当前位置:网站首页>MNIST手写数字识别 —— 从二分类到十分类
MNIST手写数字识别 —— 从二分类到十分类
2022-08-04 05:30:00 【学习历险记】
将一个二分类模型改成多分类模型的方法
本案例中使用深度学习框架MindSpore,利用其友好的封装模块,模型结构定义、损失函数定义、梯度下降实现等过程,只需简单地函数调用,就能实现模型训练,极大地提高了模型开发的效率。
1.加载数据集
加载完整的、十个类别的数据集
import os
import numpy as np
import moxing as mox
import mindspore.dataset as ds
datasets_dir = '../datasets'
if not os.path.exists(datasets_dir):
os.makedirs(datasets_dir)
if not os.path.exists(os.path.join(datasets_dir, 'MNIST_Data.zip')):
mox.file.copy('obs://modelarts-labs-bj4-v2/course/hwc_edu/python_module_framework/datasets/mindspore_data/MNIST_Data.zip',
os.path.join(datasets_dir, 'MNIST_Data.zip'))
os.system('cd %s; unzip MNIST_Data.zip' % (datasets_dir))
# 读取完整训练样本和测试样本
mnist_ds_train = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/train"))
mnist_ds_test = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/test"))
train_len = mnist_ds_train.get_dataset_size()
test_len = mnist_ds_test.get_dataset_size()
print('训练集规模:', train_len, ',测试集规模:', test_len)训练集规模:60000,测试集规模:10000
查看10个样本
from PIL import Image
items_train = mnist_ds_train.create_dict_iterator(output_numpy=True)
train_data = np.array([i for i in items_train])
images_train = np.array([i["image"] for i in train_data])
labels_train = np.array([i["label"] for i in train_data])
batch_size = 10 # 查看10个样本
batch_label = [lab for lab in labels_train[:10]]
print(batch_label)
batch_img = images_train[0].reshape(28, 28)
for i in range(1, batch_size):
batch_img = np.hstack((batch_img, images_train[i].reshape(28, 28))) # 将一批图片水平拼接起来,方便下一步进行显示
Image.fromarray(batch_img)[0, 2, 2, 7, 8, 4, 9, 1, 8, 8]
2.处理数据集
数据集对于训练非常重要,好的数据集可以有效提高训练精度和效率,在使用数据集前,通常会对数据集进行一些处理。
进行数据增强操作
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
num_parallel_workers = 1
resize_height, resize_width = 28, 28
# according to the parameters, generate the corresponding data enhancement method
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # 对图像数据像素进行缩放
type_cast_op = C.TypeCast(mstype.int32) # 将数据类型转化为int32。
hwc2chw_op = CV.HWC2CHW() # 对图像数据张量进行变换,张量形式由高x宽x通道(HWC)变为通道x高x宽(CHW),方便进行数据训练。
# using map to apply operations to a dataset
mnist_ds_train = mnist_ds_train.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds_train = mnist_ds_train.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds_train = mnist_ds_train.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers)
buffer_size = 10000
mnist_ds_train = mnist_ds_train.shuffle(buffer_size=buffer_size) # 打乱训练集的顺序进行数据归一化
对图像数据进行标准化、归一化操作,使得每个像素的数值大小在(0,1)范围中,可以提升训练效率。
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
rescale_op = CV.Rescale(rescale, shift)
mnist_ds_train = mnist_ds_train.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
mnist_ds_train = mnist_ds_train.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds_train = mnist_ds_train.batch(60000, drop_remainder=True) # 对数据集进行分批,此处加载完整的训练集3. 封装成函数
到此,我们就完成了训练数据的准备工作,可以将以上操作封装成load_data_all函数和process_dataset函数,以便后面再次用到。
定义数据处理操作
定义一个函数process_dataset来进行数据增强和处理操作:
定义进行数据增强和处理所需要的一些参数。
根据参数,生成对应的数据增强操作。
使用map映射函数,将数据操作应用到数据集。
对生成的数据集进行处理。
%%writefile ../datasets/MNIST_Data/process_dataset.py
def process_dataset(mnist_ds, batch_size=32, resize= 28, repeat_size=1,
num_parallel_workers=1):
"""
process_dataset for train or test
Args:
mnist_ds (str): MnistData path
batch_size (int): The number of data records in each group
resize (int): Scale image data pixels
repeat_size (int): The number of replicated data records
num_parallel_workers (int): The number of parallel workers
"""
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
# define some parameters needed for data enhancement and rough justification
resize_height, resize_width = resize, resize
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# according to the parameters, generate the corresponding data enhancement method
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
c_trans = [resize_op, rescale_op, rescale_nml_op, hwc2chw_op]
# using map to apply operations to a dataset
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=c_trans, input_columns="image", num_parallel_workers=num_parallel_workers)
# process the generated dataset
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size)
return mnist_ds定义数据加载函数
%%writefile ../datasets/MNIST_Data/load_data_all.py
def load_data_all(datasets_dir):
import os
if not os.path.exists(datasets_dir):
os.makedirs(datasets_dir)
import moxing as mox
if not os.path.exists(os.path.join(datasets_dir, 'MNIST_Data.zip')):
mox.file.copy('obs://modelarts-labs-bj4-v2/course/hwc_edu/python_module_framework/datasets/mindspore_data/MNIST_Data.zip',
os.path.join(datasets_dir, 'MNIST_Data.zip'))
os.system('cd %s; unzip MNIST_Data.zip' % (datasets_dir))
# 读取完整训练样本和测试样本
import mindspore.dataset as ds
datasets_dir = '../datasets'
mnist_ds_train = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/train"))
mnist_ds_test = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/test"))
train_len = mnist_ds_train.get_dataset_size()
test_len = mnist_ds_test.get_dataset_size()
print('训练集规模:', train_len, ',测试集规模:', test_len)
return mnist_ds_train, mnist_ds_test, train_len, test_len4.加载处理后的测试集
import os, sys
sys.path.insert(0, os.path.join(os.getcwd(), '../datasets/MNIST_Data'))
from process_dataset import process_dataset
mnist_ds_test = process_dataset(mnist_ds_test, batch_size= 10000)5.定义网络结构和评价函数
import mindspore
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore.common.initializer import Normal
class Network(nn.Cell):
def __init__(self, num_of_weights):
super(Network, self).__init__()
self.fc = nn.Dense(in_channels=num_of_weights, out_channels=10, weight_init=Normal(0.02)) # 定义一个全连接层
self.nonlinearity = nn.Sigmoid()
self.flatten = nn.Flatten()
def construct(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
x = self.flatten(x)
z = self.fc(x)
pred_y = self.nonlinearity(z)
return pred_y
def evaluate(pred_y, true_y):
pred_labels = ops.Argmax(output_type=mindspore.int32)(pred_y)
correct_num = (pred_labels == true_y).asnumpy().sum().item()
return correct_num6.定义交叉熵损失函数和优化器
# 损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 创建网络
network = Network(28*28)
lr = 0.01
momentum = 0.9
# 优化器
net_opt = nn.Momentum(network.trainable_params(), lr, momentum)7.实现训练函数
def train(network, mnist_ds_train, max_epochs= 50):
net = WithLossCell(network, net_loss)
net = TrainOneStepCell(net, net_opt)
network.set_train()
for epoch in range(1, max_epochs + 1):
train_correct_num = 0.0
test_correct_num = 0.0
for inputs_train in mnist_ds_train:
output = net(*inputs_train)
train_x = inputs_train[0]
train_y = inputs_train[1]
pred_y_train = network.construct(train_x) # 前向传播
train_correct_num += evaluate(pred_y_train, train_y)
train_acc = float(train_correct_num) / train_len
for inputs_test in mnist_ds_test:
test_x = inputs_test[0]
test_y = inputs_test[1]
pred_y_test = network.construct(test_x)
test_correct_num += evaluate(pred_y_test, test_y)
test_acc = float(test_correct_num) / test_len
if (epoch == 1) or (epoch % 10 == 0):
print("epoch: {0}/{1}, train_losses: {2:.4f}, tain_acc: {3:.4f}, test_acc: {4:.4f}" \
.format(epoch, max_epochs, output.asnumpy(), train_acc, test_acc, cflush=True))8. 配置运行信息
在正式训练前,通过context.set_context来配置运行需要的信息,譬如运行模式、后端信息、硬件等信息。
from mindspore import context
context.set_context(mode=context.GRAPH_MODE, device_target="CPU") # device_target 可选 CPU/GPU, 当选择GPU时mindspore规格也需要切换到GPU9.开始训练
import time
from mindspore.nn import WithLossCell, TrainOneStepCell
max_epochs = 100
start_time = time.time()
print("*"*10 + "开始训练" + "*"*10)
train(network, mnist_ds_train, max_epochs= max_epochs)
print("*"*10 + "训练完成" + "*"*10)
cost_time = round(time.time() - start_time, 1)
print("训练总耗时: %.1f s" % cost_time)**********开始训练********** epoch: 1/100, train_losses: 2.2832, tain_acc: 0.1698, test_acc: 0.1626 epoch: 10/100, train_losses: 2.0465, tain_acc: 0.6343, test_acc: 0.6017 epoch: 20/100, train_losses: 1.8368, tain_acc: 0.7918, test_acc: 0.7812 epoch: 30/100, train_losses: 1.7602, tain_acc: 0.8138, test_acc: 0.8017 epoch: 40/100, train_losses: 1.7245, tain_acc: 0.8238, test_acc: 0.7972 epoch: 50/100, train_losses: 1.7051, tain_acc: 0.8337, test_acc: 0.8044 epoch: 60/100, train_losses: 1.6922, tain_acc: 0.8403, test_acc: 0.8047 epoch: 70/100, train_losses: 1.6827, tain_acc: 0.8454, test_acc: 0.8033 epoch: 80/100, train_losses: 1.6752, tain_acc: 0.8501, test_acc: 0.8051 epoch: 90/100, train_losses: 1.6689, tain_acc: 0.8536, test_acc: 0.8049 epoch: 100/100, train_losses: 1.6635, tain_acc: 0.8569, test_acc: 0.8037 **********训练完成********** 训练总耗时: 430.7 s
到目前为止,基于手写数字二分类的代码进行少量修改,就快速实现了手写数字识别的十分类。
修改的过程是非常简单的,但从上面的结果可以看到,该模型训练100个epoch,在手写数字识别十分类的任务上仅仅达到了80%的准确率,而在上一节二分类任务上,模型训练50个epoch达到了99%的准确率,说明在感知机这样简单的模型上,手写数字识别十分类要比二分类要难。
边栏推荐
- 软著撰写注意事项
- yolov3中数据读入(一)
- Lee‘s way of Deep Learning 深度学习笔记
- 2020-10-19
- 审稿意见回复
- TensorFlow2 study notes: 8. tf.keras implements linear regression, Income dataset: years of education and income dataset
- TensorFlow2 study notes: 4. The first neural network model, iris classification
- fuser 使用—— YOLOV5内存溢出——kill nvidai-smi 无pid 的 GPU 进程
- Unity ML-agents 参数设置解明
- No matching function for call to ‘RCTBridgeModuleNameForClass‘
猜你喜欢

TensorFlow2学习笔记:7、优化器
Jupyter Notebook installed library;ModuleNotFoundError: No module named 'plotly' solution.

MAE 论文《Masked Autoencoders Are Scalable Vision Learners》
TensorFlow2 study notes: 7. Optimizer
YOLOV5 V6.1 详细训练方法
深度确定性策略梯度(DDPG)
![[Go language entry notes] 13. Structure (struct)](/img/0e/44601d02a1c47726d26f0ae5085cc9.png)
[Go language entry notes] 13. Structure (struct)
安卓连接mysql数据库,使用okhttp
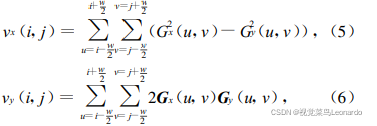
光条中心提取方法总结(一)
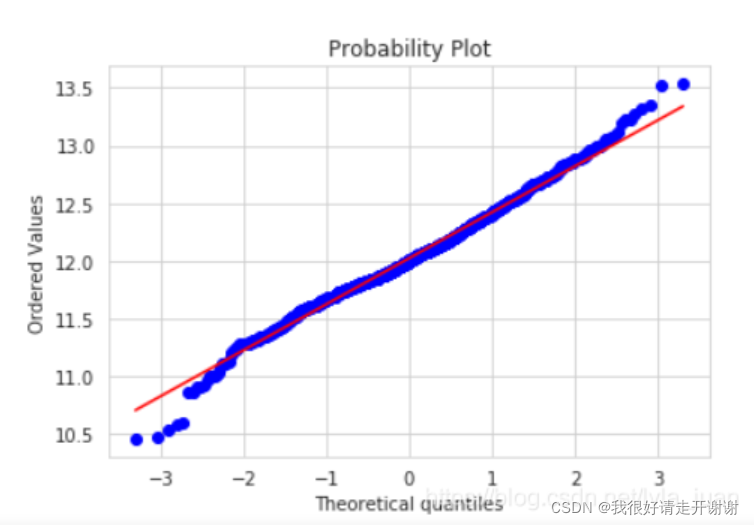
Briefly say Q-Q map; stats.probplot (QQ map)
随机推荐
空洞卷积
详解近端策略优化
动手学深度学习_卷积神经网络CNN
yolov3中数据读入(一)
Thoroughly understand box plot analysis
latex-写论文时一些常用设置
[CV-Learning] Convolutional Neural Network Preliminary Knowledge
【论文阅读】Mining Cross-Image Semantics for Weakly Supervised Semantic Segmentation
Usage of RecyclerView
【CV-Learning】卷积神经网络
Jupyter Notebook installed library;ModuleNotFoundError: No module named 'plotly' solution.
Pytorch问题总结
深度学习,“粮草”先行--浅谈数据集获取之道
PostgreSQL schema (Schema)
DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better 图像去模糊
【论文阅读】Anchor-Free Person Search
读研碎碎念
YOLOV5 V6.1 详细训练方法
图像形变(插值方法)
线性回归简介01---API使用案例