当前位置:网站首页>6. Dropout application
6. Dropout application
2022-07-08 01:01:00 【booze-J】
article
One 、 not used Dropout Under normal circumstances
stay 4. Cross entropy Add some hidden layers to the network model construction of code , And output the loss and accuracy of the training set .
take 4. In cross entropy
# Creating models Input 784 Neurons , Output 10 Neurons
model = Sequential([
# Define output yes 10 Input is 784, Set offset to 1, add to softmax Activation function
Dense(units=10,input_dim=784,bias_initializer='one',activation="softmax"),
])
Add a hidden layer and change it to :
# Creating models Input 784 Neurons , Output 10 Neurons
model = Sequential([
# Define output yes 200 Input is 784, Set offset to 1, add to softmax Activation function The first hidden layer has 200 Neurons
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# The second hidden layer has 100 Neurons
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10,bias_initializer='one',activation="softmax")
])
Code run results :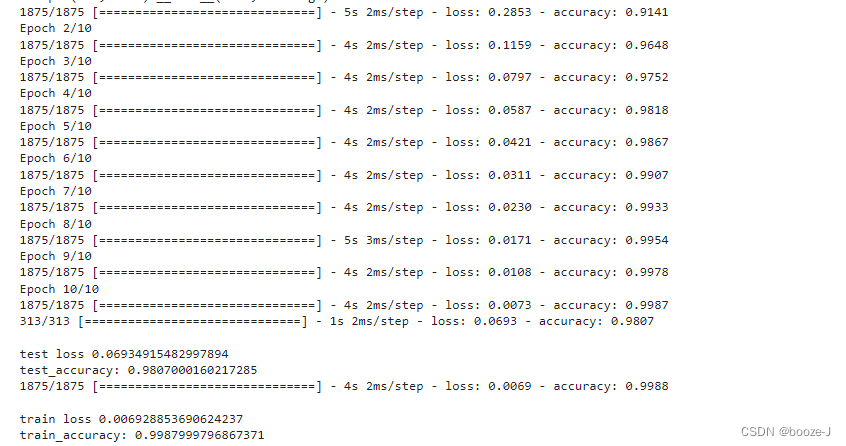
contrast 4. Cross entropy Results of operation , You can find that after adding more hidden layers , The accuracy of model testing is greatly improved , But there is a slight over fitting phenomenon .
Two 、 Use Dropout
Add Dropout:
# Creating models Input 784 Neurons , Output 10 Neurons
model = Sequential([
# Define output yes 200 Input is 784, Set offset to 1, add to softmax Activation function The first hidden layer has 200 Neurons
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# Give Way 40% Of neurons do not work
Dropout(0.4),
# The second hidden layer has 100 Neurons
Dense(units=100,bias_initializer='one',activation="tanh"),
# Give Way 40% Of neurons do not work
Dropout(0.4),
Dense(units=10,bias_initializer='one',activation="softmax")
])
Use Dropout You need to import from keras.layers import Dropout
Running results :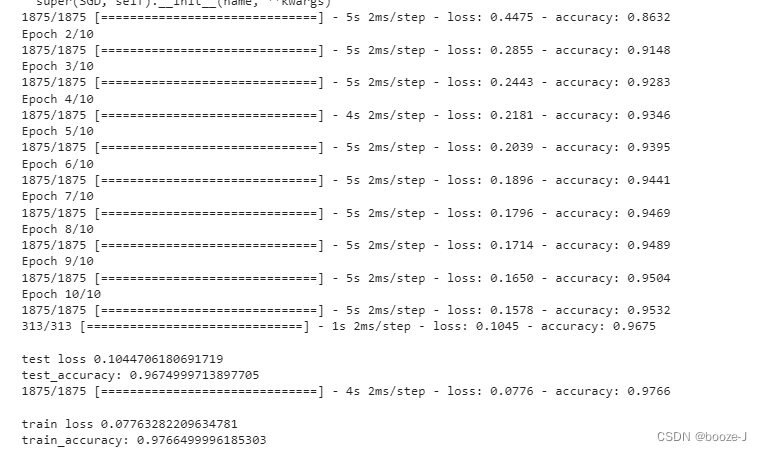
In this example, it is not to say that dropout Will get better results , But in some cases , Use dropout Can get better results .
But use dropout after , The test accuracy and training accuracy are relatively close , Over fitting phenomenon is not very obvious . We can see from the training results , The accuracy of the training process is lower than that of the final model test training set , This is because of the use of dropout after , Each training only uses some neurons , Then after the model training , At the last test , It is tested with all neurons , So the effect will be better .
Complete code
1. not used Dropout Complete code of the situation
The code running platform is jupyter-notebook, Code blocks in the article , According to jupyter-notebook Written in the order of division in , Run article code , Glue directly into jupyter-notebook that will do .
1. Import third-party library
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout
from tensorflow.keras.optimizers import SGD
2. Loading data and data preprocessing
# Load data
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) Not yet one-hot code You need to operate by yourself later
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape() Middle parameter filling -1 Parameter results can be calculated automatically Divide 255.0 To normalize
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# in one hot Format
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3. Training models
# Creating models Input 784 Neurons , Output 10 Neurons
model = Sequential([
# Define output yes 200 Input is 784, Set offset to 1, add to softmax Activation function The first hidden layer has 200 Neurons
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# The second hidden layer has 100 Neurons
Dense(units=100,bias_initializer='one',activation="tanh"),
Dense(units=10,bias_initializer='one',activation="softmax")
])
# Define optimizer
sgd = SGD(lr=0.2)
# Define optimizer ,loss_function, The accuracy of calculation during training
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# Training models
model.fit(x_train,y_train,batch_size=32,epochs=10)
# Evaluation model
# Test set loss And accuracy
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("test_accuracy:",accuracy)
# Training set loss And accuracy
loss,accuracy = model.evaluate(x_train,y_train)
print("\ntrain loss",loss)
print("train_accuracy:",accuracy)
2. Use Dropout Complete code for
The code running platform is jupyter-notebook, Code blocks in the article , According to jupyter-notebook Written in the order of division in , Run article code , Glue directly into jupyter-notebook that will do .
1. Import third-party library
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout
from tensorflow.keras.optimizers import SGD
2. Loading data and data preprocessing
# Load data
(x_train,y_train),(x_test,y_test) = mnist.load_data()
# (60000, 28, 28)
print("x_shape:\n",x_train.shape)
# (60000,) Not yet one-hot code You need to operate by yourself later
print("y_shape:\n",y_train.shape)
# (60000, 28, 28) -> (60000,784) reshape() Middle parameter filling -1 Parameter results can be calculated automatically Divide 255.0 To normalize
x_train = x_train.reshape(x_train.shape[0],-1)/255.0
x_test = x_test.reshape(x_test.shape[0],-1)/255.0
# in one hot Format
y_train = np_utils.to_categorical(y_train,num_classes=10)
y_test = np_utils.to_categorical(y_test,num_classes=10)
3. Training models
# Creating models Input 784 Neurons , Output 10 Neurons
model = Sequential([
# Define output yes 200 Input is 784, Set offset to 1, add to softmax Activation function The first hidden layer has 200 Neurons
Dense(units=200,input_dim=784,bias_initializer='one',activation="tanh"),
# Give Way 40% Of neurons do not work
Dropout(0.4),
# The second hidden layer has 100 Neurons
Dense(units=100,bias_initializer='one',activation="tanh"),
# Give Way 40% Of neurons do not work
Dropout(0.4),
Dense(units=10,bias_initializer='one',activation="softmax")
])
# Define optimizer
sgd = SGD(lr=0.2)
# Define optimizer ,loss_function, The accuracy of calculation during training
model.compile(
optimizer=sgd,
loss="categorical_crossentropy",
metrics=['accuracy']
)
# Training models
model.fit(x_train,y_train,batch_size=32,epochs=10)
# Evaluation model
# Test set loss And accuracy
loss,accuracy = model.evaluate(x_test,y_test)
print("\ntest loss",loss)
print("test_accuracy:",accuracy)
# Training set loss And accuracy
loss,accuracy = model.evaluate(x_train,y_train)
print("\ntrain loss",loss)
print("train_accuracy:",accuracy)
边栏推荐
- What does interface testing test?
- 【深度学习】AI一键换天
- [Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
- Mathematical modeling -- knowledge map
- 133. 克隆图
- QT establish signal slots between different classes and transfer parameters
- 5.过拟合,dropout,正则化
- Experience of autumn recruitment in 22 years
- ABAP ALV LVC template
- 攻防演练中沙盘推演的4个阶段
猜你喜欢
1293_ Implementation analysis of xtask resumeall() interface in FreeRTOS
【深度学习】AI一键换天
基于微信小程序开发的我最在行的小游戏

How does starfish OS enable the value of SFO in the fourth phase of SFO destruction?
letcode43:字符串相乘
Interface test advanced interface script use - apipost (pre / post execution script)
4.交叉熵

13.模型的保存和载入
Application practice | the efficiency of the data warehouse system has been comprehensively improved! Data warehouse construction based on Apache Doris in Tongcheng digital Department
13. Enregistrement et chargement des modèles
随机推荐
接口测试要测试什么?
5.过拟合,dropout,正则化
Hotel
Lecture 1: the entry node of the link in the linked list
STL -- common function replication of string class
Experience of autumn recruitment in 22 years
SDNU_ACM_ICPC_2022_Summer_Practice(1~2)
[Yugong series] go teaching course 006 in July 2022 - automatic derivation of types and input and output
完整的模型训练套路
New library online | cnopendata China Star Hotel data
NVIDIA Jetson测试安装yolox过程记录
Codeforces Round #804 (Div. 2)(A~D)
【GO记录】从零开始GO语言——用GO语言做一个示波器(一)GO语言基础
y59.第三章 Kubernetes从入门到精通 -- 持续集成与部署(三二)
Service Mesh介绍,Istio概述
My best game based on wechat applet development
13.模型的保存和载入
9.卷积神经网络介绍
[necessary for R & D personnel] how to make your own dataset and display it.
German prime minister says Ukraine will not receive "NATO style" security guarantee