配置为客户端节点,并充当负载平衡器,将传入的请求路由到集群中的不同节点。
若你连接的是作为客户端的节点,该节点称为协调节点(coordinating node)。协调节点将客户机请求路由到集群中对应分片所在的节点。对于读取请求,协调节点每次选择不同的分片来提供请求以平衡负载。
(4)存储模型
使用称为倒排索引的数据结构,用于提供低延迟搜索结果
注意:索引数据的操作只会发生在主分片(primary shard)上,而不会发生在分片副本(Replica) 上。如果索引数据的请求发送到的节点没有合适的分片或者分片是副本,那么请求会被转发到含有主分片的节点。
2、不可变性
写入磁盘的倒排索引是不可变的,它有如下好处:
①不需要锁,提升并发能力,避免锁的问题
②数据不变,一直保存在os cache中,只要cache内存足够
③filter cache一直驻留在内存,因为数据不变
④可以压缩,节省cpu和io开销
坏处:
①每次都要重新构建整个索引
3、写和创建
1)通过索引中的主分片数量进行取模运算,以确定文档应被索引到哪个分片。 shard = hash(document_id) % (num_of_primary_shards)
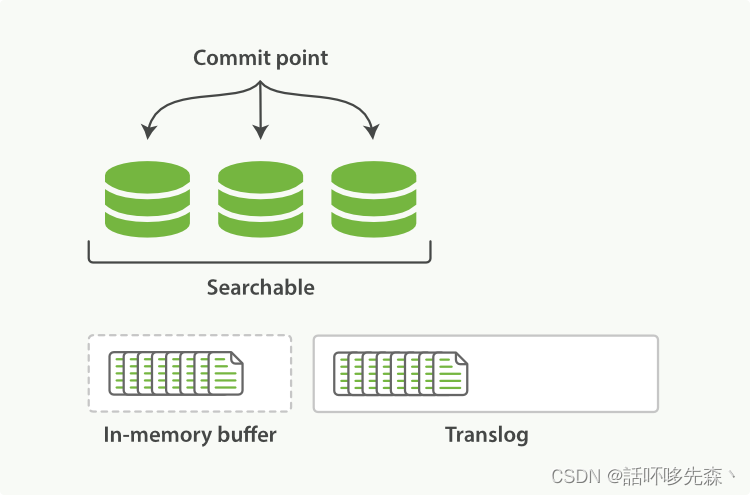
2)当节点接收到来自协调节点的请求时,请求被写入到translog,并将该文档添加到内存缓冲区。
如果请求在主分片上成功,则请求将并行发送到副本分片。只有在所有主分片和副本分片上的translog被fsync’ed后,客户端才会收到该请求成功的确认。
- 内存缓冲区以固定的间隔刷新(默认为1秒),并将内容写入文件系统缓存中的新段。此分段的内容更尚未被fsync’ed(未被写入文件系统),分段是打开的,内容可用于搜索。
- translog被清空,并且文件系统缓存每隔30分钟进行一次fsync,或者当translog变得太大时进行一次fsync。这个过程在Elasticsearch中称为flush。在刷新过程中,内存缓冲区被清除,内容被写入新的文件分段(segment)。当文件分段被fsync’ed并刷新到磁盘,会创建一个新的提交点(其实就是会更新文件偏移量,文件系统会自动做这个操作)。旧的translog被删除,一个新的开始。
4、删除和更新
删除:每一个提交点包括一个.del文件,包含了段上已经被删除的文档当一个文档被删除,它是实际上只是在.del文件中被标记删除,亦然可以匹配查询,但最终返回之前会被从结果中删除。
更新:旧版本的文档被标记为删除,新版本的文档在新的段中索引
5、利用磁盘缓存实时检索
1)新收到的数据写入新的索引文件中,生成倒排索引叫做一个端--segment
2)使用一个commit文件记录索引内的所有segment
3)新数据进入内存buffer中
4)内存buffer生成一个新的segment,刷到文件系统缓存中,ES即可检测到新的segment
5)文件系统缓存真正同步到磁盘中,commit文件更新
6、translog提供磁盘控制
防止丢失(主机错误、磁盘故障)。当ES把数据写入buffer中,还记录了translog日志
二、倒排索引
1、单词----文档矩阵
文档1 | 文档2 | 文档3 | 文档4 | 文档5 | 文档6 | |
单词1 |
|
| ||||
单词2 |
|
| ||||
单词3 |
|
| ||||
单词4 |
|
| ||||
单词5 |
| |||||
单词6 |
|
2、倒排索引
1)、单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
2)、倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。

3、倒排索引简单实例
假设文档集合包含四个文档,对这个文档集合建立倒排索引。
文档编号 | 文档内容 |
1 | 谷歌地图之父跳槽Facebook |
2 | 谷歌地图之父加盟Facebook |
3 | 谷歌地图创始人拉斯离开谷歌加盟Facebook |
4 | 谷歌地图之父拉斯加盟社交网站Facebook |
1)、取得关键词—分词处理
没有实际意义的:“的”,“是”,“in”,“too”;
标点符号、空格;
统一大小写:“a”,“A”。还原单词 lives-->live
2)、建立索引列表
文章位置、出现的频率、出现的位置
3)、应用原因
时间复杂度--1秒
单词ID | 单词 | 文档频率 | 倒排列表(DocID:TF:<Position>) |
1 | 谷歌 | 4 | (1:1:<1>),(2:1:<1>),(3:2:<1><6>),(4:1:<1>) |
2 | 地图 | 4 | (1:1:<2>),(2:1:<2>),(3:1:<2>),(4:1:<2>) |
3 | 之父 | 3 | (1:1:<3>),(2:1:<3>),(4:1:<3>) |
4 | 跳槽 | 1 | (1:1:<4>) |
5 | 4 | (1:1:<5>),(2:1:<5>),(3:1:<8>),(4:1:<8>) | |
6 | 加盟 | 2 | (2:1:<4>),(4:1:<5>) |
7 | 创始人 | 1 | (3:1:<3>) |
8 | 拉斯 | 2 | (3:1:<4>),(4:1:<4>) |
9 | 离开 | 1 | (3;1:<5>) |
10 | 社交 | 1 | (4:1:<6>) |
11 | 网站 | 1 | (4:1:<7>) |
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息、文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
边栏推荐
- 消息队列消息丢失和消息重复发送的处理策略
- Fleet tutorial 19 introduction to verticaldivider separator component Foundation (tutorial includes source code)
- Superscalar processor design yaoyongbin Chapter 9 instruction execution excerpt
- Some opinions and code implementation of Siou loss: more powerful learning for bounding box regression zhora gevorgyan
- Summed up 200 Classic machine learning interview questions (with reference answers)
- Sonar:Cognitive Complexity认知复杂度
- [texture feature extraction] LBP image texture feature extraction based on MATLAB local binary mode [including Matlab source code 1931]
- Unity 贴图自动匹配材质工具 贴图自动添加到材质球工具 材质球匹配贴图工具 Substance Painter制作的贴图自动匹配材质球工具
- 防红域名生成的3种方法介绍
- Fleet tutorial 15 introduction to GridView Basics (tutorial includes source code)
猜你喜欢

Nuclear boat (I): when "male mothers" come into reality, can the biotechnology revolution liberate women?
Superscalar processor design yaoyongbin Chapter 8 instruction emission excerpt
![[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]](/img/90/ef2400754cbf3771535196f6822992.jpg)
[filter tracking] comparison between EKF and UKF based on MATLAB extended Kalman filter [including Matlab source code 1933]
5V串口接3.3V单片机串口怎么搞?
zero-shot, one-shot和few-shot
千人规模互联网公司研发效能成功之路
SwiftUI 教程之如何在 2 秒内实现自动滚动功能
@What happens if bean and @component are used on the same class?

Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
About how to install mysql8.0 on the cloud server (Tencent cloud here) and enable local remote connection
随机推荐
【滤波跟踪】基于matlab扩展卡尔曼滤波EKF和无迹卡尔曼滤波UKF比较【含Matlab源码 1933期】
112.网络安全渗透测试—[权限提升篇10]—[Windows 2003 LPK.DDL劫持提权&msf本地提权]
Use references
免备案服务器会影响网站排名和权重吗?
千人规模互联网公司研发效能成功之路
大佬们有没有人遇到过 flink oracle cdc,读取一个没有更新操作的表,隔十几秒就重复读取
wallys/Qualcomm IPQ8072A networking SBC supports dual 10GbE, WiFi 6
Swiftui swift internal skill how to perform automatic trigonometric function calculation in swift
Steps of redis installation and self startup configuration under CentOS system
What is high cohesion and low coupling?
消息队列消息丢失和消息重复发送的处理策略
[shortest circuit] acwing1128 Messenger: Floyd shortest circuit
110.网络安全渗透测试—[权限提升篇8]—[Windows SqlServer xp_cmdshell存储过程提权]
How to connect 5V serial port to 3.3V MCU serial port?
数据库系统原理与应用教程(011)—— 关系数据库
Problem: the string and characters are typed successively, and the results conflict
Various uses of vim are very practical. I learned and summarized them in my work
即刻报名|飞桨黑客马拉松第三期盛夏登场,等你挑战
Cmu15445 (fall 2019) project 2 - hash table details
College entrance examination composition, high-frequency mention of science and Technology