当前位置:网站首页>[yarn] yarn container log cleaning
[yarn] yarn container log cleaning
2022-07-06 11:31:00 【kiraraLou】
Preface
Let's tidy up today yarn Container Log cleaning mechanism .
One 、container Log directory structure
Yarn container The log directory structure of is shown in the following figure .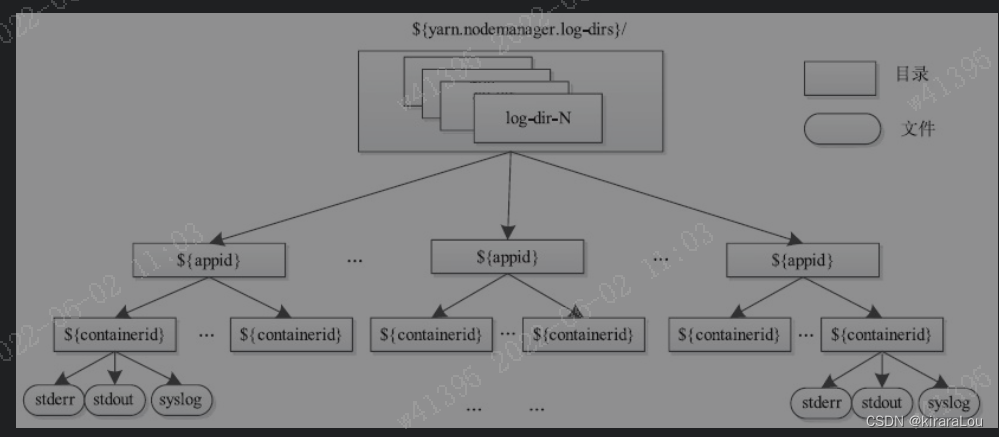
NodeManager The same directory structure will be established for the same application on all directories , And the polling scheduling method is used to allocate these directories to different Container Use . Every Container Three types of logs will be output :
stdout: Log printed using standard output function , such as Java MediumSystem.out.printOutput content .stderr: Log information generated by standard error output .syslog: Use log4j Printed log information , This is the most commonly used way to print logs , By default ,YARN The log is printed in this way , let me put it another way , Usually , Only this file has content , The other two files are empty .
This configuration is yarn.nodemanager.log-dirs.
Two 、 Log cleaning mechanism
because NodeManager Will all Container Save the running log of to the local disk , therefore , Over time , There will be more and more logs . To avoid a lot of Container journal “ Burst ” disk space ,NodeManager Log files will be cleaned up periodically , This function consists of components LogHandler( There are currently two implementations :NonAggregatingLogHandler and LogAggregationService) complete .
In total ,NodeManager Provides regular deletion ( from NonAggregatingLogHandler Realization ) And log aggregation transfer ( from LogAggregation-Service Realization ) Two log cleaning mechanisms , By default , The mechanism of regular deletion is adopted .
1. Delete periodically
NodeManager Allow an application log to remain on disk for yarn.nodemanager.log.retain-seconds( The unit is seconds , The default is 3×60×60, namely 3 Hours ), Once that time has passed ,NodeManager All logs of the application will be deleted from the disk .

2. Log aggregation and forwarding
Except for regular deletion ,NodeManager Another log processing method is also provided —— Log aggregation and forwarding [ illustrations ], Administrators can configure parameters yarn.log-aggregation-enable Set as true Enable this feature .
The mechanism will HDFS As a log aggregation warehouse , It uploads the logs generated by the application to HDFS On , For unified management and maintenance . The mechanism consists of two stages : File upload and file lifecycle management .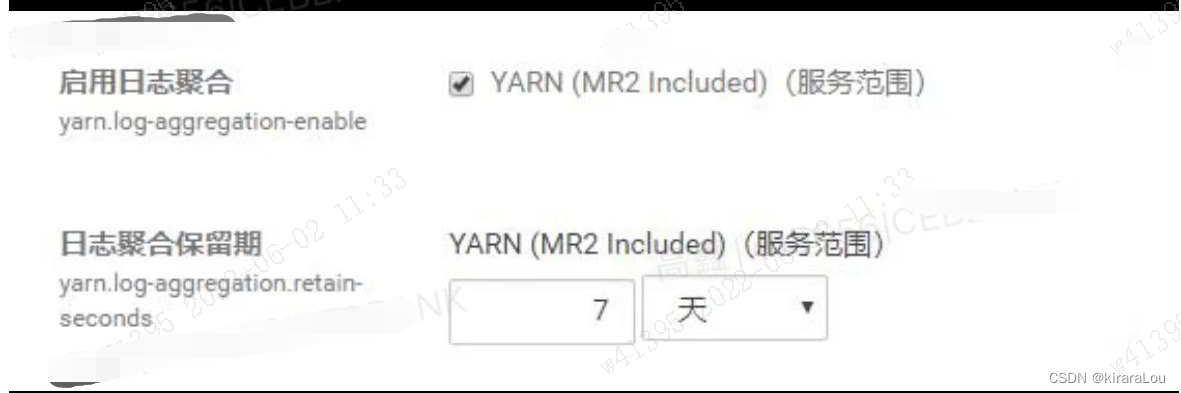
(1) Upload files
When an application finishes running , All logs generated by it will be uploaded to HDFS Upper ${remoteRootLogDir}/${user}/${suffix}/${appid}
${remoteRootLogDir}The value is determined by the parameteryarn.nodemanager.remote-app-log-dirAppoint , The default is/tmp/logs${user}For the application owner${suffix}The value is determined by the parameteryarn.nodemanager.remote-app-log-dir-suffixAppoint , The default is "logs"${appid}For applications ID
And all logs in the same node are saved to the same file in the directory , These files are represented by nodes ID name .
The log structure is shown in the following figure .
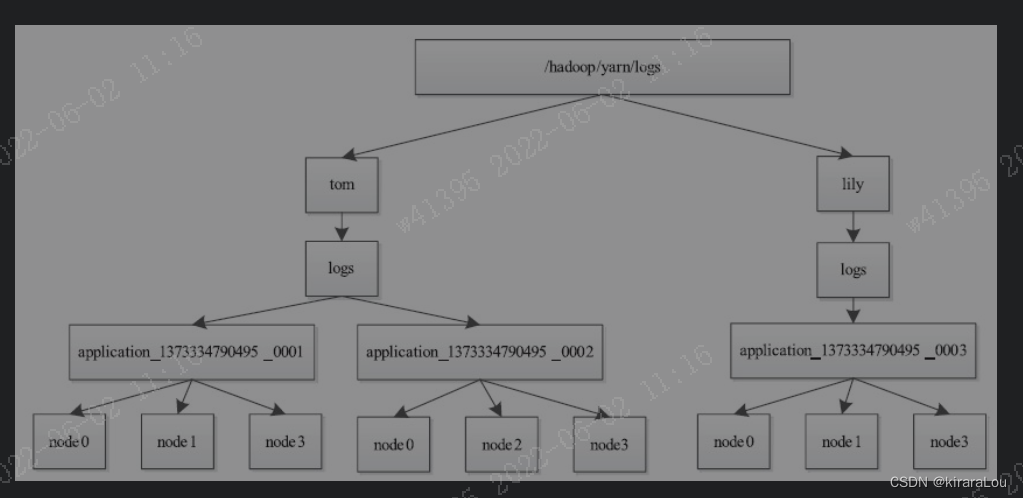
Once all the logs are uploaded to HDFS after , The log files on the local disk will be deleted . Besides , In order to reduce unnecessary log uploading ,NodeManager Allow users to specify the log type to upload . There are three types of logs currently supported :
ALL_CONTAINERS( Upload allContainerjournal )APPLICATION_MASTER_ONLY( Upload onlyApplicationMasterGenerated log )AM_AND_FAILED_CONTAINERS_ONLY( UploadApplicationMasterAnd failedContainerGenerated log ), By defaultALL_CONTAINERS.
(2) File lifecycle management
Transfer to HDFS The life cycle of logs on is no longer controlled by NodeManager be responsible for , But by the JobHistory Service management . For example, for MapReduce In terms of computational framework , It's proprietary JobHistory Be responsible for regular cleaning MapReduce Transfer the job to HDFS Log on , The maximum retention time of each log file is yarn.log-aggregation.retain-seconds( The unit is seconds , The default is 3×60×60, namely 3 Hours ).
Users can view the application log in two ways , One is through NodeManager Of Web Interface ; The other is through Shell Command view .
View all logs generated by an application , The order is as follows :
bin/yarn logs -applicationId application_130332321231_0001
View one Container Generated log , The order is as follows :
bin/yarn logs -applicationId application_130332321231_0001 -containerId container_130332321231_0002 -nodeAddress 127.0.0.1_45454
summary
Yarn ContainerThere are two mechanisms: local deletion and log aggregation and transfer deletion .Yarn ContaionerLocal logs are created byyarn.nodemanager.log.retain-secondscontrol .yarn.log-aggregation-enableIs to enable log aggregation and transfer .- The log after transferring is saved by
yarn.log-aggregation.retain-secondscontrol .
边栏推荐
猜你喜欢

分布式节点免密登录
Image recognition - pyteseract TesseractNotFoundError: tesseract is not installed or it‘s not in your path
Use dapr to shorten software development cycle and improve production efficiency
When you open the browser, you will also open mango TV, Tiktok and other websites outside the home page

小L的试卷
![[download app for free]ineukernel OCR image data recognition and acquisition principle and product application](/img/1b/ed39a8b9181660809a081798eb8a24.jpg)
[download app for free]ineukernel OCR image data recognition and acquisition principle and product application
Dotnet replaces asp Net core's underlying communication is the IPC Library of named pipes
Neo4j installation tutorial
How to build a new project for keil5mdk (with super detailed drawings)
C语言读取BMP文件
随机推荐
Number game
Codeforces Round #771 (Div. 2)
Connexion sans mot de passe du noeud distribué
QT creator support platform
Introduction to the easy copy module
Pytorch基础
L2-007 家庭房产 (25 分)
One click extraction of tables in PDF
Picture coloring project - deoldify
express框架详解
牛客Novice月赛40
In the era of DFI dividends, can TGP become a new benchmark for future DFI?
L2-006 tree traversal (25 points)
Learning question 1:127.0.0.1 refused our visit
Deoldify project problem - omp:error 15:initializing libiomp5md dll,but found libiomp5md. dll already initialized.
TypeScript
Database advanced learning notes -- SQL statement
Valentine's Day flirting with girls to force a small way, one can learn
Antlr4 uses keywords as identifiers
Learn winpwn (2) -- GS protection from scratch